基于分组扩张卷积神经网络模型的目标检测方法及装置与流程
本发明属于计算机视觉、人工智能技术领域,涉及一种复杂场景下的目标检测方法及装置,具体涉及一种基于分组扩张卷积神经网络模型的目标检测方法及装置。
背景技术:
在当前机器学习技术及计算机硬件性能高速提升的情况下,近年来计算机视觉、自然语言处理和语音检测等应用领域取得了突破性进展。目标检测作为计算机视觉领域一项基础的任务,其精度也得到了大幅提升。
目标检测任务可分为两个关键的子任务:目标分类和目标定位。
其中,目标分类任务负责判断输入图像中是否有感兴趣类别的物体出现,其输出一系列带分数的标签,用来表明感兴趣类别的物体出现在输入图像中的可能性;目标定位任务负责确定输入图像中感兴趣类别的物体的位置和范围,输出物体的包围盒,或物体中心,或物体的闭合边界等,通常方形包围盒是最常用的选择。
目标检测对计算机视觉领域和实际应用具有重要意义,在过去几十年里激励大批研究人员密切关注并投入研究。随着强劲的机器学习理论和特征分析技术的发展,近十几年目标检测课题相关的研究活动有增无减,每年都有最新的研究成果和实际应用发表和公布。不仅如此,目标检测也被应用到很多实际任务,例如智能视频监控、基于内容的图像检索、机器人导航和增强现实等。然而,现有技术的多种目标检测方法的检测准确率仍然较低而不能应用于实际通用的检测任务。因此,目标检测还远未被完美解决,仍旧是重要的挑战性的研究课题。
为了提高目标检测的准确率,目前常用的方法是增加检测模型训练时的训练数据。然而,一方面,收集大量的训练数据是一件极其困难的工作,另一方面,训练数据量增多也导致模型训练时间延长,甚至有可能然后训练无法实际完成。
技术实现要素:
为解决上述问题,提供一种结构简单、训练消耗少的目标检测方法及装置,本发明提出了一种利用特征融合来提高检测精度的新型的卷积神经网络模型,即分组扩张卷积神经网络模型。进一步,本发明提出了基于该分组扩张卷积神经网络模型的检测方法和装置,技术方案如下:
本发明提供了一种基于分组扩张卷积神经网络模型的目标检测方法,其特征在于,采用基于分组扩张卷积神经网络模型从待测图像中检测出目标物体的位置及类别,包括如下步骤:
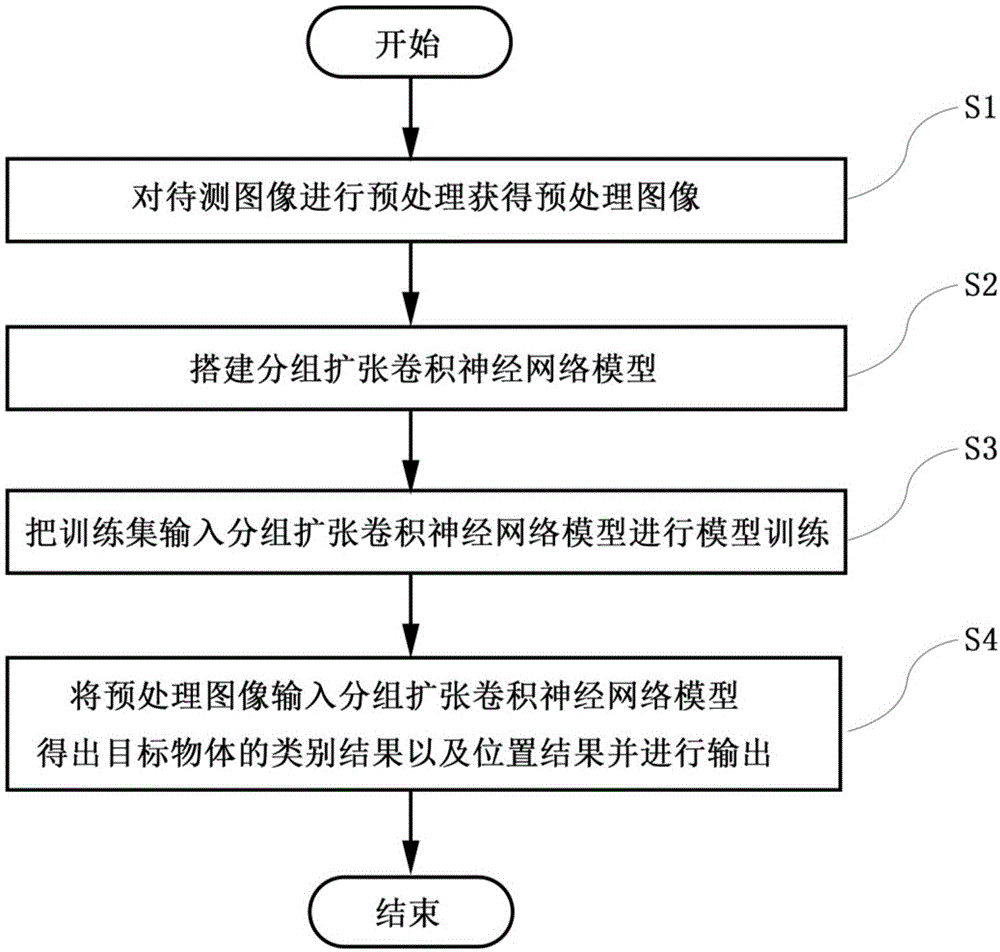
步骤s1,对待测图像进行预处理获得预处理图像;
步骤s2,搭建分组扩张卷积神经网络模型;
步骤s3,把包含多张训练图像的训练集输入搭建好的分组扩张卷积神经网络模型从而进行模型训练;
步骤s4,将预处理图像输入训练完成的分组扩张卷积神经网络模型,从而让训练完成的分组扩张卷积神经网络模型得出预处理图像中的目标物体的位置及类别,
其中,分组扩张卷积神经网络模型具有多个残差结构以及至少一个第一特征融合层,第一特征融合层由多个残差结构中的一部分分别经上下采样后连接得到,并被归一化到相同的特征空间。
本发明提供的基于分组扩张卷积神经网络模型的目标检测方法,还可以具有这样的技术特征,其中,分组扩张卷积神经网络模型还包括至少一个第二特征融合层,该第二特征融合层由多个残差结构中的另一部分以及第一特征融合层分别经上下采样后连接得到,并被归一化到相同的特征空间。
本发明提供的基于分组扩张卷积神经网络模型的目标检测方法,还可以具有这样的技术特征,其中,待测图像为待测视频,步骤s1的预处理包括从待测视频中抽取多个图像帧。
