一种图片多标签分类方法与流程
本发明涉及计算机的图像深度学习领域,特别是涉及一种图片多标签分类方法。
背景技术:
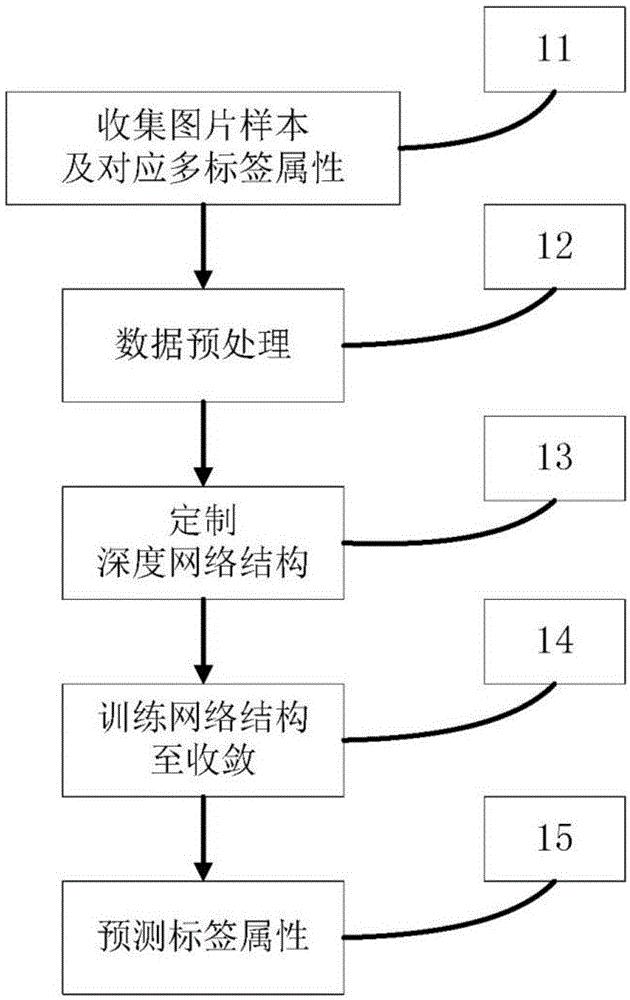
:1张图片包含多元信息,图片分类技术只允许1张图片对应1个预测目标,如手写数字识别,1张手写数字图片仅对应1个0-9的数字识别结果,不能预测出字体风格,书写美观度等多重属性,往往不能满足应用的需求。因此,需要一种图片分类方法,能允许1个输入样本对应1组目标输出,即1张图片预测1组与之相关的标签属性,这样可以更方便地进行图片筛选,素材分类归档等任务。在工程应用中,能获取到的图片样本规模因项目而异,时多时少,针对不同样本规模,需要构造不同复杂程度的网络结构进行训练,才能得到可靠预测效果,否则无法达到应用门槛。技术实现要素:本发明所要解决的技术问题是克服现有技术的不足,提供一种图片多标签分类方法。为解决上述技术问题,本发明提供一种图片多标签分类方法,其特征在于,包括如下步骤:步骤1、收集图片样本,所述图片样本规模至少在100k张;整理每张图对应的1组标签属性,所述1组标签属性至少包含2个标签属性,所述不同标签属性之间互相独立,不存在范围重叠或包含关系;步骤2、数据的预处理,将每张图片尺寸更改为224×224×3;步骤3、根据训练样本规模,定制的深度网络结构,所述深度网络结构由keras定制,网络输出类别数即标签类别数;所述深度网络结构包括至少5个卷积层:卷积层由至少32个卷积核串联构成,全连接层包含256个节点,dropout随机丢弃节点设为0.5,并行soft-max(parallel-soft-max)用于分别预测各类标签属性,各soft-max层并联连接;步骤4、以预测各类标签的平均损失为目标,训练至收敛;步骤5、训练完成,预测待测图片的标签属性。所述步骤3中,当样本数量在100k-1000k张,则构建包含5个卷积层的深度网络,其中包括2个由32个3×3卷积核(conv3-32)串联构成和3个由64个3×3卷积核(conv3-64)串联构成的卷积层。所述步骤3中,当样本数量在1000k-10000k张,则构建包含7个卷积层的深度网络,其中包括2个由64个3×3卷积核(conv3-64)串联构成、2个由128个3×3卷积核(conv3-128)串联构成的和3个由256个3×3卷积核(conv3-256)串联构成的卷积层。所述步骤3中,当样本数量在10000k张以上时,则构建包含9个卷积层的深度网络,其中包括2个由64个3×3卷积核(conv3-64)串联构成、2个由128个3×3卷积核(conv3-128)串联构成的、2个由256个3×3卷积核(conv3-256)串联构成的、3个由512个3×3卷积核(conv3-512)串联构成的卷积层和1个512个1×1卷积核(conv1-512)卷积层。本发明所达到的有益效果:在大批量样本训练的情况下,深度学习分类预测效果优于机器学习(100k样本规模时,机器学习已无法超过90%准确率,随着样本规模继续增加,机器学习预测效果出现瓶颈,无法提升);在工程应用中,能获取到的图片样本规模因项目而异,时多时少,针对不同样本规模,需要构造不同复杂程度的网络结构进行训练,才能得到可靠预测效果,否则无法达到应用门槛;本发明着手3类样本规模(100k张以上,1000k张以上,10000k张以上),定制适配的深度网络结构,构造合适的网络结构训练至收敛,已得到可靠的多标签分类模型,取得平均96%的高准确率(样本规模相对少时,选择100k张以上样本网络结构,此网络层数较少,在当前规模能够收敛,准确率约94%;样本规模适中时,选择1000k张以上样本网络结构,此网络层数适中,在当前规模能够收敛,准确率约96%;样本规模相对多时,选择10000k张以上样本网络结构,此网络结构层数较多,在当前规模能够收敛,准确率约98%);多标签分类在多分类基础上再进一层,可以预测图片的一组标签属性,能更完美地迎合图片筛选,素材分类归档等任务。