一种优化卷积神经网络中神经元空间排布的方法与流程
本发明属于人工智能领域,具体涉及深度学习方法。
背景技术:
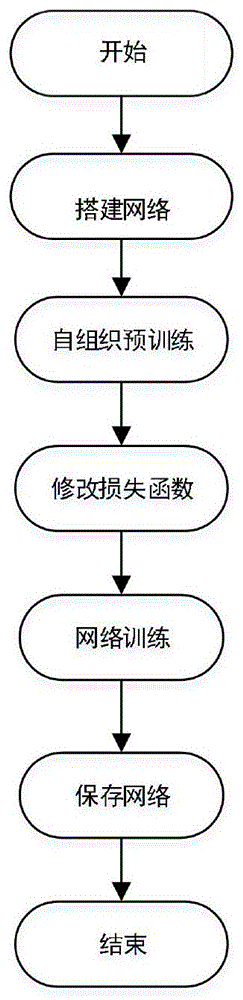
:人体内神经元的组织连接一直都是各国科研工作者的研究热点和重点。神经科学家已经发现,当视网膜中有若干个接收单元同时受特定模式刺激时,就使大脑皮层中的特定神经元开始兴奋,输入模式接近,与之对应的兴奋神经元也接近。心理学家已经探索了大脑中概念的组织方式。最流行的理论之一是语义网络模型,它使用网络结构来表示概念及其关系。网络中的每个节点表示概念或类别,并且每个边表示连接的节点之间的关系。语义相关的概念通过几条边直接或间接连接。一旦激活了某个概念,就通过连接传播到相邻的概念节点,从而也可能激活语义相关的概念。人工神经网络模拟了人体内神经元的连接方式和工作原理,使其接近人体内神经元的组织排列方式。卷积神经网络作为人工神经网络的重要组成部分,已经取得了很多成果,主要集中在如何实现诸如分类等任务的良好性能。在传统的卷积神经网络中,卷积层之间的神经元具有连接,而层内的神经元之间没有联系,这与人脑中神经元的组织排列方式不一致,因此还可以进一步优化改进。技术实现要素:为了使卷积神经网络中神经元之间具有语义组织关系,受到神经科学和认知心理学的启发,本发明提出一种优化卷积神经网络中神经元的语义组织排列方法,也就是说,对语义相近类别敏感的神经元在网络空间中的分布位置也相近。我们利用图像分类的任务,将这种语义组织关系融合到卷积神经网络。本发明的流程图如图1所示,包括四个步骤:步骤1:搭建网络网络包括五个卷积层、三个最大池化层,以及三个全连接层,其连接顺序为:第一卷积层、第一最大池化层、第二卷积层、第二最大池化层、第三卷积层、第四卷积层、第五卷积层、第二最大池化层、第一全连接层、第二全连接层、第三全连接层;步骤2:利用自组织映射算法预训练网络得到网络的初始化参数,具体步骤如下:按照步骤1搭建好网络后,需要修改卷积层和全连接层的前向传播过程,,在每个卷积层和每个全连接层内加入自组织映射的学习方式,利用自组织映射算法更新卷积核的权值,即每当窗口滑动到当前位置时,分别计算每个卷积核与该窗口区域内像素的点积,并找到最大点积值对应的卷积核,称之为获胜的卷积核,并用公式(1)更新获胜的卷积核及其邻近卷积核的权重,然后窗口滑动到下一位置,重复相同的操作,其中权重更新公式如下:wl,k(q)表示第l层第k个卷积核在第q个位置时的权重,t为迭代次数,η(t)是学习速度,λ(k,k*)是窗函数,k*表示获胜卷积核的位置,φq表示卷积核在特征图上第q个位置上所覆盖的像素;第l层用于表示卷积层和全连接层;在根据公式(1)更新完获胜卷积核及其邻近卷积核的权重后,对这些卷积核的权重进行归一化操作,防止获胜卷积核的权值在更新后过大,如下式(2),表示根据公式(1)更新完后的第l层第k个卷积核在第q个位置的权重,wl,k(q+1)表示第l层第k个卷积核在第q+1个位置时的权重,μl,k和σl,k分别是根据公式(1)更新完后的第l层第k个卷积核权值的均值和方差,μ和σ分别为网络初始化时第l层第k个卷积核权值的均值和方差;结合图像分类数据集,输入图像到网络,利用公式(1)和(2)不断更新网络中卷积核的权值,整个训练过程不需要反向传播算法更新卷积核的权值,达到预设的迭代次数后结束预训练过程,保存网络的所有卷积核的权值;步骤3:修改损失函数所述的损失函数,即在交叉熵损失函数的基础上新加描述相邻卷积核权值分布相似性的正则化项,具体公式如下,l=lcls+lsom(3)l表示网络整体的损失函数,lcls表示交叉熵损失函数,lsom是用于描述网络中相邻核的权值分布相似程度的正则化项;其中,lcls=-logpu,u表示人工标注图片的类别序号,pu表示网络预测该图片为类别序号u的概率;λ为平衡因子,用来调节lsom损失项对总体损失的影响,n1表示网络中卷积层的总数,n2表示网络中全连接层的总数,l表示卷积层的对应层数或者全连接层的对应层数,m1表示第l个卷积层中卷积核的个数,m2表示第l个全连接层中卷积核的个数,wli表示第l个卷积层或全连接层第i个卷积核的权值;步骤4:按照步骤1再次搭建好新的网络,需要注意的是,这里不需要如步骤(2)修改卷积层或全连接层的前向传播过程,保持卷积层和全连接层的原有前向传播过程不变即可。