一种基于深度学习的数据编码芯片和方法与流程
本发明涉及芯片硬件电路领域,特别涉及一种基于深度学习的数据编码芯片和方法。
背景技术:
当前,在采用摄像头进行拍摄过程中,在采集的音频信息中出现了一些不期望出现的声音,比如有路人骂脏话或者其他一些不期望出现的声音出现,这种情况下,用户往往只能手动对音轨进行编辑,以便对不期望出现的声音进行删除,这种方式不仅花费了大量的人力和时间,同时也会导致音频信息由于部分音段的删除出现间断,影响了用户体验。
技术实现要素:
为此,需要提供一种基于深度学习的数据编码的技术方案,用以解决当采集的音频流中出现敏感词汇或者当拍摄视频流画面中出现用户不期望看到的物体时,需要用户手动去除,费时费力的问题。
为实现上述目的,发明人提供了一种基于深度学习的数据编码芯片所述芯片包括音频处理模块,所述音频处理模块包括语音识别单元、敏感词判断单元、敏感词处理单元和语音合成单元;
所述语音识别单元用于接收语音采集单元采集的音频信息,对采集的音频信息进行语音识别,并将语音识别结果发送至敏感词判断单元;所述语音识别结果包括采集的音频信息对应的文字信息,以及各个文字信息在音频信息内的时间戳信息;
所述敏感词判断单元用于接收音频信息的语音识别结果,判断音频信息对应的文字信息中是否包括有预先存储的敏感词,若是则第一音段信息存储于第一缓存单元中,所述第一音段信息为敏感词对应的音段信息;
所述敏感词处理单元用于根据敏感词与处理方式的对应关系,采用相应的处理方式对第一音段信息进行处理,得到音段处理信息,并将音段处理信息发送至语音合成单元;
所述语音合成单元用于根据第一音段信息对应的时间戳信息,将音段处理信息更换至音频信息中的对应位置,从而得到新的音频信息。
进一步地,所述敏感词判断单元还用于判定音频信息对应的文字信息中包含有预先设置的敏感词时,将第二音段信息存储于第二缓存单元中,所述第二音段信息为非敏感词对应的音段信息;
所述敏感词处理单元用于从第二缓存单元中获取第一音段信息前后的第二音段信息,并根据获取的第二音段信息预测出音频处理信息。
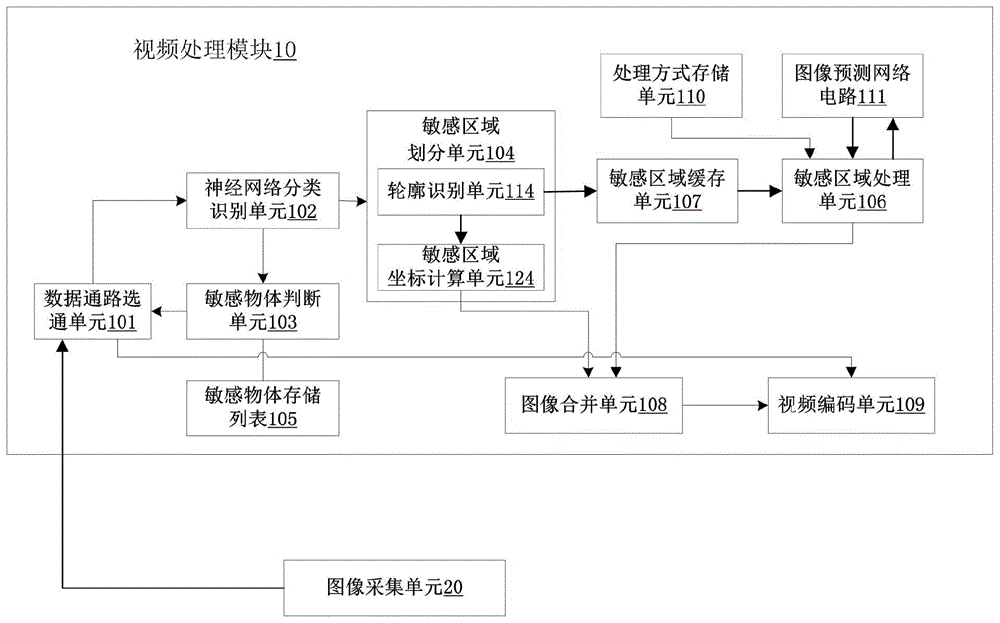
进一步地,所述芯片包括视频处理模块,所述视频处理模块包括数据通路选择单元、神经网络分类识别单元、敏感物体判断单元、敏感区域划分单元、敏感物体存储列表、敏感区域处理单元、敏感区域缓存单元、图像合并单元、视频编码单元;
所述数据通路选择单元用于接收图像采集单元采集的视频流数据,并将当前帧图像发送至神经网络分类识别单元;
所述神经网络分类识别单元用于对当前帧图像进行物体识别,并将物体识别结果发送至敏感物体判断单元;
所述敏感物体判断单元用于根据当前帧图像的物体识别结果,判断当前帧图像中是否包含有敏感物体存储列表中预先存储的敏感物体,若是则发送第一控制信号至数据通路选择单元,否则发送第二控制信号至数据通路选择单元;
所述数据通路选择单元用于接收第一控制信号,将当前帧图像之后的连续n帧图像传输至神经网络分类识别单元;或者,用于接收第二控制信号,将当前帧图像之后的连续m帧图像传输至视频编码单元进行编码处理;n、m为正整数;
所述敏感区域划分单元用于在当前帧图像中存在敏感物体的情况下,接收神经网络分类识别单元传输的当前帧图像,并划分出当前帧图像对应的敏感区域图像,并将敏感区域图像存储于敏感区域缓存单元中;所述敏感区域图像包含有敏感物体;
所述敏感区域处理单元用于获取敏感区域缓存单元中的敏感区域图像,根据敏感物体与处理方式的对应关系,采用相应地处理方式处理敏感区域图像,并将处理结果发送至图像合并单元;
所述图像合并单元用于接收当前帧图像和处理后的敏感区域图像,根据敏感区域图像在当前帧图像上的坐标位置,将处理后的敏感区域图像和当前帧图像合成为处理帧图像,并将所述处理帧图像传输至视频编码单元进行编码。
进一步地,所述敏感区域划分单元包括轮廓识别单元和敏感区域坐标计算单元;
所述轮廓识别单元用于识别出敏感区域图像中敏感物体的轮廓位置信息,所述轮廓位置信息以“第一标识行-第一起始坐标点-第一结束坐标点”的方式进行存储;
所述敏感区域坐标计算单元用于根据轮廓位置信息、以及敏感区域图像在当前帧图像中的坐标信息,计算敏感区域图像内的敏感物体在当前帧图像中的坐标位置信息,并将所述坐标位置信息以“第二标识行-第二起始坐标点-第二结束坐标点”的方式进行存储;
