基于改进的Adaboost算法的人脸检测方法与流程
本发明涉及人脸检测技术领域,尤其涉及一种基于改进的adaboost算法的人脸检测方法。
背景技术:
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。随着社会的信息化与智能化发展,人脸检测技术在商业、文化等各领域扮演着日益重要的角色,社会对人脸检测系统的性能要求也越来越高。开源计算机视觉库opencv中实现了众多图像处理算法,其中包括使用adaboost算法训练出haar分类器,用以进行高准确率人脸检测。常用的基于haar-like特征的adaboost人脸检测算法还存在着不足之处,例如漏检率和误检率较高,检测效率较低等。因此,解决adaboost人脸检测算法存在的不足就显得尤为重要了。
技术实现要素:
为解决上述问题,本发明的目的提供一种基于改进的adaboost算法的人脸检测方法,通过对adaboost算法进行改进,提高adaboost算法的检测效率,降低漏检率和误检率,解决了adaboost人脸检测算法存在不足的问题。
本发明提供一种基于改进的adaboost算法的人脸检测方法,所述检测方法步骤如下:
步骤一:采用深度感应传感器进行人脸图像的采集;
步骤二:对采集到的图像进行去噪处理,具体去噪处理方法为:设f1,f2,.......,fn为像素点f0附近的n个邻域点,则f0的表达式为:f0=mediun(f1,f2,......fn);
步骤三:通过深度感应传感器采集人脸区域的深度信息和彩色信息,并通过人脸区域深度信息计算获得人脸半径r,r的计算公式为:r=a*dep2+b*dep+c,其中dep为人脸区域平均深度,a、b、c为根据最小二乘法设定的常量;
步骤四:将采集到的原始图像进行rgb色彩空间和ycrcb色彩空间的转换,变换公式为:
式中,r,g,b为原始图像的红色、绿色和蓝色的色彩分量值,y表示ycrcb空间中的亮度,cr表示为红色色度,cb表示为蓝色色度;
步骤五:再利用先验统计的判别式进行区域筛选:77≤cb≤127,133≤cr≤173;
步骤六:执行多匹配算法,对人脸进行识别。
进一步改进在于:所述人脸区域平均深度dep通过下式得到:
进一步改进在于:所述步骤五中,在人脸图像中,眼睛、鼻子和嘴巴等器官区域的灰度值较高,其余区域灰度值较低,根据人脸图像中眼睛和鼻子的位置特征,引入了两种扩展的haar-like特征,由人脸检测的先验知识可知,人脸中眼睛、鼻子和嘴巴等器官的位置是相对固定的;在训练过程中,每个简单的特征对应一个弱分类器,弱分类器的判定公式为:
其中,x为待检测窗口,fj为窗口区域的特征值,θj为此弱分类器的阈值,pj用来控制不等式方向,hj是判定结果,1表示判定为人脸,0则判定为非人脸。
进一步改进在于:所述步骤六中多匹配算法具体步骤如下:
a:以92*92尺度建立一维坐标系,采用二分法得到左右端点和中心节点,左端点代表46*46尺度,右端点代表23*23尺度,中心节点设为坐标原点,左右端点横坐标分别为-1和1;
b:人脸匹配模块接收到人脸图像,计算其边长,以坐标轴左端点为轴心,人脸图像边长为半径画圆交坐标轴于a点,设a点的横坐标为a;
c:分别将左右端点的横坐标-1和1与a相乘,结果为负端点被舍弃,结果为正的端点即为代表相近尺度的端点;
d:若代表相近尺度的端点为右端点,则算法结束,若代表相近尺度的端点为左端点,则进入步骤e;
e:以左端点和a点作为左右端点,重新建立坐标系,左端点代表23*23尺度,右端点代表46*46尺度,采用二分法得到中心节点,设中心节点为坐标原点,左右端点横坐标分别为-1和1,之后重复步骤c,得到最相近的尺度;
f:将人脸图像与最相近的尺度的人脸库进行匹配,采用被广泛使用的lda算法进行人脸匹配,该算法先将样本集和测试集线性变换到一个新的空间,再计算样本集和测试集的特征向量,计算测试图片和训练集特征向量之间的欧式距离,距离最小的样本的身份即为匹配结果。
进一步改进在于:所述每个训练样本都有自己的权重,而此权重会根据上一轮判定的准确率和每轮样本分类是否正确而发生改变,分类错误的样本会在下一层分类器中加大训练权重,反之减小权重,如此反复迭代训练,得到若干个弱分类器,再将这些弱分类器按权重叠加成最终的强分类器,多个强分类器通过级联组成级联分类器,获取图像中到的所有子窗口,将数据发送到级联分类器来进行检测,如果级联分类器的某一级未能识别该子窗口为人脸,则去除子窗口;如果子窗口成功通过级联分类器的每一级,则将其区分为人脸。