然后利用步骤2得到的卷积核的权值,初始化步骤1中搭建的网络的卷积核的权值,利用图像分类的数据集imagenet进行网络训练,利用反向传播算法不断更新网络的参数,当步骤3修改后得到的损失函数达到最小时结束训练,得到神经元空间排布优化后的卷积神经网络模型。有益效果本发明得到的卷积神经网络模型的神经元之间具有更好的语义组织关系,与人体内神经元的组织排列方式更相似。神经元语义组织的用途具有非常广泛的前景,能够节省概念存储空间和加快概念检索速度。附图说明图1、本发明方法流程图;图2、本发明所述网络结构示意图;图3、实验使用的部分数据;具体实施方式:以下将从实验具体实现细节方面对本发明作进一步详细说明。根据图1所示的流程图中步骤进行实验操作。步骤1:搭建网络本发明选择alexnet网络作为基本网络,如图2所示,其特征于:输入的图片大小为227x227;所述的第一卷积层的卷积核大小为11x11,个数为96,步长为4;所述的第一最大池化层窗口大小为3x3,步长为2;所述的第二卷积层的卷积核大小为5x5,个数为256,步长为1;所述的第二最大池化层窗口大小为3x3,步长为2;所述的第三卷积层的卷积核大小为3x3,个数为384,步长为1;所述的第四卷积层的卷积核大小为3x3,个数为384,步长为1;所述的第五卷积层的卷积核大小为3x3,个数为256,步长为1;所述的第三最大池化层窗口大小为3x3,步长为2;所述的第一全连接层的维度为4096;所述的第二全连接层的维度为4096;所述的第三全连接层的维度为1000,与数据集中类别数保持相等即可;在整个网络中选择relu函数作为激活函数。步骤2:利用自组织映射算法预训练网络得到网络的初始化参数,具体步骤如下:我们首先基于python编写代码,搭建实现了alexnet网络框架,该部分的实验均在cpu上运行。我们根据公式(1)和(2),在卷积层和全连接层中加入了自组织算法的更新规则,所有的反向传播过程是不需要的。我们根据caffe框架提供的alexnet网络设置初始化参数。为了利用自组织映射算法训练alexnet网络,我们从imagenetilsvrc2012数据集中随机抽取了15个类别,每个类别随机抽取100张图片。每张图片的大小固定到227x227,并且每个像素的rgb通道需要分别减去对应的均值,进行归一化处理,rgb通道的均值根据抽取的所有样本计算可得。我们设置batch_size等于5,实验共迭代训练了300次,η(t)的初始值设置为0.0001,在整个训练过程中,每迭代150次,学习率η(t)减半。整个训练过程大约持续了12个小时,训练结束后将所有卷积核的权值保存在文本文件中。根据公式(1)所述,其窗函数具体如下:其中,k表示第k个卷积核的位置,k*表示获胜卷积核的位置。步骤3:修改损失函数根据公式(3)和(4),修改caffe框架的交叉熵损失函数层,增加正则化项lsom,它计算了网络中所有卷积层和全连接层中相邻卷积核之间权值的差值平方和,置λ为0.0004较为合适。imagenet数据集总类别数为1000,对应第三全连接层的维度为1000,假设输入图片的真实类别为u,第三全连接层的第u维数据即为叉熵损失函数lcls中的pu。步骤4:网络训练首先基于caffe框架搭建好步骤1中的alexnet网络,不需要如步骤(2)修改卷积层或全连接层的前向传播过程,保持卷积层和全连接层的原有前向传播过程不变即可。然后按照步骤3修改好网络的损失函数,还利用步骤2得到的卷积核权值初始化新搭建的alexnet网络的卷积核。我们使用imagenetilsvrc2012数据集训练和验证网络,它共有1000个类别,每个类别有1300张训练图片,50张验证图片。当损失函数达到最小时网络训练完毕,得到神经元空间排布优化后的卷积神经网络模型。步骤5:结果预测和评价为了与其他实验结果做对比,我们在alexnet的第三全连接层后面附加一个全连接层,保持1000维。在网络训练结束后,去除了附加的全连接层,我们只利用剩余的网络结构来评价网络性能。