基于高斯回归算法的K-Means聚类分析车道流量方法与流程
本发明涉及交通控制工程、大数据分析应用领域,尤其利用高斯回归算法得到拟合曲线,通过基于k-means聚类算法对每天的流量曲线聚类分析,得到某路口能最佳适应配时方案。
背景技术:
随着城市经济的发展,人均轿车保有量不断上升,道路交通的拥堵问题日益凸显,随着城市基础建设的不断推进对于路口信号灯的配时方案的优化也迫在眉睫。由于车道车流量变化的快速性、复杂性和不确定性,其中表现较为突出的是受早晚高峰等时段的影响大,车流量变化较为明显,从而导致城市路网交通状态变化频繁、复杂,适应困难,常处于混合交通状态中。而现在基于k-means聚类算法对单周单日车流量的分类、分析和计算,将对路口交通信号灯配时方案做有效调整。
技术实现要素:
为了能规划出更适合于某日期某路口特定的配时方案,以便更好的优化路口交通拥堵问题,做到对每个路口有个性化的配置方案。考虑到城市路网交通流量的快速性、随机性、复杂性和时段性,每个月每周每天的流量都会发生或大或小变动,前一个时间段段配时方案不一定适合下一个时间段的流量,因此需要对路口流量分析并反馈,适时地对方案进行动态的调整,本发明提出了一种基于高斯回归算法的k-means聚类分析车道流量方法,利用聚类算法把类似的流量分布的日期归为同一类,得到更加精确的流量分类结果。
本发明解决其技术问题所采用的技术方案是:
一种基于高斯回归算法的k-means聚类分析车道流量方法,包括以下步骤:
1)在数据库中获取某交叉路口的过车流量数据表,根据过车数据统计某一规定步长下的时间间隔,将一天划分成n个时段,通过的车辆数集合,记为pn,单位为车辆数集合;n为1,2,3……n,计算得到n维的车流量,记为v,其中v(t)代表当前路口t时段的车流量;
2)运用超参数优化的高斯过程回归算法对流量v进行平滑处理,计算过程如下:
2.1)设置初始超参数hyp0=[sf0,ell0,sn0],分别表示高斯核函数的函数标准差、核函数的特征长度尺度、噪声标准偏差,开始进入训练过程;
2.2)为了消除由于横纵坐标差距过大带来的影响,对车流量v进行归一化处理:
2.3)进入第l次迭代过程,首先计算高斯核函数,此处采用时间t和它本身的协方差函数,考虑到噪声的影响,计算公式如式(3):
式中:k为协方差矩阵,在此处由于是时间t和其自身的协方差,故矩阵为n维方阵,kij为矩阵内对应的元素,计算公式如下式(4):
2.4)计算边缘函数nlz,作为超参数优化的目标函数:
式中:l为高斯核函数k的cholesky分解所得的上三角阵,记作l=chol(k);
2.5)以nlz为目标函数,采用梯度下降法做超参数优化,若本次迭代结果nlzl不为最优解,则l=l+1,返回步骤2.2重新计算;若本次迭代结果已达到最优,则返回hypl,并跳出循环;
2.6)输入需要预测的时间向量
2.7)以式(8)计算回归后的车流函数,并以训练过程中已知的vmax和vmin,做反归一化处理,最终得到回归后的车流函数
3)根据得到的车流函数
4)设定某一最大的迭代次数为n_max,该数值必须大于或等于聚类后能得到的最大簇数。然后基于k-means聚类算法进行聚类运算,聚类簇数则以给定迭代簇值进行迭代聚类;
5)得到在各个簇值k下的聚类情况,使用轮廓系数法找到迭代聚类之后得到的最佳k值,在迭代完最大聚类次数n_max之后,对当前簇数值进行处理,给定一个阀值f,当两个聚类中心对距离小于该阀值就合并两个簇,相应地簇数值就会减一;若没有小于该阀值的则保持原有的k值;
6)对于分成的k个簇,以及簇中的每个向量,计算得到他们相应的轮廓系数,对于某簇中的一个点i,计算i向量到所有它属于的簇中的其他点的距离得到a(i),即称为样本i的簇内不相似度,a(i)越小说明样本越该被聚类到该簇中;计算i向量到所有非本身所在簇的点的平均距离b(i),即称为样本i的簇间不相似度,b(i)越大说明样本越不属于其他簇,那么对应的向量i的轮廓系数s(i)就为:
可见轮廓系数的值是介于[-1,1],s(i)接近1,则说明样本i聚类合理s(i)接近-1,则说明样本i更应该分类到另外的簇;若s(i)近似为0,则说明样本i在两个簇的边界上。求出所有点的轮廓系数并求出平均值,就是该聚类结果的轮廓系数;
