一种基于半监督学习的用户评论聚类方法与流程
本发明属于计算机技术领域,尤其涉及一种基于半监督学习的用户评论聚类方法。
背景技术:
随着智能设备的广泛应用,移动应用程序(mobileapp)存在大量的用户评论,现在已经成为软件生态系统的重要组成部分。这些用户评论一般分布在主要的在线应用商店,如googleplay和appleappstore。在用户评论中,包含了大量的有用信息,这些有用信息是开发人员与用户实现交互的一个重要接口。用户可以通过发表用户评论,提出一些新功能的要求及使用过程中遇到的一些问题,此信息对于软件的维护及改进有着至关重要的作用。
在下文中,总结了对用户评论进行聚类的主要相关研究,这些相关研究均发表在国际重要期刊或会议上,具有较高的参考价值。
harman等人通过识别客户评级与移动应用程序的下载排名之间的相关性,介绍了应用商店挖掘的概念。iacob和harrison根据经验评估了移动应用程序用户的使用程度靠用户评论来描述变更请求,发现有23%的用户评论描述了功能请求。此外,pagano和malej发现33%的用户评论与需求和用户体验有关,并且开发人员使用用户提供的反馈来收集需求。
chen等人在2014年icse上发表了ar-miner:mininginformativereviewsfordevelopersfrommobileappmarketplace,设计了ar-miner,一种使用半监督学习方法对信息性用户评论进行过滤和排序的方法。他们证明:平均而言,35%的用户评论包含信息内容。khalid等人报道了一项研究,共有6390个用户评论,旨在将其定性分类为12种类型的投诉。结果表明,超过45%的投诉与开发人员可以解决的问题有关。
disorbo等人设计了surf,一种总结用户评论以收集新要求的工具。
panichella等人在2016年fse上发表论文ardoc:appreviewsdevelopmentorientedclassifier,提出了ardoc,这种方法结合了自然语言处理,情感分析和文本分析技术,通过机器学习(ml)算法来检测用户评论中的句子,自动分类应用用户评论中包含的有用反馈,对于执行软件维护和演化任务非常重要。用户评论中包含的ardoc分类句,对于维护视角非常有用,包括:功能请求,问题发现,信息搜索,信息提供等。这些类别来自pagano等人描述的应用用户评论中发生的主题分类之间的系统映射以及开发人员关于发展特定通信的讨论中发生的句子类别的分类。具体而言,这种分类法定义为从维护角度对用户评论的反馈进行建模。
villarroel等人在2017年tse上发表文章listeningtothecrowdforthereleaseplanningofmobileapps,设计了clap(crowdlistenerforreleaseplanning),一种web应用程序,能够(i)自动将用户评论分类为功能性错误报告,新功能建议,性能问题报告,安全问题报告,能源消耗过度报告,可用性改进请求和其他(包括非信息性用户评论);(ii)在单个请求中将相关审核集中在一起;以及(iii)建议集群开发人员在下一版本中应满足哪些审核。与ar-miner不同,clap将用户评论分类为特定类别(例如,安全问题报告),为开发人员提供有关用户评论性质的其他见解。此外,虽然ar-miner仅根据预先定义的公式评估的用户评论的重要性提供用户评论的排名,但clap从同一应用程序或其他应用程序的过去历史中学习,以确定有助于确定是否审查应该得到解决。与其他现有技术相比,clap提供了一个完整的解决方案,从用户评论分类到下一个应用程序版本的优先级。clap将自然语言处理技术和机器学习结合起来进行评审分类,使用聚类技术对用户评论进行分组,最后,再次建立机器学习者,通过依赖于集群中的用户评论数等特征来推荐特定用户评论集群的实施或受bug影响的不同硬件设备的数量。
