一种神经网络模型训练方法、装置、设备和介质与流程
本申请涉及神经网络领域,特别是涉及一种神经网络模型训练方法、装置、设备和计算机可读存储介质。
背景技术:
强化学习又称为试错学习,是一种让智能体(agent)在学习对象的环境(environment)中不断交互,并根据环境的反馈激励(reward)进行学习的一种机器学习算法,该学习算法不基于任何先验知识,可以完全自主学习。根据学习对象的不同,可以有不同的智能体,例如学习对象为游戏时,智能体可以是游戏中的角色、参与方等。
传统的强化学习例如deepqnetwork(dqn)在训练自身的神经网络模型时,完全根据机器通过自主学习得到的数据作为训练数据。
这种场景下的训练数据均机器自主试错得到,尤其训练前期机器自主试错速度慢,无意义交互多,导致训练前期的模型参数收敛时间长,成本高,延长了训练神经网络模型的时间。
技术实现要素:
为了解决上述技术问题,本申请提供了一种神经网络模型训练方法和装置,以缩短训练前期的模型参数收敛时长,减少训练神经网络模型的时间。
本申请实施例公开了如下技术方案:
第一方面,本申请实施例提供一种神经网络模型训练方法,所述方法包括:
获取学习对象根据用户操作产生的人工样本集;
获取针对所述学习对象的神经网络模型在在所述学习对象中自主学习得到机器样本集;
根据所述人工样本集和所述机器样本集训练所述神经网络模型。
第二方面,本申请实施例提供一种神经网络模型训练装置,所述装置包括第一获取单元、第二获取单元和训练单元:
所述第一获取单元,用于获取学习对象根据用户操作产生的人工样本集;
所述第二获取单元,用于获取针对所述学习对象的神经网络模型在所述学习对象中自主学习得到机器样本集;
所述训练单元,用于根据所述人工样本集和所述机器样本集训练所述神经网络模型。
第三方面,本申请实施例提供一种用于神经网络模型训练的设备,所述设备包括处理器以及存储器:
所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
所述处理器用于根据所述程序代码中的指令执行第一方面中所述的神经网络模型训练方法。
第四方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行第一方面中所述的神经网络模型训练方法。
由上述技术方案可以看出,针对需要进行强化学习的学习对象,可以先通过人工获取学习对象根据用户操作产生的人工样本集,以及针对所述学习对象的神经网络模型在在该学习对象中自主学习得到的机器样本集。在训练该神经网络模型时,可以根据上述人工样本集和机器样本集作为训练依据,由于用于训练的训练样本集中包括了人工产生的人工样本,该人工样本相对于机器学习初期得到的机器样本来说质量更高,更具有推进该学习对象的完成进度的目的性,相对机器样本来说多为和学习对象的有意义交互,从而可以缩短训练前期的模型参数收敛时长,减少了训练神经网络模型的时间。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
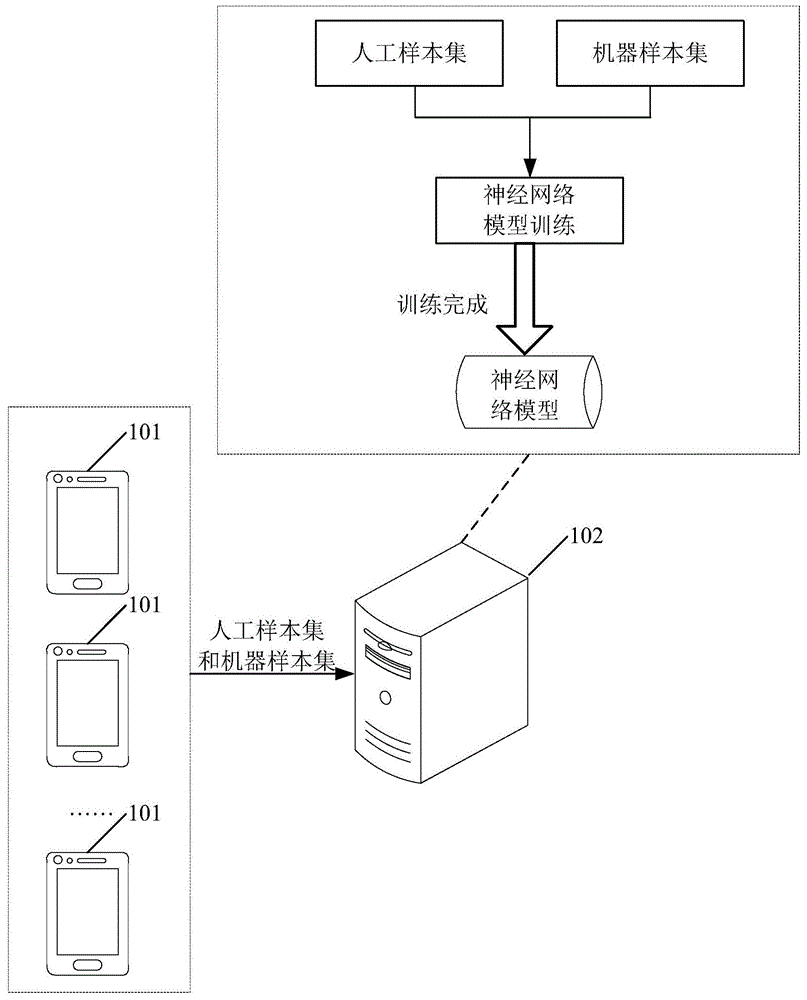
图1为本申请实施例提供的神经网络模型训练方法的应用场景示意图;
图2为本申请实施例提供的一种神经网络模型训练方法的流程图;
图3为本申请实施例提供的qq飞车游戏作为学习对象的示例图;
图4为本申请实施例提供的一种神经网络模型训练方法的流程结构示意图;
图5为本申请实施例提供的一种神经网络模型预训练的流程结构示意图;
图6为本申请实施例提供的一种神经网络模型训练方法的流程图;
图7a为本申请实施例提供的一种神经网络模型训练装置的结构图;
图7b为本申请实施例提供的一种神经网络模型训练装置的结构图;
图8为本申请实施例提供的一种用于神经网络模型训练的设备的结构图;
图9为本申请实施例提供的一种用于神经网络模型训练的设备的结构图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
传统的强化学习在训练自身的神经网络模型时,训练数据完全是由机器自主试错得到,尤其训练前期机器自主试错速度慢,无意义交互多,质量相对较差,导致训练前期的模型参数收敛时间长,成本高,延长了训练神经网络模型的时间。
为了解决上述技术问题,本申请实施例提供了一种神经网络模型训练方法。由于人工产生的人工样本相对于机器学习初期得到的机器样本来说质量更高,更具有推进该学习对象的完成进度的目的性,相对机器样本来说多为和学习对象的有意义交互,因此,在本申请实施例提供的训练方法中,训练模型所采用的训练样本集中引入了人工产生的人工样本,以协助机器样本训练神经网络模型。
本申请实施例提供的神经网络模型训练方法可以应用于数据处理设备,如终端设备、服务器等。其中,终端设备具体可以为智能手机、计算机、个人数字助理(personaldigitalassistant,pda)、平板电脑等;服务器具体可以为独立服务器,也可以为集群服务器。
