一种基于持续时间模型的驾驶员违章风险估计方法与流程
本发明属于交通安全技术领域,具体涉及一种基于持续时间模型的驾驶员违章风险估计方法。
背景技术:
现有驾驶员违章行为的检测和预警技术可大致分为如下两类。
(1)一类是基于道路监控设备或车载设备进行视频拍摄,采集车辆行驶轨迹数据,对数据进行处理分析,进而判别当前车辆是否发生违章行为的实时检测方法。这类技术是对车辆当前行为是否违章进行检测或提示,不能对驾驶员进行提前预警。
(2)另一类是运用驾驶员的历史违章地点和违章类型等数据,对驾驶员在特定时间和地点进行违章预警。
一名驾驶员在长时间驾驶的过程中可能发生多次违章行为,驾驶员违章间隔时间可能服从一定的分布规律,并受一些因素的影响。在现有的相关研究中,鲜有从驾驶员违章间隔时间的角度去探索驾驶员违章行为的特征规律。本专利从驾驶员个体角度出发,利用驾驶员的历史违章时间和行为数据,运用持续时间模型挖掘驾驶员违章间隔时间的分布规律,识别违章行为的风险因素(显著影响因素),据此提出:对驾驶员在未来一段时间内的违章风险进行估计的方法。所述估计方法可用于驾驶员违章行为的预测预警,促使其安全驾驶,减少交通违章和事故的发生概率,提升道路交通安全。
技术实现要素:
针对目前驾驶员违章行为分析的不足,本专利提出了一种基于持续时间模型的驾驶员违章风险估计方法。研究成果旨在提出一种基于历史违章数据,对驾驶员在未来一段时间内发生的违章风险进行估计的方法,据此可对驾驶员进行预警提示,为缓减交通违章和事故的发生提供技术支持。具体技术方案如下:
一种基于持续时间模型的驾驶员违章风险估计方法,包括以下步骤:
a、采集驾驶员个人属性构建个人属性数据库,采集车辆属性构建车辆属性数据库,采集驾驶员违章信息(也称为违章属性、历史违章数据)构建驾驶员历史违章信息数据库;
所述个人属性包括:驾驶员的id号(身份证号)、性别、年龄和驾龄等;
所述车辆属性包括:车辆归属地和车辆类型等;
所述违章信息包括:违章发生时间、驾驶员违章间隔时间、上一年违章次数和上一年严重违章类型等。
所述驾驶员违章间隔时间为:同一驾驶员连续两次违章的间隔时间;
所述上一年违章次数指的是:以本次违章的发生年份为基准年,统计得到的该驾驶员上一年的违章次数;
所述上一年严重违章类型指的是:以本次违章的发生年份为基准年,统计该驾驶员上一年是否发生过严重违章行为,有严重违章行为,上一年严重违章类型为1,否则上一年严重违章类型为0;
所述严重违章行为指:在交通违章中,一次性扣分6分或12分的行为;
基于驾驶员的id号,将驾驶员的个人属性、车辆属性和违章信息进行融合匹配,提取驾驶员违章间隔时间,构建驾驶员违章间隔时间样本数据库;
所述驾驶员违章间隔时间样本数据库以驾驶员每次违章间隔时间样本数据作为样本,所述违章间隔时间样本数据还包括:违章间隔时间的删失属性、每次违章间隔时间对应的驾驶员id号、性别、年龄、驾龄、车辆类型、上一年违章次数和上一年严重违章类型;
b、基于非参数方法,估计驾驶员违章间隔时间的整体分布;
c、构建考虑潜在影响因素的违章间隔时间持续时间模型,并估计标定持续时间模型回归参数;
所述潜在影响因素包括:驾驶员性别、驾驶员年龄、驾驶员驾龄、车辆类型、驾驶员上一年违章次数和驾驶员上一年是否发生严重违章;
d、在考虑潜在影响因素下,估计驾驶员违章间隔时间累积生存率
先基于违章间隔时间的持续时间模型及其持续时间模型回归参数估计值,估计违章间隔时间基准生存函数,再估计驾驶员违章间隔时间累积生存率;