通过对相关工作的了解发现,近年来,国内外对于用户评论的关注度越来越高,已经有很多工作投入到对用户评论的处理上,并且针对不同的情况,已经提出了很多种分类亦或是聚类的规则,且已取得了很好的效果,但目前还没有采用半监督聚类对用户评论进行聚类的方法。
技术实现要素:
针对于上述现有技术的不足,本发明的目的在于提供一种基于半监督学习的用户评论聚类方法,以解决现有技术中开发人员从用户评论中获取有效信息需要耗费大量时间的问题。
为达到上述目的,本发明采用的技术方案如下:
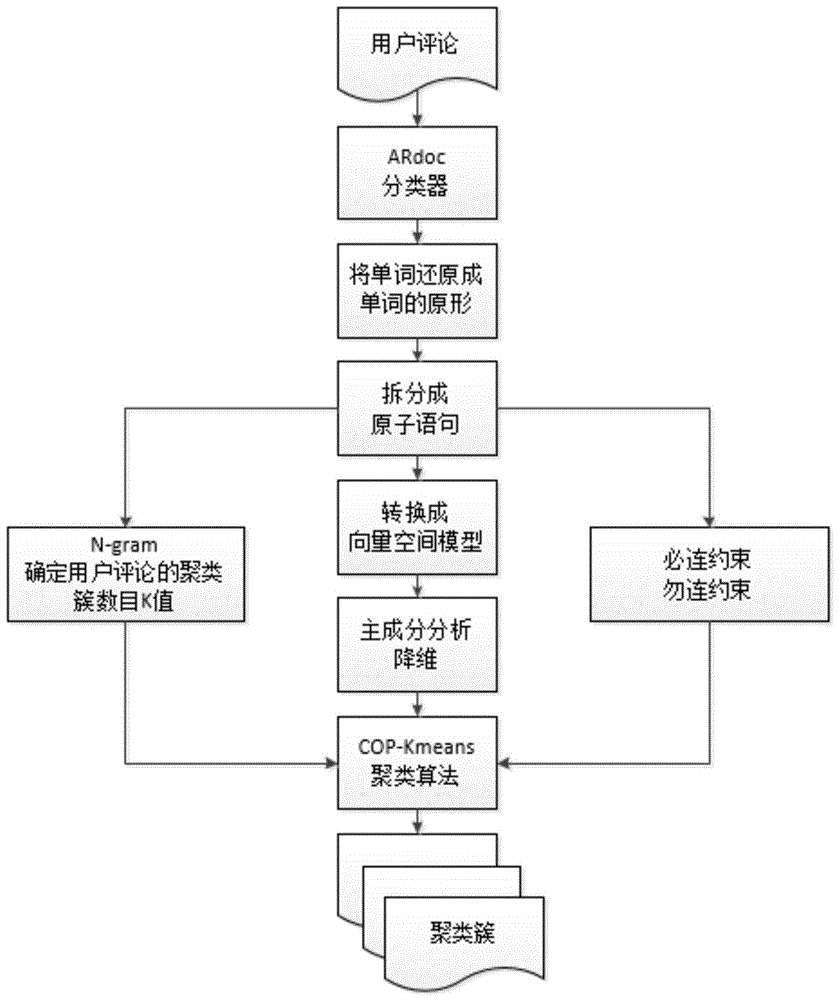
本发明的一种基于半监督学习的用户评论聚类方法,包括步骤如下:
(1)将用户评论处理成后续操作所需的形式;
(2)将处理后的用户评论转换成向量空间模型并用主成分分析进行降维;
(3)使用n-gram确定用户评论的聚类簇数目k值;
(4)构建必连约束和勿连约束;
(5)使用cop-kmeans聚类算法进行用户评论聚类。
进一步地,所述步骤(1)中将用户评论处理成后续操作所需的形式具体包括:对用户评论采用ardoc分类器,划分成句子级别并且进行分类,提取所分类别中特征需求和问题发现这两个类别,再将这两个类别中的句子采用stanfordnlp工具包中的parser解析器解析成语法树,采用自底向上的处理方法分解成原子语句,最后使用stanfordnlp工具包中的lemma组件将所得数据中的单词还原成单词的原形。
进一步地,所述步骤(2)中将处理后的用户评论转换成向量空间模型并用主成分分析进行降维具体包括:采用向量空间模型来表示处理后的用户评论,处理后的用户评论中的所有单词构成了向量空间,每个单词代表了向量空间中的一个特征,最后再使用主成分分析对向量空间模型降维,使用文档频度df来表示每个单词在向量空间模型中的权重,其中文档频度df的计算方式为:
其中,
进一步地,所述步骤(2)中采用的向量空间模型是把对文本内容的处理简化为向量空间中的向量运算,且向量空间模型以空间上的相似度表达语义的相似度,即将所有用户评论中涉及到的所有单词作为向量空间,每个单词代表向量空间中的一个特征;对于一个用户评论,其包含的单词对应向量空间的特征值为该单词的文档频度df,不包含的单词对应向量空间的特征值为0。
进一步地,所述步骤(2)中使用的主成分分析是一种降维的统计方法,其借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,表现为将原随机向量的协方差阵变换成对角形阵,对多维变量系统进行降维处理,使其以高精度转换成低维变量系统,采用主成分分析,将处理后的用户评论转换成的向量空间模型从高维度降到低维度。
进一步地,所述步骤(3)中使用n-gram确定用户评论的聚类簇数目k值具体包括:获取用户评论的n-gram短语,其中n取值为2,将相同的n-gram短语合并,并记录合并次数,删除合并次数小于2的n-gram短语,剩余的n-gram短语个数就是聚类簇数目k值。