使用深度学习框架caffe并采用随机梯度下降法sgd训练网络,网络最大迭代次数为450000,batch_size为256。设置初始学习率为0.01,网络每迭代训练100000次,学习率就乘以0.1。momentum为0.9,权重衰减项的平衡因子为0.0005。我们使用整个imagenet数据集训练和验证网络,在训练网络前需要对训练集中的图片进行预处理,我们在每张图片的中心处附近随机进行裁剪,得到227x227固定大小的图片,并且每个像素的rgb通道需要分别减去对应的均值,进行归一化处理。这些操作利用caffe提供的接口即可实现。网络的训练是在单个titanxgpu上进行,整个训练过程持续了大约七天。待训练完成后,将最后的模型数据保存。我们用三种不同的评价标准来评估本发明得到的网络模型。第一种是计算所有卷积层和全连接层中相邻核的权值分布的相似程度,第二种是计算网络输出空间神经元分布的有序程度,第三种是测量网络通过激活扩散方式的预测速度。实验组别说明如下:实验一是利用随机初始化网络参数,迭代训练直到网络收敛;实验二是利用随机初始化网络参数,并修改损失函数,增加正则化项lsom,迭代训练直到网络收敛;实验三是利用随机初始化网络参数,并修改损失函数,增加正则化项lsom,还随机打乱训练集中类别位置,迭代训练直到网络收敛;第一种评价标准:计算所有卷积层和全连接层中相邻核的权值分布的相似程度,按照下面公式(6)进行计算,n表示网络中所有卷积层和全连接层的核的个数,n1表示网络中卷积层的总数,n2表示网络中全连接层的总数,l表示卷积层的对应层数或者全连接层的对应层数,m1表示第l个卷积层中卷积核的个数,m2表示第l个全连接层中卷积核的个数,wli表示第l个卷积层或全连接层第i个卷积核的权值;dis计算了网络中所有卷积层和全连接层中相邻核之间权值的差值平方和的均值。dis越小,表示相邻核的权值分布越相似。结果如表一,相比其他方法,本发明的dis值更小,说明网络模型中卷积层或全连接层中相邻核的权值分布更相似。distop-1(val)实验一4.6100.540实验二1.0460.532本发明1.0500.532表一:第一种评价标准结果对比其中,top-1(val)表示利用验证集测试网络的分类精确度。第二种评价标准:计算网络输出空间神经元分布的有序程度,这里使用imagenet验证集作为测试数据,共5万张图像,1000类别,每个类别50张图片,我们利用模型预测每个类别的每张测试图片的输出响应位置,然后计算该类别的平均位置。按照下面公式(7)进行计算,si是在wordnet中,第i类别与之距离最近的类别之间的距离,等于这两个类别节点到最近公共父节点的距离之和,di是第i类别的均值位置与之距离最近的类别的均值位置之间的距离。d值越小,说明输出空间神经元之间的语义组织关系更强,对语义相近类别敏感的神经元在网络空间中的分布位置也更相近。结果如下表二,相比其他几种不同方法,本发明的d值更小,表明其输出空间神经元的排列分布更有序,对语义相近类别敏感的神经元在网络空间中的分布位置也更相近。si表二:第二种评价标准结果对比第三种评价标准:测量网络通过激活扩散方式的预测速度。我们用手机获取了一段关于杯子的视频,大约40秒,在图3展示了部分视频截图。我们每隔20帧抽取一张图片作为测试图片,一共抽取了50张测试图片。为了测量预测的速度,给定两个连续的测试图片,我们计算激活最强的神经元之间的距离,并将其作为响应时间的替代。更具体地,平均响应时间按照下面公式(8)进行计算,nf表示测试图片张数,ai表示第i张图片在第三全连接层神经元的响应位置。mrt值越小,说明网络通过激活扩散方式的预测速度更快。结果如表三,本发明的mrt值更小,说明本发明的网络模型通过激活扩散方式的预测速度更快。mrt实验一219.08实验二131.48本发明127.14表三:第三种评价标准结果对比通过以上的评价标准和对比实验可知,本发明得到的卷积神经网络模型的神经元之间具有更好的语义组织关系,与人体内神经元的组织排列方式更相似。神经元的语义组织的用途也非常广泛,能够节省概念存储空间和加快概念检索速度。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1