本发明提供的基于分组扩张卷积神经网络模型的目标检测方法,还可以具有这样的技术特征,其中,图像帧的抽取方式为按视频序列每三帧抽取一帧。
本发明提供的基于分组扩张卷积神经网络模型的目标检测方法,还可以具有这样的技术特征,其中,步骤s1的预处理还包括将抽取得到的图像帧进行大小归一化。
本发明提供的基于分组扩张卷积神经网络模型的目标检测方法,还可以具有这样的技术特征,其中,步骤s3包括如下步骤:
步骤s3-2,构建分组扩张卷积神经网络模型,其包含的模型参数为随机设置;
步骤s3-3,将训练集中的各个训练图像依次输入构建好的分组扩张卷积神经网络模型并进行一次迭代;
步骤s3-4,迭代后,采用最后一层的模型参数分别计算出损失误差,然后将计算得到的损失误差反向传播,从而更新模型参数;
步骤s3-5,重复步骤s3-3至步骤s3-4直至达到训练完成条件,得到训练后的分组扩张卷积神经网络模型。
本发明还提供了一种基于分组扩张卷积神经网络模型的目标检测装置,其特征在于,采用基于分组扩张卷积神经网络模型从待测图像中检测出目标物体的位置及类别,包括:预处理部,对待测图像进行预处理获得预处理图像;目标检测部,从待测图像中检测出目标物体的位置及类别,该目标检测部包含一个训练好的分组扩张卷积神经网络模型,其中,分组扩张卷积神经网络模型具有多个残差结构以及至少一个第一特征融合层,第一特征融合层由多个残差结构中的一部分分别经上下采样后连接得到,并被归一化到相同的特征空间。
发明作用与效果
根据本发明实施例提供的基于分组扩张卷积神经网络模型的目标检测方法及装置,由于采用具有第一特征融合层的分组扩张卷积神经网络模型作为检测模型,该检测模型的第一特征融合层能够融合神经网络中的不同特征层,因此,此模型能够学习到更多的特征,更好地进行特征表达,更加适合小目标及遮挡目标检测任务,能够最终提高目标检测的精度。另外,该模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法,因此,与现有的高精度模型相比,本实施例的模型构建快速方便,且训练过程所消耗的计算量也较小。
附图说明
图1是本发明实施例中基于分组扩张卷积神经网络模型的目标检测方法的流程图;
图2是本发明实施例的分组扩张卷积神经网络模型的结构示意图;
图3是本发明实施例的残差网络层结构图。
具体实施方式
本实施例采用的数据集为ua-detrac。ua-detrac是一个具有挑战性的真实世界多对象检测和多对象跟踪基准,该数据集包括在中国北京和天津的24个不同地点使用cannoneos550d摄像机拍摄的10小时的视频。录像以每秒25帧(fps)录制,分辨率为960×540像素。ua-detrac数据集中有超过14万个图像帧,手动标注了8250个车辆,总计有121万个标记的物体边界框。
另外,本实施例实现的硬件平台需要一张nvidiatitanx显卡(gpu加速)。
本实施例首先对数据集图片进行预处理,然后训练分组扩张卷积神经网络模型,最后通过分组扩张卷积神经网络模型得到目标物体的位置和类别。具体包括4个过程:预处理、搭建模型、训练模型及目标检测。
以下结合附图以及实施例来说明本发明的具体实施方式。
<实施例>
图1是本发明实施例中基于分组扩张卷积神经网络模型的目标检测方法的流程图。
如图1所示,本发明的基于分组扩张卷积神经网络模型的目标检测方法包括如下步骤。
步骤s1,对待测图像进行预处理获得预处理图像。