所述第二标识行的数值为第一标识行的数值与敏感区域图像在当前帧图像内的起始行之和,所述第二起始坐标点为第一起始坐标点与敏感区域图像在当前帧图像内的起始列之和,所述第二结束坐标点为第二结束坐标点与敏感区域图像在当前帧图像内的起始列之和。
进一步地,所述视频处理模块还包括图像预测网络电路;
所述图像预测网络电路用于根据敏感区域图像、当前帧图像、以及敏感区域图像在当前帧图像的坐标位置,根据预测出新的区域图像,并将新的区域图像送往图像合并单元。
发明人还提供了一种基于深度学习的数据编码方法,所述方法应用于基于深度学习的数据编码芯片,所述芯片包括音频处理模块,所述音频处理模块包括语音识别单元、敏感词判断单元、敏感词处理单元和语音合成单元;所述方法包括以下步骤:
语音识别单元接收语音采集单元采集的音频信息,对采集的音频信息进行语音识别,并将语音识别结果发送至敏感词判断单元;所述语音识别结果包括采集的音频信息对应的文字信息,以及各个文字信息在音频信息内的时间戳信息;
敏感词判断单元接收音频信息的语音识别结果,判断音频信息对应的文字信息中是否包括有预先存储的敏感词,若是则第一音段信息存储于第一缓存单元中,所述第一音段信息为敏感词对应的音段信息;
敏感词处理单元根据敏感词与处理方式的对应关系,采用相应的处理方式对第一音段信息进行处理,得到音段处理信息,并将音段处理信息发送至语音合成单元;
语音合成单元根据第一音段信息对应的时间戳信息,将音段处理信息更换至音频信息中的对应位置,从而得到新的音频信息。
进一步地,所述方法包括以下步骤:
敏感词判断单元判定音频信息对应的文字信息中包含有预先设置的敏感词时,将第二音段信息存储于第二缓存单元中,所述第二音段信息为非敏感词对应的音段信息;
敏感词处理单元从第二缓存单元中获取第一音段信息前后的第二音段信息,并根据获取的第二音段信息预测出音频处理信息。
进一步地,所述芯片包括视频处理模块,所述视频处理模块包括数据通路选择单元、神经网络分类识别单元、敏感物体判断单元、敏感区域划分单元、敏感物体存储列表、敏感区域处理单元、敏感区域缓存单元、图像合并单元、视频编码单元;所述方法包括:
数据通路选择单元接收图像采集单元采集的视频流数据,并将当前帧图像发送至神经网络分类识别单元;
神经网络分类识别单元对当前帧图像进行物体识别,并将物体识别结果发送至敏感物体判断单元;
敏感物体判断单元根据当前帧图像的物体识别结果,判断当前帧图像中是否包含有敏感物体存储列表中预先存储的敏感物体,若是则发送第一控制信号至数据通路选择单元,否则发送第二控制信号至数据通路选择单元;
数据通路选择单元接收第一控制信号,将当前帧图像之后的连续n帧图像传输至神经网络分类识别单元;或者,用于接收第二控制信号,将当前帧图像之后的连续m帧图像传输至视频编码单元进行编码处理;n、m为正整数;
敏感区域划分单元在当前帧图像中存在敏感物体的情况下,接收神经网络分类识别单元传输的当前帧图像,并划分出当前帧图像对应的敏感区域图像,并将敏感区域图像存储于敏感区域缓存单元中;所述敏感区域图像包含有敏感物体;
敏感区域处理单元获取敏感区域缓存单元中的敏感区域图像,根据敏感物体与处理方式的对应关系,采用相应地处理方式处理敏感区域图像,并将处理结果发送至图像合并单元;
图像合并单元接收当前帧图像和处理后的敏感区域图像,根据敏感区域图像在当前帧图像上的坐标位置,将处理后的敏感区域图像和当前帧图像合成为处理帧图像,并将所述处理帧图像传输至视频编码单元进行编码。
进一步地,所述敏感区域划分单元包括轮廓识别单元和敏感区域坐标计算单元;所述方法包括:
轮廓识别单元识别出敏感区域图像中敏感物体的轮廓位置信息,所述轮廓位置信息以“第一标识行-第一起始坐标点-第一结束坐标点”的方式进行存储;
敏感区域坐标计算单元根据轮廓位置信息、以及敏感区域图像在当前帧图像中的坐标信息,计算敏感区域图像内的敏感物体在当前帧图像中的坐标位置信息,并将所述坐标位置信息以“第二标识行-第二起始坐标点-第二结束坐标点”的方式进行存储;
