基于改进型EAST算法的文本检测方法与流程
本发明涉及一种基于改进型east算法的文本检测方法,该方法适用于身份证文字识别、银行卡文字识别、电子票据文字识别、印刷体文档文字识别、自然场景文字识别等ocr文字识别领域。
背景技术:
ocr(opticalcharacterrecognition)光学字符识别是ai领域的一项重要技术,主要内容是让计算机读取图像中的文字信息。当今主流的ocr技术主要分为两步:1、文本检测,指的是定位出文本在图像中的精确位置;2、文本识别,指的是根据文本检测提供的位置信息将文本裁剪出来并加以识别。
现有ocr领域,文本检测技术多如牛毛,性能良好的检测技术主要都是基于深度神经网络,它们的区别仅在于网络的结构和其他的细枝末节。目前比较流行的文本检测技术有ctpn、textboxes、east、pixellink等,它们都有各自的优缺点,比如ctpn算法的优点是对水平文本的检测精度高,缺点是无法检测倾斜的文本;east文本检测算法虽然可以定位倾斜的文本,但是无法精确定位较长的文本。
技术实现要素:
本发明的目的在于提供一种基于改进型east算法的文本检测方法,解决了原算法对长文本定位准确率低的问题。
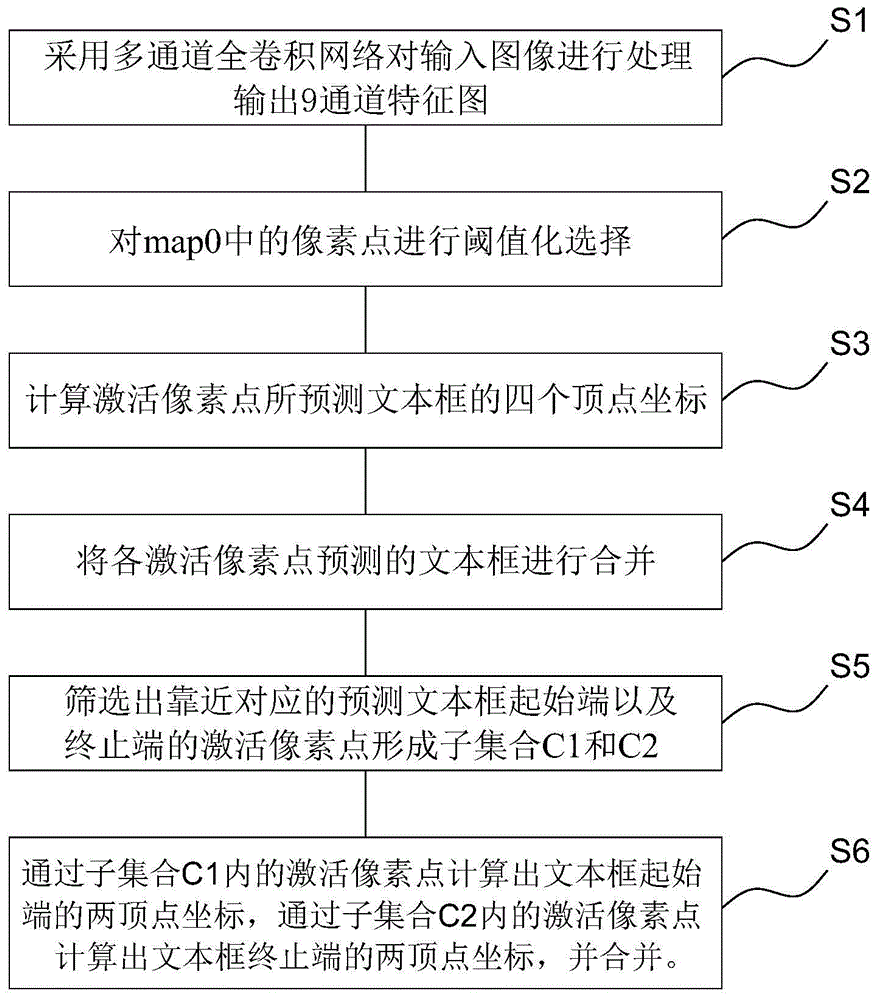
本发明的目的通过如下技术方案实现:一种基于改进型east算法的文本检测方法,它包括以下步骤:
s1.采用多通道全卷积网络对输入图像进行处理,输出一个9通道特征图,分别为map0,map1,map2,map3,map4,map5,map6,map7,map8;
s2.对map0中的像素点进行阈值化选择,将符合阈值范围的像素点选定作为激活像素点;
s3.在map1-map8上分别找到激活像素点对应的坐标,并计算出激活像素点所预测文本框的四个顶点坐标;
s4.将各激活像素点预测的文本框根据重合程度进行合并得到多边形polygon,多边形polygon对应的所有激活像素点组成一个集合c;
s5.从集合c中筛选出靠近对应的预测文本框起始端的激活像素点形成子集合c1以及靠近对应的预测文本框终止端的激活像素点形成子集合c2;
s6.通过子集合c1内的激活像素点计算出文本框起始端的两顶点坐标,通过子集合c2内的激活像素点计算出文本框终止端的两顶点坐标;
将子集合c1得到的两顶点坐标与子集合c2得到的两顶点坐标进行合并,形成最终文本框的四个顶点坐标。
较之现有技术而言,本发明的优点在于:本发明根据文本框中靠近起始端的像素点来预测文本框起始端的两个顶点坐标,根据文本框中靠近终止端的像素点来预测文本框终止端的两个顶点坐标,然后合并上述四个顶点坐标得到最终的预测文本框,从而提高east算法对长文本的预测的准确率。
附图说明
图1是一种基于改进型east算法的文本检测方法的流程图。
图2是iou值计算公式的概念演示图。
图3是计算激活像素点到其预测文本框两个端部顶点的曼哈顿距离的示意图。
图4是用于演示本发明文本检测过程的示例图。
图5是对图4进行阈值化后得到的激活像素点的分布图(黑点表示激活像素点)。