e、根据构建的持续时间模型,估计驾驶员发生违章的风险
基于违章间隔时间样本数据和构建的持续时间模型,计算驾驶员的违章危险率,进而估计其在未来一段时间内发生违章行为的风险概率。
在上述技术方案的基础上,所述持续时间模型为cox比例风险模型。
在上述技术方案的基础上,步骤a的具体步骤如下:
a1、采集驾驶员的id号、个人属性、车辆属性和违章信息;
a2、将采集的驾驶员id号和违章发生时间分别作为第一关键词和第二关键词,对驾驶员历史违章信息进行排列,再计算每一名驾驶员的每一次违章间隔时间;
a3、基于驾驶员的id号,将驾驶员的个人属性、车辆属性和违章属性进行融合匹配,得到驾驶员违章间隔时间样本数据库;
a4、将驾驶员性别、驾驶员年龄、驾驶员驾龄、车辆类型、驾驶员上一年违章次数和上一年是否发生严重违章作为违章间隔时间的潜在影响因素;
a5、针对驾驶员性别采用潜在影响因素变量gen,若为女性,gen取值为0,若为男性,gen取值为1;
针对驾驶员年龄采用潜在影响因素变量age,age的取值为驾驶员的年龄,单位为:岁;
针对驾驶员驾龄采用潜在影响因素变量dyear,dyear的取值为驾驶员驾龄,单位为:年;
针对车辆类型采用潜在影响因素变量car;
针对驾驶员上一年违章次数采用潜在影响因素变量vtime,vtime的取值为驾驶员上一年的违章次数;
针对驾驶员上一年是否发生严重违章采用潜在影响因素变量vtype,当驾驶员上一年发生过严重违章行为,vtype的取值为1;当驾驶员上一年未发生过严重违章行为,vtype的取值为0。
在上述技术方案的基础上,步骤b中所述非参数方法为乘积极限法。在上述技术方案的基础上,步骤b的具体步骤如下:
假设驾驶员违章间隔时间数据为n个,所述驾驶员违章间隔时间数据包括:删失数据和完全数据;
将上述违章间隔时间数据从小到大排成t(1)≤t(2)≤…≤t(i)≤…≤t(n),则通过式(3)估计驾驶员违章间隔时间的整体分布,
其中,skm(t(i))为驾驶员违章间隔时间大于t(i)的概率;1≤i≤n,1≤j≤n;j*为:在满足违章间隔时间t(j)<t(i)的条件下,所有j的集合;t(j)为完全数据;d(j)为违章间隔时间等于t(j)的违章间隔时间样本数量,包括在[t(j),t(j+1))时段内发生违章的完全数据和在这一时段内终止观测的删失数据;r(j)为:在所有违章间隔时间样本中,违章间隔时间不小于t(j)的违章间隔时间样本数量,包括:完全数据和删失数据。
在上述技术方案的基础上,所述cox比例风险模型包括:驾驶员违章间隔时间t的危险率函数h(t)和驾驶员违章间隔时间累积生存率函数s(t);
在步骤c中,构建cox比例风险模型的具体步骤如下:
c1、假设t为驾驶员违章间隔时间变量,所述驾驶员违章间隔时间t的危险率函数形式如式(4)所示,
h(t)=h0(t)exp(βx′)(4)
其中,h(t)为危险率函数,t为时间变化量,x=(x1,x2,…,xj1,…,xq)为q个潜在影响因素变量的取值形成的一维行向量,称为协变量;β=(β1,β2,…,βj1,…,βq)为协变量x中的q个潜在影响因素变量分别对应的cox比例风险模型回归参数形成的一维行向量;1≤j1≤q;exp(βx')代表协变量x对h(t)的影响;h0(t)为:当所有的潜在影响因素都被忽略时的危险率,称为基准危险率函数;x'表示对x进行转置操作;
