一种基于混合推荐算法的学术会议推荐系统的制作方法
本发明涉及计算机网络的技术领域,尤其是指一种基于混合推荐算法的学术会议推荐系统。
背景技术:
如今,用户可以通过各种设备和服务访问大量的网络应用。由于移动平台提供的功能增强,用户可以随时随地访问感兴趣的网络资源,互联网越来越上的信息量的不断增长,推荐系统已成为克服此类信息过载问题的有效策略。推荐系统能够有效地改善过度选择等隐藏在庞大网络资源下的问题,其实用性不容小觑,因此它在许多网络应用中被广泛采用。而用户和资源的多样性导致单一模型实现的推荐引擎效果不尽如人意,因此混合推荐算法的研究具有重大意义。
高校、研究机构环境下,同样存在信息过载的问题,其中学术会议信息是备受重视的,此类信息是高校师生、研究人员非常关注并且时常接触的,此类信息的来源渠道包括科研人员收到的科研邮件,公开发布学术会议通知的网站,科研人员所属机构的内部资源分享等。近年来学术会议的数量也在不断扩展,质量也良莠不齐,因此在现实中存在一些常见的问题,一方面网络上垃圾邮件、订阅邮件、广告邮件泛滥,科研人员在处理邮件时需要耗费相当多的时间精力去筛选学术会议的通知类邮件;另一方面高校人员会接触到许多的学术会议信息,但是其中绝大部分并不符合他们的研究领域以及科研水平;另外此类学术会议信息中往往有一些不重要的部分,在处理信息时需要花费时间去定位有效信息,实现学术会议信息的个性化推送有助于提高科研人员处理信息的效率,从而激发学术热情,促进学术研究工作,十分具有研究意义。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于混合推荐算法的学术会议推荐系统,能够从用户个人邮件及公开会议发布网站上获取学术会议信息,并根据用户的历史行为及学术会议内在特征实现学术会议信息的个性化推荐,并通过基于web的展示和网盘归档两种方法实现信息的推送。
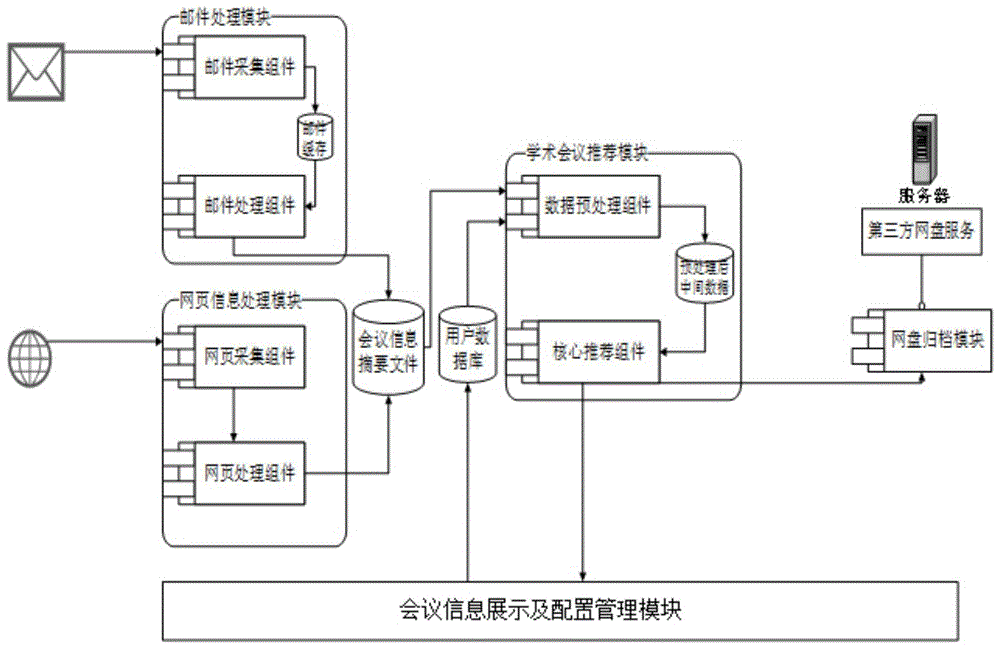
为实现上述目的,本发明所提供的技术方案为:一种基于混合推荐算法的学术会议推荐系统,所述系统通过用户邮件过滤、公开会议通知网站信息采集两种方法获取学术会议通知信息,对学术会议通知信息分别进行邮件数据的预处理和html网页数据提取,经处理后生成统一格式的会议信息持久化存储在服务器上,根据服务器性能及数据更新速度设置合适的时间间隔布置定时任务,该定时任务实现用户和物品相关度的计算,计算方法为一种融合基于用户的协同过滤和基于内容的混合推荐算法,其中基于内容的算法以tf-idf结合词向量的文本表示为基础,并根据相关度对用户进行会议推荐,推荐结果通过网页展示和归档到网盘两种方法推送给用户;所述系统具体包括以下模块:
邮件信息处理模块,用于实现接收电子邮件数据,解码邮件数据形成邮件摘要,筛选学术会议通知类邮件并根据邮件正文进行基于svm的学术会议领域分类,对经过筛选的邮件正文进行基于规则的有效信息提取,存储处理后的学术会议信息元数据及邮件摘要;
网页信息处理模块,用于实现根据系统配置指定目标网页,实时检查目标网页情况,采集目标网页更新的学术会议通知资源,记录无法连接或结构变更的失效网页,并用基于标签的方法提取网页中的有效信息,存储处理后的学术会议信息元数据及网页摘要;
