一种基于词频幂律分布特性的文本关键词权重计算方法与流程
本发明涉及一种基于词频幂律分布特性的文本关键词权重计算方法。
背景技术:
目前应用最广的关键词提取算法有tf-idf、textrank、主题模型以及基于深度学习的word2vec。tf-idf是典型的词袋法,忽略单词的顺序,语法及句法,仅仅将文本看成若干个词汇的集合,且每个单词都是独立的,不依赖与其他单词的出现而出现。并且,在计算词的逆文档频率(idf)时,需要依赖领域文本集,无法针对单篇的文本,而领域文集的质量和规模对于词权重计算及关键词抽取产生巨大影响。textrank将文本的候选关键词节点及其共现关系链接组成有向图,利用pagerank算法在节点之间迭代传播节点权重,直至收敛。textrank虽然无需训练集,只需对单篇文本进行权重计算,但其权重迭代过程是基于词频和词共现频率,没有考虑文本的语义信息。主题模型认为文本是由多个主题组成,而主题又是词语的概率分布。通过大规模训练集即“词语-文档”矩阵,推理出“词语-主题”矩阵和“主题-文档”矩阵从而获得文本主题关键词。word2vec可以将字词转化成机器可理解的多维稠密的词向量,广泛应用于机器翻译和在线自动问答等领域,准确率较高,但构建多维稠密词向量需要大规模的训练集,且训练过程的参数规模非常庞大。
技术实现要素:
本发明的目的在于针对现有技术存在的缺陷,提供一种基于词频幂律分布特性的文本关键词权重计算方法。该方法充分利用文本的词频呈现幂律分布,且高频词成为关键词的概率比低频词大的特点,利用概率公式将初始时以词频表示的词权重转化为以词重要性表示的词权重,并且只针对单篇文本,无需文本的领域知识或领域文本集作为辅助,也无需递归收敛过程。
为了达到上述的目的,本发明的构思如下:
文本预处理后,以候选关键词为节点,词频为节点的初始权重,词共现为边,词共现频率为边的初始权重,构建无向的关键词网络。由于文本的词频呈现幂律分布的特点,因此文本词的权重(体现词重要性的指标)也应呈现幂律分布,且高频词成为高权重词(关键词)的概率比低频词大。利用概率公式将以词频为初始值的词权重转化为以词重要性为词的权重,由此可以得出所有词的权重。
根据上述的发明思想,本发明采用下述技术方案:
一种基于词频幂律分布特性的文本关键词权重计算方法,其具体步骤如下:
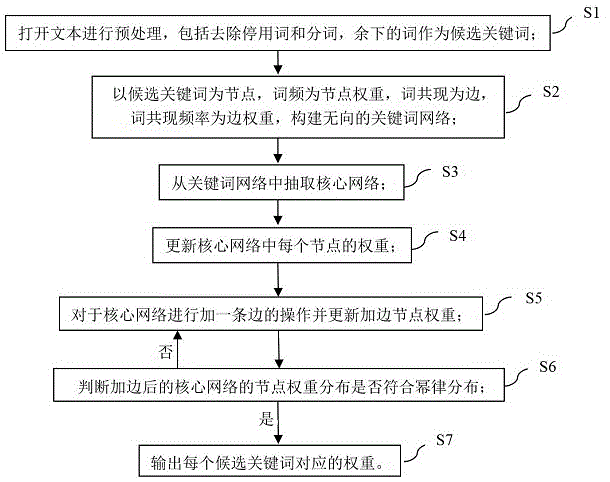
s1:打开文本进行预处理,包括去除停用词和分词,余下的词作为候选关键词;
s2:以候选关键词为节点,词频为节点权重,词共现为边,词共现频率为边权重,构建无向的关键词网络;
s3:从关键词网络中抽取核心网络;
s4:更新核心网络中每个节点的权重;
s5:对于核心网络进行加一条边的操作并更新节点权重;
s6:判断加边后的核心网络的节点权重分布是否符合幂律分布,如果不符合,转至步骤s5;如果符合,转至步骤s7;
s7:输出每个候选关键词对应的权重。
所述步骤s3中从关键词网络中抽取核心网络,其方法是:设计两个节点集合a和b,及一个边集合l。a为核心网络节点集合,b为关键词网络节点集合,l为核心网络边集合。初始状态下,所有节点均属于b。从b中选择权重最大的节点作为当前节点加入a,从当前节点的边中选择权重最大的边作为当前边加入l,此时当前节点更新为当前边对应的另一端节点。若更新后的当前节点已经属于a,则从b中再选择权重最大的节点作为当前节点。重复上述步骤,直至b集合为空。
所述步骤s4中更新核心网络中每个节点的权重,其方法是将每个节点的权重更新为每个节点的原始权重和该节点当前所有边的权重之和。