c2、驾驶员违章间隔时间累积生存率函数s(t)如式(5)所示,
其中,
在上述技术方案的基础上,在步骤c中,估计标定cox比例风险模型回归参数的步骤如下:
c3、假设在n个违章间隔时间样本中,k个违章间隔时间为完全数据,将k个违章间隔时间完全数据从小到大排列成t(1)≤t(2)≤…≤t(k1)≤…≤t(k),对应的潜在影响因素协变量依次为x(1)=(x1(1),x2(1),…,xj1(1),…,xq(1)),x(2)=(x1(2),x2(2),…,xj1(2),…,xq(2)),…,x(k1)=(x1(k1),x2(k1),…,xj1(k1),…,xq(k1)),…,x(k)=(x1(k),x2(k),…,xj1(k),…,xq(k)),计算偏似然函数l(β),如式(7)所示,
其中,k2*为:在所有违章间隔时间数据(即n个违章间隔时间样本)中,不小于t(k1)的违章间隔时间样本集合;
c4、通过极大似然方程组(8)估计β,得出β的估计值
所述极大似然方程组(8)采用newton-raphson方法求解。
在上述技术方案的基础上,步骤d的具体步骤为:
d1、采用公式(9)估计违章间隔时间基准生存函数s0(t),
其中,
d2、根据公式(5),驾驶员违章间隔时间累积生存率s(t)的估计由公式(10)计算,
在上述技术方案的基础上,步骤e的具体步骤为:
e1、根据构建的考虑潜在影响因素的驾驶员违章间隔时间cox比例风险模型,计算出每个潜在影响因素的p值;
设置一显著性水平,通过p值从潜在影响因素中选出显著影响因素;
所述显著性水平不大于0.10;
e2、在只考虑显著影响因素的条件下,根据公式(10)估计出驾驶员在ti时刻和ti+1时刻的违章间隔时间累积生存率估计
令tmi为区间[ti,ti+1)的中点,区间宽度bi=ti+1-ti,驾驶员的违章危险率h(tmi)采用公式(14)进行估计,
e3、驾驶员在上一次违章发生后,持续到ti时刻没有发生新的违章,则在接下来的区间[ti,ti+1)内,发生违章的风险概率pf由式(15)计算,
e4、根据式(15)计算得到某一驾驶员在接下来的区间[ti,ti+1)内的违章风险概率,当违章风险概率大于违章风险给定临界值时,就给上述驾驶员进行违章行为的预警,提醒其安全驾驶,据此达到提升道路交通安全的目的。
在上述技术方案的基础上,所述违章风险给定临界值可根据违章间隔时间的历史数据来确定。具体步骤如下:
e41、根据违章间隔时间的历史数据,计算出历史数据中每个违章间隔时间样本在接下来的区间[ti,ti+1)内发生违章的风险概率;
e42、计算出上述历史数据中所有违章间隔时间样本发生违章的风险概率的均值和标准差;
e43、将步骤e42中的均值加上1.5倍标准差的值作为违章风险给定临界值。
本发明的有益技术效果为:
能够考虑删失数据,更准确地估计驾驶员违章间隔时间的分布;基于驾驶员的个人属性、车辆属性和历史违章信息数据库,构建驾驶员违章间隔时间持续模型,识别违章行为的显著影响因素;计算驾驶员违章间隔时间累积生存率和违章危险率,估计驾驶员未来一段时间内的违章风险概率。可据此为驾驶员提供违章预警提示,减少驾驶员发生违章和事故事件的可能性,提升道路交通安全。
附图说明
本发明有如下附图:
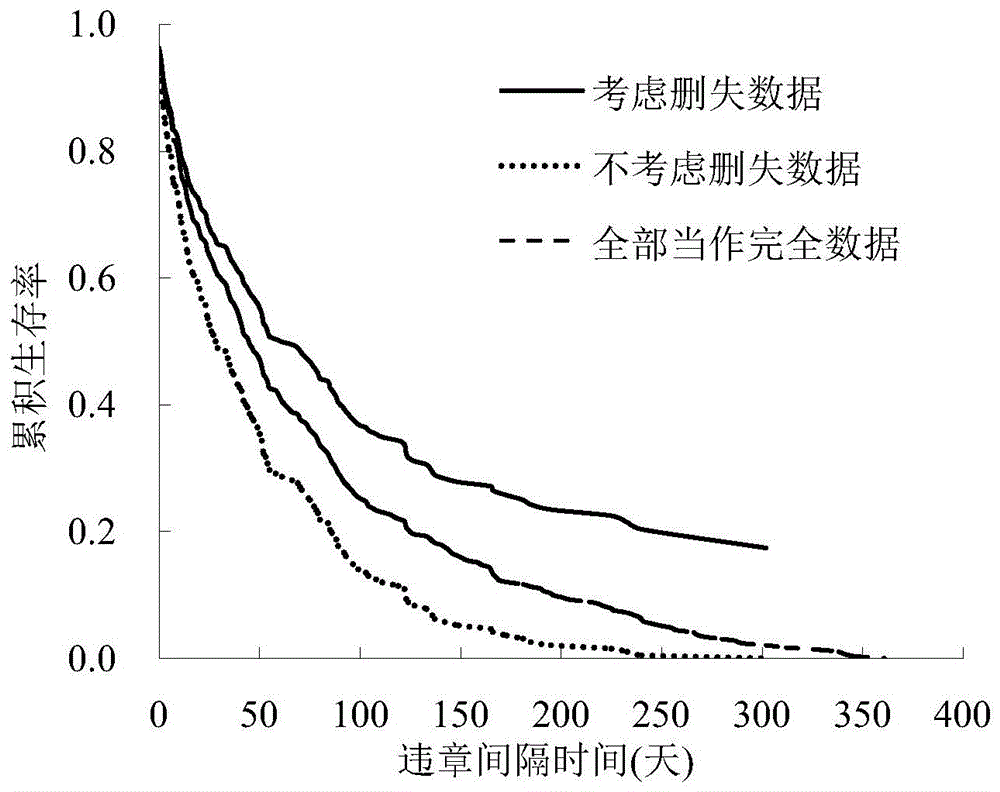
图1不同数据处理方法对驾驶员违章间隔时间分布的影响曲线图。