本实施例中,待测图像为包含了检测目标的视频(例如,道路监控视频等)。预处理过程如下:首先,将待测视频序列(即视频的各个图像帧的时间顺序)每三帧抽取一帧得到多个图像帧,因为帧间差距不大,这样处理可以增加数据集迭代的epoch;然后,将抽取得到的各个图像帧进行水平翻转从而实现数据扩充;最后,将抽取得到以及翻转得到的各个图像帧大小归一化至960x540(即960像素乘540像素),得到预处理图像。
本实施例的上述过程中,抽取图像帧是针对待测图像为视频的情况而进行的;水平翻转是为了增加获取的图像数量,实现数据扩充从而让从待测图像中获取的数据量更为丰富,进而增加迭代的epoch。在其他实施例中,待测图像也可以是单张图像(例如照片等),这种情况下不需要进行图像帧的抽取操作。另外,在其他实施例中也可以不对图像帧进行水平翻转,或者采用其他的现有技术中的数据扩充方式(例如垂直翻转、水平翻转与垂直翻转结合等)。
步骤s2,搭建分组扩张卷积神经网络模型。
首先,利用现有的深度学习框架caffe,搭建分组扩张卷积神经网络模型。该分组扩张卷积神经网络模型是基于分组的特征融合的卷积神经网络模型,主要可以分为两个模块,一是目标框提取子网络,一是目标位置预测和类别预测子网络。其中,目标框提取子网络用于搭建分组的特征融合网络结构,能够更好的提取目标特征信息,目标位置预测和类别预测子网络用于对输入目标的特征进行位置回归预测和分类预测。
具体地,本实施例的模型由残差网络结构(卷积层)、下采样层以及上采样层组成,其中残差网络结构由两路数据(一路是若干个卷积层级联的数据和一路原始数据)相加求和构成,并且网络结构中每一个卷积层之后都做批量归一化(batchnormalization)操作。
以下结合附图说明本实施例的分组扩张卷积神经网络模型的具体结构。
图2是本发明实施例的分组扩张卷积神经网络模型的结构示意图。
如图2所示,本发明的分组扩张卷积神经网络模型包括依次设置的输入层i、残差结构c1、残差结构c2、残差结构c3、残差结构c4、残差结构c5、上采样层、下采样层、第一特征融合层ch、第二特征融合层cl、卷积层fcn_cls、卷积层fcn_bbox、位置敏感roi池化层、下采样层2-d、下采样层8-d。其中,残差层由两路数据(一路是若干个卷积层级联的数据和一路原始数据)相加求和构成。
图3是本发明实施例的残差网络层结构图。
如图3所示,分组扩张卷积神经网络模型的残差结构中,每一个卷积层之后都做批量归一化(batchnormalization)操作。
如图2所示,分组扩张卷积神经网络模型具体包括如下结构:
(1)输入层i,用于输入各个经过预处理的图像帧,其大小与归一化后的图像帧的大小相对应,为960×540×3;
(2)多个残差结构,包括残差结构c1(卷积核大小为3×3,滑动步长为1,填充为0,输出为480×270×64)、残差结构c2(卷积核大小为3×3,滑动步长为1,填充为0,输出为240×135×128)、残差结构c3(卷积核大小为3×3,滑动步长为1,填充为0,输出为120×68×256)、残差结构c4(卷积核大小为3×3,滑动步长为1,填充为0,输出为60×34×512)、残差结构c5(卷积核大小为3×3,滑动步长为1,填充为0,输出为60×34×512);
(3)下采样层以及上采样层,其中下采样层包括残差结构c3的下采样和残差结构c1的下采样,该两个残差结构的步长均为2,上采样层包括步长为1的残差结构c5的上采样和步长为4的特征融合层ch上采样;
