SQL语句归类方法、装置、计算机设备和存储介质与流程
本申请涉及数据处理技术领域,尤其涉及一种sql语句归类方法、装置、计算机设备和存储介质。
背景技术:
抓取结构化查询语言sql并对其进行优化是数据库审计平台需要实现的一项主要功能。在数据库中,每一条sql语句都有唯一的sql_id,但是不同sql_id的sql语句可能执行相同的功能。审计平台在审计出问题sql语句时,需要对问题sql语句进行优化,但与问题sql语句具有相同功能的其他sql语句也很有可能出现同样的问题。如果可以将执行相同功能的所有sql语句进行归类,那么在优化时可以直接根据问题sql语句对应的类别,便可找到具有相同功能的所有sql语句,然后进行统一优化,从而大大提高sql语句的优化效率,从而提升数据库的稳定性。
目前,在对sql语句进行归类时大都采用文本归类算法进行归类,其需要抽取每条sql语句的完整文本,并且对文本的书写习惯有着统一性的要求。但是,由于两个功能相同的sql语句可能存在着书写规则不一致的问题,此时则无法快速将sql语句进行归类。
技术实现要素:
有鉴于此,有必要针对由于sql语句可能存在着书写规则不一致,导致无法快速将sql语句进行归类的问题,提供一种sql语句归类方法、装置、计算机设备和存储介质。
一种sql语句归类方法,包括如下步骤:
获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表;
过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表;
从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行;
获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称;
将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表。
在其中一个可能的实施例中,所述获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表,包括:
从数据库中抽取sql语句数据,打包所述sql语句数据后生成sql语句数据组,赋予所述sql数据组以时间标记后形成带有时间标记的待归类sql数据组;
从所述带有时间标记的待归类sql数据组中抽取出对象名称字段;
根据所述对象名称字段的首字母和所述时间标记,将所述待归类sql数据组中的sql语句数据依次排列后形成所述待归类sql语句数据基表。
在其中一个可能的实施例中,所述过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表,包括:
抽取所述待归类sql语句数据基表中包含的索引标识和文本语段;
将所述索引标识和所述文本语段与预设的索引规则进行比较,若所述索引标识或所述文本语段中存在与所述索引规则不符的字符,则对所述索引标识或所述文本语段从所述待归类sql语句数据基表中清除,得到修正后的待归类sql语句数据基表。
在其中一个可能的实施例中,所述从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行,包括:
从数据库视图中抽取所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称;
根据所述数据库视图的对象类型,抽取所述sql语句id标识和所述对象名称中所包含的索引字符;
过滤所述索引字符,将过滤后的所述对象名称和所述sql语句id标识导入到所述修正后的待归类sql语言数据基表后得到sql语句建立行。
在其中一个可能的实施例中,所述获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称,包括:
获取与所述sql语句建立行中的行id标识对应的二进制数值,以所述二进制数值为查询对象,从所述修正后的待归类sql语段基表中抽取出包含所述二进制数值的所有sql建立行;
抽取所有所述sql建立行中的对象名称,将所述对象名称按照首字母进行排序后形成对象名称序列;
拼接所述对象名称序列中首字母相同的对象名称后形成所述全对象名称。
在其中一个可能的实施例中,所述将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表,包括:
应用字符串相似度函数计算所述sql语句id标识和所述全对象名称的相似度;
获取预设的相似度阈值,若所述相似度大于所述相似度阈值,则将所述全对象名称和所述sql语句数据归成一类,否则不归成一类;
赋予归类后的所述sql语句数据以类型标识,并将所述类型标识和所述sql语句数据导入到所述修正后的sql语句数据基表形成sql语句分类表。