图2违章间隔时间的基准生存函数曲线。
图3cox比例风险模型估计结果与非参数方法估计结果的比较图。
具体实施方式
为了更清楚地说明本发明,下面结合附图和实施例,对本发明的具体实施方式做进一步详细描述。以下实施例仅用于说明本发明,但不能用来限制本发明的范围。
a、基于驾驶员的id号,将驾驶员的个人属性、车辆属性和违章信息进行融合匹配,提取驾驶员违章间隔时间,构建驾驶员违章间隔时间样本数据库
根据驾驶员个人属性数据库,提取驾驶员的性别、年龄和驾龄等个人属性,根据车辆属性数据库,提取车辆归属地和车辆类型等车辆属性信息;根据驾驶员历史违章信息数据库提取违章行为发生时间、上一年违章次数和上一年严重违章类型等违章属性。
所述上一年违章次数指的是:以本次违章的发生年份为基准年,统计得到的该驾驶员上一年的违章次数。
所述上一年严重违章类型指的是:以本次违章的发生年份为基准年,统计该驾驶员上一年是否发生过严重违章行为,有严重违章行为,上一年严重违章类型为1,否则上一年严重违章类型为0。
先采集驾驶员的身份证号(id)、个人属性、车辆属性和违章信息等数据,再将采集的驾驶员身份证号和违章发生时间分别作为第一关键词和第二关键词,对驾驶员历史违章信息进行排列,再计算每一名驾驶员的每一次违章间隔时间(duration)。
所述驾驶员违章间隔时间指的是:同一驾驶员连续两次违章的间隔时间。
在持续时间模型中,时间数据分为完全数据和删失数据。完全数据指的是:能确切知道的时间数据,比如两次连续违章的间隔时间。删失数据是:由于某种原因未能观察到所感兴趣的事件发生,而得到的数据。比如,在观测时间内的最后一次违章到观测截止的时间差,在观测截止时,后续的违章事件仍未发生,只能知道违章间隔时间大于某一值,而不能知道违章间隔时间的确切值,故称之为删失数据。
违章间隔时间包含完全数据和删失数据两种,在观测截止时间之前发生的多次违章事件,除最后一次违章事件之外,我们可以知道连续两次违章事件之间的确切时间差值,即违章间隔时间的确切值,则为完全数据;从观测截止时间之前的最后一次违章事件,一直持续到观测截止时间,这一时间段内没有新的违章事件发生,因此我们不知道最后一次违章事件与其后续违章事件间隔时间的确切值,则为删失数据。
用event表示违章间隔时间是否为删失数据,若为删失数据,具有删失属性,event=0,否则,不具有删失属性,event=1。另外,如果驾驶员在观测期内一次违章行为都没有发生,则其违章间隔时间为观测期长度,且属于删失数据。
基于驾驶员的身份证号(id),将驾驶员的个人属性、车辆属性和违章属性等进行融合匹配,得到驾驶员违章间隔时间样本数据库。
违章间隔时间样本数据库以驾驶员每次违章间隔时间(duration)数据作为一个样本,即为违章间隔时间样本数据,所述违章间隔时间样本数据的信息还包括:违章间隔时间的删失属性(event)、每次违章间隔时间对应的驾驶员身份证号(id)、性别(gen)、年龄(age)、驾龄(dyear)和车辆类型(car)等个人/车辆属性,以及驾驶员上一年违章次数(vtime)和上一年严重违章类型(vtype)等违章属性(违章特性)。
b、基于非参数方法,估计驾驶员违章间隔时间的整体分布
由于驾驶员违章间隔时间样本中包含删失数据,传统的估计方法不能处理这类问题。为此,需要引入基于风险的持续时间模型方法。令违章间隔时间t的密度函数和分布函数分别为f(t)和f(t),持续时间模型中两个关键概念,t的生存函数s(t)和风险率函数h(t)分别如式(1)和式(2)所示:
违章间隔时间的生存函数s(t)也称之为累积生存率函数,指的是:违章间隔时间长于给定时间t的概率。风险率函数h(t)表示驾驶员上次发生违章后,持续了t天没有发生新的违章,在接下来的一个非常小的单位时间间隔δt内发生违章的(条件)概率。
驾驶员违章间隔时间的整体分布可以运用非参数方法中的乘积极限法来估计。设驾驶员违章间隔时间数据共有n个(包括删失数据和完全数据),将这些数据从小到大排成t(1)≤t(2)≤…≤t(n),则可通过式(3)估计驾驶员违章间隔时间的整体分布。
其中,skm(t(i))表示驾驶员违章间隔时间大于t(i)的概率;j*表示:在满足违章间隔时间t(j)<t(i)的条件下,所有j的集合;但要求t(j)是完全数据;1≤i≤n,1≤j≤n。d(j)是指:在所有违章间隔时间样本中,违章间隔时间大于或等于t(j),但小于t(j+1)的违章间隔时间样本数量,即违章间隔时间等于t(j)的违章间隔时间样本数量,包括在[t(j),t(j+1))时段内发生违章的完全数据和在这一时段内终止观测的删失数据。r(j)是指:在所有违章间隔时间样本中,违章间隔时间不小于t(j)的违章间隔时间样本数量,包括:完全数据和删失数据。
c、构建(拟合)考虑潜在影响因素的违章间隔时间cox比例风险模型,并估计标定cox比例风险模型回归参数
驾驶员的违章间隔时间会受到其自身的个人属性、车辆属性和违章特性等多种潜在因素的影响,cox比例风险模型是最常用的关于生存时间的多因素分析方法,它的优点是对生存时间的分布形式没有事先的假定,具有良好的稳健性。为此,构建驾驶员违章间隔时间cox比例风险模型,根据违章间隔时间样本数据拟合考虑潜在影响因素的违章间隔时间cox比例风险模型,识别违章间隔时间的显著影响因素,并估计标定cox比例风险模型回归参数。
令t为非负的随机变量,代表驾驶员违章间隔时间变量,违章间隔时间的潜在影响因素(包括:驾驶员的个人属性、车辆属性和违章属性等)定义为协变量x(也称之为解释变量),所述协变量x为矢量。给定协变量x后,cox比例风险模型假定驾驶员违章间隔时间t的危险率函数(风险率函数)为式(4)所示,
h(t)=h0(t)exp(βx′)(4)
式中h(t)为潜在的危险率函数,代表随时间变化量t的危险率;exp(βx')代表协变量x的影响;β=(β1,β2,…,βq)为协变量x对应的参数向量,即cox比例风险模型回归参数,q为协变量x的潜在影响因素变量的个数。h0(t)可理解为所有的潜在影响因素都被忽略,即x=0或exp(βx')=1时的危险率,所以也称为基准危险率函数,x'表示对x进行转置操作。
根据生存函数s(t)和h(t)之间的关系,联合公式(2)和(4),可以得到考虑潜在影响因素下,驾驶员违章间隔时间累积生存率函数s(t)如式(5)所示。
这里的
在上述公式(5)中,首先需要估计cox比例风险模型回归参数β。估计回归参数β的基本思路是:先给出β的不依赖于h0(t)的偏似然函数,然后极大化偏似然函数,在缺乏h0(t)信息的情况下,给出β的估计
设n个违章间隔时间样本中,k个违章间隔时间是完全数据,从小到大排列后依次为t(1),t(2),…,t(k),即t(1)≤t(2)<…≤t(k1)≤…≤t(k),对应的潜在影响因素的协变量依次为x(1),x(2),…,x(k1),…,x(k),另外n-k个违章间隔时间是删失数据。违章间隔时间的cox比例风险模型需采用下述的偏似然函数,