(4)第一特征融合层ch,由残差结构c3、残差结构c4、残差结构c5分别经上下采样后连接得到,归一化到相同的特征空间;
(5)第二特征融合层cl,由残差结构c1、残差结构c2、第一特征融合层ch分别经上下采样后连接得到,归一化到相同的特征空间;
(6)多个卷积层,包括卷积层fcn_cls(卷积核大小为3×3,滑动步长为1,填充为0,输出为60×34×98)、卷积层fcn_bbox(卷积核大小为3×3,滑动步长为1,填充为0,输出为60×34×392);
(7)位置敏感roi池化层,用于获取目标物体的位置信息,其中,卷积层fcn_cls经过位置敏感roi池化层的输出为7×7×2,卷积层fcn_bbox经过位置敏感roi池化层的输出为7×7×8;
(8)下采样层2-d,用于进行池化操作,步长为2,其特征向量作为目标框类别(即该层的特征向量表示目标物体的物体类别);
(9)下采样层8-d,用于进行池化操作,步长为2,其特征向量作为目标框位置(即该层的特征向量表示目标物体在待测图像中的坐标位置)。
步骤s3,把训练数据输入搭建好的分组扩张卷积神经网络模型,从而进行模型训练。
本实施例采用车辆数据集detrac作为训练数据。采用与步骤s1相同的方法,从该数据集中获得了包含8250辆车的8万张图像;将这些图像做水平翻转操作,以实现数据增强,然后再进行归一化处理,得到的多张图像即为本实施例的训练集。
上述训练集中的图像分批次进入网络模型进行训练,每次进入网络模型的训练图像批次大小为2,一共迭代训练9万次。
本实施例的分组扩张卷积神经网络模型的各层包含不同的模型参数,这些模型参数构建时为随机设置。
模型训练过程中,每次迭代(即训练集图像通过模型)后,最后一层的模型参数分别计算出损失误差(softmaxloss交叉熵损失,squareloss平方差损失),然后将计算得到的损失误差(softmaxloss,squareloss)反向传播,从而更新模型参数。另外,模型训练的训练完成条件与常规的卷积神经网络模型相同,即,各层的模型参数收敛后就完成训练。
经过上述迭代训练并在迭代过程中进行误差计算和反向传播的过程,即可获得训练完成的分组扩张卷积神经网络模型。本实施例用该训练完成的模型在复杂场景下进行车辆检测。
步骤s4,将经过预处理得到的预处理图像输入训练完成的分组扩张卷积神经网络模型,从而通过该模型得出各个预处理图像中的目标物体的类别结果以及位置结果并进行输出。其中,预处理图像通过了分组扩张卷积神经网络模型得到对应特征向量,然后根据该特征向量,通过回归算法即可计算出目标物体的位置和类别。
本实施例中采用detrac测试集作为待测图像来对本实施例的模型进行测试,其中目标物体就是车辆。
具体过程为:利用ua-detrac团队提供的测试代码,对其数据集中的多个视频进行如步骤s1所描述的预处理,得到6万张车辆图像(即预处理后的预处理图像)作为测试集,依次输入训练好的分组扩张卷积神经网络模型,取下采样层2-d的特征向量作为目标框类别,下采样层8-d特征向量作为目标框位置,通过回归算法进行计算,最终得到目标物体(即图中的车辆)的位置及类别。
本实施例中,训练好的分组扩张卷积神经网络模型对该测试集的车辆检测overall检测精度(即检测准确率)为71.56%。
发明人还采用现有技术中的其他物体检测模型对同样的测试集进行了对比测试,结果如下表1所示。
