一种风险识别方法和系统与流程
本申请属于数据处理技术领域,具体涉及一种风险识别方法和系统。
背景技术:
企业在生产经营过程中,需要通过金融市场的金融工具实现资金的筹备等,而,企业破产会对金融市场造成严重的损失,金融企业通过建立风险模型并通过风险模型对企业经营风险进行预测,以使得金融企业保持投资回报。
在企业经营过程中,每个企业每天都在发生着改变,这些改变有可能使得企业越来越好,也有可能使得企业面临各种风险。面对企业的千万级数据,从中分析出企业的风险信息对企业运营的决策和投资者都是比较好的参考。目前已有的企业经营风险预测方法主要包括于统计学的方法和基于机器学习的方法。
目前,现有的企业风险预测评估方法不完善,而且在风险模型的建立过程中数据处理量过大,对服务器造成巨大压力,且数据处理速度过慢。因此,亟待一种企业风险识别能够结合企业的各种资产、财务数据、经营数据、债务相关数据,迅速建立模型并将该模型应用到预测数据中,从不同维度对企业风险进行预测。
技术实现要素:
为了解决现有技术存在的上述问题,本申请目的在于提供一种风险识别方法和系统,旨在解决现有预测模型对内存消耗过大,存在大量不必要的数据计算的问题。
为解决上述技术问题,本申请提供了一种风险识别方法,应用于终端,用于对企业破产风险进行识别,所述方法包括:获取待预测企业的信息数据;根据构建的风险识别模型对所述待预测企业的信息数据进行分析处理以得到预测结果,其中,所述构建的风险识别模型为依据lightgbm机器学习算法训练建立;将所述预测结果以预设的可视化方式显示于所述终端的显示界面,以供用户可以清楚地获知预测结果。
可选地,所述方法还包括:获取所述风险识别模型的原始训练数据;利用所述lightgbm机器学习算法对所述原始训练数据进行学习,以得到所述风险识别模型。
可选地,所述利用所述lightgbm机器学习算法对所述原始训练数据进行学习,以得到所述风险识别模型的步骤,包括:将所述原始训练数据进行数值处理以得到连续的特征值数据;对所述连续的特征值数据进行离散处理以得到直方图;根据所述直方图生成所述风险识别模型。
可选地,所述原始训练数据包括已知破产企业数据信息和非破产企业数据信息,其中,所述已知破产企业与所述非破产企业的数量比为1:1.4。
可选地,所述已知破产企业数据信息和非破产企业数据信息包括但不限于:工商信息、行政处罚、开庭公告、裁判文书、招投标、司法拍卖、商标注册、失信被执行、专利和判决执行。
可选地,所述直方图中包括的类别包括:注册资本(量级万)、成立年限、行业企业数量、行业企业吊销率、关联公司裁判文书被告次数、裁判文书次数、法人变更次数、商标注册数量、是否吊销、失信次数、裁判文书被告案件判决总金额、网络图法人对外投资或者任职的公司执行次数、裁判文书被告与破产有关纠纷次数、行业企业吊销数量、股东变更次数、网络图股东或者对外投资企业的执行次数、裁判文书被告合同纠纷次数、法院公告与否、网络图股东或者对外投资企业作为被告的裁判文书次数、地址变更次数。
可选地,所述根据所述直方图生成所述风险识别模型的步骤,包括:遍历所述直方图确定类别以及对应的统计量;根据所述统计量确定满足预设条件的类别为最优分割点;以梯度提升树和所述最优分割点建立决策树以形成所述风险识别模型。
可选地,所述决策树的建树过程中采用带深度限制的leaf-wise的叶子生长策略。
可选地,所述决策树的叶子所对应的直方图通过所述叶子的父节点的直方图与所述叶子的兄弟节点的直方图做差得到。