所述第二标识行的数值为第一标识行的数值与敏感区域图像在当前帧图像内的起始行之和,所述第二起始坐标点为第一起始坐标点与敏感区域图像在当前帧图像内的起始列之和,所述第二结束坐标点为第二结束坐标点与敏感区域图像在当前帧图像内的起始列之和。
进一步地,所述视频处理模块还包括图像预测网络电路;所述方法包括:
图像预测网络电路根据敏感区域图像、当前帧图像、以及敏感区域图像在当前帧图像的坐标位置,根据预测出新的区域图像,并将新的区域图像送往图像合并单元。
区别于现有技术,上述技术方案所述的基于深度学习的数据编码芯片和方法,所述方法通过语音识别单元将采集的音频信息转换为文字信息,并将得到的文字信息与预先存储的敏感词汇进行比对,当转换得到的文字信息中存在着敏感词汇时,采用该敏感词汇对应的处理方式对相应的音段信息进行处理,从而达到自动消除音频信息中敏感声音(即敏感词汇对应的音段信息)的目的。相较于人工识别判断的方式,有效提升了数据处理效率。
附图说明
图1为本发明一实施方式涉及的视频处理模块的示意图;
图2为本发明一实施方式涉及的视频处理方法的流程图;
图3本发明一实施方式涉及的神经网络分类识别单元进行物体识别的示意图;
图4为本发明一实施方式涉及的轮廓识别单元进行物体轮廓识别的示意图;
图5为本发明一实施方式涉及的图像预测网络电路进行处理后的敏感区域预测的示意图;
图6为本发明一实施方式涉及的音频处理方法的流程图;
图7为本发明一实施方式涉及的音频处理模块的示意图。
附图标记说明:
10、视频处理模块;
101、数据通路选择单元;102、神经网络分类识别单元;103、敏感物体判断单元;
104、敏感区域划分单元;114、轮廓识别单元;124、敏感区域坐标计算单元;
105、敏感物体存储列表;106、敏感区域处理单元;107、敏感区域缓存单元;108、图像合并单元;109、视频编码单元;110、处理方式存储单元;111、图像预测网络电路;
20、图像采集单元;
30、音频处理模块;
301、语音识别单元;302、敏感词判断单元;303、敏感词坐标计算单元;304、敏感词列表;305、敏感词处理单元;306、语音处理配置存储单元;307、声音预测网络电路单元;308、语音合成单元;309、语音编码单元;310、第一缓存单元。
40、语音采集单元。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
本发明提供了一种基于深度学习的数据编码芯片,所述芯片包括音频处理模块,请参阅图,7,本发明一实施方式所述的音频处理模块的示意图。所述音频处理模块包括语音识别单元301、敏感词判断单元302、敏感词处理单元305和语音合成单元308;
所述语音识别单元301用于接收语音采集单元40采集的音频信息,对采集的音频信息进行语音识别,并将语音识别结果发送至敏感词判断单元302。所述语音识别结果包括采集的音频信息对应的文字信息,以及各个文字信息在音频信息内的时间戳信息。
所述语音采集单元20为具有音频流数据采集的电子设备,如可以是一个麦克风。通常视频流数据包括多帧图像,音视频的编码是基于一帧一帧图像而进行的。在本实施方式中,采集的音频信息也可以是当前帧的音频段信息,即播放当前帧画面时同步播放的语音信息。
在本实施方式中,所述时间戳信息通过敏感词坐标计算单元303来计算完成,时间戳信息包括各个文字信息所在的画面帧的音频段,以及各个文字信息在该音频段内的时间。优选的,为了节省传输的数据量,在传输过程中,只需要传输敏感词(包括一个或多个文字信息)对应的音段信息在对应的语音帧中的起止时间。
所述敏感词判断单元302用于接收音频信息的语音识别结果,判断音频信息对应的文字信息中是否包括有预先存储的敏感词,若是则第一音段信息存储于第一缓存单元310中,所述第一音段信息为敏感词对应的音段信息。在本实施方式中,预先存储的敏感词可以存储于敏感词列表304中。
所述敏感词处理单元305用于根据敏感词与处理方式的对应关系,采用相应的处理方式对第一音段信息进行处理,得到音段处理信息,并将音段处理信息发送至语音合成单元。在本实施方式中,敏感词的处理方式存储于语音处理配置存储单元中,敏感词的处理方式包括但不限于加噪处理、消音处理、对抗生成语音等。
