用于目标识别的神经网络终端运行方法和装置与流程
本发明属于智能算法领域,涉及一种用于目标识别的神经网络终端运行方法和装置。
背景技术:
红外成像在军用导引头中的应用广泛应用,其中,针对航弹在移动靠近打击过程中目标的识别很重要。目标由远到近的过程中目标成像的结构外形有很大的变化,因此采用传统的图像处理很难提取出固有的特征进行识别处理。采用深度卷积神经网络的方法进行自动目标识别,可以获得很高的识别率,但是由于参数量很大,模型参数存储是很大的问题,且在终端移植上也存在巨大挑战。
相关技术中,大多是通过将深度卷积神经网络模型经过剪枝,进行参数压缩以适应目前硬件的条件。但是该优化方法存有极限,且随着深度卷积神经网络发展,网络模型的深度和宽度将会变大,但是编程逻辑模块pl(programmablelogic)的资源,如块随机存取存储器bram(blockrandomaccessmemory)、触发器ff(flipflop)等增加的速度却远远跟不上。因此在目标识别过程中,将深度卷积神经网络在pl中完全实现是不现实的。
针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
本发明提供了一种用于目标识别的神经网络终端运行方法和装置,以至少解决相关技术中硬件处理器无法满足目标识别中深度卷积神经网络运行要求的技术问题。
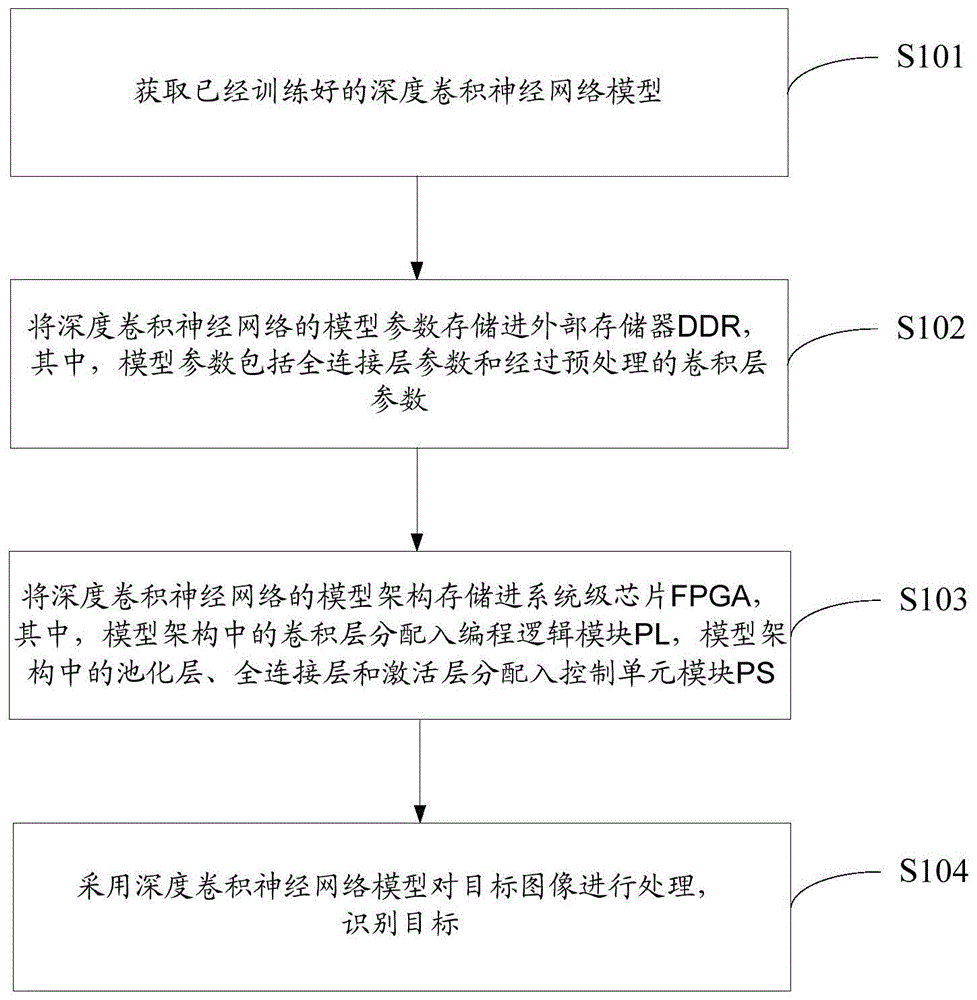
本发明的技术解决方案是:一种用于目标识别的神经网络终端运行方法,包括:获取已经训练好的深度卷积神经网络模型;将所述深度卷积神经网络的模型参数存储进外部存储器ddr,其中,所述模型参数包括全连接层参数和经过预处理的卷积层参数;将所述深度卷积神经网络的模型架构存储进系统级芯片fpga,其中,所述模型架构中的卷积层分配入编程逻辑模块pl,所述模型架构中的池化层、全连接层和激活层分配入控制单元模块ps;采用所述深度卷积神经网络模型对目标图像进行处理,识别所述目标。
可选的,采用所述深度卷积神经网络模型对所述目标图像进行处理,识别所述目标,包括:提取所述卷积层参数到所述pl,根据所述卷积层和所述目标图像,在所述pl中进行卷积层计算,得到所述目标图像的特征数据;提取全连接层参数到所述ps,根据所述池化层、所述全连接层、所述激活层和所述特征数据,在所述ps中进行计算,得到并输出所述目标的识别结果。
可选的,提取所述卷积层参数到所述pl,根据所述卷积层和所述目标图像,在所述pl中进行卷积层计算,得到所述目标图像的特征数据,包括:设计卷积层计算模块,所述卷积层计算模块用于进行卷积核计算,其中,所述卷积层有多个,所述目标图像每一个卷积层中有多个卷积核,所述卷积层计算模块有多个;根据所述pl,分配不同的卷积层计算模块进行并行计算;根据所述目标图像和多个卷积层计算模块,得到所述目标图像的特征数据。
可选的,设计卷积层计算模块,包括:采用二维快速傅里叶变换2dfft对所述目标图像进行计算,获取所述目标图像的频域图像数据;将所述频域图像数据与所述卷积层参数进行复数乘法计算;采用二维快速傅里叶逆变换2difft对复数乘法计算后的数据进行处理,并对处理后的结果进行实部提取,并输出。
可选的,采用2dfft对所述目标图像进行计算,包括:针对原图图像img(x,y),依次选取各行中数据做1dfft处理:
针对上一步计算结果,依次选取各列中数据再做1dfft处理:
采用2difft对复数乘法计算后的数据进行处理,包括:对复数乘法计算后的数据img_k(x,y)依次选取各行中数据做1difft处理:
针对上一步计算结果,依次选取各列中数据再做1difft处理:
其中,k1、p1、k2、p2均为频域变换后参数。
可选的,所述预处理为:对原卷积层参数进行2dfft计算。
可选的,在所述pl中每进行完一次卷积层计算模块的计算,均通过中断系统通知所述ps进行下一次计算的调度。