图6是根据图5中激活像素点计算出的预测文本框的示意图。
图7是将图6中各文本框根据重合程度进行合并后的示意图。
图8是对图7中多边形polygon两端激活像素点进行筛选后的示意图。
图9是对图8中两子集合内所有激活像素点进行加权平均处理后的示意图。
图10是本发明最终定位文本框的示意图。
图11是原east文本检测技术预测图片文本框的示意图。
图12是不同算法对图像文本框定位的效果对比图(左边为原east算法处理,右边为本发明处理)。
具体实施方式
下面结合说明书附图和实施例对本发明内容进行详细说明:
本发明是基于east文本检测技术的改进,为了便于更好的理解发明内容,我们首先对east文本检测技术的主要原理进行阐述,east文本检测技术主要由以下两部分组成:
1.multi-channelfcn,多通道全卷积网络,该网络对输入图像进行处理,输出一个9通道的特征图(输出几何图为quad类型的east版本)。9通道的特征图其实就是9张图像矩阵,分别命名为map0,map1,map2,map3,map4,map5,map6,map7,map8,假设第x个图像矩阵mapx上坐标(x,y)处的值为mapx[x][y],每个像素所预测的四边形文本框的四个顶点坐标分别为v1(x1,y1),v2(x2,y2),v3(x3,y3),v4(x4,y4)。
第一张图像map0是概率图,该图像上每个像素值的取值范围都是(0,1),表示该像素是文本像素的概率。其他8张图像上的坐标为(x,y)的像素点上的值分别表示概率图上坐标为(x,y)的像素点所预测的其坐标值x、y到该像素点所在的文本框的四个顶点的坐标值的x、y的偏移量。故概率图中坐标为(x,y)的像素点所预测的所在文本框的四个顶点的坐标分别为:
v1(x1,y1)=v1(x+map1[x][y],y+map2[x][y])
v2(x2,y2)=v2(x+map3[x][y],y+map4[x][y])
v3(x3,y3)=v3(x+map5[x][y],y+map6[x][y])
v4(x4,y4)=v4(x+map7[x][y],y+map8[x][y])
2.thresholding&nms,thresholding阈值化,对第一部分得到的概率图map0中的像素点进行阈值化选择,因为概率图map0中的概率值越大就越可能是文本像素,所以需要把概率值大的像素筛选出来,比如设置阈值为0.9,则概率图map0中概率值大于等于0.9的像素点被选定作为激活的文本像素点,然后根据该像素点的坐标找到对应其他8张图像上的坐标值,并计算得到该像素点对应的文本框的四个顶点坐标,由于一个实际文本框中有很多像素点,这些像素点共同预测一个文本框时,会出现很多重合的文本框,原算法通过nms算法来将这些重合的文本框整合为一个文本框。
上述east算法的缺陷是其全卷积神经网络的感受野有限,无法通过像素点来精确预测相对于图像尺寸距离较远的文本框顶点的坐标,因此无法精确定位长文本,但是east算法能通过某个像素点来精确预测距离较近的文本框顶点的坐标。