在其中一个可能的实施例中,所述从数据库中抽取sql语句数据,打包所述sql语句数据后生成sql语句数据组,赋予所述sql数据组以时间标记后形成带有时间标记的待归类sql数据组,包括:
获取预设的频率阈值和所述sql语句数据产生的频率,将所述sql语句数据产生的频率与所述频率阈值进行比较;
当所述sql语句数据产生的频率大于所述频率阈值时,生成定时任务,当所述sql语句数据产生的频率小于所述频率阈值时,等待新的sql语句数据的产生;
触发所述定时任务,将上次定时任务触发后到本次定时任务触发前的所有sql语句数据进行打包;
获取所述定时任务的触发时间节点,以所述时间节点为记号,对打包好的sql语言数据进行标记后得到所述带有时间标记的待归类sql数据组。
一种sql语句归类装置,包括如下模块:
基表建立模块,设置为获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表;
基表过滤模块,设置为过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表;
建立行生成模块,设置为从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行;
全对象名称生成模块,设置为获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称;
分类表建立模块,设置为将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述sql语句归类方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述sql语句归类方法的步骤。
上述sql语句归类方法、装置、计算机设备和存储介质,包括:获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表;过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表;从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行;获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称;将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表。本技术方案通过数据库视图生成sql语句的全对象名称后对sql语句进行精准分类,克服了由于sql书写规则不一致的无法快速对sql语句分类的问题。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。
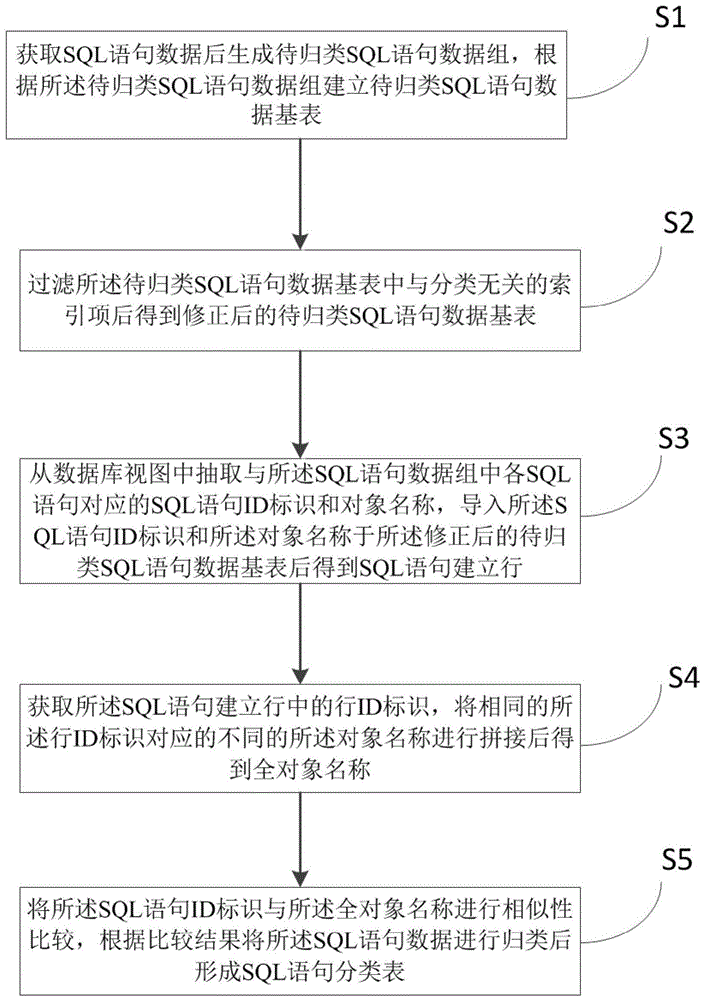
图1为本申请在一个实施例中的一种sql语句归类方法的整体流程图;
图2为本申请在一个实施例中的一种sql语句归类方法中的基表过滤过程示意图;
图3为本申请在一个实施例中的一种sql语句归类方法中的建立行生成过程示意图;
图4为本申请在一个实施例中的一种sql语句归类装置的结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本申请的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
图1为本申请在一个实施例中的一种sql语句归类方法的整体流程图,如图1所示,一种sql语句归类方法,包括以下步骤:
s1,获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表;
具体的,sql语句按照实现的功能不同,主要分为3类:数据操纵语言(dml),数据定义语言(ddl),数据控制语言(dcl)。一般sql语句以流式数据的形式存储在数据库中,在获取sql语句时,可以根据所述sql语句在数据库中的存储位置依次获取,然后根据存储在数据库中的位置信息将数个sql语句打包成一sql语句数据组。
s2,过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表;
具体的,根据所述待归类的sql语句的语句规则,从所述待归类sql语句数据基表中抽取出不符合所述语句规则的索引项,将这些索引项清除后得到修正后的待归类sql语句数据基表。
s3,从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行;