学术会议推荐模块,用于实现对用户数据及邮件信息处理模块和网页信息处理模块存储的会议数据进行预处理,通过定时任务在指定时间通过融合基于用户的协同过滤和基于内容的混合推荐算法得到用户物品相关度,并根据相关度及用户配置生成推荐结果并缓存;
网盘归档模块,用于实现学术会议推荐模块推荐结果获取,根据推荐结果包含的用户依次检查关联网盘,将推荐给对应用户的学术会议通知邮件摘要或网页正文归档到用户的网盘;
会议信息展示及配置管理模块,用于实现用户管理个人信息和用户配置系统相关设置,展示相关学术会议摘要,反馈推荐结果,订阅会议网站。
进一步,所述邮件信息处理模块包括邮件采集组件和邮件处理组件;所述邮件采集组件实现邮件接收、邮件解析、邮件过滤和邮件缓存;所述邮件处理组件实现基于svm的学术会议通知邮件领域分类,基于规则的有效信息提取,学术会议信息元数据及邮件原件的存储;其中:
所述邮件采集组件创建监听25端口的socket,实现一个信道接收smtp连接的命令并按协议规范进行处理,若rcptto命令所标识的收件人地址不在系统的用户名单中,拒绝传输,在符合条件的传输中,获取邮件具体内容,根据smtp及mime协议解码邮件报文数据,提取其邮件头和邮件体,获取邮件头中的收件人地址、发件人地址和主题数据,使用基于关键词规则的方法对邮件体即邮件正文进行过滤,筛选出学术会议通知类邮件;为防止阻塞邮件接受,对于通过筛选的邮件生成唯一的文件名,以[字段名:字段]的格式分别将邮件头数据和邮件正文写入文件形成邮件摘要,通过redis数据库创建邮件处理工作队列,将文件名添加到处理队列中通知后续邮件处理组件;
所述邮件处理组件通过轮询邮件处理工作队列获取到待处理的文件后,使用离线训练得到的svm模型对邮件正文进行领域多分类得到该学术会议通知邮件的会议领域,利用正则表达式的规则提取邮件正文中的有效信息包括会议名称、会议届数、会议开始时间、会议截止时间、会议截稿时间和会议投稿方式,加上会议领域、会议来源即邮件收件人地址、邮件摘要文件地址作为会议信息元数据存储在关系型数据库中,通过redis数据库创建会议数据预处理工作队列,将新增会议的会议id添加到数据预处理工作队列。
进一步,所述网页信息处理模块包括网页采集组件和网页处理组件;所述网页采集组件实现目标网页更新检查、目标网页信息采集和目标网页失效报警;所述网页处理组件实现基于标签的网页有效信息提取、学术会议信息元数据及网页摘要的存储;其中:
所述网页采集组件定时于每日0点执行采集任务,通过读取配置文件,获取目标网站的简称、url和最近更新日期,目标网站为公开发布会议举办通知的网站,采集网页上相对于最近更新日期之后发布的会议举办通知的网页资源以html格式文件传输下来并修改配置文件最近更新日期,若采集失败,获取错误信息使用邮件通知管理员并更改配置文件对应目标网站状态为不可用;
所述网页处理组件通过观察各个目标网站的网页结构设计实现基于html标签的有效信息获取函数,根据目标网站的简称选择不同的信息提取函数处理上述网页资源,获取会议名称、会议届数、会议开始时间、会议截止时间、会议截稿时间、会议领域和会议投稿方式,会议举办通知正文,将网页来源网站简称、网页采集时间和会议举办通知正文保存为网页摘要文件,将会议有效信息及网页摘要文件地址存储在关系型数据库中,将新增会议的会议id添加到会议数据预处理工作队列。