所述步骤s5中对于核心网络进行加一条边的操作并更新节点权重,其方法是选择两个节点加一条边,每个节点被选择的概率与其权重成正比,权重越大,节点被选择的概率也就越大,两个选中的节点权重各加1;若此两节点之间已有边相连,则边权重加1;否则两节点之间加一条边,权重为1。
所述步骤s6中节点权重分布定义为权重为k的节点个数nk的分布,其中k=0,1,2…。
所述步骤s6中幂律分布函数为f(n)=c×n-α,其中,c和α均是常数。
所述步骤s6中计算每次加边后的节点权重分布如下:
本发明的文本关键词权重计算方法与现有技术相比较,具有如下突出优点:
本发明方法没有领域文本集和训练集,能够通过扫描单篇文本,利用文本的词频和权重均呈现幂律分布,且词频越大的词,其权重也越大的特点,利用概率公式将词频转化成词权重。具体方法是利用概率将体现词频的边删掉,再以当前权重成正比的概率选择节点添加边,同时增加节点权重,直到权重分布呈现幂律分布。由于幂律分布是可扩展的数量级,因此,能够兼具tfidf的功能,而且比tfidf更加简便。
附图说明
图1是本发明方法的流程图。
具体实施方式
以下结合附图对本发明的实施例作进一步的说明。
本实施例以ieeetransactionsonparallelanddistributedsystems期刊的文章《hring:astructuredp2poverlaybasedonharmonicseries》为例。
如图1所示,一种基于词频幂律分布特性的文本关键词权重计算方法,其具体步骤如下:
s1:打开文本进行预处理,包括去除停用词和分词,余下的词作为候选关键词。
s2:以候选关键词为节点,词频为节点权重,词共现为边,词共现频率为边权重,构建无向的关键词网络。将关键词网络以表格形式表示,见表1,1(a)表示节点的权重,1(b)表示边权重。
表1(a).关键词网络的节点权重
表1(b).关键词网络的边权重
s3:从关键词网络中抽取核心网络;其方法是:设计两个节点集合a和b,及一个边集合l。a为核心网络节点集合,b为关键词网络节点集合,l为核心网络边集合。初始状态下,所有节点均属于b。从b中选择权重最大的节点作为当前节点加入a,从当前节点的边中选择权重最大的边作为当前边加入l,此时当前节点更新为当前边对应的另一端节点。若更新后的当前节点已经属于a,则从b中再选择权重最大的节点作为当前节点。重复上述步骤,直至b集合为空。将核心网络以表格表示,见表2,2(a)表示节点权重,2(b)表示边的权重。
2(a).核心网络的节点权重
2(b).核心网络的边权重
s4:更新核心网络中每个节点的权重;其方法是将每个节点的权重更新为每个节点的原始权重和该节点当前所有边的权重之和。更新后的核心网络以表格表示,表3表示更新后的节点权重,此时的边权重仍为2(b)。
表3.核心网络的节点权重
s5:对于核心网络进行加一条边的操作并更新节点权重;其方法是选择两个节点加一条边,每个节点被选择的概率与其权重成正比,权重越大,节点被选择的概率也就越大,两个选中的节点权重各加1;若此两节点之间已有边相连,则边权重加1;否则两节点之间加一条边,权重为1。每个节点的权重及其被选中的概率如下表4(a)表示。假设被选中的节点为p2p和overlay,则表4(b)和4(c)中对应的p2p和overlay进行更新操作后的节点权重和边权重。
表4(a).节点权重及其被选中的概率
表4(b).节点权重更新
表4(c).边权重更新
s6:判断加边后的核心网络的节点权重分布是否符合幂律分布,如果不符合,转至步骤s5;如果符合,转至步骤s7。其中,节点权重分布定义为权重为k的节点个数nk的分布,其中k=0,1,2…。幂律分布函数为f(n)=c×n-α,其中,c和α均是常数。计算每次加边后的节点权重分布如下:
s7:输出每个候选关键词对应的权重。
- 还没有人留言评论。精彩留言会获得点赞!