一种基于语义对齐多区域模板融合的三维人脸识别方法与流程
本发明属于图像处理及模式识别技术领域,更具体的是涉及一种基于语义对齐多区域模板融合的三维人脸识别方法。
背景技术:
人脸识别在公安刑侦、国家安全、市场金融等诸多领域具有广泛的应用前景。然而,鉴于三维人脸本身的可形变特性以及易受不同表情变化的影响,发展对表情鲁棒的人脸识别算法一直都是三维人脸识别领域的研究热点和难点问题。
目前,表情鲁棒的三维人脸识别方法主要分为统计模型方法、同等形变模型方法和基于区域的方法。其中统计模型方法即通过构建统计模型对表情变化引起的面部软组织形变关系进行刻画,算法的精度和鲁棒程度受训练统计模型所采用的三维人脸库的表情变化多样性、数据质量等的影响;同等形变模型方法即将表情变化引起的三维人脸形变转化为等距形变问题建模,将表情变化近似为等距形变,用等距形变特征近似表情变化特征,同等形变的方法通过弱化表情变化引起的三维形变达到表情鲁棒,然而,同等形变一定程度上也弱化了人脸原有三维结构。
由于表情变化呈现局部性,相较上述整体类方法,基于区域类方法表现出更多的灵活性和稳定性。基于区域的表情不变三维人脸识别方法即结合人脸表情的分布特点,将人脸区域划分为表情易变和表情不变区域,然后分别针对表情不变和表情易变区域设计不同的相似度匹配策略。传统基于区域类方法如,依据关键特征点位置进行人脸区域划分。此类方法将表情不变区域和表情易变区域分开处理,对表情变化具有较强的适应性,但是前提是表情不变和表情易变区域的划分要准确,否则将直接影响此类方法的整体准确度。
以往基于区域划分的表情鲁棒三维人脸识别方法很难将表情不变区域与表情易变区域准确划分,主要有两方面原因,首先,人脸区域的划分通常依赖面部特征点的准确定位,而三维人脸特征点的定位又是一个尚未完全解决的问题。其次,对于不同对象三维人脸,很难严格界定表情不变和表情易变区域。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提出了一种基于语义对齐多区域融合的三维人脸识别方法,解决了基于区域方法存在的比较依赖区域划分精准度以及没有充分利用整个人脸区域的问题。
(二)技术方案
为实现上述目的,本发明提供如下技术方案:一种基于语义对齐的多区域融合三维人脸识别方法,其步骤如下:
一、确定三维人脸数据库的注册人脸和测试人脸数据集,其中注册人脸数据集包含每人一个中性表情的三维人脸数据;
二、对所有注册人脸和测试人脸数据集进行预处理,包括鼻尖点检测、切割人脸区域、姿态矫正和数据填补,并将所有注册和待识别三维人脸模型与参考模型进行点云稠密对齐;
三、将人脸区域预划分为多个不含表情影响的、可重叠的模版区域,得到多个相对可靠的区域分类器;
四、对每个模版区域,在人脸的三维结构上直接计算模版区域间的相似度值,其中相似度值定义为两人脸区域语义对应坐标点的欧式距离平方和,即
五、对每个区域分别单独投票,设区域相似度用si表示,其对应相似度阈值用ti表示,则每个区域的投票结果表示为
六、综合多个区域匹配结果,采用多数投票的方式确定最终的匹配结果,所有模版区域投票数总和n与一个总体阈值tv(0≤tv≤24)进行比较,当投票总数大于阈值tv时,即认为匹配成功,否则匹配失败,公式表示为
所述步骤二中的鼻尖点检测,采用的是基于曲率的鼻尖点自动检测方法。
所述步骤二中的切割人脸区域,过程是以鼻尖点为中心,计算任意点(x,y,z)与鼻尖点(x0,y0,z0)的测地线距离d,若d≤100mm则保留该点到人脸区域,若d>100mm则丢弃该点,依次剪切出整个人脸区域。
所述步骤二中的姿态矫正,采用已对齐的中性三维人脸数据的平均人脸作为参考模型,将所有注册三维人脸和待测试三维人脸与该参考模型通过最近点迭代法(iterativeclosestpoint,icp)进行姿态矫正。
所述步骤二中的数据填补,采用对称填补的方法对缺失人脸数据进行填补,缺失的部分数据使用相应的对称进行填补。