为了便于理解本申请的技术方案,下面结合实际应用场景、以数据处理设备为服务器为例对本申请实施例提供的神经网络模型训练方法进行介绍。
参见图1,图1为本申请实施例提供的神经网络模型训练方法的应用场景示意图,该应用场景中可以包括至少一个终端设备101和服务器102,学习对象可以配置在终端设备101中,通过操作终端设备101可以产生人工样本集和机器样本集。服务器102可以从终端设备101中获取学习对象根据用户操作产生的人工样本集和针对该学习对象的神经网络模型在该学习对象中自主学习得到的机器样本集,以便对神经网络模型进行训练。
神经网络模型可以是训练完成的,也可以在使用的过程中持续训练。其中,学习对象可以一种应用于深度学习的对象,学习对象中可以具有给定的任务,需要通过实施一定规则下的技能动作完成任务、或者推动任务进度。学习对象例如可以是游戏、运动项目等等,若以游戏作为学习对象,则针对该学习对象的神经网络模型在该学习对象中进行强化学习学习的是玩游戏的技能,若以运动项目例如跳高项目作为游戏对象,则针对该学习对象的神经网络模型进行强化学习学习的是在不同环境下跳高的技能。
样本是用于训练神经网络模型的。在本实施例中,样本可以包括人工样本、机器样本或训练样本。人工样本,机器样本和训练样本中包括的数据类型是一致的。
每个人工样本是学习对象根据用户操作产生的,多个人工样本构成人工样本集;每个机器样本是针对该学习对象的神经网络模型在该学习对象中自主学习得到的,多个机器样本构成机器样本集;训练样本可以是选了神经网络模型时从人工样本集和机器样本集中选取出的样本,多个训练样本构成训练样本集。
人工样本集是针对学习对象基于人类的先验知识人工产生的数据,该人工样本集可以是预先整理的,也可以是通过用户在终端设备101上通过对学习对象执行操作而持续产生的。而在自主学习初期神经网络模型还没有训练好,神经网络模型的模型参数可能还是一些初始数值,通过此时的神经网络模型自主学习得到的机器样本多为与学习对象无意义的交互。因此,人工样本相对于机器学习初期得到的机器样本来说人工样本的质量更高,更具有推进该学习对象的完成进度的目的性。
故服务器102根据获取到的人工样本集和机器样本集训练针对学习对象的神经网络模型,由于质量较高的人工样本集的加入,使得在训练神经网络模型时更具有推进该学习对象的完成进度的目的性,从而可以缩短训练前期的模型参数收敛时长,减少了训练神经网络模型的时间。
本申请实施例提供的神经网络模型训练方法可以应用于训练人工智能(artificialintelligence,简称ai)的应用场景中,例如游戏、机器人、工业自动化、教育、医学、金融等。为了便于介绍,后续实施例将以训练游戏的ai的应用场景(游戏作为学习对象)进行介绍。
接下来,将结合附图对本申请实施例提供的神经网络模型训练方法进行介绍。
参见图2,图2示出了一种神经网络模型训练方法的流程图,所述方法包括:
s201、获取学习对象根据用户操作产生的人工样本集。
训练游戏的ai的应用场景中,游戏作为学习对象,用户可以根据游戏的游戏规则玩游戏,从而产生根据用户操作产生人工样本集。不同的游戏虽然游戏规则可能不同,但人工样本集中所包括数据类型一般是一致的。
产生的人工样本集可以被保存下来,例如可以保存在人工样本池中,这样,当需要利用人工样本集来协助训练神经网络模型时,可以从人工样本池中获取人工样本集。s202、获取针对所述学习对象的神经网络模型在所述学习对象中自主学习得到机器样本集。
通过神经网络模型在学习对象中产生的机器样本集可以被保存下来,例如可以保存在重放内存(replaymemory)中,这样,当需要利用机器样本集来训练神经网络模型时,可以从replaymemory中获取机器样本集。机器样本集所包括的数据类型可以与人工样本集一致。
在一种可能的实现方式中,机器样本集与人工样本集都包括了在所述学习对象中实施的动作、在实施动作时所述学习对象的环境参数,以及动作实施后所述学习对象的回馈参数。
其中,在所述学习对象中实施的动作可以是通过不同的方式在学习对象中实施的学习对象所允许的动作,例如为通过用户操作在所述学习对象中实施的动作或通过所述神经网络模型在所述学习对象中实施的动作。
在实施动作时所述学习对象的环境参数可以用于标识实施动作时所提供的环境,例如,游戏作为学习对象时,环境参数可以是实施动作时的游戏画面。
动作实施后所述学习对象的回馈参数可以是通过实施动作与学习对象进行交互时,学习对象产生的回馈,回馈参数可以起到评价在学习对象中所实施的动作对推进任务完成进度所带来的影响的作用,一般来说,该回馈参数越高越好,回馈参数越高,意味着在学习对象中所实施的动作越有利于推进学习对象的完成进度。
例如,在学习对象为跑酷游戏时,其给定的任务是避免障碍的阻拦在一定规则下移动到终点。用户观察到学习对象的当前环境包括一道矮墙,若用户基于当前环境实施的动作为跳跃,使得游戏角色跃过矮墙进行高速前进,可见这一动作使得游戏角色避免了被障碍阻挡而继续前移,有利于推进任务进度。故学习对象针对该动作产生的回馈参数比较高。若用户实施的动作为向着矮墙正常跑步,使得游戏角色撞到矮墙,产生停滞,阻碍了前移,不利于推进任务进度,故学习对象针对该动作产生的回馈参数比较低。