进一步,所述学术会议推荐模块包括数据预处理组件和核心推荐组件;所述数据预处理组件实现用户数据预处理、会议信息预处理、中间数据存储和失效数据检查及清理;所述核心推荐组件实现相关度计算、用户配置读取、推荐结果生成和推荐结果缓存;其中:
所述数据预处理组件通过轮询检查会议数据预处理队列和用户数据预处理队列,在进行数据预处理之前进行失效数据检查,将会议开始时间晚于当前日期的会议状态设置为历史会议,不作为推荐备选会议,分别实现两种数据预处理方法如下:
对于用户数据的预处理,创建系统保存的物品-用户倒排表,并计算相关用户的喜好相似度,使用余弦相似度衡量用户间的喜好相似度,设n(u)为用户u感兴趣的会议集合,n(v)为用户v感兴趣的会议集合,则用户u和用户v的喜好相似度为
对于会议数据的预处理为对会议数据的文本数据进行分词和去停用词,使用结合tf-idf及在大型语料库上进行预训练的词向量来进行文本表示,文档向量表示为
为节省计算时间,将预处理后得到的中间数据持久化保存在本地文件系统;
所述核心推荐组件通过定时任务设置,在固定时间执行推荐任务,具体步骤如下:
a、根据用户喜好相似度矩阵,找出与用户u最相似的k个用户,用集合s(u,k)表示,将s中用户感兴趣的会议全部提取出来,并去除u已经感兴趣的会议;对于每个候选会议i,用户u对它感兴趣的程度用如下公式计算:
b、根据会议的文本表示向量及其相似度,找出步骤a中得到的候选会议集合j(u)中与用户u感兴趣的会议集合i(u)最相似的会议,对于每个候选会议i∈j(u),用户u对它感兴趣的程度用公式计算:
c、通过redis创建网盘归档队列,将得到的推荐结果以{用户:[会议1,会议2,会议3…]}的json格式添加到网盘归档队列。
进一步,所述网盘归档模块需要集成第三方网盘存储服务,使用dcampusweblib云盘系统作为网盘存储服务,所述网盘归档模块在轮询网盘归档队列过程中,检测到推荐结果时,对推荐结果中的用户依次查询关联网盘的用户名及密码,通过第三方云服务weblib所提供的http接口登录到对应账号,在指定目录下创建以当前日期为目录名的新目录,依次上传用户推荐列表中的会议邮件摘要或网页摘要至指定目录。
本发明与现有技术相比,具有如下优点与有益效果:
1、通过聚合用户的多个邮箱,多个公开学术会议网站的信息,能够保证信息来源丰富可靠。
2、通过有效信息提取,能够更加直观地展示出学术会议举办的关键信息。
3、通过混合推荐算法,能够筛选出基于用户的协同过滤方法结果中不符合用户喜好的伪推荐。
4、通过结合tf-idf及词向量的方法进行文本表示,能够在保留文本语义信息的条件下得到关键的特征信息。
5、通过基于web的展示方式和用户关联网盘的归档两种方法,能够保证用户方便地查看推荐结果,并实现资源的存储。
附图说明
图1为基于混合推荐算法的学术会议推荐系统架构图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