本申请还提供了一种风险识别系统,所述风险识别系统用于对企业破产风险进行识别,所述系统包括:数据获取模块,用于获取待预测企业的信息数据;数据分析模块,用于根据构建的风险识别模型对所述待预测企业的信息数据进行分析处理以得到预测结果,其中,所述构建的风险识别模型为依据lightgbm机器学习算法训练建立;显示模块,用于将所述预测结果以预设的可视化方式显示于所述终端的显示界面,以供用户可以清楚地获知预测结果。
本申请通过从现有的企业信息数据中,通过lightgbm机器学习算法对企业信息数据中的各个方面的数据特征进行学习,通过直方图的方式可以使用类别型数据,减少了数据标准化流程,同时,通过此种方式建立的决策树的叶子的直方图可以由它的父亲节点的直方图与它兄弟节点的直方图做差得到,提升一倍速度。并且在进行建树过程中,采用带有深度限制的按叶子生长(leaf-wise)算法,leaf-wise是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂并循环,在分裂次数相同的情况下,leaf-wise可以降低更多的误差,得到更好的精度。同时,在风险识别模型学习过程中采用多种不同类型企业信息数据,使得建立的模型更加的完善,以确保风险预测的准确性。
附图说明
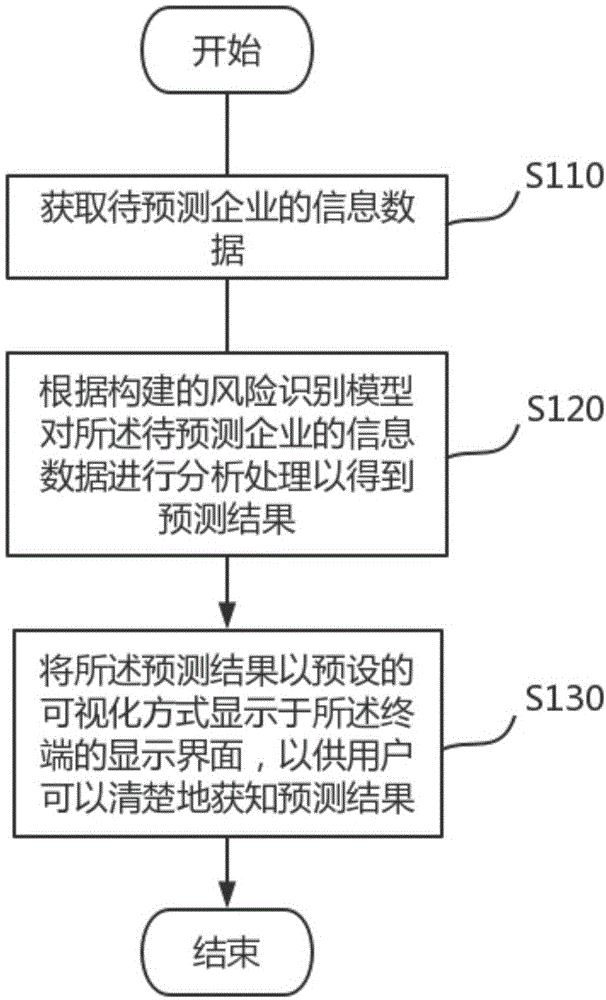
图1为本申请流程图。
具体实施方式
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
在后续的描述中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身没有特定的意义。因此,“模块”、“部件”或“单元”可以混合地使用。
图1是本申请提供的一风险识别方法的流程图。该实施例的方法一旦被用户触发,则该实施例中的流程通过终端自动运行,其中,各个步骤在运行的时候可以是按照如流程图中的顺序先后进行,也可以是根据实际情况多个步骤同时进行,在此并不做限定。本申请提供的风险识别方法用于对企业破产风险进行识别。本申请提供的信息提示方法包括如下步骤:
步骤s110,获取待预测企业的信息数据;
步骤s120,根据构建的风险识别模型对所述待预测企业的信息数据进行分析处理以得到预测结果,其中,所述构建的风险识别模型为依据lightgbm机器学习算法训练建立;
步骤s130,将所述预测结果以预设的可视化方式显示于所述终端的显示界面,以供用户可以清楚地获知预测结果。
通过本申请提供的风险识别方法,通过lightgbm可以降低数据学习过程的数据处理程序,同时,可以降低更多的误差,得到更好精度决策树。同时,在风险识别模型学习过程中采用多种不同类型企业信息数据,使得建立的模型更加的完善,以确保风险预测的准确性。
下面将结合具体实施例对上述各步骤进行详细的叙述。
在步骤s110中,获取待预测企业的信息数据。
在本实施方式中,待预测企业是指待评估其经营风险的企业。信息数据包括但不限于工商信息、行政处罚、开庭公告、裁判文书、招投标、司法拍卖、商标注册、失信被执行、专利、执行等企业正面和负面的信息。
具体地,在本实施方式中,可以通过网络爬虫的方式,预先设定待预测企业的基本信息,然后通过网络爬虫自动从网上获取与该预测企业相关的信息信息数据。在其他实施方式中,也可以是待预测企业主动将与其相关的数据提供给使用本申请提供的风险识别方法的使用者,使用者利用待预测企业提供的信息数据通过下述步骤完成风险识别预测。