人工样本集包括用户在所述学习对象中实施的动作、在实施动作时所述学习对象的环境参数,以及动作实施后所述学习对象的回馈参数三者之间的对应关系。人工样本集中包括的对应关系可以反映出用户在学习对象的任一环境下所选择实施的动作,以及用户实施的动作对推进任务完成进度所带来的影响。
机器样本集包括通过所述神经网络模型在学习对象中实施的动作、在实施动作时学习对象的环境参数,以及动作实施后所述学习对象的回馈参数三者之间的对应关系。机器样本集中包括的对应关系可以反映出通过所述神经网络模型在学习对象的任一环境下所选择实施的动作,以及通过所述神经网络模型实施的动作对推进任务完成进度所带来的影响。
利用神经网络模型对学习对象中的技能进行自主学习,具体的神经网络模型可以根据环境参数确定在学习对象中所要实施的动作,确定出的每个动作分别具有对应的回馈参数,基于回馈参数可以选择出在该环境参数下实施哪个动作更有利于推进学习对象的完成进度。
需要说明的是,由于在自主学习初期神经网络模型还没有训练好,神经网络模型的模型参数可能还是一些初始数值,通过此时的神经网络模型还不知道哪些动作是有利于推进学习对象的完成进度的,导致在自主学习初期选择的动作无意义的可能性比较大,例如选择实施的动作与推进学习对象的完成进度无关或者选择实施的动作使得学习对象的进度无法完成,使得在自主学习初期和学习对象进行无意义的交互较多。例如,在学习对象为跑酷游戏时,若为了推进该学习对象的完成进度通过所述神经网络模型在学习对象中实施的动作应该是向前走,但是,由于神经网络模型还没有训练好,使得通过所述神经网络模型在自主学习时选择实施的动作可能是向左走,但是向左走实际上对于推进该学习对象的完成进度没有意义,此时,包括通过所述神经网络模型在学习对象中实施的动作“向左走”的机器样本为无意义交互。
故后续训练神经网络模型的过程中将结合人工样本集和机器样本集训练神经网络模型。
人工样本集或机器样本集中的样本可以采用一定的数据格式表示,例如都可以采用如下数据格式:(实施动作时学习对象的环境参数、在学习对象中实施的动作、动作实施后学习对象的回馈参数)。
需要说明的是,在学习对象中实施动作的目的是推进学习对象的完成进度,动作实施后所述学习对象的回馈参数可以起到评价在学习对象中所实施的动作对推进任务完成进度所带来的影响,回馈参数可以包括实施所述目标动作得到的奖励参数和根据实施所述目标动作在所述学习对象中得到的环境参数这两方面中的至少一方面。这里的目标动作可以为人工样本集或者机器样本集中,任意一个目标样本中包括的任意一个动作。
这两个方面都可以起到评价在学习对象中所实施的动作对推进任务完成进度所带来的影响的作用。
在一种实现方式中,回馈参数包括实施目标动作得到的奖励参数(reward)。
在很多情况下,实施的目标动作不同,实施该目标动作得到的奖励不同,实施该目标动作得到的奖励越好,可以认为实施的该目标动作越有利于推进学习对象的完成进度,其中,奖励的好坏可以通过奖励参数来体现。
在一种实现方式中,回馈参数包括实施目标动作在所述学习对象中得到的环境参数。
在很多情况下,实施的目标动作不同,得到的实施目标动作后的环境可能不同,实施目标动作后的环境可以通过实施目标动作在所述学习对象中得到的环境参数来体现。该环境参数的好坏,可以反映出动作对推进学习对象的完成进度的影响。
以图3所示qq飞车游戏为例,当实施的动作为漂移时,实施该动作后,若赛车可能会撞到旁边的护栏,导致游戏终止,则赛车撞到旁边的护栏为实施漂移动作后的环境,可以通过该环境对应的环境参数确定该漂移动作不利于推进学习对象的完成进度。
基于此,在本实施例的另一种实现方式中,为了避免过度追求一方面对应的参数例如奖励参数的好,而忽略另一方面对应的参数例如环境参数,导致根据奖励参数或环境参数评价出的目标动作对推进学习对象的完成进度的影响不够准确。因此,针对实施的动作,例如目标动作,可以综合考虑实施目标动作后得到的奖励参数和根据实施目标动作在学习对象中得到的环境参数这两方面来评价目标动作的对推进学习对象的完成进度的影响,即在人工样本集或机器样本集中,针对任意一个目标动作,目标动作实施后学习对象的回馈参数包括实施目标动作得到的奖励参数和根据实施目标动作在学习对象中得到的环境参数。将两方面共同作为回馈参数能够更准确的评价出目标动作对推进学习对象的完成进度的影响。
在回馈参数包括实施目标动作得到的奖励参数和根据实施目标动作在学习对象中得到的环境参数的基础上,人工样本集或机器样本集中的样本可以采用如下数据格式:(s,a,r,s’)。其中,s表示实施目标动作时学习对象的环境参数,a表示在学习对象中实施的目标动作,r表示实施目标动作得到的奖励参数,s’表示根据实施目标动作在学习对象中得到的环境参数。
s203、根据所述人工样本集和机器样本集训练所述神经网络模型。
在训练神经网络模型时,可以从人工样本集和机器样本集选取样本得到用于训练神经网络模型的训练样本集,利用训练样本集对神经网络模型进行n轮训练,其中,每一轮训练或者前m轮训练的任意一个轮所采用的训练样本集可以包括人工样本集中的一部分人工样本和机器样本集中的一部分机器样本。