所述语音合成单元308用于根据第一音段信息对应的时间戳信息,将音段处理信息更换至音频信息中的对应位置,从而得到新的音频信息。在某些实施例中,所述音频处理模块30还包括语音编码单元309,所述语音编码单元309用于接收语音合成单元处理得到的新的音频信息,并对新的音频信息进行编码。
在某些实施例中,所述敏感词判断单元302还用于判定音频信息对应的文字信息中包含有预先设置的敏感词时,将第二音段信息存储于第二缓存单元中,所述第二音段信息为非敏感词对应的音段信息;
所述敏感词处理单元305用于从第二缓存单元中获取第一音段信息前后的第二音段信息,并根据获取的第二音段信息预测出音频处理信息。
优选的,敏感词的处理方式选用对抗生成语音的方式进行处理,所述音频处理模块30还包括声音预测网络电路生成单元307,敏感词处理单元对第一音段信息的处理是通过声音预测网络电路生成单元307来实现的。具体地,声音预测网络电路生成单元307先将敏感词对应的音段信息处理为空白信息,而后再从第二缓存单元中获取位于敏感词的起始点之前的音段信息以及敏感词的结束点之后的音段信息,并根据前后的音段信息重新预测产生空白信息位置的音段信息,并将新产生的音段信息传输给敏感词处理单元305,敏感词处理单元305接收声音预测网络电路生成单元307传输的音段信息,根据敏感词所在的时间戳信息,将其覆盖至第一音段信息所在的位置。
相比于加噪或者消音处理的方式,采用声音预测网络电路生成单元(即对抗神经网络)对第一音段信息进行处理,能够使得音频流的播放更加流畅,有效提升用户的视听体验。对抗神经网络根据前后音段信息生成中间音段信息的过程,此为现有技术,具体可以参考以下链接:
http://www.sohu.com/a/153964865_468740。
请参阅图6,为本发明一实施方式涉及的音频处理方法的流程图。所述方法包括以下步骤:
首先进入步骤s601语音识别单元接收语音采集单元采集的音频信息,对采集的音频信息进行语音识别,并将语音识别结果发送至敏感词判断单元;所述语音识别结果包括采集的音频信息对应的文字信息,以及各个文字信息在音频信息内的时间戳信息;
而后进入步骤s602敏感词判断单元接收音频信息的语音识别结果,判断音频信息对应的文字信息中是否包括有预先存储的敏感词,由于该处理是实时处理的,如果没有就不用进行处理,而是继续进行语音识别。若是则进入步骤s603将第一音段信息存储于第一缓存单元中,所述第一音段信息为敏感词对应的音段信息;
步骤s603后可以进入步骤s604敏感词处理单元根据敏感词与处理方式的对应关系,采用相应的处理方式对第一音段信息进行处理,得到音段处理信息,并将音段处理信息发送至语音合成单元;
步骤s604后可以进入步骤s605语音合成单元根据第一音段信息对应的时间戳信息,将音段处理信息更换至音频信息中的对应位置,从而得到新的音频信息。
视频画面在播放过程中,除了播放的音频信息可能存在着敏感声音段之外,画面上显示的字幕信息也可能存在着敏感词汇,因而还需要对画面上字幕显示的敏感词汇进行处理。具体地,在执行步骤s605时还可以执行以下步骤s606:当判定某一帧音频段存在着敏感声音时,在语音合成单元生成该帧新的音频信息后,将会把新的音频信息重新转换为文字信息,并将转换得到的文字信息覆盖至该帧画面原有的字幕位置。由于新的音频信息是经过处理后的音频信息,其中不包含有敏感词汇,因而其转换的文字信息也不包含原有敏感信息,从而在对音频信息中敏感声音处理的同时,也实现了对字幕信息中敏感词汇的处理。在某些实施例中,也可以通过当判定某一帧音频段存在着敏感声音时,识别该帧画面上的字幕为文字信息,获取文字信息中与敏感声音对应的文字位置,在该帧画面的文字位置上进行模糊处理(如马赛克处理),这样就可以避免显示该敏感声音对应的字幕。
视频流数据在播放过程中,当音频数据中存在着敏感词汇时,该音频数据时间段内对应的视频画面往往也存在着敏感物体,为了进一步简化视频数据的处理步骤,节省电路功耗,在某些实施例中,所述芯片还包括丢帧判断单元,所述方法在执行步骤s605时,还可以包括以下步骤:丢帧判断单元直接接收摄像头采集的视频流数据,并根据敏感词处理单元传输的第一音段信息对应的时间戳信息,直接对所述时间戳信息对应的视频流数据进行丢帧处理,丢帧处理不仅可以实现对画面的处理,同时也一并对音频进行处理。从而实现了对大概率存在敏感物体的视频流画面的快速处理,提升了处理效率。
