一种基于感兴趣区域和全局特征的图像美学质量评估方法与流程
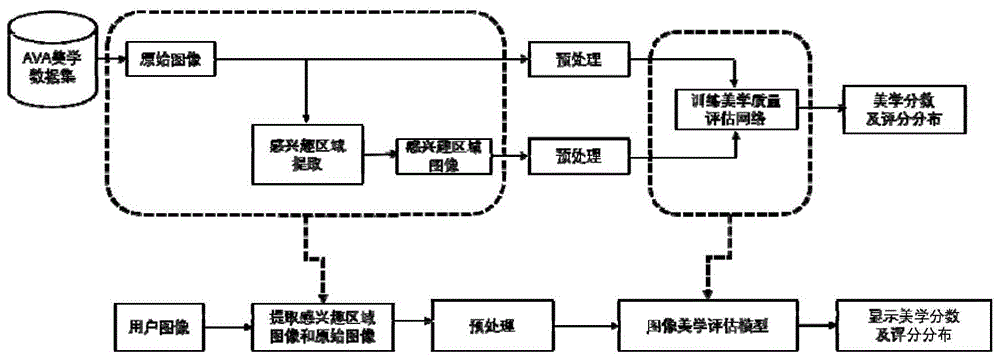
本发明涉及图像处理、计算机视觉领域,具体涉及一种基于感兴趣区域和全局特征的图像美学质量评估方法。
背景技术:
美的判断是否存在客观的标准?从感知层面分析,一幅美的图像,不仅依赖于符合特定的美学规则,如三分法则、色彩平衡、景深等,还依赖于图像传达出来的语义内容和情感信息。在计算机视觉领域,图像美学质量评估(imageaestheticqualityassessment)希望通过计算机模拟人类的视觉系统和审美感知,实现对图片美感的自动判别,如判断图像高美感、低美感的分类,或者给出图像美学分数,或给出图像美学评级分布。
图像美学评估方法是一个复杂的任务,目前大部分研究关注于图像全局特征表示,这种方法不区分前景和背景,具有计算速度快,噪声容忍度高等优点。但是这类方法将图像中具有特定语义信息的区域和背景区域等同对待,认为图像是一个不可分割的整体,忽略了不同区域间所含信息量的差异性。
根据摄影学和认知神经科学的研究,人类在评估图像时会聚焦于引起其兴趣的区域,该区域往往包含了一定的语义意义。然而,如何在一张图像中发现感兴趣区域,是一个非常有挑战性的问题。一方面,现有的美学数据集中只有人工标注的美学标签,并没有相关区域级的语义标签。另一方面,由于不同内容图片的差异性极大,目前已有的内容检测算法不能处理多种不同类型的图像。其中,目标检测算法能够检测出图像中的特定类别的物体(一般为常见物体),并给出区域级标注,但是美学数据集中包含大量不常见物体,这些物体无法被检测出;已有的显著性检测算法能够发现出现中的显著性区域并给出显著度映射图,但是无法给出明确的区域级标注,而且当图像中背景较为复杂时,检测效果较差。
在美学质量评估领域,感兴趣区域特征虽然能够针对性地描述图像前景中的语义信息,但是图像全局特征对于图像整体理解也有着不可替代的作用。图像全局特征不仅包括图像的纹理、颜色等低层次信息,还包括图像构图、上下文信息等高层次信息。两种特征的结合能够克服单一特征对图像描述的不足,但是如何设计有效的美学评估模型用来同时学习两种特征,成为亟待解决的问题。
技术实现要素:
有鉴于此,为解决上述现有技术中的问题,本发明提供了一种基于感兴趣区域和全局特征的图像美学质量评估方法,该方法能够对任意输入图片进行美学质量评估,预测一个1到10分的美学评分概率分布,该评分分布与人类评分分布相关性高,能够客观地描述图像美学质量。
为了实现上述目的,本发明的技术方案如下。
一种基于感兴趣区域和全局特征的图像美学质量评估方法,包括以下步骤:
步骤1、感兴趣区域提取算法设计;将原始图像作为全局图像输入;利用目标检测算法提取目标检测框,从全局图像中筛选出目标检测框,得到它们的中心点;利用显著性检测算法提取显著性映射图,对显著性映射图做二值化以分离出连通区域,提取所有连通区域的中心点;以所有提取到的中心点为中心,设置9个不同尺寸的候选区域;计算所有候选区域的区域语义性评分;根据区域语义性分数排序并使用非极大值抑制算法得到最终的感兴趣区域;
步骤2、数据集预处理;对感兴趣区域和全局图像进行归一化、镜像和随机裁剪操作;
步骤3、美学评估网络设计;美学评估网络包括感兴趣区域和全局图像输入、双通道并行卷积网络主体和earthmover′sdistance-basedloss损失函数;所述双通道并行卷积网络通过提取输入的感兴趣区域和全局图像中的局部特征和全局特征进行融合,再利用earthmover′sdistance-basedloss损失函数进行进行误差反向传播,最终输出一个美学分数概率分布;
步骤4、渐进优化训练;通过步骤1~步骤3训练获得初始收敛模型f1,利用初始收敛模型f1对训练集进行分类,剔除正确概率大于阈值的样本,得到新的训练集;在新的训练集上微调训练网络,优化模型,得到收敛模型f2;在收敛模型f2基础上,重复上述过程,得到收敛模型f3;将三个模型预测结果加权融合,获得最终的美学质量评估结果;