在一种可能的实现方式中,若人工样本集或机器样本集中的样本可以采用如下数据格式(s,a,r,s’),在训练过程中,可以根据损失函数(lossfunction)采用预设算法例如预梯度优化算法训练神经网络模型,直到训练的神经网络模型达到较好的效果。损失函数可以如公式(1)所示:
y=r+γ*maxaq(s’,a)
loss=(y-q(s,a))2(1)
其中,s表示实施目标动作时学习对象的环境参数;a表示在学习对象中实施的目标动作;r表示实施目标动作得到的奖励参数;s’表示根据实施目标动作在学习对象中得到的环境参数;q(s,a)表示神经网络模型输出的环境参数s下对应的学习对象中实施的动作a的实际价值;q(s’,a)表示神经网络模型输出的环境参数s’下对应的学习对象中实施的动作a的实际价值;γ为价值q(s’,a)的折扣系数,通常设为0.99;y表示神经网络模型输出的环境参数s下对应的学习对象中实施的动作a的理论价值,loss表示实际价值相对于理论价值的损失。
根据loss可以对神经网络模型的模型参数进行调整,直到调整后的模型参数使得神经网络模型较好。
若人工样本集或机器样本集中的样本可以采用如下数据格式(s,a,r,s’),神经网络模型的输入为实施目标动作时学习对象的环境参数s,神经网络模型的输出为在学习对象中实施的动作a,动作a可以根据r和s’的大小确定,一般情况下,选择比较好的r和s’所对应的动作a作为神经网络模型的输出。训练得到的神经网络模型可以用于玩游戏的机器中,使得可以利用机器玩游戏实现对游戏故障的检测。
由于训练得到的神经网络模型可以根据任一环境参数,给出相应的可以推进学习对象的完成进度的动作,这样,在使用该神经网络模型时,当在该神经网络模型中输入某个环境参数后,通过该神经网络模型确定出的动作也会是推进学习对象的完成进度的动作。
由上述技术方案可以看出,针对需要进行强化学习的学习对象,可以先通过人工获取学习对象根据用户操作产生的人工样本集,以及针对所述学习对象的神经网络模型在在该学习对象中自主学习得到的机器样本集。在训练该神经网络模型时,可以根据上述人工样本集和机器样本集作为训练依据,由于用于训练的训练样本集中包括了人工产生的人工样本,该人工样本相对于机器学习初期得到的机器样本来说质量更高,更具有推进该学习对象的完成进度的目的性,相对机器样本来说多为和学习对象的有意义交互,从而可以缩短训练前期的模型参数收敛时长,减少了训练神经网络模型的时间。
可以理解的是,获取的机器样本集主要保存在replaymemory中,replaymemory中机器样本集的质量,将对训练神经网络模型所使用的机器样本的质量有很大影响。接下来,将对replaymemory中的机器样本集进行介绍。
在本实施例中,可以一边训练神经网络模型,一边利用训练得到的神经网络模型自主学习得到数据,随着时间的推移,训练得到的神经网络模型越来越好,那么,利用训练得到的神经网络模型自主学习得到数据的质量也会越来越高。在这种情况下,为了提高训练神经网络模型所使用的机器样本集的质量,在训练所述神经网络模型的过程中,可以将通过训练得到的神经网络模型自主学习得到的数据作为机器样本,补充到replaymemory中以加入机器样本集,参见图4所示。其中,(s,a,r,s’)为通过训练得到的神经网络模型自主学习得到的数据。当replaymemory中的机器样本集达到replaymemory的容量时,可以删除最先保存进replaymemory中的机器样本。
由于随着训练的不断进行,训练得到的神经网络模型越来越好,通过神经网络模型自主学习得到数据的质量也会越来越高,将质量较高的数据作为机器样本加入到机器样本集中,可以提高replaymemory中机器样本集的质量,使得机器样本集更有利于推进该学习对象的完成进度,从而可以缩短模型参数收敛时长,减少训练神经网络模型的时间。
需要说明的是,图2对应的实施例介绍了一种神经网络模型的训练方法,而训练神经网络模型所使用的训练样本集可以由从s201获取的人工样本集和s202获取的机器样本集中选取的样本构成,而为了保证训练样本集的质量,训练样本集中需要包括人工样本,但是,根据自主学习的应用场景,难以在整个神经网络模型的过程完全根据人工样本训练神经网络模型,甚至训练样本集中的人工样本不能过多,因此,训练样本集中需要包括人工样本和机器样本两部分。
因此,s203的一种可能实现方式为:分别从人工样本集和所述机器样本集中选取样本得到用于训练所述神经网络模型的训练样本集,其中,训练样本集中人工样本的数量和机器样本的数量之间满足预设比例。然后,根据所述训练样本集对所述神经网络模型进行训练。其中,训练样本集中包括的样本可以称为训练样本。
接下来,将对如何确定训练样本集中人工样本数量和机器样本数量之间的预设比例进行介绍。
在本实施例中,预设比例的确定方式可以包括多种,本实施例将主要以两种为例进行介绍。