可选的,第一卷积层参数精度为int32,第二卷积层参数精度为int16,第三卷积层参数精度为int8,第四卷积层及其他卷积层参数精度均为int4。
根据本发明的另一方面,还提出了另一种技术解决方案:一种用于目标识别的神经网络终端运行装置,包括:获取模块,用于获取已经训练好的深度卷积神经网络模型;第一存取模块,用于将所述深度卷积神经网络的模型参数存储进外部存储器ddr,其中,所述模型参数包括全连接层参数和经过预处理的卷积层参数;第二存取模块,用于将所述深度卷积神经网络的模型架构存储进系统级芯片fpga,其中,所述模型架构中的卷积层分配入编程逻辑模块pl,所述模型架构中的池化层、全连接层和激活层分配入控制单元模块ps;识别模块,用于采用所述深度卷积神经网络模型对目标图像进行处理,识别所述目标。
根据本发明的另一方面,还提出了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述任意一项的用于目标识别的神经网络终端运行方法。
本发明的用于目标识别的神经网络终端运行方法,基于对深度卷积神经网络计算的特点分析,将网络模型中计算量大的卷积层计算在pl中搭建,将计算量略小的池化层、全连接层和激活层计算在ps中搭建,同时,还利用ps进行网络计算调度,并在移植前对卷积层参数进行预处理,以减少移植后pl中的卷积层计算量。区别于相关技术中通过剪枝进行参数压缩后将整个深度卷积网络在pl中完全实现的方式,本发明解决了因为深度卷积神经网络参数量大、pl中bram资源少,导致的硬件处理器无法满足目标识别中深度卷积神经网络运行要求的技术问题,实现了在向目标运动变化的过程中目标识别的精度提高和速度加快的技术效果。
附图说明
图1是根据本发明实施例的用于目标识别的神经网络终端运行方法的流程图;
图2是根据本发明实施例的卷积层计算模块的加速设计示意图;
图3是根据本发明实施例的用于目标识别的神经网络终端运行系统示意图;
图4是根据本发明实施例的用于目标识别的神经网络终端运行装置示意图。
具体实施方式
为使本领域技术人员更好的理解本发明方案,下面将结合附图描述本发明实施例。
根据本发明实施例,提供了一种用于目标识别的神经网络终端运行的方法实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
图1是根据本发明实施例的用于目标识别的神经网络终端运行方法的流程图,如图1所示,该方法包括如下步骤:
步骤s101,获取已经训练好的深度卷积神经网络模型;
步骤s102,将深度卷积神经网络的模型参数存储进外部存储器ddr(doubledataratesdram),其中,模型参数包括全连接层参数和经过预处理的卷积层参数;
步骤s103,将深度卷积神经网络的模型架构存储进系统级芯片fpga(fieldprogrammablegatearray),其中,模型架构中的卷积层分配入编程逻辑模块pl,模型架构中的池化层、全连接层和激活层分配入控制单元模块ps(processingsystem);
步骤s104,采用深度卷积神经网络模型对目标图像进行处理,识别目标。
需要说明的是,对于深度卷积神经网络的实现,在可供选择的处理器终端中(如cpu、gpu、fpga、asic),通过仿真测算,可得出前向深度卷积神经网络各层计算时间占系统总预测时间的百分比,其中,卷积层占用系统计算总时间比例最高,全连接层、池化层和激活层占比时间较少,因此可以得出针对深度卷积神经网络的优化,主要针对卷积层展开即可。
基于对深度卷积神经网络计算的特点分析,通过上述步骤,可以实现在本发明实施例中,将网络模型中计算量大的卷积层计算在pl中搭建,将计算量略小的池化层、全连接层和激活层计算在ps中搭建,同时,本发明实施例还利用ps进行网络计算调度,并在移植前对卷积层参数进行预处理,以减少移植后pl中的卷积层计算量。