表1本发明的方法以及现有技术的其他方法在detrac评测集上车辆检测准确率的对比测试结果
表1中,dpm、acf、r-cnn、faster-rcnn、compact、eb为现有技术中常见检测准确率较高的几种模型。另外,fullset代表总体检测准确率,easy、medium、hard分别表示不同检测难度的目标物体的检测准确率(即easy指低难度,medium指中等难度,hard指高难度);cloudy、night、rainy、sunny分别代表模型对不同的环境的待识别图像(即,待识别对象在不同的天气环境或光线环境下拍摄获得,因此其背景呈现为不同的环境)中目标物体的识别准确,cloudy、night、rainy和sunny分别表示多云、夜晚、雨天和晴天。
上述测试过程表面,本实施例的基于分组扩张卷积神经网络模型的目标检测方法能够在detrac数据集上取得很高的准确率。
实施例作用与效果
根据本发明实施例提供的基于分组扩张卷积神经网络模型的目标检测方法,由于采用具有第一特征融合层和第二特征融合层的分组扩张卷积神经网络模型作为检测模型,该检测模型的第一特征融合层和第二特征融合层能够很好地融合神经网络中的不同特征层,因此,此模型能够学习到更多的特征,更好地进行特征表达,更加适合小目标及遮挡目标检测任务,能够最终提高目标检测的精度。
表1的结果也可以证明,相比于传统的计算机视觉方法,本实施例的方法大幅提升了目标检测的准确率,在不同检测难度、不同检测环境下均具有良好的检测精度,尤其是在复杂场景中精度更好。
另外,本实施例的模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法,因此,与现有的高精度模型相比,本实施例的模型构建快速方便,训练集也不需要过多数据就能够实现训练,因此训练过程可以快速完成,且训练消耗的计算资源也较少。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
例如,上述实施例提供了一种基于分组扩张卷积神经网络模型的目标检测方法,该方法主要包括预处理、搭建模型、训练模型及目标检测的步骤。然而,为了实际使用时更为方便,本发明中的训练好的模型也可以打包形成一个目标检测部,该目标检测部可以与用于对待测图像进行预处理的预处理部构成基于分组扩张卷积神经网络模型的目标检测装置,使得待测图像经过预处理部处理后由训练好的分组扩张卷积神经网络模型检测出目标物体的类别和位置。
另外,上述实施例中,分组扩张卷积神经网络模型具有两种特征融合层,其中第一特征融合层由多个残差结构分别经上下采样后连接得到,第二特征融合层由第一特征融合层与多个其他残差结构分别经上下采样后连接得到,因此,该两种特征融合层分别相当于低层特征融合层和高层特征融合层。在本发明中,为了精简模型结构,也可以仅设置第一特征融合层(即去掉第二特征融合层),这种精简方式的不足之处在于,模型精度会因特征融合的减少而降低。
实施例中,第一特征融合层和第二特征融合层分别只有一层。但在本发明中,也可以设置多个第一特征融合层和/或多个第二特征融合层,只要满足其特征融合方式(第一特征融合层由多个残差结构分别经上下采样后连接得到,第二特征融合层由一个或多个第一特征融合层与多个其他残差结构分别经上下采样后连接得到)即可。这种设置多个特征融合层的方式将使模型结构更复杂,消耗较多计算资源,但精度会较实施例进一步提高。
- 还没有人留言评论。精彩留言会获得点赞!