在某些实施例中,本发明的芯片还包括视频处理模块10,请参阅图1,为本发明一实施方式所述的视频处理模块的示意图。所述视频处理模块10包括数据通路选择单元101、神经网络分类识别单元102、敏感物体判断单元103、敏感区域划分单元104、敏感物体存储列表105、敏感区域处理单元106、敏感区域缓存单元107、图像合并单元108、视频编码单元109;
所述数据通路选择单元101分别与图像采集单元20、敏感物体判断单元103、神经网络分类识别单元102连接;所述神经网络分类识别单元102与敏感区域划分单元104、敏感物体判断单元103连接;所述敏感物体判断单元103与敏感物体存储列表105连接;所述敏感区域划分单元104与敏感区域缓存单元107连接,所述敏感区域缓存单元107与图像合并单元108连接,所述图像合并单元108与视频编码单元109连接;
所述数据通路选择单元101用于接收图像采集单元20采集的视频流数据,并将当前帧图像发送至神经网络分类识别单元102。所述图像采集单元20为具有视频流数据采集的电子设备,如可以是一个摄像头。通常视频流数据包括多帧图像,视频的编码是基于一帧一帧图像而进行的。所述数据通路选择单元101为具有控制信号选择功能的电子元件,其可以选择将摄像头采集的当前帧图像直接发送给视频编码单元进行编码,也可以选择将当前帧图像发送至神经网络分类识别单元102进行分类识别,数据通路选择单元选择的依据在下方展开详细说明。
所述神经网络分类识别单元102用于对当前帧图像进行物体识别,并将物体识别结果发送至敏感物体判断单元。如图3所示,神经网络分类识别单元不仅可以识别出某一张图像包括中哪些物体,通常还能以特定形状(如矩形、圆形等)框出这些物体对应的位置区域。例如当前帧图像为一张草原图片,该图像除了背景是大部分草之外,还存在着白云、垃圾桶、花、树等物体。当这张图像被传输至神经网络分类识别单元后,神经网络分类识别单元能够识别出白云、垃圾桶、花、树等物体,并将这些物体在图像上的大致区域(一般为恰好能包含对应物体的固定图形)圈出。
图像上目标区域检测和物体识别是较成熟技术,所述神经网络分类识别电路包括:fast-rcnn神经网络电路、ssd神经网络电路、yolo神经网络电路。fast-rcnn神经网络电路相关实现方式可以参考以下链接:https://blog.csdn.net/xiaoye5606/article/details/71191429。ssd神经网络电路、yolo神经网络电路的实现方式可以参考以下链接:
http://www.360doc.com/content/17/0810/10/10408243678091430.shtml
https://www.cnblogs.com/fariver/p/7446921.html。
所述敏感物体判断单元103用于根据当前帧图像的物体识别结果,判断当前帧图像中是否包含有敏感物体存储列表105中预先存储的敏感物体,若是则发送第一控制信号至数据通路选择单元,否则发送第二控制信号至数据通路选择单元。
所述敏感物体是指用户事先自定义需要进行特殊处理的物体,既可以是某个物体形象,如垃圾桶,也可以是某段以图片形式呈现的文字,如一些敏感词汇。同样以前文所述的草原图像为例,假设敏感物体为垃圾桶,那么在敏感物体存储列表中存储有垃圾桶的相关参数,以便敏感物体判断单元进行获取判断。
所述数据通路选择单元101用于接收第一控制信号,将当前帧图像之后的连续n帧图像传输至神经网络分类识别单元;或者,用于接收第二控制信号,将当前帧图像之后的连续m帧图像传输至视频编码单元进行编码处理;n、m为正整数。n、m的数值既可以相同,也可以不同。
在实际应用过程中,可以在数据通路选择单元(即数据通路选通开关)内置一个帧计数器,摄像头采集到的第一帧图像会被送往cnn分类单元(即神经网络分类识别单元)进行物体识别。当敏感物体判断单元判定第一帧图像中没有出现敏感物体时,其会发送第一控制信号至数据通路选择单元,数据通路选择单元会将当前帧图像之后连续的5帧图像(假设m的值为5)都不再送往cnn分类单元进行分类判断,而是直接将这5帧图像送往视频编码单元进行视频编码,并且直到当前帧图像之后的第6帧图像,再将其送往cnn分类单元进行物体识别。