步骤5、预测输出;将任何目标图像使用已训练好的美学评分模型进行评估,得到相应的1~10分的美学分数概率分布以及最终的数学期望评分。
进一步,所述步骤1中包括以下步骤:
步骤11、通过目标检测算法提取目标检测框,删除面积小于全局图像总面积1/10或者置信度小于50%的检测框,剩余检测框根据置信度进行评分排序,选取置信度最高的前10%检测框的中心点作为第一初始化中心点;
步骤12、通过显著性检测算法提取显著性映射图,计算每张显著性映射图的均值,以此为阈值对显著性映射图做二值化,根据二值化后的显著性映射图计算连通区域,提取所有连通区域的中心点作为第二初始化中心点;
步骤13、合并第一初始化中心点和第二初始化中心点,以此为中心设置9个不同尺寸的候选区域;
步骤14、提取到候选区域后,计算所有候选区域的区域语义性评分,并根据语义性分数排序;
步骤15、用nms非极大值抑制算法对排序候选区域进行处理,获得分数越高,说明该区域包含的语义信息量越大,得到分数最高的3个候选区域,作为最终的感兴趣区域。
进一步地,所述步骤14中,通过下列公式计算候选区域的语义性评分:
score=α*sa+β*sb,α>0,β>0
其中iroi为输入的候选区域,sal(iroi)为候选区域内所有像素点的显著值之和,area(iroi)为候选区域的面积;sa为显著性/面积比,其值越高,代表局部区域单位面积内的显著性越高,sb为面积约束项,防止局部区域的面积过小,α、β为调节sa、sb两项的参数。
进一步地,所述步骤2中采用大规模美学数据库ava作为数据集,其中随机选择23万张图片作为训练集,2万张图片作为测试集;所述归一化操作是对感兴趣区域和全局图像进行同样的去均值和除方差处理。。
进一步地,所述步骤3中的双通道并行卷积网络主体选用了经典的卷积神经网络结构vggnet,并将其在imagenet上训练得到的网络模型迁移至美学评估网络中,所述双通道并行卷积网络主体包含特征提取网络和特征分类网络,所述特征提取网络是由两个分支组成的双通道网络,每个分支包含13个卷积层、5层池化层和第一全连接层,两个分支的第一全连接层拼接融合,输出至特征分类网络,所述特征分类网络由第二全连接层和第三全连接层组成。
进一步地,所述第一全连接层和第二全连接层中均包含4096个神经元,所述第三全连接层中包含10个神经元,所述第三全连接层经过softmax后得到1*10维的向量,用于表示图像属于1~10分之间任一分数的概率。
进一步地,所述步骤4中的渐进优化训练中,先使用含动量的随机梯度下降算法sgd-with-momentum对美学评估网络进行训练,训练时特征提取网络中的13个卷积层和第一全连接层使用了迁移过程中学习得到的权值参数,将特征提取网络中的初始学习率设置为0.00005,特征分类网络中的初始学习率设置为0.0001,经过每10次整个数据集上的样本遍历,学习率降低10倍,直到收敛为止,获得收敛模型f1。
进一步地,所述步骤4中的渐进优化训练中,获得收敛模型f1后,用训练好的收敛模型f1对整个训练集进行评估,获得预测分数;计算预测分数与数据集中的真实分数的绝对分数差值,将差值最小的前10%的样本从训练集中删除,用剩下90%的样本对收敛模型f1进行微调,重复该过程两次,分别获得收敛模型f2和收敛模型f3。
与现有技术比较,本发明的一种基于感兴趣区域和全局特征的图像美学质量评估方法,当用户给定图像后,系统能根据训练好的模型给出具有参考意义的美学评价,其评估结果不仅包含具体的期望分数,而且包含评分分数的分布,在现实场景下有比较强的指导意义。
附图说明
图1为本发明的一种基于感兴趣区域和全局特征的图像美学质量评估方法的流程示意图。
图2为本发明的美学评估网络模型结构示意图。
图3为本发明的感兴趣区域提取算法流程示意图。
具体实施方式
下面将结合附图和具体的实施例对本发明的具体实施作进一步说明。需要指出的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1所示,为本发明的一种基于感兴趣区域和全局特征的图像美学质量评估方法的流程示意图,包括以下步骤:
(1)感兴趣区域提取算法设计,如图3所示,为本发明的感兴趣区域提取算法流程示意图,包括以下步骤:
(1-1)本文使用了目标检测算法fasterrcnn(rens,hek,girshickr,etal.fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetworks[c]//advancesinneuralinformationprocessingsystems.2015:91-99.)来获得初始的目标检测框;首先删除明显不合理的检测框,本发明中为面积小于全局图像总面积1/10或置信度低于50%的检测框,然后将剩余的检测框根据置信度进行评分排序,最后选取置信度最高的前10%检测框的中心点作为第一初始化中心点;
(1-2)使用显著区域提取算法deepconvnet(akasalnet)(panj,sayrole,giro-i-nietox,eta1.shallowanddeepconvolutionalnetworksforsaliencyprediction[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016:598-606.)来提取图像的显著性映射图,计算每张显著性映射图的均值,以此为阈值对显著性映射图做二值化操作,得到二值化图,计算二值化图中的连通区域,提取所有连通区域的中心点作为第二初始化中心点;
(1-3)合并第一初始化中心点和第二初始化中心点,得到k个中心点,以这些中心点为中心,设置5种面积,3种纵横比的候选区域,5种面积分别为全局图像面积的(0.3,0.4,0.5,0.6,0.7)倍,3种比例为(0.5,1,2)的纵横比,共设置k*5*3个候选区域;
(1-4)通过下列公式计算候选区域的语义性评分,并根据语义性分数排序:
score=α*sa+β*sb,α>0,β>0
其中iroi为输入的候选区域,sal(iroi)为候选区域内所有像素点的显著值之和,area(iroi)为候选区域的面积;sa为显著性/面积比,其值越高,代表局部区域单位面积内的显著性越高,sb为面积约束项,防止局部区域的面积过小,α、β为调节sa、sb两项的参数;取α=1.0,β=2.0;
(1-5)本发明使用两个区域之间的交并比(iou)来判断两个区域之间的相对位置关系,iou表示两个区域之间的重合度,iou值越高,表明两个区域间的重合面积越大,当iou为0时,两个区域不相交;
iou的计算公式如下:
其中,area1和area2分别表示区域1和区域2的面积,area1∩area2表示区域1和区域2的交集的面积,area1∪area2表示区域1和区域2的并集的面积;
对得分大于某个阈值的所有候选区域,使用nms(非极大值抑制)算法,合并相邻的候选区域,得到最终的3个感兴趣区域,每个区域有相应的分数来评估其语义性;nms算法从语义性得分最高的候选区域开始,分别判断其他区域与该候选区域的重叠度iou是否大于某个设定的阈值;如果存在与该候选区域的重叠度超过阈值的框,并且舍弃这些框;并标记该分数最高的候选区域为保留候选区域;接着继续从剩下的矩形框所有框中,选择概率最大的候选区域,重复上述步骤;通过nms算法,可以只剔除iou高于阈值,即高度重叠的候选区域,而不影响最终的效果;
(2)数据集预处理阶段,包括以下步骤:
(2-1)作为优选的技术方案,选择了大规模美学数据库ava(n.murray,l.marchesotti,f.perronnin,ava:alarge-scaledatasetforaestheticvisualanalysis,in:proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition(cvpr),2012,pp.2408-2415.)来作为训练和评估模型的数据集;该数据库来源于图像分享网站fickle,包含约25w+图片,每张图片有77~220位用户的评分,评分范围为1~10分,即可认为每张图片都拥有一个总体上正确客观的美学分数;