本实施例所提供的基于混合推荐算法的学术会议推荐系统,是主要使用python语言开发的在centos操作系统上运行的学术会议推荐系统,本系统所支持的邮件归档云盘为广州数园网络公司暨广东省计算机网络重点实验室所研发的dcampusweblib云盘系统,该网盘属于企业级云盘服务,针对不同的组织的知识管理需求,已经开发出标准版、科研机构版与医疗机构版等多个版本。支持文件管理,用户管理,全库搜索及文件柜管理等,且支持多终端访问。如图1所示,通过内部模块和第三方云服务weblib的http接口支持实现学术会议推荐系统,它包括有:
邮件信息处理模块,用于实现接收电子邮件数据,解码邮件数据形成邮件摘要,筛选学术会议通知类邮件并进行基于svm的学术会议领域分类,对经过筛选的邮件正文进行基于规则的有效信息提取,存储处理后的学术会议信息元数据及邮件摘要。
网页信息处理模块,用于实现根据系统配置指定目标网页,实时检查目标网页情况,采集目标网页更新的学术会议通知资源,记录无法连接或结构变更的失效网页,并用基于标签的方法提取网页中的有效信息,存储处理后的学术会议信息元数据及网页摘要。
学术会议推荐模块,用于实现对用户数据及上述邮件信息处理模块及网页信息处理模块存储的会议数据进行预处理,通过定时任务在指定时间通过融合基于用户的协同过滤和基于内容的混合推荐算法得到用户物品相关度,并根据相关度及用户配置生成推荐结果并缓存。
网盘归档模块,用于实现上述学术会议推荐模块所述推荐结果获取,根据推荐结果包含的用户依次检查关联网盘,将推荐给对应用户的学术会议通知邮件摘要或网页正文归档到用户的网盘。
会议信息展示及配置管理模块,用于实现用户管理个人信息、用户配置系统相关设置,展示相关学术会议摘要,反馈推荐结果,订阅会议网站。
所述邮件信息处理模块包括邮件采集组件和邮件处理组件;邮件采集组件实现邮件接收,邮件解析,邮件过滤,邮件缓存;邮件处理组件实现基于svm的学术会议通知邮件领域分类,基于规则的有效信息提取,学术会议信息元数据及邮件原件的存储。
邮件采集组件创建监听25端口的socket,实现一个信道接收smtp连接的命令并按协议规范进行处理,若rcptto命令所标识的收件人地址不在系统的用户名单中,拒绝传输,在符合条件的传输中,获取邮件具体内容,根据smtp及mime协议解码邮件报文数据,提取其邮件头和邮件体,获取邮件头中的收件人地址、发件人地址、主题数据,使用基于关键词规则的方法对邮件体即邮件正文进行过滤,筛选出学术会议通知类邮件。为防止阻塞邮件接受,对于通过筛选的邮件生成唯一的文件名,以[字段名:字段]的格式分别将邮件头数据和邮件正文写入文件形成邮件摘要,通过redis数据库创建邮件处理工作队列,将文件名添加到处理队列中通知后续邮件处理组件。
邮件处理组件通过轮询邮件处理工作队列获取到待处理的文件后,使用离线训练得到的svm模型对邮件正文进行领域多分类得到该学术会议通知邮件的会议领域,利用正则表达式的规则提取邮件正文中的有效信息包括会议名称、会议届数、会议开始时间、会议截止时间、会议截稿时间、会议投稿方式,加上会议领域、会议来源即邮件收件人地址、邮件摘要文件地址作为会议信息元数据存储在关系型数据库中,通过redis数据库创建会议数据预处理工作队列,将新增会议的会议id添加到数据预处理工作队列。
所述网页信息处理模块包括网页采集组件和网页处理组件;网页采集组件实现目标网页更新检查,目标网页信息采集,目标网页失效报警;网页处理组件实现基于标签的网页有效信息提取,学术会议信息元数据及网页摘要的存储。