在步骤s120中,根据构建的风险识别模型对所述待预测企业的信息数据进行分析处理以得到预测结果,其中,所述构建的风险识别模型为依据lightgbm机器学习算法训练建立。
具体地,风险识别模型是通过lightgbm基于一定数据量的企业数据信息的学习建立的回归型决策树。lightgbm是一款机器学习框架应用,lightgbm是基于决策树算法的分布式梯度提升框架,首先,其采用直方图的方式将连续的特征值离散化,构造直方图,通过遍历数据获得直方图的统计量,遍历统计量寻找最优分割点;其次,在决策树生长树的策略上采用leaf-wise生长策略,每次从当前所有叶子中找到分类增益最大的一个叶子,然后分裂,依次循环,内存消耗低。
在本实施方式中,构建风险识别模型可以通过如下步骤进行:
步骤s1201,获取所述风险识别模型的原始训练数据;
步骤s1202,利用所述lightgbm机器学习算法对所述原始训练数据进行学习,以得到所述风险识别模型。
具体地,在本实施方式中,所述原始训练数据包括已知破产企业数据信息和非破产企业数据信息,其中,所述已知破产企业与所述非破产企业的数量比为1:1.4。举例而言,用于训练风险识别模型的训练的已知破产企业为7000家,非破产企业为10000家。其中,所述已知破产企业数据信息和非破产企业数据信息包括但不限于:工商信息、行政处罚、开庭公告、裁判文书、招投标、司法拍卖、商标注册、失信被执行、专利和判决执行信息。
其中,在步骤s1202中,在本实施方式中,包括如下步骤:
步骤s12021,将所述原始训练数据进行数值处理以得到连续的特征值数据;
步骤s12022,对所述连续的特征值数据进行离散处理以得到直方图;
步骤s12023,根据所述直方图生成所述风险识别模型。
具体地,首先对lightgbm算法的总体框架进行介绍。它是以gdbt算法为基础演进出来的轻量级算法。lightgbm算法是一种基于gbdt的机器学习算法,gbdt在函数空间是一种梯度提升算法,在参数空间体现为梯度下降方法。
(1)首先对梯度下降方法进行介绍:
首先,引入泰勒展开式:
泰勒展开的一阶展开式:f(x)=f(x0)+f'(x0)(x-x0)
泰勒展开的二阶展开式:
可以看出,泰勒展开式的本质就是:一个用函数在某点的取值描述其附近取值的公式;上面展开式是泰勒公式的基本形式,可以把它转化成迭代形式如下:
假设:xt=xt-1+δx,则泰勒公式的迭代形式如下,即将f(x)在δ×附近展开:
在机器学习模型中,要得到一个比较好的模型,通常需要最小化模型的损失函数l(θ),其中θ就是需要确定的参数,梯度下降法就是用来解决解决这类无约束优化问题的,它是通过选取参数参数初始值,不断迭代更新,直到找到损失函数的极小值;具体推导过程如下:
首先,令损失函数参数迭代形式为:θt=θt-1+δθ
然后,将l(θt)在θ(t-1)处展开:
l(θt)=l(θt-1+δθ)l(θt-1)+l'(θt-1)δθ
迭代求最小化损失函数,就是通过保证当前得到的损失函数值相比上一次得到的损失函数值要小,这样一值迭代,最终总可以得到一个极小值,数学上表示为:
l(θt)<l(θt-1)
要使上式成立,可以让l'(θt-1)δθ为负数,即令:δθ=αl'(θt-1),其中,α为步长,一般可以设定为比较小的正数;
gdbt算法在参数空间利用梯度下降法优化,参数空间具体形式为:
(1)θt=θt-1+θt
(2)θt=αtgt
(3)