第一种确定预设比例的方式可以是根据前一次训练的训练结果确定用于本次训练的训练样本集中两种样本的预设比例,即第n次训练所采用训练样本集中人工样本数量和机器样本数量之间的预设比例是根据对所述神经网络模型的第n-1次训练的训练结果确定的。
第n-1次训练的训练结果可以是第n-1次训练得到的神经网络模型,在使用第n-1次训练得到的神经网络模型时,根据该神经网络模型可以输出动作,根据该神经网络模型输出的动作对推进学习对象(游戏)完成进度的影响对预设比例进行调整。
例如,使用第n-1次训练得到的神经网络模型玩游戏时,根据该神经网络模型输出的是不利于推进学习对象(游戏)完成进度的动作,使得学习对象的完成进度低,据此,可以对训练样本集中人工样本数量和机器样本数量之间的预设比例进行调整。由于人工样本是有利于推进学习对象的完成进度,那么,为了使得在使用训练得到的神经网络模型时,根据神经网络模型能够输出更有利于推进学习对象完成进度的动作,则用于训练神经网络模型的训练样本集中人工样本可以增加一些,即调整预设比例增加人工样本在训练样本集中所占比例。
反之,用于训练神经网络模型的训练样本集中人工样本可以减少一些,即调整预设比例减少人工样本在训练样本集中所占比例。
第二种确定预设比例的方式可以是逐渐减少训练样本集中人工样本所占比例,即对神经网络模型的第n次训练所采用的训练样本集中人工样本所占比例小于对神经网络模型的第n-1次训练所采用的训练样本集中人工样本所占比例。
可以理解的是,在学习对象为游戏时,通过神经网络模型玩游戏的目的不仅包括完成游戏进度,还包括检测游戏故障,为了检测游戏故障,需要针对一个环境参数能够通过神经网络模型实施各种不同动作,以得到在实施各种动作后该游戏的环境参数(游戏画面)等,从而对实施各种动作后的环境参数(游戏画面)进行检测,例如,检测动作实施后游戏画面是否存在渲染不出来的地方。
然而,由于人工样本集是基于人类的先验知识产生的,用户针对一个环境参数,基本上会根据先验知识选择常用的动作,很少会尝试其他动作,从而导致人工样本集比较单一,多样性差。例如,在跑酷游戏中,当环境参数表示的是跑酷游戏的赛道上出现一个横杆,基于人类的先验知识,多数人在遇到横杆时可能会从横杆上跳过去,那么,用户一般会选择跳跃这个动作而从横杆上跳过去。然而,过横杆的动作还可能是从横杆下滑过去等,但是,由于人类的先验知识或者从横杆下滑过去这一动作操作复杂等原因,用户很少或者基本上不会选择从横杆下滑过去这一动作过横杆。
为了保证利用神经网络模型玩游戏时针对一个环境参数能够实施不同的动作,以便实现游戏故障的检测,这就要求训练样本集中的训练样本具有较好的多样性。因此,随着神经网络模型训练次数的不断增加,可以逐次减少训练样本集中人工样本所占的比例,提高机器样本所占的比例,使得训练样本集中的训练样本具有较好的多样性。
可见,通过逐渐减少训练样本集中所述人工样本所占比例,可以提高训练样本集中训练样本的多样性,使得利用训练得到的神经网络模型玩游戏时针对一个环境参数能够实施多种不同的动作,以便实现游戏故障的检测。
接下来,将对神经网络模型训练过程中如何使用人工样本集和机器样本集训练针对学习对象的神经网络模型进行介绍。根据人工样本集和机器样本集的自身特性,可以在不同神经网络模型训练时期合理利用人工样本集和机器样本集。
在一种实现方式中,在执行s203之前可以根据人工样本集对所述神经网络模型进行预训练。由于在训练神经网络模型的前期,神经网络模型的模型参数收敛相对于后期来说会比较慢,模型参数的变化会很大,得到的神经网络模型很不稳定。为了在训练神经网络模型的前期能够快速得到一个稳定的神经网络模型,在训练神经网络模型的前期可以仅使用质量较高的人工样本集对神经网络模型进行预训练,得到完成预训练的神经网络模型。完成预训练的神经网络模型是一个比较稳定的模型,其模型参数变化比较小,然后,再执行s203,即根据人工样本集和机器样本集训练完成预训练的神经网络模型。
其中,神经网络模型预训练的流程结构示意图可以参见图5所示,神经网络模型预训练所采用的人工样本可以从保存人工样本集的人工样本池中选取,根据选取的人工样本对神经网络模型进行预训练得到完成预训练的神经网络模型。
由于人工样本集更具有推进该学习对象的完成进度的目的性,因此,可以加快模型参数的稳定时间,快速地得到稳定的完成预训练的神经网络模型。这样,再根据人工样本集和机器样本集训练完成预训练的神经网络模型时,也能够减少训练神经网络模型的时间。
神经网络模型的预训练不能一直进行下去,总会完成预训练以根据人工样本集和机器样本集对完成预训练的神经网络模型继续训练。下面将对如何判断神经网络模型的完成预训练进行介绍。
本实施例主要介绍两种判断方法,第一种判断方法是当人工样本集被训练完。神经网络模型的预训练采用的是人工样本集,当人工样本集被训练完,没有能够继续进行神经网络模型的预训练的样本,此时,可以认为完成预训练。