上述特点是我们通过实验发现的,图11为east算法对输入图像进行文本框定位的结果,图像中的圆圈表示预测文本框的像素点所在位置,矩形表示该像素点所预测的文本框,由图可知像素点对距离比较近的四边形顶点坐标的预测非常准确,而对距离比较远的四边形顶点坐标的预测比较差。根据这一特点,本发明重新设计了一个文本框回归算法来替代原来的nms算法。
本发明的主要思想是只根据文本框的靠近左端的像素点来预测左端的两个顶点的坐标,并且只根据文本框的靠近右端的像素点来预测右端的两个顶点的坐标,然后合并左右两端像素所预测的文本框的相对的两个顶点得到最终的预测文本框。算法步骤如下:
s1.采用多通道全卷积网络对输入图像进行处理,输出一个9通道特征图,分别为map0,map1,map2,map3,map4,map5,map6,map7,map8。
s2.对map0中的像素点进行阈值化选择,将符合阈值范围的像素点选定作为激活像素点。
s3.在map1-map8上分别找到激活像素点对应的坐标,并计算出激活像素点所预测文本框的四个顶点坐标。
s4.将各激活像素点预测的文本框根据重合程度进行合并得到多边形polygon,多边形polygon对应的所有激活像素点组成一个集合c。
在一些实施例中,通过iou值来确定是否需要对两文本框进行合并,即计算两激活像素点预测文本框的iou值,当iou值大于指定阈值时,将两预测文本框进行合并,并将对应的激活像素点归入集合c内。
在不同的应用场景中,iou阈值有所不同。优选的,iou指定阈值的取值范围为(0.3,1)。
在经过multi-channelfcn和thresholding的处理后,一行文本中会有很多的像素处于激活状态,它们所预测的文本框大多都是重复的,所以首先需要将重合程度比较大的文本框进行合并,通过合并得到一个囊括该文本行内所有激活像素点的多边形,合并条件是如果两个文本框的iou值大于指定阈值(比如0.3)则合并它们,最终得到一个多边形polygon;
但是一张图像上通常有多个文本行,所以最终可得到若干个多边形polygon。
iou(intersectionoverunion)指的是两个四边形的交集的面积和并集的面积的比值,公式是:iou=intersection/union,这个比值越大,说明两个四边形重合程度越高,比值越小,说明两个四边形重叠程度越低,参见图2。
s5.从集合c中筛选出靠近对应的预测文本框起始端的激活像素点形成子集合c1以及靠近对应的预测文本框终止端的激活像素点形成子集合c2;
本发明主要用于预测水平方向的长文本框,故文本框起始端即为文本框的左端,文本框终止端即为文本框的右端。
在一些实施例中,子集合c1和子集合c2的筛选方法为:
求集合c中每个激活像素点到其预测文本框起始端两顶点的曼哈顿距离之和dist1与集合c中每个激活像素点到其预测文本框终止端两顶点的曼哈顿距离之和dist2的比值ratio;
根据比值ratio对集合c内所有激活像素点进行排序,取比值最小的前n个激活像素点组成子集合c1,取比值最大的前n个激活像素点组成子集合c2。