所述步骤二中的点云稠密对齐过程为:设q为待对齐模型,t为参考模型,则q=(v,e),其中v是顶点,共n个,e表示边,xi表示每个顶点的变换矩阵,则所有顶点的变换矩阵可表示为x=[x1,x2,...,xn]t;然后分别最小化数据、平滑、以及关键点损失函数。
所述步骤五中的相似度阈值ti的取值过程为:当far(falseacceptancerate,far=0.1%即允许千分之一误识率的条件下)为定值,每个区域的真实样本通过率tar(truthacceptancerate)来确定每个区域的相似度阈值。
所述步骤六中的总体阈值tv的取值过程为:分别对每个区域所确定阈值进行投票,然后根据投票结果,获得的最多投票数即为最终的总体阈值。
(三)有益效果
与现有技术相比,本发明提供了一种基于语义对齐的多区域融合三维人脸识别方法,具备以下有益效果:
1.本发明的一种基于语义对齐的多区域模板融合三维人脸识别方法,采用多模板区域划分方法不需要面部特征点辅助,同时多模板区域相互独立进行相似度预测,减小了算法对单一区域精准划分的依赖性;
2.本发明的一种基于语义对齐的多区域模板融合三维人脸识别方法,依据易受表情影响区域设计的多表情影响区域去除的模版,既有效避免了以往依赖特征点的区域划分问题,同时也得到了多个相对可靠的区域分类器。
3.本发明的一种基于语义对齐的多区域模板融合三维人脸识别方法,采用多区域模版共同投票策略,不光对表情鲁棒,对其他受区域影响因素(如遮挡)也具有一定的鲁棒性。
附图说明
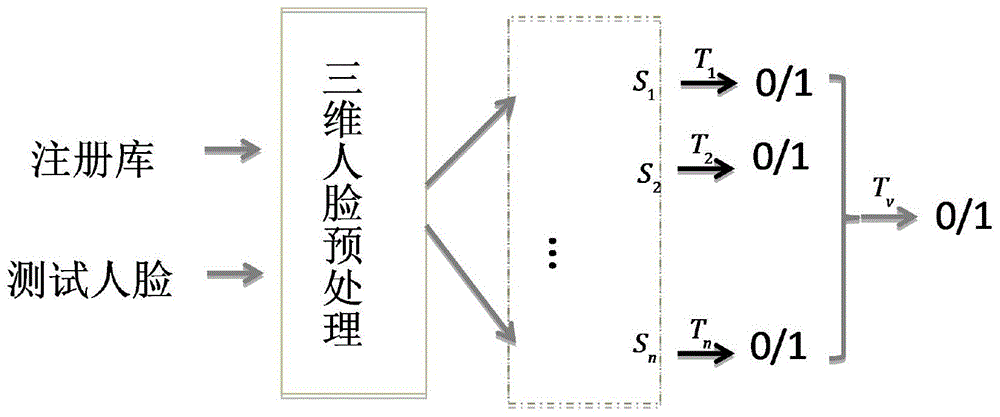
图1为本发明的一种基于语义对齐多区域模板融合的三维人脸识别方法流程图。
图2为本发明的三维人脸模型预处理流程图。
图3为预处理时模版区域示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图对本发明实施例作进一步说明:
本发明提供一种基于语义对齐的多区域模板融合三维人脸识别方法,用于人脸的精准识别。
如图1所示本发明的一种基于语义对齐的多区域模板融合三维人脸识别方法的流程图:确定三维人脸数据库的注册人脸和测试人脸数据集,其中注册人脸数据集包含每人一个中性表情的三维人脸数据;对所有注册人脸和测试人脸数据集进行预处理,将所有注册和待识别三维人脸模型与参考模型进行点云稠密对齐,对齐之后的三维人脸拥有相同的点数、相同的拓扑结构,并且各点之间存在语义上的一一对应关系;将人脸区域预划分为多个不含表情影响的、可重叠的模版区域,得到多个相对可靠的区域分类器;对每个模版区域,在人脸的三维结构上直接计算模版区域间的相似度值,对每个区域分别单独投票,综合多个区域匹配结果,采用多数投票的方式确定最终的匹配结果。
如图2所示本发明的三维人脸模型预处理流程图,包括鼻尖点检测、切割人脸区域、姿态矫正、数据填补和点云稠密对齐。其中鼻尖点检测,采用的是基于曲率的鼻尖点自动检测方法;切割人脸区域,过程是以鼻尖点为中心,计算任意点(x,y,z)与鼻尖点(x0,y0,z0)的测地线距离d,若d≤100mm则保留该点到人脸区域,若d>100mm则丢弃该点,依次剪切出整个人脸区域;姿态矫正,采用已对齐的中性三维人脸数据的平均人脸作为参考模型,将所有注册三维人脸和待测试三维人脸与该参考模型通过最近点迭代法(iterativeclosestpoint,icp)进行姿态矫正;数据填补,采用对称填补的方法对缺失人脸数据进行填补,缺失的部分数据使用相应的对称进行填补;点云稠密对齐,设q为待对齐模型,t为参考模型,则q=(v,e),其中v是顶点,共n个,e表示边,xi表示每个顶点的变换矩阵,则所有顶点的变换矩阵可表示为x=[x1,x2,...,xn]t,然后分别最小化数据、平滑、以及关键点损失函数。