具体的,数据库视图是从一个或多个表或视图导出的表。视图与表不同,视图是一个虚表,即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,在对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表。例如,在oracle数据库中的数据库视图包括dba_hist_sql_text、dba_hist_sql_plan等虚表。
s4,获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称;
具体的,行id标识可以是sql语句建立行中首个sql语句的前三位字符,每一个sql语句建立行都对应一个对象名称,这些对象名称具有行唯一性,即不同建立行对应的对象名称不同。
s5,将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表。
其中,所述sql语句id标识是从dba_hist_sql_text、dba_hist_sql_plan中抽取后得到的。
本实施例,通过建立sql语句分类表,从而使不同书写规则的sql语句能够有效进行分类。
在一个实施例中,所述s1,获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表,包括:
从数据库中抽取sql语句数据,打包所述sql语句数据后生成sql语句数据组,赋予所述sql数据组以时间标记后形成带有时间标记的待归类sql数据组;
具体的,在赋予所述sql数据组以时间标记时,可以根据sql数据组中sql语句的抽取时间作为标记,同时在进行打包时可以将相同的sql语句进行删除,从而保证所述sql数据组中的sql语句各不相同。
从所述带有时间标记的待归类sql数据组中抽取出对象名称字段;
根据所述对象名称字段的首字母和所述时间标记,将所述待归类sql数据组中的sql语句数据依次排列后形成所述待归类sql语句数据基表。
具体的,在所述待归类sql语句基表的第一行为首字母为“a”的sql语句,时间标记为“1”,第二行为首字母为“a”的sql语句,时间标记为“2”,依次类推。
本实施例,通过建立待归类的sql基表,可以使sql语句数据结构化便于进行查找。
图2为本申请在一个实施例中的一种sql语句归类方法中的基表过滤过程示意图,如图所示,所述s2,过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表,包括:
s201、抽取所述待归类sql语句数据基表中包含的索引标识和文本语段;
具体的,获取数据库中的索引标识信息表,将所述待归类sql语句数据基表中的每一行数据与所述索引标识信息表中的索引信息进行比对,若比对一致,则将其抽取,不一致则不抽取。
s202、将所述索引标识和所述文本语段与预设的索引规则进行比较,若所述索引标识或所述文本语段中存在与所述索引规则不符的字符,则对所述索引标识或所述文本语段从所述待归类sql语句数据基表中清除,得到修正后的待归类sql语句数据基表。
具体的,预设的索引规则主要有字符数限制、建立字段选择和单字段排除等。例如,选择的索引规则是字符数限制为3个字符,则在进行比较时,将那些超过3个字符的索引标识进行清除。
本实施例,通过清除无效索引从而提升了sql语句数据基表的查询效率。
图3为本申请在一个实施例中的一种sql语句归类方法中的建立行生成过程示意图,如图所示,所述s3,从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行,包括:
s301、从数据库视图中抽取所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称;
具体的,获取sql语句字符,从所述sql语句字符中抽取对象名称,并获取所述对象名称的赋值;根据所述对象名称的赋值,从所述基表中获取所述对象名称赋值所对应的id标识,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行。
s302、根据所述数据库视图的对象类型,抽取所述sql语句id标识和所述对象名称中所包含的索引字符;
具体的,获取所述对象类型,根据所述对象类型对应的索引类型,抽取出述sql语句id标识和所述对象名称中所包含的索引字符。
s303、过滤所述索引字符,将过滤后的所述对象名称和所述sql语句id标识导入到所述修正后的待归类sql语言数据基表后得到sql语句建立行。
具体的,应用索引识别工具对所述索引字符进行识别后加以清除,对过滤后的sql语句进行核验,检测其是否还含有与分类无关的对象名称,若有则进行清除。
本实施例,通过对索引字符进行有效的清除,从而使sql语句建立行中的sql语句数据更加便于进行检索。
在一个实施例中,所述s4,获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称,包括:
获取与所述sql语句建立行中的行id标识对应的二进制数值,以所述二进制数值为查询对象,从所述修正后的待归类sql语段基表中抽取出包含所述二进制数值的所有sql建立行;
具体的,每一个建立行都具有唯一的行id标识,此标识可以根据建立行的位置赋予,比如第一行的行id标识为“1”,进行二进制转化后的二进制数值仍然为“1”。
抽取所有所述sql建立行中的对象名称,将所述对象名称按照首字母进行排序后形成对象名称序列;
拼接所述对象名称序列中首字母相同的对象名称后形成所述全对象名称。
本实施例,通过生成全对象名称,从而使sql语句归类更加方便快捷。
在一个实施例中,所述s5,将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表,包括:
应用字符串相似度函数计算所述sql语句id标识和所述全对象名称的相似度;
其中,字符串相似度函数可以使用oracle数据库中字符串相似度函数utl_match对所述sql语句进行相似度计算,也可以是使用最短路径算法中的字符串相似度函数对所述sql语句的字符串相似度进行计算。
获取预设的相似度阈值,若所述相似度大于所述相似度阈值,则将所述全对象名称和所述sql语句数据归成一类,否则不归成一类;
其中,预设的相似度阈值是根据历史数据统计后得到的,在进行历史数据统计时,距离现在时刻越近的历史数据的权重越大,距离现在时刻越远的历史数据的权重越小。
赋予归类后的所述sql语句数据以类型标识,并将所述类型标识和所述sql语句数据导入到所述修正后的sql语句数据基表形成sql语句分类表。
其中,sql语句的类型主要包括数据操纵语言(dml),数据定义语言(ddl),数据控制语言(dcl),可以应用英文缩写字母作为类型标识对sql语句数据进行区分。
本实施例,通过进行相似度计算后建立sql语句分类表,从而有效的将sql语句进行分类。
在一个实施例中,所述s101、从数据库中抽取sql语句数据,打包所述sql语句数据后生成sql语句数据组,赋予所述sql数据组以时间标记后形成带有时间标记的待归类sql数据组,包括:
获取预设的频率阈值和所述sql语句数据产生的频率,将所述sql语句数据产生的频率与所述频率阈值进行比较;
具体的,预设的频率阈值是根据历史数据统计后得到的。在获取所述sql语句数据产生的频率时,可以先设定两个统计时间区间,在这两个统计时间区间内,分别记录产生的sql语句数据量,然后以产生的sql语句数据量的平均值作为所述sql语句数据产生的频率。
当所述sql语句数据产生的频率大于所述频率阈值时,生成定时任务,当所述sql语句数据产生的频率小于所述频率阈值时,等待新的sql语句数据的产生;
触发所述定时任务,将上次定时任务触发后到本次定时任务触发前的所有sql语句数据进行打包;
获取所述定时任务的触发时间节点,以所述时间节点为记号,对打包好的sql语言数据进行标记后得到所述带有时间标记的待归类sql数据组。
本实施例,通过sql数据组进行有效的时间标记,能够有效的追踪sql语句的来源,从而在sql语句归类后对数据来源的sql语句类型构成进行分析。
在一个实施例中,提出了一种sql语句归类装置,如图4所示,包括如下模块:
基表建立模块41,设置为获取sql语句数据后生成待归类sql语句数据组,根据所述待归类sql语句数据组建立待归类sql语句数据基表;
基表过滤模块42,设置为过滤所述待归类sql语句数据基表中与分类无关的索引项后得到修正后的待归类sql语句数据基表;
建立行生成模块43,设置为从数据库视图中抽取与所述sql语句数据组中各sql语句对应的sql语句id标识和对象名称,导入所述sql语句id标识和所述对象名称于所述修正后的待归类sql语句数据基表后得到sql语句建立行;
全对象名称生成模块44,设置为获取所述sql语句建立行中的行id标识,将相同的所述行id标识对应的不同的所述对象名称进行拼接后得到全对象名称;
分类表建立模块45,设置为将所述sql语句id标识与所述全对象名称进行相似性比较,根据比较结果将所述sql语句数据进行归类后形成sql语句分类表。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述各实施例中所述sql语句归类方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例中所述sql语句归类方法的步骤。所述存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请一些示例性实施例,其中描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!