7)利用轮廓系数法判断得到的相对的最佳聚类簇数值作为新的k值,再以此k值进行进行基于k-means聚类的算法,最后输出聚类结果;
8)参考聚类结果给出相应的最佳调度方案。
本发明的有益效果表现在:利用聚类算法把类似的流量分布的日期归为同一类,得到更加精确的流量分类结果。
附图说明
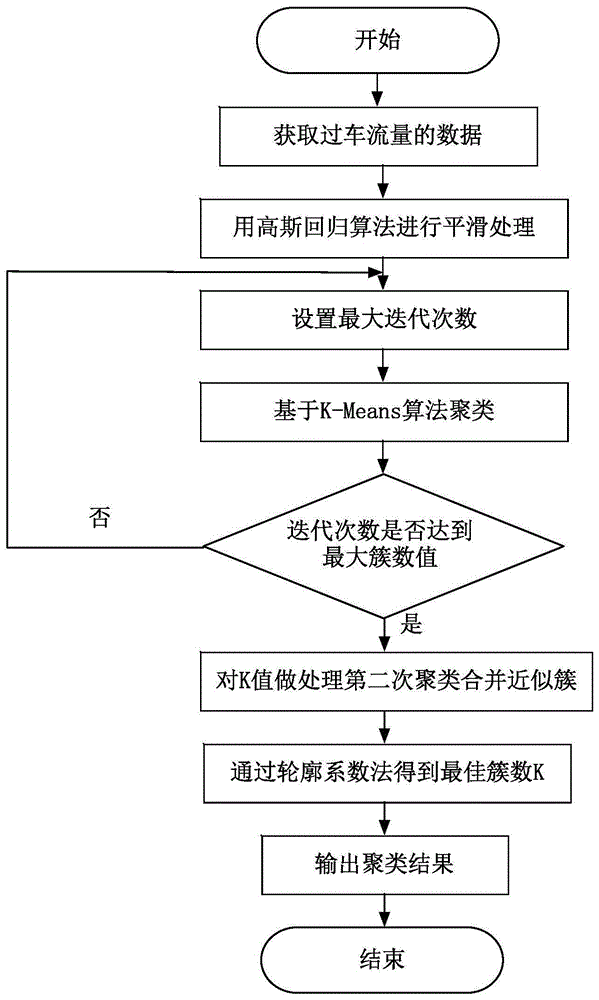
图1是基于高斯回归算法的k-means聚类的逻辑流程图;
图2是浙江台州某一实际路网示意图;
图3是基于高斯回归算法的曲线图;
图4是基于k-means聚类算法的聚类结果示意图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图4,一种基于高斯回归算法的k-means聚类分析车道流量方法,包括以下步骤:
1)在数据库中获取某交叉路口的过车流量数据表,根据过车数据统计某一规定步长下的时间间隔δt=5,单位为秒,将一天划分成n(n=288)个时段,通过的车辆数集合,记为pn,单位为车辆数集合;n为1,2,3……n,计算得到288维的车流量,记为v,其中v(t)代表当前路口t时段的车流量;
2)运用超参数优化的高斯过程回归算法对流量v进行平滑处理,计算过程如下:
2.1)设置初始超参数hyp0=[sf0,ell0,sn0],分别表示高斯核函数的函数标准差、核函数的特征长度尺度、噪声标准偏差,开始进入训练过程;
2.2)为了消除由于横纵坐标差距过大带来的影响,对车流量v进行归一化处理:
2.3)进入第l次迭代过程,首先计算高斯核函数,此处采用时间t和它本身的协方差函数,考虑到噪声的影响,计算公式如式(3):
式中:k为协方差矩阵,在此处由于是时间t和其自身的协方差,故矩阵为n维方阵,kij为矩阵内对应的元素,计算公式如下式(4):
2.4)计算边缘函数nlz,作为超参数优化的目标函数:
式中:l为高斯核函数k的cholesky分解所得的上三角阵,记作l=chol(k);
2.5)以nlz为目标函数,采用梯度下降法做超参数优化,若本次迭代结果nlzl不为最优解,则l=l+1,返回步骤2.2重新计算;若本次迭代结果已达到最优,则返回hypl,并跳出循环;
2.6)输入需要预测的时间向量
2.7)以式(8)计算回归后的车流函数,并以训练过程中已知的vmax和vmin,
做反归一化处理,最终得到回归后的车流函数
3)根据得到的车流函数
4)设定某一最大的迭代次数为n_max,该数值必须大于或等于聚类后能得到的最大簇数,然后基于k-means聚类算法进行聚类运算,聚类簇数则以给定迭代簇值进行迭代聚类;
5)得到在各个簇值k下的聚类情况,使用轮廓系数法找到迭代聚类之后得到的最佳k值,在迭代完最大聚类次数n_max之后,对当前簇数值进行处理,给定一个阀值f,当两个聚类中心对距离小于该阀值就合并两个簇,相应地簇数值就会减一;若没有小于该阀值的则保持原有的k值;
6)对于分成的k个簇,以及簇中的每个向量,计算得到他们相应的轮廓系数,对于某簇中的一个点i,计算i向量到所有它属于的簇中的其他点的距离得到a(i),即称为样本i的簇内不相似度,a(i)越小说明样本越该被聚类到该簇中;计算i向量到所有非本身所在簇的点的平均距离b(i),即称为样本i的簇间不相似度,b(i)越大说明样本越不属于其他簇,那么对应的向量i的轮廓系数s(i)就为:
可见轮廓系数的值是介于[-1,1],s(i)接近1,则说明样本i聚类合理s(i)接近-1,则说明样本i更应该分类到另外的簇;若s(i)近似为0,则说明样本i在两个簇的边界上,求出所有点的轮廓系数并求出平均值,就是该聚类结果的轮廓系数;
7)利用轮廓系数法判断得到的相对的最佳聚类簇数值作为新的k值,再以此k值进行进行基于k-means聚类的算法,最后输出聚类结果;
8)参考聚类结果给出相应的最佳调度方案。