如图3所示预处理时模版区域示意图,本发明的三维模版区域投影共计24个模版,白色代表模版包含数据,黑色代表模版不包含数据。由于受表情、遮挡等因素的影响,即使经过语义对齐的三维人脸模型,也无法避免由于局部形变导致的同一对象(类内)的相似度差异大于不同对象(类间)间的相似度的问题。为了减小局部区域形变严重进而影响整体区域相似度计算的问题,以往算法大多将人脸划分为互不重叠的多个局部区域,考虑一般局部区域的区分度也小,即使融合多个局部区域对整张人脸识别能力依然有限,本发明提出基于易受表情影响区域特性,将人脸区域划分为多个不含表情影响的模版区域再分别进行匹配,即基于多模版区域的投票策略,依据易受表情影响区域设计的多表情影响区域去除的模版,既有效避免了以往依赖特征点的区域划分问题,同时也得到了多个相对可靠的区域分类器。
人脸主要包括眼睛、额头、鼻子、嘴巴、脸颊等区域,不同区域受表情影响程度不同,如通常认为额头、鼻子受表情影响较小,但额头易受帽子、头发等遮挡的影响;眼睛区域易受表情或眼镜遮挡的影响;嘴巴和脸颊受表情影响最大。但是,考虑不同对象受表情影响区域不同,不同表情影响人脸区域亦不同,因此,本发明提出了基于局部区域的不同区域模版划分方法,模版设计思想为:将人脸按照易受表情影响区域划分为多个不同的模版区域,对于某一对象的某种表情,显然,受表情影响小的同一对象区域之间具有较大的相似度,而部分受表情影响较大的区域则倾向具有较小的相似度;最终的投票结果由多数相似度较大区域投票得到最终识别结果,即受表情影响较小区域决定,因此,该多区域模版融合方法不但对表情遮挡有一定的鲁棒性,同时对区域划分具有很强的容忍性。
区域相似度就是将待测试三维人脸于注册库中三维人脸之间进行相似度比较,相似度值最大的最相似。本发明共使用24个区域模版,针对每个模版区域内的三维人脸信息,都独立进行相似度计算,为了保证算法整体的运行速度以及避免损失三维人脸结构信息,本发明定义人脸区域语义对应坐标点的欧式距离平方和作为两人脸区域的相似度值,即
式中,p(xj,yj,zj)为待测试人脸区域中某点,g(xi,yi,zi)为注册库中人脸区域中其语义对应点,相似度值越大,表示两区域越相似,当相似度值大于一定阈值时,即判定为同一人脸。
关于多分类器融合的方法有很多,如分数级融合,决策级融合等。本发明选用后者,并按照多数投票机制对多模版分类器投票结果进行融合。主要基于以下两方面考虑:首先,我们根据人脸特性将人脸划分为不同的区域,每个区域之间是相互独立的,因此,分类结果也应该相互独立;其次,当人脸受表情、遮挡等因素影响比较严重时,受影响严重的这些区域必然具有较小的相似度,而受影响较小的人脸区域仍然可以得到较高的相似度,每个区域分别单独投票的好处是少数受影响区域的投票结果并不影响其它不受影响的区域获得准确的分类。
设区域相似度用si表示,其对应相似度阈值用ti表示,则每个区域的投票结果表示为
式中,相似度阈值ti的取值过程为:当far(falseacceptancerate,far=0.1%即允许千分之一误识率的条件下)为定值,每个区域的真实样本通过率tar(truthacceptancerate)来确定每个区域的相似度阈值。
然后,所有模版区域投票数总和n与一个总体阈值tv(0≤tv≤24)进行比较,当投票总数大于阈值tv时,即认为匹配成功,否则,匹配失败,公式表示为
式中,总体阈值tv的取值过程为:分别对每个区域所确定阈值进行投票,然后根据投票结果,获得的最多投票数即为最终的总体阈值。
本发明阐述了基于语义对齐的多区域模板融合三维人脸识别方法,首先利用一个参考模型实现所有三维人脸模型的预处理及模型之间的语义对齐,然后依据表情对人脸影响,设计多个独立的有重叠的人脸区域,在每个模版区域内分别计算区域相似度并投票,最后,采用多数投票法决定最终的识别结果。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!