如果第一帧图像被敏感物体判断单元判定为出现了敏感物体,那么敏感物体判断单元会发送第二控制信号至数据通路选择单元,数据通路选择单元会将当前帧图像之后连续的6帧图像(假设n的值为6)都送往cnn分类单元进行分类判断,直到摄像头采集到当前帧图像之后的第7帧图像时,再将第7帧图像发送给cnn分类单元进行识别,而后再根据第7帧图像是否存在敏感物体,决定是将第7帧之后的连续n帧图像送往cnn分类单元进行识别,还是直接将第7帧之后的连续n帧图像送往视频编码单元进行编码。
这样,当某一帧图像识别出敏感物体时,则会对接下来几帧图像都进行物体识别,反之,当某一帧图像未识别出敏感物体时,则对接下来几帧图像直接进行编码输出而不进行物体识别,相较于对每一帧图像都进行识别判断的方式,有效提升了处理效率。
所述敏感区域划分单元104用于在当前帧图像中存在敏感物体的情况下,接收神经网络分类识别单元传输的当前帧图像,并划分出当前帧图像对应的敏感区域图像,并将敏感区域图像存储于敏感区域缓存单元中;所述敏感区域图像包含有敏感物体。
所述敏感区域划分单元104包括轮廓识别单元114和敏感区域坐标计算单元124。轮廓识别单元进行敏感区域中敏感物体的轮廓识别如图4所示。
所述轮廓识别单元114用于识别出敏感区域图像中敏感物体的轮廓位置信息,所述轮廓位置信息以“第一标识行-第一起始坐标点-第一结束坐标点”的方式进行存储;
所述敏感区域坐标计算单元124用于根据轮廓位置信息、以及敏感区域图像在当前帧图像中的坐标信息,计算敏感区域图像内的敏感物体在当前帧图像中的坐标位置信息,并将所述坐标位置信息以“第二标识行-第二起始坐标点-第二结束坐标点”的方式进行存储;
所述第二标识行的数值为第一标识行的数值与敏感区域图像在当前帧图像内的起始行之和,所述第二起始坐标点为第一起始坐标点与敏感区域图像在当前帧图像内的起始列之和,所述第二结束坐标点为第二结束坐标点与敏感区域图像在当前帧图像内的起始列之和。
例如敏感物体为垃圾桶,神经网络分类识别单元识别出的敏感区域为包含有垃圾桶的矩形区域,那么轮廓识别单元会从所述敏感区域识别出“垃圾桶”的轮廓,并将轮廓对应的坐标点计算出来,送往敏感区域坐标计算单元。轮廓区域存储格式为:图像行数,敏感物起始像素点,结束像素点。比如:一个垃圾桶,轮廓信息为:第300行,50像素点到150点;301行,51像素点到148像素点;302行,52像素点到149像素点等等。通过上述格式,可以将整个敏感物体的轮廓信息通过“第一标识行-第一起始坐标点-第一结束坐标点”的方式进行存储。
而敏感区域在当前帧图像中的起始行为第200行,起始列为第300列,那么当敏感物体在敏感区域内的坐标换算为敏感物体在整个当前帧图像内的坐标时,假设垃圾桶的轮廓信息中某一行的存储格式为“第300行,50像素点到150点”,那么经过划算后该行的存储格式为“第500行,第350像素值450像素点”,其他行同理可得。
轮廓识别是现有成熟技术,轮廓识别单元可以为fcn电路,参考链接如下:https://www.cnblogs.com/gujianhan/p/6030639.html,也可以为deeplab网络电路,参考链接如下:
https://baijiahao.baidu.com/s?id=1595995875370065359&wfr=spider&for=pc。
所述敏感区域处理单元106用于获取敏感区域缓存单元107中的敏感区域图像,根据敏感物体与处理方式的对应关系,采用相应地处理方式处理敏感区域图像,并将处理结果发送至图像合并单元108。在本实施方式中,敏感区域图像内敏感物体的处理方式包括以下一种或多种:马赛克处理、二值化处理、添加遮挡标识。处理方式的类型,可以预先存储于处理方式存储单元110中。
马赛克处理是指在敏感区域图像以4x4或者8x8为单位处理宏块,将宏块内的图像像素值取平均值,并将该平均值重新赋值给该图像块内的所有像素点,用该方法覆盖全部敏感图像区域,完成马赛克处理。
二值化是指将敏感区域图像内所有像素点的像素值全部赋值为0或者255,也就是对应为黑色或白色。采用的做法可以是像素值大于某个预设值的像素点全部赋值为255,像素值小于某个预设值的像素点全部赋值为0.