其中,k2*为:在n个违章间隔时间样本数据中,不小于t(k1)的违章间隔时间样本集合,l(β)是偏似然函数。l(β)与h0(t)无关,因此可在缺乏h0(t)信息下,通过下列的极大似然方程组估计β。
用newton-raphson方法求解这一方程组,便可得出β的估计值
d、在考虑潜在影响因素下,估计驾驶员违章间隔时间累积生存率
上一步基于违章间隔时间样本数据,得到cox比例风险模型回归参数β的估计后,再运用类似步骤b所述的乘积极限法估计违章间隔时间基准生存函数s0(t)。估计s0(t)的公式如式(9)所示:
其中,
根据公式(5),可得到,考虑潜在影响因素x时,驾驶员违章间隔时间累积生存率s(t)的估计由式(10)计算,
e、根据拟合的cox比例风险模型,估计驾驶员发生违章的风险
根据前面构建的考虑潜在影响因素的驾驶员违章间隔时间cox比例风险模型,以及运用违章间隔时间样本数据对cox比例风险模型的拟合结果,可得到违章间隔时间cox比例风险模型的显著影响因素、参数β的估计值和基准生存函数s0(t)的估计值。
据此,任意给定一个驾驶员的个人/车辆属性和违章信息(即协变量x的值),即可计算出其违章行为的危险率,进而可估计该驾驶员在未来一段时间内[ti,ti+1)发生违章事件的风险概率。具体步骤如下:
首先,基于违章间隔时间样本数据,根据公式(10)可估计出驾驶员在ti时刻和ti+1时刻的违章间隔时间生存函数估计
令tmi为区间[ti,ti+1)的中点,区间宽度bi=ti+1-ti。违章间隔时间的密度函数估计值
所述违章间隔时间的危险率函数估计值
其中,
由公式(11)-(13)得到式(14),
驾驶员在上一次违章发生后,持续到ti时刻没有发生新的违章,则在接下来的区间[ti,ti+1)内,发生违章的风险(即发生违章事件的风险概率)pf由式(15)计算,
可以规定,根据式(15)计算得到驾驶员在接下来的区间[ti,ti+1)内的违章风险概率大于违章风险给定临界值时,就给上述驾驶员进行违章行为的预警,提醒其安全驾驶,据此达到提升道路交通安全的目的。
其中,违章风险给定临界值可根据违章间隔时间历史数据来确定。可根据违章间隔时间历史数据,先求出历史数据中每个违章间隔时间样本在接下来的区间[ti,ti+1)内的违章风险值(即发生违章事件的风险概率),再求出这些违章风险值的均值和标准差。以违章风险均值加上1.5倍标准差的值作为违章风险给定临界值,当估计得到的某驾驶员在接下来的区间[ti,ti+1)内的违章风险概率大于这一违章风险给定临界值时,就给他进行预警。
利用前述给出的基于持续时间模型的驾驶员违章风险估计方法,通过实际数据,给出具体的案例说明以及案例结果展示。
1.案例数据介绍
本专利所使用的数据来自m城市交通部门提供的2012年至2013年的驾驶员违章数据。案例数据为随机选取在2013年发生了违章行为的100位驾驶员为研究对象。
首先针对100位驾驶员,提取其在2012年内的违章次数和严重违章类型(是否有严重违章行为),2013年内的每次违章行为发生时间和违章间隔时间等信息,以及这些驾驶员的个人属性和车辆属性等信息。最终得到100名驾驶员的291个违章间隔时间样本。每个违章间隔时间做为一个样本,违章间隔时间样本的数据信息主要包含以下内容:
(1)驾驶员个人属性:包括驾驶员的性别、驾龄和年龄等。
(2)驾驶员车辆属性:包括驾驶员的车辆类型。
(3)驾驶员违章属性:包括驾驶员本次违章间隔时间、违章间隔时间是否为删失数据、以及驾驶员的上一年违章次数和严重违章类型。
在使用的案例数据中,违章间隔时间样本数据文件的基本格式如表1所示示意,各变量的定义解释如下:
第1列no代表每个违章间隔时间样本的编号。
第2列id代表驾驶员的身份证号。
第3列duration代表驾驶员的违章间隔时间,单位为:天。
第4列event代表该违章间隔时间数据的删失属性,0代表删失数据,1代表完全数据。
第5列gen代表驾驶员性别,0为女性,1为男性。
第6列age代表驾驶员年龄,为数值型变量,单位为:岁。
第7列dyear代表驾驶员驾龄,为数值型变量,单位为:年。
第8列和第9列car(1)和car(2)代表车辆类型,当car(1)=0且car(2)=0时车辆类型为小汽车,当car(1)=1且car(2)=0时为客车,当car(1)=0且car(2)=1时为货车。。
第10列vtime代表驾驶员上一年违章次数,为数值型变量,单位为:次。
第11列vtype代表驾驶员上一年是否发生严重违章,1为上一年发生过严重违章行为,0为上一年未发生过严重违章行为。
表1违章间隔时间样本数据文件的基本格式
2.运用非参数方法估计驾驶员违章间隔时间的整体分布
根据案例数据,运用公式(3)给出的非参数方法估计驾驶员违章间隔时间的整体分布,可以得到驾驶员违章间隔时间的生存函数(累积生存率)。如图1所示,图中实线为:在考虑删失数据的情况下,驾驶员违章间隔时间的累积生存率曲线,表示的是:在给定时间下,驾驶员不发生交通违章的概率。针对图1中的实线,从图中可以得出驾驶员违章间隔时间的累积生存率是时间的减函数,随着时间的增加,驾驶员仍不发生交通违章的概率逐渐降低,可能发生违章的概率则逐渐增大。具体而言,违章间隔时间的下四分位数(亦即累积生存率为75%时)约为15天,表明有25%的驾驶员违章间隔时间不到15天,即25%的驾驶员在15天内就会发生新的交通违章;违章间隔时间的中位数约为61天,表明有一半的驾驶员在61天内就会发生新的交通违章。曲线在中间阶段的斜率逐渐变小,当累积生存率接近20%时,曲线变得很平缓,表明约20%驾驶员的违章间隔时间超过1年,亦即20%的驾驶员在1年甚至更长时间内都不会发生新的违章。
相比于传统回归方法,基于持续时间模型的驾驶员违章间隔时间估计方法的一大优点是能有效处理删失数据。针对删失数据,若不考虑删失数据或者直接把其当作完全数据处理都是不恰当的。图1也给出了针对删失数据进行不同处理方式时,驾驶员违章间隔时间生存函数(累积生存率)的差异。从图中可以看出三条曲线存在明显的差异,不考虑删失数据的曲线下降最快,其次是将删失数据作为完全数据处理的情况。说明相同的时间下,两种不当的处理方式,累积生存率(持续不发生违章的概率)都明显低于正确处理删失数据的实际值,亦即这两种对删失数据的不当处理方式都会导致显著高估驾驶员的违章风险。
3.运用违章间隔时间样本数据对cox比例风险模型进行拟合,估计cox比例风险模型参数,分析违章间隔时间的潜在影响因素
运用上述291个违章间隔时间样本数据,拟合驾驶员违章间隔时间cox比例风险模型,cox比例风险模型拟合的参数估计结果如表2所示。
表2.违章间隔时间cox比例风险模型的参数估计结果
