一种大矩阵快速转置多核并行处理方法与流程
本发明属于图像信号处理领域。
背景技术:
图像中含有丰富的信息,雷达成像已经成为获取地面细节信息的重要来源。雷达成像需处理由距离向、方位向构成的二维矩阵数据,尤其是高分辨率雷达的矩阵行列数较大。为了获取更多的信息,信号处理算法需要处理的数据量越来越大;同时为了保证处理实时性,信号处理平台的计算能力也在不断扩大。
目前,在弹载高实时性要求的场景下,多核处理器已经成为提高信号处理算力的主要解决方案,n个内核的处理耗时可达1个内核的1/n。但是外部资源的限制,多核在实际使用时需要串行排队等待资源,大大降低了多核的工作效率。因此,最大限度减少外部资源冲突限制,达到多核并行比最大化,已经成为一个热门的攻关方向。
例如:tms320c667x是ti公司开发的多核高性能dsp(digitalsignalprocessing数字信号处理技术)芯片,是图像信号处理中比较常用的芯片,其工作主频最大能达1.2ghz,拥有丰富的srio、pcie等高速外部接口,以及增强型直接内存读取edma模块,为大运算量、高实时性要求的雷达成像提供了可能。雷达成像所需的二维矩阵数据由于较大,只能存储于外部存取速度较慢的大存储器中(如ddr等)。ti提供两种矩阵转置的方案,第一种为cpu使用优化的内联函数直接转置,另一种为edma(enhanceddirectmemoryaccess,增强型直接内存访问)转置。如果使用cpu进行矩阵转置,由于外部存储器中存取数据速度慢cpu高速处理受限,导致转置耗时长;如果使用edma进行矩阵转置,由于外部大存储器内单个数据跳读或者跳写操作效率很低,会严重降低edma执行速度,导致转置时间长。
技术实现要素:
针对现有技术数据处理实时性不能满足要求的问题,本发明提供一种大矩阵快速转置多核并行处理方法,提高了数据处理速度。
本发明一种大矩阵快速转置多核并行处理方法,包括以下步骤:
步骤一:dsp每个内核利用edma将外部大存储器中需处理子矩阵ai(n,m),i∈[0,x-1]搬移至sram缓存;
步骤二、x个内核并行处理,cpu利用优化的内联函数,对缓存数据进行转置,得到aτi(n,m),i∈[0,x-1],再通过edma将结果数据搬移至外部大存储器;
所述ai(n,m),i∈[0,x-1]为每个内核需处理一个子矩阵,由雷达成像所需x*n个距离向点数、m个方位向点数构成的大复数矩阵a(x*n,m)为
a(x*n,m)=[a0(n,m);a1(n,m);...;ax-1(n,m)]
共x*n行,m列,每个复数由1个浮点数实部,1个浮点数虚部构成,将a(x*n,m)从行向均分为x块ai(n,m),i∈[0,x-1];
所述转置结果aτ(x*n,m)为
aτ(x*n,m)=[aτ0(n,m),aτ1(n,m),...,aτx-1(n,m)]
n为距离向点数、m为方位向点数。
进一步,所述每个内核将ai(n,m),i∈[0,x-1]再细分为p*q个小矩阵ai,(p,q),p∈[0,n/blockrow-1],q∈[0,m/blockcol-1],其中,blockrow为每个小矩阵的行数,blockcol为每个小矩阵的列数,p=n/blockrow,q=m/blockcol。
本发明的有益效果在于通过多核并行转置算法实现理论并行处理设计,然后利用cpu高速处理、edma直接内存读取的特点,同时合理分配总线传输带宽以及内核处理时间,对达到每个cpu内核可视为并行全速进行转置处理的效果,大大减少了串行开销,提高了多核并行比。该方法相比传统单一的cpu转置快十几倍,比单一的edma转置快7倍,8核处理并行比达6.723。
附图说明
图1:本发明的示意图。
具体实施方式
下面结合附图对本发明作详细的说明。
本实施例利用大矩阵转置模块进行多核并行处理算法设计;采用ti公司的tms320c667x系列多核芯片进行具体实现,将信号处理算法分解至n个内核并行处理,将芯片资源进行多核并行比最大化的优化。
一、本实施例的技术方案
本实施例包括以下步骤:
步骤一、将雷达成像数据进行多核并行矩阵转置
雷达成像需处理由x*n个距离向点数、m个方位向点数构成的大复数矩阵a(x*n,m)(x*n为矩阵行数,m为矩阵列数)。一般来说,每个复数点由1个浮点数实部,1个浮点数虚部构成,因此大复数矩阵a(x*n,m)总数据量大小为x*n*m*8byte。将a(x*n,m)从行向均分为x块,每个内核需处理一个子矩阵ai(n,m),i∈[0,x-1],如下公式(1):