第二种判断方法是通过神经网络模型完成了学习对象的预设进度。可以理解的是,进行神经网络模型预训练的目的是得到一个比较稳定的神经网络模型,得到稳定的神经网络模型则可以认为神经网络模型完成预训练,神经网络模型是否稳定可以通过模型参数来体现,即模型参数越变化越小,神经网络模型越稳定,反之,神经网络模型越不稳定。那么,如何衡量神经网络模型是否稳定则可以利用通过神经网络模型完成学习对象的进度来确定,通过神经网络模型完成学习对象的进度越大,模型参数越变化越小,则神经网络模型越稳定,反之,模型参数越变化越大,则神经网络模型越不稳定。
例如,学习对象为跑酷游戏,跑酷游戏的赛道全长1000米,若通过神经网络模型在跑酷游戏的赛道上完成200米才终止游戏,此时完成的200米为通过神经网络模型完成学习对象的进度,该进度比较大,则可以认为神经网络模型比较稳定;若通过神经网络模型在跑酷游戏的赛道上完成5米就终止游戏,此时完成的5米为通过神经网络模型完成学习对象的进度,该进度比较小,则可以认为神经网络模型比较不稳定。
因此,可以预先设定通过神经网络模型完成学习对象的进度为多大则认为神经网络模型稳定,例如,预先设定通过神经网络模型完成学习对象的预设进度,则认为神经网络模型稳定。这样,当通过神经网络模型完成了学习对象的预设进度,则确定神经网络模型完成预训练。
接下来,将结合具体应用场景对神经网络模型训练方法进行介绍。在该应用场景中,通过训练得到神经网络模型玩游戏,以检测游戏故障,则在训练神经网络模型时,游戏为学习对象。在该应用场景下,参见图6,神经网络模型训练方法包括:
s601、用户在终端设备上玩游戏得到人工样本集。
s602、获取人工样本池中的人工样本集。
人工样本池是根据收集到的用户在玩游戏时产生的人工样本集构建的。
s603、根据获取的人工样本集对神经网络模型进行预训练。
s604、判断人工样本集是否被训练完或者通过神经网络模型是否完成了游戏的预设进度,若是,则执行s605,若否,则执行s603。
s605、通过所述完成预训练的神经网络模型对游戏进行自主学习得到机器样本集。
s606、获取人工样本池中的人工样本集和replaymemory中的机器样本集。
replaymemory是根据收集到的机器样本集构建的。
s607、根据所述人工样本集和机器样本集训练完成预训练的所述神经网络模型。
其中,神经网络模型训练过程主要包括两个阶段,两个阶段分别是预训练阶段和对完成预训练的神经网络模型进行训练的阶段,s601-s604可以作为预训练阶段,s605-s607可以作为对完成预训练的神经网络模型进行训练的阶段。
由上述技术方案可以看出,针对需要进行强化学习的学习对象,可以先通过人工获取学习对象根据用户操作产生的人工样本集,以及针对所述学习对象的神经网络模型在在该学习对象中自主学习得到的机器样本集。在训练该神经网络模型时,可以根据上述人工样本集和机器样本集作为训练依据,由于用于训练的训练样本集中包括了人工产生的人工样本,该人工样本相对于机器学习初期得到的机器样本来说质量更高,更具有推进该学习对象的完成进度的目的性,相对机器样本来说多为和学习对象的有意义交互,从而可以缩短训练前期的模型参数收敛时长,减少了训练神经网络模型的时间。
基于前述实施例提供的神经网络模型训练方法,本实施例提供一种神经网络模型训练装置700,参见图7a,所述装置700包括第一获取单元701、第二获取单元702和训练单元703:
所述第一获取单元701,用于获取学习对象根据用户操作产生的人工样本集;
所述第二获取单元702,用于获取针对所述学习对象的神经网络模型在所述学习对象中自主学习得到机器样本集;
所述训练单元703,用于根据所述人工样本集和机器样本集训练所述神经网络模型。
在一种实现方式中,参见图7b,所述装置700还包括预训练单元704:
所述预训练单元704,用于根据所述人工样本集对所述神经网络模型进行预训练;
所述训练单元703,具体用于:
根据所述人工样本集和机器样本集训练完成预训练的所述神经网络模型。
在一种实现方式中,当所述人工样本集被训练完或者通过所述神经网络模型完成了所述学习对象的预设进度,所述预训练单元704确定所述神经网络模型完成预训练。
在一种实现方式中,所述人工样本集包括通过用户操作在所述学习对象中实施的动作、在实施动作时所述学习对象的环境参数,以及动作实施后所述学习对象的回馈参数三者之间的对应关系;
所述机器样本集包括通过所述神经网络模型在所述学习对象中实施的动作、在实施动作时所述学习对象的环境参数,以及动作实施后所述学习对象的回馈参数三者之间的对应关系。
在一种实现方式中,所述训练单元703,具体用于:
分别从所述人工样本集和所述机器样本集中选取样本得到用于训练所述神经网络模型的训练样本集;所述训练样本集中人工样本的数量和机器样本的数量之间满足预设比例;
根据所述训练样本集对所述神经网络模型进行训练。
在一种实现方式中,对所述神经网络模型的第n次训练所采用训练样本集中人工样本数量和机器样本数量之间的预设比例是根据对所述神经网络模型的第n-1次训练的训练结果确定的。
在一种实现方式中,对所述神经网络模型的第n次训练所采用训练样本集中所述人工样本所占比例小于对所述神经网络模型的第n-1次训练所采用训练样本集中所述人工样本所占比例。