上述公式(1)表示参数迭代过程,其中θt表示第t次参数迭代,θt-1表示第t-1次参数迭代,θt表示第t次迭代的参数增量;公式(2)描述了第t次迭代的参数增量为梯度的反方向,其中αt为第t次参数迭代步长,gt是梯度;公式(3)是最终的参数,它等于前面每次迭代增量的和。
(2)gdbt算法原理
类似地,其函数空间具体形式为:
(1)ft(x)=ft-1(x)+ft(x)
(2)ft(x)=αtgt(x)
(3)
上述公式(1)表示函数迭代过程,其中ft(x)表示第t次函数迭代,ft-1(x)表示第t-1次参数迭代,ft(x)表示第t次迭代的函数增量;公式(2)描述了第t次迭代的函数增量为拟合梯度gt(x)的反方向,其中αt为第t次参数迭代步长,gt是梯度;公式(3)表名最终的函数等于每次迭代增量的和.上述函数空间最终函数为求和形式,因此可称为加法模型,gbdt正是基于这一思想,其具体模型表达式为:
其中,x为输入样本,h为分类回归树,w为分类回归树的参数,α是每棵树的权值;通过最小化损失函数模型确定参数:
因为这是np难问题,因此可以通过贪心法,迭代求局部最优解;
综上,gbdt算法原理如下:
输入:(xi,yi),t,l分别对应:(输入样本特征,输入标签),迭代次数,损失函数
输出:ft,为最终确定的模型函数表达式
算法过程:
(step4)令ft=ρresht(x;wres)
更新模型:ft=ft-1+ft
具体描述:
步骤a,为计算损失函数的负梯度在当前模型的值,将它作为残差的估计;
步骤b,为学习回归树参数;
步骤c,为通过利用线性搜索估计叶节点区域值,使损失函数极小化,求步长;
步骤d,为更新回归树;
步骤e,为最终的模型表达式;
在此基础上,在步骤s12021,将所述原始训练数据进行数值处理以得到连续的特征值数据。在本实施方式中,将原始训练数据进行标准化,举例而言,将文字变量通过字典的方式进行数值转化。通过对原始数据进行清洗以得到特征数据和标记数据,然后通过对特征数据和标注数据进行处理,例如样本采样、样本调权、异常点去除、特征归一化处理等。在本实施方式中,用于训练风险识别模型的特征数据包括但不限于:注册资本(量级万)、成立年限、行业企业数量、行业企业吊销率、关联公司裁判文书被告次数、裁判文书次数、法人变更次数、商标注册数量、是否吊销、失信次数、裁判文书被告案件判决总金额、网络图法人对外投资或者任职的公司执行次数、裁判文书被告与破产有关纠纷次数、行业企业吊销数量、股东变更次数、网络图股东或者对外投资企业的执行次数、裁判文书被告合同纠纷次数、法院公告与否、网络图股东或者对外投资企业作为被告的裁判文书次数、地址变更次数。
在步骤s12022中,对所述连续的特征值数据进行离散处理以得到直方图。
具体地,直方图包括类别和每个类别所包含数量,在本实施方式中,直方图的类别以上述特征数据为分类标准。其中,连续的特征值数据指的是输入样本中有些维度的特征取值是连续的。
在具体实现时,将连续的特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点,这样就实现了离散化。在本实施方式中,计算数据的最大值和最小值,得到极差,即数据的最大值减去最小值;确定直方图的组数,然后以此极差去除组数,可得到直方图每组的宽度,即组距;确定各组的界限值,分组时应把所有的数据表都包括在内;统计各组的频数。通过上述步骤得到直方图。
在本实施方式中,步骤s12023可以包括如下步骤:
步骤a,遍历所述直方图确定类别以及对应的统计量;
步骤b,根据所述统计量确定满足预设条件的类别为最优分割点;