a(x*n,m)=[a0(n,m);a1(n,m);...;ax-1(n,m)](1)
按照分块矩阵原理,x核并行处理大矩阵a(x*n,m)的矩阵转置公式如下(2),每个内核针对处理得到一个子矩阵aτi(n,m),i∈[0,x-1],从而实现x个内核并行处理得到最终转置结果aτ(x*n,m)的效果。
aτ(x*n,m)=[aτ0(n,m),aτ1(n,m),...,aτx-1(n,m)](2)
以ti公司的8核tms320c6678dsp芯片为例,x为8。
步骤二、cpu+edma协同处理
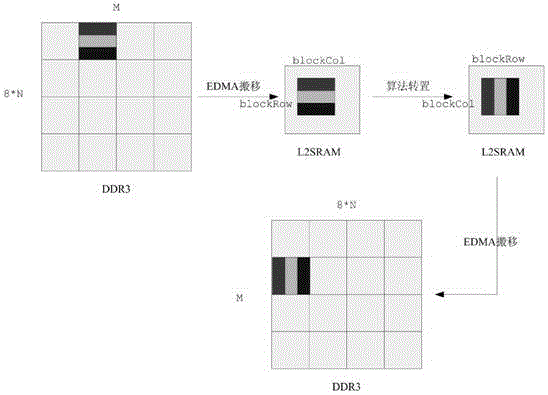
tms320c667x芯片每个内核有数据读取速率与cpu主频接近的l2sram,可最大限度的发挥cpu的运算速率。每个内核利用edma高速数据传输能力,将外部大存储器中需处理子矩阵ai(n,m),i∈[0,x-1]搬移至l2sram缓存。cpu利用优化的内联函数,直接操作l2sram缓存数据进行转置,再通过edma将结果数据搬移至外部大存储器中的目的地址得到aτi(n,m),i∈[0,x-1],即可实现cpu+edma协同处理的快速矩阵转置。
如果数据量比较大,ai(n,m),i∈[0,x-1]相对l2sram内存而言仍然较大,cpu不能一次完成转置操作。因此,再次利用分块转置原理,每个内核将ai(n,m),i∈[0,x-1]再细分为p*q个小矩阵ai,(p,q),p∈[0,n/blockrow-1],q∈[0,m/blockcol-1],其中,blockrow为每个小矩阵的行数,blockcol为每个小矩阵的列数,p=n/blockrow,q=m/blockcol。
由于外部大存储器没有多通道接口,每个内核通过edma存取数据时,需要串行等待;由于此时cpu正在进行小矩阵的转置处理,edma存取数据时间被视为后台等待时间,p*q个小矩阵流水处理后,每个cpu内核可视为并行全速进行转置处理,大大减少了串行开销,提高了多核并行比。
二、cpu+edma协同处理实现方法
雷达成像所需的大复数矩阵a(x*n,m)在外部大存储器的起始地址为srcaddr,每个内核处理原始数据的起始地址为srcaddr+i*n*m*8,i∈[0,x-1]。每个内核细分的小矩阵的起始地址为srcaddr+i*n*m*8+p*blockcol*8(i∈[0,x-1],p∈[0,n/blockrow-1]),利用edma将每个小矩阵快速搬移至l2sram缓存中。搬移完成后,cpu调用优化的内联函数,直接操作该缓存数据进行转置。
转置后目的矩阵aτ(x*n,m)在外部大存储器的起始地址为dstaddr,则每个内核处理结果数据存储的起始地址为dstaddr+i*n*8,i∈[0,x-1]。每个内核细分的小矩阵转置后存储的起始地址为dstaddr+i*n*8+q*blockrow*8(i∈[0,x-1],q∈[0,m/blockcol-1]),利用edma将每个转置后的小矩阵搬移至外部大存储器中。
所有内核的小矩阵处理完成后,即完成了大矩阵转置。
三、效率测试
在ti公司的8核处理芯片tms320c6678上实现该大矩阵快速转置多核并行处理方法,并针对单核cpu转置、edma转置、cpu+edma转置效率,单核cpu+edma转置、8核cpu+edma转置进行了对比测试。
表1单核cpu转置、edma转置、cpu+edma转置效率对比
表2单核cpu+edma转置、8核cpu+edma转置对比
通过对比数据可以发现,该方式实现1024*8192复数点矩阵的转置,耗时为24ms,cpu+edma转置比传统单一的cpu转置快十几倍,比单一的edma转置快5倍。同时8核cpu+edma转置处理的多核并行比达6.723。
上述具体实施方式仅用于解释和说明本发明的技术方案,但并不构成对权利要求保护范围的限定。本领域的技术人员应当清楚,在本发明的技术方案基础上做任何简单的变形或替代而得到的新的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!