添加遮挡标识是指在所述敏感区域图像上添加预设的遮挡标识,例如可以采用与敏感区域图像大小相同的矩形框遮挡当前敏感区域图像。
所述图像合并单元108用于接收当前帧图像和处理后的敏感区域图像,根据敏感区域图像在当前帧图像上的坐标位置,将处理后的敏感区域图像和当前帧图像合成为处理帧图像,并将所述处理帧图像传输至视频编码单元进行编码。
在本实施方式中,将处理后的敏感区域图像和当前帧图像合成为处理帧图像包括:将当前帧图像上原始的敏感区域图像替换为经过处理后的敏感区域图像。
在某些实施例中,所述芯片还包括图像预测网络电路111;所述图像预测网络电路111用于根据敏感区域图像、当前帧图像、以及敏感区域图像在当前帧图像的坐标位置,根据预测出新的区域图像,并将新的区域图像送往图像合并单元。图像预测网络电路进行区域图像预测的方式如图5所示。
例如草原图片上的敏感物体为垃圾桶,当敏感物体被去除后,当前帧图像则会留下一大片空白区域,严重影响用户的感官体验,因而需要对这部分区域进行图像预测,采用的方式是基于周围像素点预测出新的区域图像,例如垃圾桶所在位置周围都是草地,那么经过图像预测网络电路预测后会生成与敏感物体区域大小相同的新图像,并用新图像覆盖原有当前帧图像上的敏感区域位置。
图像预测网络电路为现有技术,具体可以采用dcgan或lapgan网络实现,实现的方式可以参考以下链接:
https://blog.csdn.net/stdcoutzyx/article/details/53872121。
https://blog.csdn.net/u011534057/article/details/53410098。
请参阅图2,发明人提供了一种基于深度学习的异物过滤视频编码方法,所述方法应用于基于深度学习的异物过滤视频编码电路,所述芯片包括数据通路选择单元、神经网络分类识别单元、敏感物体判断单元、敏感区域划分单元、敏感物体存储列表、敏感区域处理单元、敏感区域缓存单元、图像合并单元、视频编码单元;
所述数据通路选择单元分别与图像采集单元、敏感物体判断单元、神经网络分类识别单元连接;所述神经网络分类识别单元与敏感区域划分单元、敏感物体判断单元连接;所述敏感物体判断单元与敏感物体存储列表连接;所述敏感区域划分单元与敏感区域缓存单元连接,所述敏感区域缓存单元与图像合并单元连接,所述图像合并单元与视频编码单元连接;
所述方法包括以下步骤:
首先进入步骤s201数据通路选择单元接收图像采集单元采集的视频流数据,并将当前帧图像发送至神经网络分类识别单元;
而后进入步骤s202神经网络分类识别单元对当前帧图像进行物体识别,并将物体识别结果发送至敏感物体判断单元;
而后进入步骤s203敏感物体判断单元根据当前帧图像的物体识别结果,判断当前帧图像中是否包含有敏感物体存储列表中预先存储的敏感物体,若是则进入步骤s204发送第一控制信号至数据通路选择单元,否则进入步骤s206发送第二控制信号至数据通路选择单元;
步骤s204后进入步骤s205数据通路选择单元接收第一控制信号,将当前帧图像之后的连续n帧图像传输至神经网络分类识别单元;或者,步骤s206后进入步骤s207数据通路选择单元接收第二控制信号,将当前帧图像之后的连续m帧图像传输至视频编码单元进行编码处理;n、m为正整数;
步骤s205后进入步骤s208敏感区域划分单元在当前帧图像中存在敏感物体的情况下,接收神经网络分类识别单元传输的当前帧图像,并划分出当前帧图像对应的敏感区域图像,并将敏感区域图像存储于敏感区域缓存单元中;所述敏感区域图像包含有敏感物体;
步骤s208后进入步骤s209敏感区域处理单元获取敏感区域缓存单元中的敏感区域图像,根据敏感物体与处理方式的对应关系,采用相应地处理方式处理敏感区域图像,并将处理结果发送至图像合并单元;