本实施例以台州市实际路网区域的某一路口作为实施例子,如图2所示路网,以2017年5月24日至2017年5月30日连续七天,在人为标号为77号的路口通过的车辆数据作为例子进行演示,标号为77号的路口为图2中的某一路口,基于高斯回归算法的k-means聚类分析车道流量的结果,包括以下步骤:
1)第一步,获取在2017年5月24日至2017年5月30日的七天中在77号路口的过车流量数据表,以δt=5分钟作为步长将一天24小时划分为288个单位,将通过的车辆数集合,记为pn,单位为车辆数集合;n为1,2,3……n,计算得到288维的车流量,记为v,其中v(t)代表当前路口t时段的车流量;
2)运用超参数优化的高斯过程回归算法对流量v进行平滑处理,也就是根据过车数据表每隔五分钟统计一次过车曲线图数量根据坐标画出流量,然后利用高斯回归算法将其拟合成光滑曲线,以此七天的过车数据中就能得到七条拟合图,拟合得到的光滑曲线即图3所示,计算过程如下:
2.1)设置初始超参数hyp0=[sf0,ell0,sn0],分别表示高斯核函数的函数标准差、核函数的特征长度尺度、噪声标准偏差,开始进入训练过程;
2.2)为了消除由于横纵坐标差距过大带来的影响,对车流量v进行归一化处理:
2.3)进入第l次迭代过程,首先计算高斯核函数,此处采用时间t和它本身的协方差函数,考虑到噪声的影响,计算公式如式(3):
式中:k为协方差矩阵,在此处由于是时间t和其自身的协方差,故矩阵为n维方阵,kij为矩阵内对应的元素,计算公式如下式(4):
2.4)计算边缘函数nlz,作为超参数优化的目标函数:
式中:l为高斯核函数k的cholesky分解所得的上三角阵,记作l=chol(k);
2.5)以nlz为目标函数,采用梯度下降法做超参数优化,若本次迭代结果nlzl不为最优解,则l=l+1,返回步骤2.2重新计算;若本次迭代结果已达到最优,则返回hypl,并跳出循环;
2.6)输入需要预测的时间向量
2.7)以式(8)计算回归后的车流函数,并以训练过程中已知的vmax和vmin,做反归一化处理,最终得到回归后的车流函数
3)根据得到的车流函数
4)设定某一最大的迭代次数为n_max=10,该数值必须大于或等于聚类后能得到的最大簇数,本例子的最大聚类簇数为7,符合要求,然后基于k-means聚类算法进行聚类运算,聚类簇数则以给定迭代簇值进行迭代聚类;
5)得到在各个簇值k下的聚类情况,使用轮廓系数法找到迭代聚类之后得到的最佳k值,在迭代完最大聚类次数n_max之后,对当前簇数值进行处理,给定一个阀值f,当两个聚类中心对距离小于该阀值就合并两个簇,相应地簇数值就会减一;若没有小于该阀值的则保持原有的k值;
6)对于分成的k个簇,以及簇中的每个向量,计算得到他们相应的轮廓系数,对于某簇中的一个点i,计算i向量到所有它属于的簇中的其他点的距离得到a(i),即称为样本i的簇内不相似度,a(i)越小说明样本越该被聚类到该簇中;计算i向量到所有非本身所在簇的点的平均距离b(i),即称为样本i的簇间不相似度,b(i)越大说明样本越不属于其他簇,那么对应的向量i的轮廓系数s(i)就为:
可见轮廓系数的值是介于[-1,1],s(i)接近1,则说明样本i聚类合理s(i)接近-1,则说明样本i更应该分类到另外的簇;若s(i)近似为0,则说明样本i在两个簇的边界上,求出所有点的轮廓系数并求出平均值,就是该聚类结果的轮廓系数;
7)利用轮廓系数法判断得到的相对的最佳聚类簇数值作为新的k值,如图3所示,以此过车数据作为例子得到的最佳k值为2,再以此k=2的簇值进行基于k-means聚类的算法,最后输出聚类结果;
8)最后得到聚类完成之后的曲线,如图4所示,7天的过车流量可以大致分为两类,第一类为:2017年5月24日、25日、26日(周三、四、五),第三类为2017年5月27日、28日、29日、30日(周六、日、一、二),则在本路口的此阶段内需要在一周中有两不同的周调度方案,方案一针对周三、四、五;方案二针对周六、日、一、二。
以上阐述的是本发明给出的一个实施例表现出来的优良效果,显然本发明不仅适合上述实施例,在不偏离本发明基本精神及不超出本发明实质内容所涉及内容的前提下可对其做种种变化并加以实施。
- 还没有人留言评论。精彩留言会获得点赞!