步骤c,以梯度提升树和所述最优分割点建立决策树以形成所述风险识别模型。
具体地,直方图离散化后的值对应为索引;遍历一次数据后,离散化后的值的统计量对应直方图索引对应的统计量;寻找最优分割点是为了实现分类,寻找最优分割点的规则:在遍历分割点的时候,对于每个数据点都使用其离散化后的值计算分裂增益,找到一个特征上的最好分割点。以二分类决策树为基础,根据分割点确定叶子,然后通过循环上述分类增益逐步确定子叶,以形成最终的风险识别模型。
进一步地,决策树的叶子所对应的直方图通过所述叶子的父节点的直方图与所述叶子的兄弟节点的直方图做差得到。通过此种方式,可以提升一倍的建树速度。
进一步地,所述决策树的建树过程中采用带深度限制的leaf-wise的叶子生长策略。具体地,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。通过此种方式,可以降低更多的误差,得到更好的精度,且保证高效率同时防止过拟合。
步骤s130,将所述预测结果以预设的可视化方式显示于所述终端的显示界面,以供用户可以清楚地获知预测结果。
通过上述实施方式,通过lightgbm机器学习算法对企业信息数据中的各个方面的数据特征进行学习,通过直方图的方式可以使用类别型数据,减少了数据标准化流程,同时,通过此种方式建立的决策树的叶子的直方图可以由它的父亲节点的直方图与它兄弟节点的直方图做差得到,提升一倍速度。并且在进行建树过程中,采用带有深度限制的按叶子生长(leaf-wise)算法,leaf-wise是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂并循环,在分裂次数相同的情况下,leaf-wise可以降低更多的误差,得到更好的精度。同时,在风险识别模型学习过程中采用多种不同类型企业信息数据,使得建立的模型更加的完善,以确保风险预测的准确性。
本申请还提供一种风险识别系统,所述风险识别系统用于对企业破产风险进行识别,所述系统包括:
数据获取模块,用于获取待预测企业的信息数据;
数据分析模块,用于根据构建的风险识别模型对所述待预测企业的信息数据进行分析处理以得到预测结果,其中,所述构建的风险识别模型为依据lightgbm机器学习算法训练建立;
显示模块,用于将所述预测结果以预设的可视化方式显示于所述终端的显示界面,以供用户可以清楚地获知预测结果。
可选地,数据分析模块,还用于获取所述风险识别模型的原始训练数据;利用所述lightgbm机器学习算法对所述原始训练数据进行学习,以得到所述风险识别模型。
可选地,数据分析模块,还用于将所述原始训练数据进行数值处理以得到连续的特征值数据;对所述连续的特征值数据进行离散处理以得到直方图;根据所述直方图生成所述风险识别模型。
可选地,数据分析模块,还用于遍历所述直方图确定类别以及对应的统计量;根据所述统计量确定满足预设条件的类别为最优分割点;以梯度提升树和所述最优分割点建立决策树以形成所述风险识别模型。
需要说明的是,在系统方法实施方式的内容同样可以采用前述的方法实施方式中的内容,故,在此不做赘述。
本申请不局限于上述可选实施方式,任何人在本申请的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是落入本申请权利要求界定范围内的技术方案,均落在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!