需要说明的是,车辆类型有三种,为三分类变量,在模型估计的具体操作时,需要将其转换为两个0-1虚拟变量car(1)和car(2)。由于车辆类型是由这两个0-1虚拟变量共同表示,因此在模型估计结果中两个虚拟变量只要有一个显著时,两个0-1虚拟变量就需要都保留在最终的模型中。
取显著性水平为0.10,从表2可知,根据p值,在违章间隔时间cox比例风险模型的潜在影响因素中,驾驶员的驾龄(dyear)、车辆类型(car(1)、car(2))和上一年违章次数(vtime)等对违章间隔时间有显著影响。表2还给出了潜在影响因素的回归参数估计值
根据表2,对显著影响因素的分析如下:
(1)驾驶员的驾龄(dyear)对驾驶员违章间隔时间有显著影响。根据表2,驾龄的回归参数估计值为正值,表明随着驾龄的增大,驾驶员的违章风险增大,违章间隔时间会越短。这可能是早期的驾驶培训考核要求较松,导致部分老驾驶员没有养成良好的安全驾驶习惯,违章行为相对较多。根据表2最后一列的数据可知,驾驶员的驾龄增加1年,发生违章事件的风险(影响程度)增加2.7%。
(2)车辆类型(car(1)、car(2))对驾驶员违章间隔时间有显著影响。表2中,car(1)的回归参数估计值为负值,对应p值为0.025,表明客车的违章风险比小汽车更低,亦即客车的违章间隔时间更长。对应的
(3)上一年违章次数(vtime)对驾驶员违章间隔时间有显著影响。上一年违章次数的回归参数估计值为正值,表明上一年违章次数越多的驾驶员,其违章风险越大,违章间隔时间越短。驾驶员的上一年违章次数增加1次,违章风险增加5.3%。
4.估计基准生存函数,得到违章间隔时间累积生存率的估计值
上一步得到cox比例风险模型回归参数β的估计后,再运用公式(9)估计违章间隔时间的基准生存函数s0(t)。基于案例数据,可得到随时间变化,基准生存函数(基准累积生存率)取值变化曲线如图2所示。
此外,图3给出了运用cox比例风险模型的估计结果与运用非参数方法的估计结果的比较,从图3可知,两种方法的估计结果非常接近,表明本专利构建的考虑潜在影响因素的驾驶员违章间隔时间cox比例风险模型的有效可靠性。
根据s0(t)的估计值和cox比例风险模型回归参数β的估计值,先给定一个驾驶员的个人、车辆属性和历史违章数据等协变量x的值,再将x的值代入公式(10),便可计算出这一驾驶员在任意时间的违章间隔时间累积生存率的估计值。例如,以表1中第一个违章间隔时间样本为例,估计这个驾驶员在前一次违章之后的第20天,仍没有发生新违章的概率,亦即其累积生存率
基于案例数据,根据公式(9)可得到
5.估计驾驶员发生违章的风险
根据公式(15),可以计算出驾驶员在上一次违章发生之后,后续每个时间段内发生新违章的风险概率。仍以表1中第一个样本为例,若要估计这一驾驶员在上一次违章发生之后的接下来10天,即接下来的区间[0,10)天的区间内,会发生违章的概率(即发生违章事件的风险概率),根据公式(15),可知这一风险概率为
类似公式(17)的计算过程可得到,
类似地,可计算他在前20天,即区间[0,20)天的区间内,会发生新的违章的风险概率如式(19)计算所示,
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
本说明书中未做详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!