坐标为(x,y)的激活像素点所预测文本框的四个顶点坐标分别为:v1(x1,y1)、v2(x2,y2)、v3(x3,y3)、v4(x4,y4);
ratio=dist1/dist2=(dx1+dy1+dx4+dy4)/(dx2+dy2+dx3+dy3);
其中,dx1=|x1-x|;dy1=|y1-y|;dx2=|x2-x|;dy2=|y2-y|;dx3=|x3-x|;dy3=|y3-y|;dx4=|x4-x|;dy4=|y4-y|。
x、y为激活像素点的坐标,x1、x2、x3、x4、y1、y2、y3、y4为激活像素点预测的文本框四个顶点的坐标值,参见图3。
s6.通过子集合c1内的激活像素点计算出文本框起始端的两顶点坐标,通过子集合c2内的激活像素点计算出文本框终止端的两顶点坐标;
将子集合c1得到的两顶点坐标与子集合c2得到的两顶点坐标进行合并,形成最终文本框的四个顶点坐标。
在一些实施例中,文本框起始端或终止端的两顶点坐标的确定方法如下:
对子集合c1中的激活像素点所预测的文本框起始端两顶点按照概率值进行加权平均,得到子集合c1中所有激活像素点所预测的文本框起始端两顶点的坐标c1_v1,c1_v4;
对子集合c2中的激活像素点所预测的文本框终止端两顶点按照概率值进行加权平均,得到子集合c2中所有激活像素点所预测的文本框终止端两顶点的坐标c2_v2,c2_v3;
将子集合c1和子集合c2所得的顶点坐标合并,形成最终文本框的四个顶点坐标:c1_v1,c2_v2,c2_v3,c1_v4。
预测文本框顶点的加权平均算法如下:
xn代表子集合c1或子集合c2中第n个激活像素点所预测的顶点中x坐标值,yn代表子集合c1或子集合c2中第n个激活像素点所预测的顶点中y坐标值,fn代表第n个激活像素点在map0上对应的概率值。
下面通过具体实例对本发明进行讲解:
1.输入待检测图像,参见图4。
2.通过多通道全卷积网络对输入图像进行处理,得到输入图像的概率图map0,对概率图map0进行阈值化后得到激活像素点分布图,参见图5(图中黑点表示激活像素点)。
3.在map1-map8上分别找到激活像素点对应的坐标,并计算出激活像素点所预测文本框的四个顶点坐标,参见图6。
4.合并重合的文本框得到如下两个多边形polygon1和多边形polygon2,它们共同组成多边形集合polygons,参见图7。
5.求文本行左端像素点子集合c1和右端像素点子集合c2,参见图8。
6.对子集合c1中的激活像素点所预测的文本框四个顶点坐标按照概率值进行加权平均,得到子集合c1中所有激活像素点所预测的文本框四个顶点坐标c1_v1,c1_v2,c1_v3,c1_v4;
对子集合c2中的激活像素点所预测的文本框四个顶点坐标按照概率值进行加权平均,得到子集合c2中所有激活像素点所预测的文本框四个顶点坐标c2_v1,c2_v2,c2_v3,c2_v4;
图9演示了两个多边形polygon的坐标处理结果,为了方便理解,图中添加了实际文本的位置。
8.取c1_v1,c2_v2,c2_v3,c1_v4组成最终的预测文本框的四个顶点坐标,连接形成四边形,参见图10。
- 还没有人留言评论。精彩留言会获得点赞!