区别于相关技术中通过剪枝进行参数压缩后将整个深度卷积网络在pl中完全实现的方式,本发明实施例解决了因为深度卷积神经网络参数量大、pl中bram资源少,导致的硬件处理器无法满足目标识别中深度卷积神经网络运行要求的技术问题,实现了在向目标运动变化的过程中目标识别的精度提高和速度加快的技术效果。
可选的,采用深度卷积神经网络模型对目标图像进行处理,识别目标,可以包括:提取卷积层参数到pl,根据卷积层和目标图像,在pl中进行卷积层计算,得到目标图像的特征数据;提取全连接层参数到ps,根据池化层、全连接层、激活层和特征数据,在ps中进行计算,得到并输出目标的识别结果。即通过在pl中进行卷积层计算,在ps中进行池化层、全连接层和激活层计算的方式,解决了深度卷积神经网络扩展带来的移植问题,并进一步实现了识别加速。
进一步优选的,提取卷积层参数到pl,根据卷积层和目标图像,在pl中进行卷积层计算,得到目标图像的特征数据,包括:设计卷积层计算模块,卷积层计算模块用于进行卷积核计算,其中,卷积层有多个,目标图像每一个卷积层中有多个卷积核,卷积层计算模块有多个;根据pl,分配不同的卷积层计算模块进行并行计算;根据目标图像和多个卷积层计算模块,得到目标图像的特征数据。
红外成像在军用导引头中的应用广泛,主要是针对目标的识别的需求更显突出,针对红外目标的识别,由于本身导引头红外图像的分辨率就很低,因此,针对红外目标的识别需求很大。在对于小尺寸红外目标的用于目标识别的神经网络终端运行过程中,由于小尺寸红外图像,尺寸小、单通道等特点,在输入处理器终端预测过程前,首先可以对输入的目标图像进行标准化处理,由于航弹再由远及近靠近目标的过程中,目标在视场中的大小(所占像素多少)不同,所以针对实际目标大小特点,确定标准化尺寸,将输入候选区目标缩放到制定尺寸,再输入卷积神经网络进行目标识别。
然后结合已训练好模型中模型参数里卷积核的设计尺寸,进行相应卷积层计算模块设计。对于小尺寸红外目标,深度卷积神经网络中卷积层在3-5层就可以很好的提取到物体的特征,考虑到同一层卷积层中计算模块的复用性,因此每一个卷积层中卷积层计算模块需要至少设计一个,然后针对不同卷积层输入图片的大小进行相应类别卷积层计算模块的设计,同时根据处理器资源使用特点,同一类别的卷积层计算模块可以进行多个设计,以便在计算同一层卷积层中,多个卷积核在算法层面上可以实现多级流水并行计算处理,避免了逻辑资源闲置浪费。
为了进一步在算法层面进行计算加速,优选的,设计卷积层计算模块,可以包括:采用二维快速傅里叶变换2dfft(2d-fastfouriertransformation)对目标图像进行计算,获取目标图像的频域图像数据;将频域图像数据与卷积层参数进行复数乘法计算;采用二维快速傅里叶逆变换2difft(2d-inversefastfouriertransform)对复数乘法计算后的数据进行处理,并对处理后的结果进行实部提取,并输出。
图2是根据本发明实施例的卷积层计算模块的加速设计示意图,如图2所示,本发明实施例首先在对网络模型进行移植前,对卷积层参数进行预处理,移植后,在输入目标图像时,卷积层计算模块对目标图像做2dfft计算。再结合预处理过的卷积层参数做复数乘法计算,最后将计算后的结果做2difft计算,针对最终计算结果进行实部提取,作为每个卷积层计算模块的输出。
其中,上述卷积层参数的预处理行为:对原卷积层参数进行2dfft计算。通过在移植前对卷积层参数进行预处理,可以减少移植后pl中的卷积层计算量,进而对整个网络模型计算能力进一步加速。
同时,通过fft加速卷积层计算不仅可以减少计算量,占用较少pl中的逻辑资源,并且可以加速计算,减少计算时间。
其中,原图图像为img(x,y),(x=0,1,…,m-1;y=0,1,…,n-1),预处理过的卷积层参数复数矩阵为kernel(x,y),(x=0,1,…,2m-1;y=0,1,…,n-1),x、y分别表示二维图像中的横纵坐标的位置。其中,计算过程为:
第一步,针对原图图像img(x,y),依次选取各行中数据做1dfft处理:
第二步,针对第一步的计算结果,依次选取各列中数据再做1dfft处理:
第三步,将第二步的计算结果与kernel(x,y)按对应位相乘做复数乘法:
img_k(x,y)=img2(x,y)*kernel(x,y);
第四步,将第三步计算后的结果依次选取各行中数据做1difft处理:
第五步,针对第四步计算结果依次选取各列中数据再做1difft处理:
第六步,取第五步中输出结果img4(x,y)的实部输出。
其中,k1、p1、k2、p2均为频域变换后参数。
优选的,在pl中每进行完一次卷积层计算模块的计算,均通过中断系统通知ps进行下一次计算的调度。在各个卷积层计算模块的计算过程中,本发明实施例可以根据处理器芯片资源容量特点,对并行计算进行卷积层计算模块进行分配。图3是根据本发明实施例的用于目标识别的神经网络终端运行系统示意图,如图3所示,每个卷积层计算模块均基于axi_lite接口受ps的控制和调度,在每个卷积层计算模块的每次计算完成后,即对每个卷积层计算模块中的卷积核计算完成后,pl都会通过中断系统通知ps,ps完成新的计算调度,并通过gp口控制相应等待的ip进行新一轮的多级流水计算,其中,每个卷积层计算模块都包含cnn加速部分和cnn控制部分,ann为全连接层计算模块,可根据芯片逻辑资源使用情况将全连接层计算移植到pl中计算完成,hp口为ps与pl之间通信的高速总线接口。
为了提升深度卷积神经网络在提取特征特点时的泛化能力,优选的,网络结构中,第一卷积层参数精度可以为int32,第二卷积层参数精度可以为int16,第三卷积层参数精度可以为int8,第四卷积层及其他卷积层参数精度均为int4。即本发明实施例中将深度卷积神经网络参数精度采用逐层递减(int32→int16→int8→int4)的方式进行相应的计算,如果需要继续扩充卷积层,则以最低int4的精度扩展。参数浮点数据转定点后,不仅可以减少参数存储,占用较少的存储资源和数据传输带来的时延,定点参数计算相对于浮点参数计算可以占用较少的逻辑资源并且计算时延减少。
其中,由于小尺寸单通道红外图像中间计算结果进行fft加速计算过程中缓存较小,所以可以根据实际情况选择,卷积层加速计算后结果是保存在bram中,还是通过hp1和hp2接口缓存在外部存储器中。在结果数据量较大时,如对于高清红外图像应用,由于中间计算过程中储存结果较大,不能存储在bram资源中,需要转存到外部存储器中,故该存储方式的灵活设计可以满足实际应用需求。
进一步的,本发明实施例中的处理器芯片可以选用xlinx的xc7z030-2fbg484i。
根据本发明实施例,还提供了一种用于目标识别的神经网络终端运行的装置实施例,图4是根据本发明实施例的用于目标识别的神经网络终端运行装置示意图,如图4所示,该装置包括:获取模块41,第一存取模块42,第二存取模块43,识别模块44,其中,
获取模块41,用于获取已经训练好的深度卷积神经网络模型;
第一存取模块42,连接于获取模块41,用于将深度卷积神经网络的模型参数存储进外部存储器ddr,其中,模型参数包括全连接层参数和经过预处理的卷积层参数;
第二存取模块43,连接于第一存取模块42,用于将深度卷积神经网络的模型架构存储进系统级芯片fpga,其中,模型架构中的卷积层分配入编程逻辑模块pl,模型架构中的池化层、全连接层和激活层分配入控制单元模块ps;
识别模块44,连接于第二存取模块43,用于采用深度卷积神经网络模型对目标图像进行处理,识别目标。
根据本发明实施例,还提供了一种处理器,该处理器用于运行程序,其中,程序运行时执行上述任意一项的用于目标识别的神经网络终端运行方法。
本发明说明书中未作详细描述的内容属本领域技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!