本发明的有益效果:通过对adaboost算法进行改进,提高adaboost算法的检测效率,降低漏检率和误检率,并且通过弱分类器叠加形成强分类器,提升检测精度,解决了adaboost人脸检测算法存在不足的问题。
附图说明
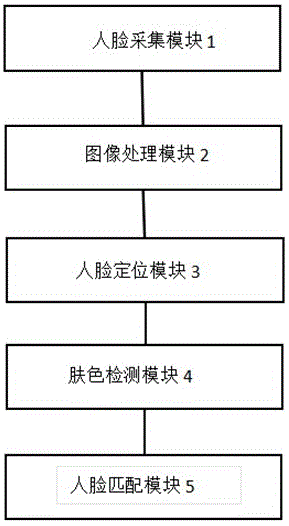
图1是本发明的方法流程图。
图2是本发明的扩展的haar-like特征中的人脸正面的主要器官双眼、鼻子和嘴巴的示意图。
图3是本发明的扩展的haar-like特征中的针对稍微倾斜的人脸而设计的示意图。
具体实施方式
为了加深对本发明的理解,下面将结合实施例对本发明作进一步详述,该实施例仅用于解释本发明,并不构成对本发明保护范围的限定。如图1所示,本实施例提供一种基于改进的adaboost算法的人脸检测方法,所述检测方法步骤如下:
步骤一:采用深度感应传感器进行人脸图像的采集;
步骤二:对采集到的图像进行去噪处理,具体去噪处理方法为:设f1,f2,.......,fn为像素点f0附近的n个邻域点,则f0的表达式为:f0=mediun(f1,f2,......fn);
步骤三:通过深度感应传感器采集人脸区域的深度信息和彩色信息,并通过人脸区域深度信息计算获得人脸半径r,r的计算公式为:r=a*dep2+b*dep+c,其中dep为人脸区域平均深度,a、b、c为根据最小二乘法设定的常量;
步骤四:将采集到的原始图像进行rgb色彩空间和ycrcb色彩空间的转换,变换公式为:
式中,r,g,b为原始图像的红色、绿色和蓝色的色彩分量值,y表示ycrcb空间中的亮度,cr表示为红色色度,cb表示为蓝色色度;
步骤五:再利用先验统计的判别式进行区域筛选:77≤cb≤127,133≤cr≤173;
步骤六:执行多匹配算法,对人脸进行识别。
进一步改进在于:所述人脸区域平均深度dep通过下式得到:
进一步改进在于:所述步骤五中,在人脸图像中,眼睛、鼻子和嘴巴等器官区域的灰度值较高,其余区域灰度值较低,根据人脸图像中眼睛和鼻子的位置特征,引入了两种扩展的haar-like特征,由人脸检测的先验知识可知,人脸中眼睛、鼻子和嘴巴等器官的位置是相对固定的;在训练过程中,每个简单的特征对应一个弱分类器,弱分类器的判定公式为:
其中,x为待检测窗口,fj为窗口区域的特征值,θj为此弱分类器的阈值,pj用来控制不等式方向,hj是判定结果,1表示判定为人脸,0则判定为非人脸。
进一步改进在于:所述步骤六中多匹配算法具体步骤如下:
a:以92*92尺度建立一维坐标系,采用二分法得到左右端点和中心节点,左端点代表46*46尺度,右端点代表23*23尺度,中心节点设为坐标原点,左右端点横坐标分别为-1和1;
b:人脸匹配模块接收到人脸图像,计算其边长,以坐标轴左端点为轴心,人脸图像边长为半径画圆交坐标轴于a点,设a点的横坐标为a;
c:分别将左右端点的横坐标-1和1与a相乘,结果为负端点被舍弃,结果为正的端点即为代表相近尺度的端点;
d:若代表相近尺度的端点为右端点,则算法结束,若代表相近尺度的端点为左端点,则进入步骤e;
e:以左端点和a点作为左右端点,重新建立坐标系,左端点代表23*23尺度,右端点代表46*46尺度,采用二分法得到中心节点,设中心节点为坐标原点,左右端点横坐标分别为-1和1,之后重复步骤c,得到最相近的尺度;
f:将人脸图像与最相近的尺度的人脸库进行匹配,采用被广泛使用的lda算法进行人脸匹配,该算法先将样本集和测试集线性变换到一个新的空间,再计算样本集和测试集的特征向量,计算测试图片和训练集特征向量之间的欧式距离,距离最小的样本的身份即为匹配结果。
进一步改进在于:所述每个训练样本都有自己的权重,而此权重会根据上一轮判定的准确率和每轮样本分类是否正确而发生改变,分类错误的样本会在下一层分类器中加大训练权重,反之减小权重,如此反复迭代训练,得到若干个弱分类器,再将这些弱分类器按权重叠加成最终的强分类器,多个强分类器通过级联组成级联分类器,获取图像中到的所有子窗口,将数据发送到级联分类器来进行检测,如果级联分类器的某一级未能识别该子窗口为人脸,则去除子窗口;如果子窗口成功通过级联分类器的每一级,则将其区分为人脸。
- 还没有人留言评论。精彩留言会获得点赞!