在一种实现方式中,所述第二获取单元702,具体用于:
在训练所述神经网络模型的过程中,将根据所述神经网络模型在所述学习对象中自主学习得到的数据作为机器样本加入所述机器样本集。
在一种实现方式中,针对所述人工样本集或机器样本集中任意一个目标样本,所述目标样本中包括目标动作实施后所述学习对象的回馈参数,所述目标动作实施后所述学习对象的回馈参数包括实施所述目标动作得到的奖励参数和/或根据实施所述目标动作在所述学习对象中得到的环境参数。
本申请实施例还提供了一种用于神经网络模型训练的设备,下面结合附图对用于神经网络模型训练的设备进行介绍。请参见图8所示,本申请实施例提供了一种用于神经网络模型训练的设备800,该设备800可以是服务器,可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(centralprocessingunits,简称cpu)822(例如,一个或一个以上处理器)和存储器832,一个或一个以上存储应用程序842或数据844的存储介质830(例如一个或一个以上海量存储设备)。其中,存储器832和存储介质830可以是短暂存储或持久存储。存储在存储介质830的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器822可以设置为与存储介质830通信,在用于神经网络模型训练的设备800上执行存储介质830中的一系列指令操作。
用于神经网络模型训练的设备800还可以包括一个或一个以上电源826,一个或一个以上有线或无线网络接口850,一个或一个以上输入输出接口858,和/或,一个或一个以上操作系统841,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
上述实施例中由服务器所执行的步骤可以基于该图8所示的服务器结构。
其中,cpu822用于执行如下步骤:
获取学习对象根据用户操作产生的人工样本集;
获取针对所述学习对象的神经网络模型在所述学习对象中自主学习得到机器样本集;
根据所述人工样本集和所述机器样本集训练所述神经网络模型。
请参见图9所示,本申请实施例提供了一种用于神经网络模型训练的设备900,该设备900还可以是终端设备,该终端设备可以为包括手机、平板电脑、个人数字助理(personaldigitalassistant,简称pda)、销售终端(pointofsales,简称pos)、车载电脑等任意终端设备,以终端设备为手机为例:
图9示出的是与本申请实施例提供的终端设备相关的手机的部分结构的框图。参考图9,手机包括:射频(radiofrequency,简称rf)电路910、存储器920、输入单元930、显示单元940、传感器950、音频电路960、无线保真(wirelessfidelity,简称wifi)模块970、处理器980、以及电源990等部件。本领域技术人员可以理解,图9中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图9对手机的各个构成部件进行具体的介绍:
rf电路910可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器980处理;另外,将设计上行的数据发送给基站。通常,rf电路910包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(lownoiseamplifier,简称lna)、双工器等。此外,rf电路910还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(globalsystemofmobilecommunication,简称gsm)、通用分组无线服务(generalpacketradioservice,简称gprs)、码分多址(codedivisionmultipleaccess,简称cdma)、宽带码分多址(widebandcodedivisionmultipleaccess,简称wcdma)、长期演进(longtermevolution,简称lte)、电子邮件、短消息服务(shortmessagingservice,简称sms)等。
存储器920可用于存储软件程序以及模块,处理器980通过运行存储在存储器920的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。存储器920可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器920可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