附图说明图1为本发明的示例性实施例的方法流程图;图2为本发明的示例性实施例中的深度网络结构示意图;图3为本发明的示例性实施例中的ml_net序贯模型示意图;图4为本发明的示例性实施例中的训练准确性变化示意图;图5为本发明的示例性实施例中的训练平均损失变化示意图。具体实施方式下面结合附图和示例性实施例对本发明作进一步的说明,完整展示多标签分类流程,其他多标签分类任务,只需更换样本,可以套用本发明的网络结构,得到可靠预测效果:一种图片多标签分类方法,其特征在于,包括如下步骤:步骤1、收集足量图片样本,所述图片样本规模至少在100k张,整理每张图对应的1组标签属性,所述1组标签属性至少包含2个标签属性,否则等同于图片分类;例如,1张图对应标签1,标签2,标签3,标签4,则这4个标签属性互相独立,不存在范围重叠或包含关系;步骤2、数据的预处理,将每张图片尺寸更改为224×224×3;步骤3、根据训练样本规模,定制适配的深度网络结构,网络输出类别数即标签类别数;所述深度网络结构包括至少5个卷积层:卷积层由至少32个卷积核串联构成,全连接层包含256个节点,dropout随机丢弃节点设为0.5,并行soft-max(parallel-soft-max)用于分别预测各类标签属性,各soft-max层并联连接;步骤4、以预测各类标签的平均损失为目标,训练至收敛;步骤5、训练完成,预测待测图片的标签属性。所述步骤3中,当样本数量在100k-1000k张,则构建包含5个卷积层的深度网络,其中包括2个由32个3×3卷积核(conv3-32)串联构成和3个由64个3×3卷积核(conv3-64)串联构成的卷积层。此网络层数较少,在样本规模相对少的场景能够收敛,准确率约94%。所述步骤3中,当样本数量在1000k-10000k张,则构建包含7个卷积层的深度网络,其中包括2个由64个3×3卷积核(conv3-64)串联构成、2个由128个3×3卷积核(conv3-128)串联构成的和3个由256个3×3卷积核(conv3-256)串联构成的卷积层。此网络层数适中,在样本规模适中的场景能够收敛,准确率约96%。所述步骤3中,当样本数量在10000k张以上时,则构建包含9个卷积层的深度网络,其中包括2个由64个3×3卷积核(conv3-64)串联构成、2个由128个3×3卷积核(conv3-128)串联构成的、2个由256个3×3卷积核(conv3-256)串联构成的、3个由512个3×3卷积核(conv3-512)串联构成的卷积层和1个512个1×1卷积核(conv1-512)卷积层。此网络层数较多,在样本规模相对多的场景能够收敛,准确率约98%。上述适配不同规模样本规模的深度网络结构如表1所示:表1适配不同样本规模的深度网络结构如图1所示,由于图片多标签分类胜任的任务繁多,无法一一枚举,这里以人物设计素材库标签分类为例,完成“图中有2名拉丁美洲男性青年”这样的定制检索需求。步骤11、收集图片样本及对应多标签属性,可通过购买,抓取,人工标注等方式,样本数量至少在100k张,否则训练可能不收敛,或者预测效果不佳,见表2:标签属性分为4类,人种(全部,高加索系,非洲系,亚洲系,拉丁美洲系),年龄(全部,婴儿,儿童,青年,成人,老人),人数(无,1,2,3,4及以上),性别(全部,男,女);人物图片样本及对应多标签属性如表2所示:表2人物图片样本及对应多标签属性人种年龄人数性别标签1全部全部无全部标签2高加索系婴儿1男标签3非洲系儿童2女标签4亚洲系青年3--标签5拉丁美洲系成人4及以上--标签6--老人----步骤12、数据预处理,将每张图片尺寸更改为224×224×3;步骤13、定制深度网络结构,以keras包定制深度网络结构数为4,即fc_race、fc_age、fc_amount和,fc_gender,相互之间并联连接,代码如下:fromkeras.layersimportconv2d,dense,dropout,flatten,input,maxpooling2dfromkeras.modelsimportmodel,sequentialml_net=sequential(name='ml_net')ml_net.add(conv2d(32,(3,3),activation='relu',padding='same',input_shape=(224,224,3),name='conv1'))ml_net.add(conv2d(32,(3,3),activation='relu',padding='same',name='conv2'))ml_net.add(maxpooling2d(pool_size=(2,2),name='pool1'))ml_net.add(conv2d(64,(3,3),activation='relu',padding='same',name='conv3'))ml_net.add(conv2d(64,(3,3),activation='relu',padding='same',name='conv4'))ml_net.add(conv2d(64,(3,3),activation='relu',padding='same',name='conv5'))ml_net.add(maxpooling2d(pool_size=(2,2),name='pool2'))ml_net.add(flatten(name='flat'))ml_net.add(dense(256,activation='relu',name='fc'))ml_net.add(dropout(0.5,name='drop'))img_input=input(shape=(224,224,3),name='img_input')img_feature=ml_net(img_input)output1=dense(5,activation='softmax',name='fc_race')(img_feature)output2=dense(6,activation='softmax',name='fc_age')(img_feature)output3=dense(5,activation='softmax',name='fc_amount')(img_feature)output4=dense(3,activation='softmax',name='fc_gender')(img_feature)ml_model=model(inputs=img_input,outputs=[output1,output2,output3,output4])整体网络结构见图2,待训练参数为51487859个,其中ml_net序贯模型结构见图3:步骤14、训练网络结构至收敛,以fc_race,fc_age,fc_amount,fc_gender的平均损失为目标,batch_size=128(每批训练的图片数,所有批次的图片训练完为1个epoch),训练准确性变化见图4,平均损失变化见图5,均已至收敛,不再大幅波动;步骤15、预测标签属性,训练完成,预测图片的1组标签属性。本发明主要用于提供一种图片多标签分类方法,在大批量样本训练的情况下,深度学习分类预测效果优于机器学习(100k样本规模时,机器学习已无法超过90%准确率,随着样本规模继续增加,机器学习预测效果出现瓶颈,无法提升);在工程应用中,能获取到的图片样本规模因项目而异,时多时少,针对不同样本规模,需要构造不同复杂程度的网络结构进行训练,才能得到可靠预测效果,否则无法达到应用门槛;本发明着手3类样本规模(100k张以上,1000k张以上,10000k张以上),定制适配的深度网络结构,构造合适的网络结构训练至收敛,已得到可靠的多标签分类模型,取得平均96%的高准确率(样本规模相对少时,选择100k张以上样本网络结构,此网络层数较少,在当前规模能够收敛,准确率约94%;样本规模适中时,选择1000k张以上样本网络结构,此网络层数适中,在当前规模能够收敛,准确率约96%;样本规模相对多时,选择10000k张以上样本网络结构,此网络结构层数较多,在当前规模能够收敛,准确率约98%);多标签分类在多分类基础上再进一层,可以预测图片的一组标签属性,能更完美地迎合图片筛选,素材分类归档等任务。以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1