(2-2)原始输入图片会包含很多冗余的信息,为此,我们需要对数据进行去均值除方差的操作,由于后期将使用imagenet数据集上训练的模型作为初始化权值,因此这里使用imagenet数据集的均值和方差对训练数据集进行预处理;
(2-3)先对所有图片提取感兴趣区域,并提前存储到内存中;当对网络进行训练和测试时,先裁剪出输入图片的感兴趣区域,然后将感兴趣区域和全局图像均调整到256*256*3的尺寸,然后在小范围内进行随机镜像和随机裁剪至224*224*3,这样确保在保存输入图片信息的前提下,增加图片的多样性,减少网络的过拟合。
(3)美学评估网络设计,包括以下步骤:
(3-1)采用双通道并行卷积网络结构,并选用经典的卷积神经网络结构vggnet(simonyank,zissermana.verydeepconvolutionalnetworksforlarge-scaleimagerecognition[j].arxivpreprintarxiv:1409.1556,2014.),并将其在imagenet上训练得到的网络模型迁移到我们的美学评估网络中来,迁移的部分包括13层卷积层、5层池化层以及1层全连接层;两路分支分别学习图像的全局特征和局部特征,并于第一个全连接层后拼接融合,再经过两个全连接层完成特征的提取;
(3-2)在前向传播阶段,两路分支输入分别为全局图像和感兴趣区域图,如图2所示,经过网络中的13个卷积层和1个全连接层后,得到两个4096维的特征,分别代表图片的全局特征和局部特征,通过决策融合,得到最终用于分类的特征,为了减少网络参数,降低网络的过拟合现象,本文中对两个通道的网络进行参数共享训练;
(3-3)网络中最后一层输出层由10个神经元组成,通过softmax映射函数,可以得到图片属于1~10分的概率,并最终得到图片的概率分布,而在反向传播阶段,预测概率分布为,其概率累积函数为,真实分布为y,其概率累积函数为,损失函数的目标是衡量预测分布于真实分布之间的相似性;为此本文选用emdloss作为损失函数,emdloss函数的计算如下:
其中,
(4)渐进优化训练,包括以下步骤:
(4-1)模型初始化:网络中前13个卷积层和1个全连接层设置成vggnet在imagenet数据集上训练后得到的参数,最后两层全连接层设置为高斯分布随机初始化;
(4-2)设置训练参数:本文采用带动量的随机梯度下降算法sgd-with-momentum进行训练,网络中前13个卷积层和1个全连接层的初始学习率设置为0.00005,最后两个全连接层的初始化学习率设置为0.0001,。训练过程中为固定学习率下降,每10个批次,学习率降低10倍;
(4-3)加载训练数据:本文采用共约有25万张图像的大规模美学数据集ava对网络模型进行训练,其中随机选择23万张图片作为训练集,2万张图片作为测试集;
所有样本进行如下操作:
(1)提取感兴趣区域并裁剪出来;
(2)去均值;
(3)去均值除方差归一化;
(4)设置图片大小为256*256;
(5)对(4)中得到的图片进行224*224的随机裁剪;
(4-4)采用随机梯度下降算法,对图2所示的深度卷积神经网络进行迭代训练,直到网络收敛,可以得到一个初始的判别模型,得到收敛模型f1;
(4-5)利用训练好的收敛模型f1对训练集进行评估,根据损失值对图片进行排序,分离出easyexample,并将其从训练集中删除,删除比例可选,本文中删除比例为10%,将剩余图片作为训练集,再次微调模型直到收敛,得到收敛模型f2;
(4-6)利用训练好的收敛模型f2,再次重复(4-5)步骤,得到收敛模型f3;最终预测结果取三个模型融合后的结果。
(5)预测输出,通过学习图像美学评分的分布函数
通过分布p计算平均分escore的计算公式如下:
其中,pi为输入属于第i类的概率。
综上所述,本发明的一种基于感兴趣区域和全局特征的图像美学质量评估方法,当用户给定图像后,系统能根据训练好的模型给出具有参考意义的美学评价,其评估结果不仅包含具体的期望分数,而且包含评分分数的分布,在现实场景下有比较强的指导意义。
- 还没有人留言评论。精彩留言会获得点赞!