进一步地,所述步骤(4)构建必连约束和勿连约束具体包括:将表达相同用户含义的用户评论连接起来构成必连约束,即指用户评论必属同一个聚类簇;将表达不同用户含义的用户评论连接起来构成勿连约束,即指用户评论必不属同一个聚类簇,根据用户评论的数量,抽取部分需要进行人工判定的用户评论进行构建必连约束和勿连约束。
进一步地,所述步骤(4)中抽取用户评论数量的十分之一进行构建必连约束和勿连约束。
进一步地,所述步骤(4)具体还包括:必连约束中存在传递闭包关系,即若用户评论1与用户评论2是必连约束,用户评论2与用户评论3是必连约束,则用户评论1与用户评论3也是必连约束。
进一步地,所述步骤(5)使用cop-kmeans聚类算法进行用户评论聚类具体还包括:将步骤(2)所得的向量空间模型、步骤(3)所得的聚类簇数目k值和步骤(4)所得的必连约束和勿连约束输入到cop-kmeans聚类算法中进行用户评论聚类得到聚类簇。
进一步地,所述步骤(5)中的cop-kmeans聚类算法执行过程具体包括:选取聚类簇数目k值个用户评论作为聚类簇中心,在确保必连约束和勿连约束中的约束条件得以满足的条件下,将用户评论分配到距离最近聚类簇中心所构成的聚类簇中,直至将所有的用户评论均分配完成后,计算聚类簇中所有用户评论的向量空间模型的均值,得到的聚类簇中所有用户评论的向量空间模型的均值即为新的聚类簇中心,重复上述操作,直至达到主循环预设最大迭代次数或新的聚类簇中心不再变化。
本发明的有益效果:
本发明的方法减少了开发人员从用户评论中提取有用信息所需消耗的时间成本,同时可通过聚类簇的大小来判断用户评论所反映的问题或需求需要解决的紧急程度。
附图说明
图1为本发明方法的流程图。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
参照图1所示,本发明的一种基于半监督学习的用户评论聚类方法,包括步骤如下:
(1)将用户评论处理成后续操作所需的形式:将用户评论中的单词还原成单词的原形等处理,得到后续操作所需的形式;
(2)将处理后的用户评论转换成向量空间模型并用主成分分析进行降维:使用向量空间模型表示处理后的用户评论,并且使用主成分分析对向量空间模型进行降维;
(3)使用n-gram(n元模型)确定用户评论的聚类簇数目k值:获取用户评论的n-gram短语,其中n取值为2,将相同的n-gram短语合并,并记录合并次数,删除合并次数小于2的n-gram短语,剩余的n-gram短语个数就是聚类簇数目k值;
(4)构建必连约束和勿连约束:构建必连约束的准则是将表达相同用户含义的用户评论连接起来构成必连约束;将表达不同用户含义的用户评论连接起来构成勿连约束,其中必连约束和勿连约束还可以根据开发人员不同的需求进行构建;
(5)使用cop-kmeans聚类算法进行用户评论聚类:将步骤(2)所得的向量空间模型、步骤(3)所得的聚类簇数目k值和步骤(4)所得的必连约束和勿连约束输入到cop-kmeans聚类算法中进行用户评论聚类得到聚类簇。
其中,所述步骤(1)具体包括:需要用到的实验数据为用户评论,因此,首先编写一个爬虫工具对所需数据进行爬取,以备后续使用,对用户评论,按照下述步骤进行处理:
11)先使用由panichella等人开发的用户评论分类器ardoc将用户评论拆分成句子级别,并将用户评论分为四类:信息提供、信息查询、特征请求及问题发现,由于本发明的最终目的是将用户评论进行聚类使开发人员可以从中获取有用信息,因此只需要最后两个类别进行进一步处理;
