多长度哈希联合学习方法与流程
本发明涉及一种多长度哈希联合学习方法,属于多媒体信号处理、大数据检索技术领域。
背景技术:
随着互联网的普及,社交网络、分享网站等网络平台极大地促进了可视媒体的发布、传播和获取。特别是随着网络带宽的不断增大和智能移动设备的普及,图像和视频等可视媒体逐渐成为网络用户获取信息的主要方式,互联网和传统媒体的融合也进一步促进了图像和视频等可视媒体数据的爆炸性增长,但同时也使得大量内容相似或重复的图像和视频等可视媒体充斥网络,对互联网内容提供商来说,过滤此类“垃圾内容”或对搜索到的相似内容进行重排序,让用户从海量数据中快速检测到对自己有用或喜欢的可视媒体内容非常必要。同时,根据用户搜索或观看的可视媒体内容进行个性化推荐,也是互联网企业的重要业务。另外,可视媒体的广泛传播在丰富人们文化娱乐生活的同时,也为暴力恐怖、淫秽色情、谣言等有害信息的传播提供了便利,这些有害图像和视频极大地危害了社会稳定和政府公信力[1],淫秽图片或视频更是影响青少年的身心健康,因此,对此类有害可视媒体内容的检测和过滤也十分必要。
哈希学习是解决可视媒体内容检索和过滤问题的一个可行技术,哈希学习是利用机器学习等工具和算法把原始高维内容特征转化为二值的哈希序列,实现在互联网和数据库中相似内容的快速搜索和检测。在学习和转化的过程中,哈希学习尽可能保持原始空间中相似内容的相似性和不同内容的区分性,近年来受到学术界和工业届的广泛关注。
现有的哈希学习算法,主要通过设计目标函数,通过优化学习得到固定长度的哈希序列。但是,不同长度的哈希是对原始数据的多角度表示,因此,根据多视图分析理论,有效利用多长度哈希之间关系对于提高哈希检索精度非常重要。
技术实现要素:
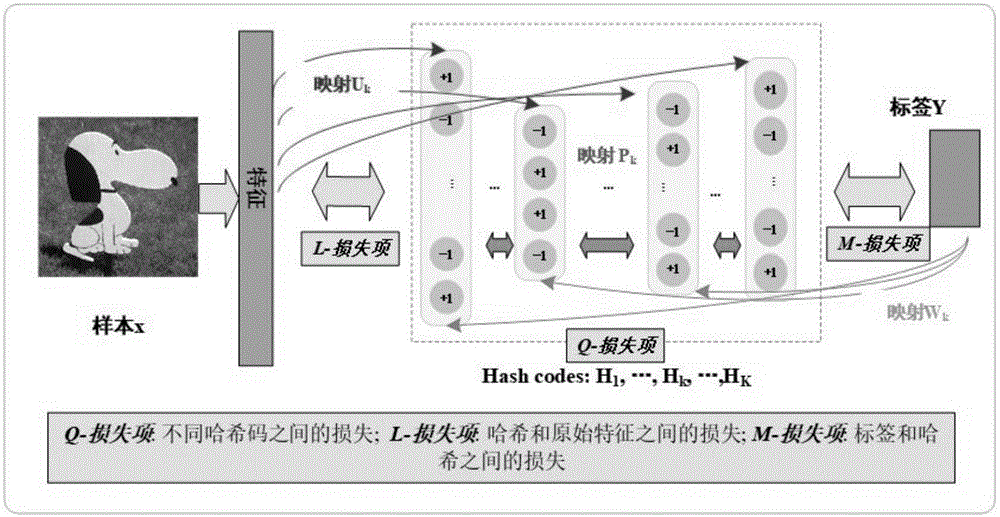
本发明提出了一种多长度哈希的联合优化学习方法。本发明的哈希学习模型在利用数据的原始特征的基础上,设置不同长度的多个哈希层,通过联合优化,充分利用了多长度哈希之间的互助关系,提升了哈希学习的性能。与现有哈希技术相比,本发明可以同时学习得到针对一个样本的多个哈希序列,提高了利用哈希技术进行大数据检索的效率和精确性。现有的文献和技术中,并没有出现多个哈希联合优化的技术和方法。
本发明采用的技术方案为:
一种多长度哈希联合学习方法,其特征在于该方法包括以下步骤:
(1)原始数据特征提取:提取原始样本特征,所述原始样本特征可以是人工定义的特征或通过深度学习得到的深度特征;
(2)多长度哈希联合学习,具体步骤为:
①建立多长度哈希相互映射关系,得到总体目标函数中关于各个长度哈希之间相互映射关系的损失项;
②建立多长度哈希与原始样本特征之间的映射关系,得到总体目标函数中关于各个长度哈希分别与原始样本特征之间相互关系的损失项;
③监督信息或无监督信息利用,对监督模型来说,建立多长度哈希与样本标记之间映射关系,得到总体目标函数中关于各个长度哈希分别与样本标记之间相互关系的损失项;对无监督模型来说,设置多长度哈希相似性保持项;
④通过联合优化学习,得到样本的多长度哈希表示。
优选地,对各种映射关系进行建模时采用线性映射,得到总体目标函数如下:
其中,
优选地,建立所述多长度哈希相互映射关系时,可以采用核化或非线性模型。
优选地,建立所述多长度哈希与原始样本特征之间的映射关系时,可以采用核化或非线性模型。
优选地,建立所述多长度哈希与样本标记之间映射关系时,可以采用核化或非线性模型。
优选地,步骤(1)中,所述人工定义的特征包括颜色、纹理和特征点。
本发明实现了多长度哈希的联合学习,充分利用了同一样本不同哈希之间的相互关系,提高了哈希检索的性能。
附图说明
图1是本发明方法示意框图。
具体实施方式
下面结合附图对本发明加以详细的说明。
本发明的方法按图1所示流程,包括如下具体步骤:
(1)特征提取
在特征提取阶段,根据实际的应用需要,可以由两类特征可用
①人工定义特征提取。可以提取例如颜色、纹理、全局特征点、局部特征点等;
②深度语义特征。可以利用现有的深度学习模型提取深度语义特征;
(3)多长度哈希联合学习:基于样本原始特征、多长度哈希关系、样本标记信息(监督的)或样本相似性保持(无监督的)来建立多长度哈希联合优化目标函数,通过优化目标函数获取多长度哈希表示,本发明以线性映射为例,提出一个优化问题如下:
其中,
表1是本发明方法的一个仿真实验,该实验采用map(平均准确率)进行度量,在cifar-10,ms-coco、nus-wide三个常用数据库上进行实验。
表1本发明于其他算法map性能比较
- 还没有人留言评论。精彩留言会获得点赞!