步骤s209后进入步骤s210图像合并单元接收当前帧图像和处理后的敏感区域图像,根据敏感区域图像在当前帧图像上的坐标位置,将处理后的敏感区域图像和当前帧图像合成为处理帧图像,并将所述处理帧图像传输至视频编码单元进行编码,从而得到新的视频片段。
在某些实施例中,所述敏感区域划分单元包括轮廓识别单元和敏感区域坐标计算单元;所述方法还包括以下步骤:
轮廓识别单元识别出敏感区域图像中敏感物体的轮廓位置信息,所述轮廓位置信息以“第一标识行-第一起始坐标点-第一结束坐标点”的方式进行存储;
敏感区域坐标计算单元根据轮廓位置信息、以及敏感区域图像在当前帧图像中的坐标信息,计算敏感区域图像内的敏感物体在当前帧图像中的坐标位置信息,并将所述坐标位置信息以“第二标识行-第二起始坐标点-第二结束坐标点”的方式进行存储;
所述第二标识行的数值为第一标识行的数值与敏感区域图像在当前帧图像内的起始行之和,所述第二起始坐标点为第一起始坐标点与敏感区域图像在当前帧图像内的起始列之和,所述第二结束坐标点为第二结束坐标点与敏感区域图像在当前帧图像内的起始列之和。
在某些实施例中,所述芯片还包括图像预测网络电路;所述方法包括以下步骤:图像预测网络电路根据敏感区域图像、当前帧图像、以及敏感区域图像在当前帧图像的坐标位置,根据预测出新的区域图像,并将新的区域图像送往图像合并单元。
在某些实施例中,敏感区域图像内敏感物体的处理方式包括以下一种或多种:马赛克处理、二值化处理、添加遮挡标识。
在某些实施例中,所述神经网络分类识别电路包括:fast-rcnn神经网络电路、ssd神经网络电路、yolo神经网络电路。
在本实施方式中,基于深度学习的异物过滤视频编码芯片可以通过以下三种方式进行工作,三种方式可以根据实际工作需要进行配置,具体如下:
(1)视频处理模块和音频处理模块相互独立进行工作,即在工作过程中,可以只开启视频处理模块和音频处理模块的其中一项,从而实现对视频流信息或者音频流信息的当单独处理。
(2)视频处理模块和音频处理模块联合进行工作,即在工作过程中,视频处理模块和音频处理模块可以同时处于开启状态,当接收到视频流数据时,视频处理模块对视频流中包含的敏感物体进行滤除,音频处理模块对采集的音频信息中的敏感词汇对应的音段进行滤除,而后视频处理模块和音频处理模块分别将经过处理后的视频流信息和音频信息输出。
(3)视频处理模块包括丢帧判断单元,实际工作时,只开启音频处理模块、丢帧判断单元以及视频编码单元,实现对音频信息中敏感声音的滤除,同时将该敏感声音音段对应的画面帧图像进行滤除。具体做法如下:敏感词坐标计算单元在计算出敏感词对应的音段信息的起止点时间后,将敏感词汇对应的起止时间信息送往丢帧判断单元。丢帧判断单元接收到起止时间信息后,对该起止时间段内的画面信息进行丢帧处理,并将丢帧处理后的图像数据送往视频编码单元进行编码,从而完成对敏感声音和图像内容的滤除。
在这一模式下,敏感区域处理单元无需开启,视频流数据直接传输至丢帧判断单元进行判断,从而有效简化了运算逻辑,节省了电路功耗。同时,为了保证音画同步,在这一实施例中,语音合成单元对敏感词汇对应的声音段的处理方法为直接将敏感词所在的音段信息删除。也就是说,此时的音频处理信息为空白信息,即删除了的音频信息。
本发明提供了一种基于深度学习的数据编码芯片和方法,所述方法通过语音识别单元将采集的音频信息转换为文字信息,并将得到的文字信息与预先存储的敏感词汇进行比对,当转换得到的文字信息中存在着敏感词汇时,采用该敏感词汇对应的处理方式对相应的音段信息进行处理,从而达到自动消除音频信息中敏感声音(即敏感词汇对应的音段信息)的目的。相较于人工识别判断的方式,有效提升了数据处理效率。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!