12)使用stanfordnlp工具包中的parser解析器,将步骤11)得到的用户评论转换成一个语法树,对该语法树进行分析,将句子级别的用户评论转换成表示单一信息的原子语句;
13)利用stanfordnlp工具包中的lemma组件将用户评论中的单词还原成单词的原形。
所述步骤(2)中,将处理后的用户评论转换成向量空间模型并用主成分分析进行降维具体包括:采用广泛使用的向量空间模型来表示处理后的用户评论,处理后的用户评论中的所有单词构成了向量空间,每个单词代表了向量空间模型中的一个特征,最后再使用主成分分析对向量空间模型降维,其中取前多少个特征需要达到的方差占比,示例中,设置为0.95,使用文档频度df来表示每个单词在向量空间模型中的权重,其中文档频度df的计算方式如下所示:
其中,
所述步骤(3)具体包括:提取所有用户评论的n-gram短语,其中n取值为2,将所有n-gram短语中重复出现的n-gram短语进行合并,并且记录合并进行的次数,若n-gram短语中出现有一个单词相同,但是整体不同的n-gram短语,则删除合并次数较少的n-gram短语,最后删除合并次数小于2的n-gram短语,剩余的n-gram短语个数就是聚类簇数目k值。
所述步骤(5)具体包括:将步骤(2)所得的向量空间模型、步骤(3)所得的聚类簇数目k值和步骤(4)所得的必连约束和勿连约束输入到cop-kmeans聚类算法中进行用户评论聚类得到聚类簇,其中cop-kmeans聚类算法采用欧氏距离计算向量空间模型中的向量之间的距离,主循环最大迭代次数为300,决定收敛的容忍度为1e-5。
以下采用实验的方式来体现本发明方法的性能:
实验的主要内容为:对用户评论进行聚类,采用likert标度强度的方法来显示本发明方法的性能。
实验采用的数据,来自于googleplay上爬取4个受欢迎的app,其详细信息如表1所示:
表1
为确保基于半监督学习的用户评论聚类方法有意义,本实验中邀请2位具有5年经验的android开发人员对本发明的性能进行评估。为了避免偏见,android开发人员不了解本发明目标以及用户评论聚类所使用的特定算法。为了表达他们的观点,android开发人员使用了从非常低到非常高的值的likert标度强度,即给出1到5之间的值(其中1表示非常低,2表示较低,3表示中等,4表示较高,5表示非常高),实验中的测试集为表2所示,其中clusters指代聚类簇数目k值,min指代android开发人员在对基于半监督学习的用户评论聚类方法的评估中给的最低分数,median指代android开发人员在对基于半监督学习的用户评论聚类方法的评估中给的平均分数,max指代android开发人员在对基于半监督学习的用户评论聚类方法的评估中给的最高分数。
表2
实验表明本发明方法在用户评论聚类的效果上已经取到较高的结果。
其中虽然likert标度强度的波动较大,最低是1,最高则可达到5,但整体效果较好,可以达到平均4.3967,经对聚类效果为1的聚类簇分析发现,该聚类簇会将用户评论中无明显关键信息的用户评论聚在一起构成一个聚类簇,所以该聚类簇中所含用户评论设计的方面较多,但是信息量却不足,因此将这些用户评论聚成一类不会有较大的信息损失且该类型的聚类簇较少一般一个app对应的用户评论聚类簇中仅含有1至2个,因此对本发明的结果影响不大。该实验结果表明,本发明方法可以有效地为开发人员聚类用户评论,节省开发人员从用户评论中提取有效信息所需的时间。
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!