输入单元930可用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。具体地,输入单元930可包括触控面板931以及其他输入设备932。触控面板931,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板931上或在触控面板931附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板931可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器980,并能接收处理器980发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板931。除了触控面板931,输入单元930还可以包括其他输入设备932。具体地,其他输入设备932可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示单元940可用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示单元940可包括显示面板941,可选的,可以采用液晶显示器(liquidcrystaldisplay,简称lcd)、有机发光二极管(organiclight-emittingdiode,简称oled)等形式来配置显示面板941。进一步的,触控面板931可覆盖显示面板941,当触控面板931检测到在其上或附近的触摸操作后,传送给处理器980以确定触摸事件的类型,随后处理器980根据触摸事件的类型在显示面板941上提供相应的视觉输出。虽然在图9中,触控面板931与显示面板941是作为两个独立的部件来实现手机的输入和输入功能,但是在某些实施例中,可以将触控面板931与显示面板941集成而实现手机的输入和输出功能。
手机还可包括至少一种传感器950,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板941的亮度,接近传感器可在手机移动到耳边时,关闭显示面板941和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
音频电路960、扬声器961,传声器962可提供用户与手机之间的音频接口。音频电路960可将接收到的音频数据转换后的电信号,传输到扬声器961,由扬声器961转换为声音信号输出;另一方面,传声器962将收集的声音信号转换为电信号,由音频电路960接收后转换为音频数据,再将音频数据输出处理器980处理后,经rf电路910以发送给比如另一手机,或者将音频数据输出至存储器920以便进一步处理。
wifi属于短距离无线传输技术,手机通过wifi模块970可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图9示出了wifi模块970,但是可以理解的是,其并不属于手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
处理器980是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器920内的软件程序和/或模块,以及调用存储在存储器920内的数据,执行手机的各种功能和处理数据,从而对手机进行整体监控。可选的,处理器980可包括一个或多个处理单元;优选的,处理器980可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器980中。
手机还包括给各个部件供电的电源990(比如电池),优选的,电源可以通过电源管理系统与处理器980逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
在本实施例中,该终端设备所包括的处理器980还具有以下功能:
获取学习对象根据用户操作产生的人工样本集;
获取针对所述学习对象的神经网络模型在所述学习对象中自主学习得到机器样本集;
根据所述人工样本集和所述机器样本集训练所述神经网络模型。
本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行图1至图6对应的实施例所述的任一项神经网络模型训练方法。
本申请的说明书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
应当理解,在本申请中,“至少一个(项)”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系,例如,“a和/或b”可以表示:只存在a,只存在b以及同时存在a和b三种情况,其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”,其中a,b,c可以是单个,也可以是多个。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-onlymemory,简称rom)、随机存取存储器(randomaccessmemory,简称ram)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!