网页采集组件定时于每日0点执行采集任务,通过读取配置文件,获取目标网站的简称、url和最近更新日期,目标网站为公开发布会议举办通知的网站,采集网页上相对于最近更新日期之后发布的会议举办通知的网页资源以html格式文件传输下来并修改配置文件最近更新日期,若采集失败,获取错误信息使用邮件通知管理员并更改配置文件对应目标网站状态为不可用。
网页处理组件通过观察各个目标网站的网页结构设计实现基于html标签的有效信息获取函数,根据目标网站的简称选择不同的信息提取函数处理上述网页资源,获取会议名称、会议届数、会议开始时间、会议截止时间、会议截稿时间、会议领域、会议投稿方式,会议举办通知正文,将网页来源网站简称、网页采集时间、会议举办通知正文保存为网页摘要文件,将上述其他会议有效信息及网页摘要文件地址存储在关系型数据库中,将新增会议的会议id添加到会议数据预处理工作队列。
所述学术会议推荐模块包括数据预处理组件和核心推荐组件;数据预处理组件实现用户数据预处理,会议信息预处理,中间数据存储,失效数据检查及清理;核心推荐组件实现相关度计算,用户配置读取,推荐结果生成,推荐结果缓存。
数据预处理组件通过轮询检查会议数据预处理队列和用户数据预处理队列,在进行数据预处理之前进行失效数据检查,将会议开始时间晚于当前日期的会议状态设置为历史会议,不作为推荐备选会议,分别实现两种数据预处理方法如下所示,为节省计算时间,将预处理后得到的中间数据持久化保存在本地文件系统。
对于用户数据的预处理,创建系统保存的物品-用户倒排表,并计算相关用户的喜好相似度,本系统使用余弦相似度衡量用户间的喜好相似度,设n(u)为用户u感兴趣的会议集合,n(v)为用户v感兴趣的会议集合,则用户u和用户v的喜好相似度为
对于会议数据的预处理为对会议数据的文本数据进行分词、去停用词,使用结合tf-idf及在大型语料库上进行预训练的词向量来进行文本表示,文档向量可表示为
核心推荐组件通过定时任务设置,在固定时间执行推荐任务,具体步骤如下:
a、根据用户喜好相似度矩阵,找出与用户u最相似的k个用户,用集合s(u,k)表示,将s中用户感兴趣的会议全部提取出来,并去除u已经感兴趣的会议。对于每个候选会议i,用户u对它感兴趣的程度用如下公式计算:
b、根据会议的文本表示向量及其相似度,找出步骤i中得到的候选会议集合j(u)中与用户u感兴趣的会议集合i(u)最相似的会议,对于每个候选会议i∈j(u),用户u对它感兴趣的程度用如下公式计算:
c、通过redis创建网盘归档队列,将得到的推荐结果以{用户:[会议1,会议2,会议3…]}的json格式添加到网盘归档队列。
所述网盘归档模块需要集成第三方网盘存储服务,本系统使用dcampusweblib作为网盘存储服务,该网盘系统由广州数园网络公司暨广东省计算机网络重点实验室所研发。网盘归档模块在轮询网盘归档队列过程中,检测到推荐结果时,对推荐结果中的用户依次查询关联网盘的用户名及密码,通过weblib所提供的http接口登录到对应账号,在指定目录下创建以当前日期为目录名的新目录,依次上传用户推荐列表中的会议邮件摘要或网页摘要至指定目录。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!