一种基于半监督K-Means聚类算法的Android恶意软件检测方法与流程
本发明涉及恶意软件检测及网络安全技术领域,尤其涉及一种基于半监督k-means聚类算法的android恶意软件检测方法。
背景技术:
由于系统开源性、免费性的特点,android系统作为主流的移动操作系统成为了恶意软件攻击的主要目标。从2017年新增恶意软件分布来看资费消耗类型的恶意样本占比已达到3/4,说明恶意软件依然是以推销广告、消耗流量、增加手机用户的流量资费等来谋取经济利益,用户的安全得不到保障,所以研究android恶意软件检测方法仍然是很有必要的。
android恶意代码分析研究目前主要有两种方法,即静态分析和动态检测。静态分析是指通过分析程序代码来判断程序行为;动态分析是指在严格控制的环境下执行应用程序,尽可能的触发软件的全部行为并记录,以检测应用程序是否包含恶意行为。目前,关于android恶意应用程序的检测方法较多,但总体而言,其大致是围绕权限机制和api的调用这两大方面来进行展开的;权限控制着应用软件对资源的访问,但程序员在app的开发过程中存在过度申请权限的行为,这加大了恶意软件检测的难度。应用程序可以通过对api的调用在一定程度上反映出一款应用程序真实的行为特点,因此可以运用于android恶意软件检测。
在静态分析中主要运用机器学习的方法来进行数据挖掘,主要分为两类,有监督学习和无监督学习,有监督学习主要分为分类模型和预测模型,无监督学习主要分为关联分析和聚类分析。分类算法主要有k近邻算法,朴素贝叶斯、决策树归纳、随机森林、支持向量机svm、遗传算法等,这些分类算法在android恶意软件检测中频繁运用。现在研究中的android恶意软件检测方法大多是有监督学习的算法,但是有监督学习的算法需要大量的恶意android软件作为训练样本,由于恶意软件更新换代很快,收集足够多的最新型恶意软件的代价是昂贵的。无监督学习的算法因为具有太多不确定性,所有很少用于检测android恶意软件。用k-means聚类算法检测android恶意软件易受初始聚类中心影响,当初始聚类中心选取合适时,准确率高,初始聚类中心选取不合适时,准确率低。2018年《android恶意软件检测方法研究综述》表明,android恶意软件检测经过多年努力,已经取得了一定的成果,研究结果都表示机器学习算法在android恶意软件检测的研究中起着积极的作用,但随着新型恶意软件的增多,恶意软件样本库需要不断更新,能够检测出现有恶意软件的同时还能够应对不断出现的新型恶意软件的成果还未曾出现。
技术实现要素:
本发明的目的在于提供一种基于半监督k-means聚类算法的android恶意软件检测方法,以解决k-means聚类算法检测android恶意软件易受初始聚类中心影响的问题。运用半监督k-means聚类算法进行android恶意软件检测,首先通过约束种子即有标签的样本集合确定初始聚类中心,然后运用kmeans聚类算法根据欧式距离对无标签的样本集合进行聚类,直到每个类别中的样本不再发生变化,使用大量的无标签样本,同时使用尽量少的有标签样本,来进行分类,对恶意软件检测具有较高的准确性。
为实现上述技术目的,本发明提供的一种技术方案是,一种基于半监督k-means聚类算法的android恶意软件检测方法,所述方法包括:
步骤s1、解析android应用软件包:选择适量有标签的样本和两倍数量的无标签的样本,使用解压缩工具打开这些样本的android应用软件包,得到classes.dex文件androidmanifest.xml文件,解析androidmanifest.xml文件提取每个样本的权限的特征集合p1,反编译classes.dex文件提取调用的api,构建每个样本api对应的权限的特征集合p2,通过每个样本的权限集合p1和p2得到该样本的非过度申请的权限集合p3;
步骤s2、构建特征矩阵:通过信息增益算法得到不同权限的属性评分结果,统计每个样本的权限集合p1、p2、p3的评分结果为s1、s2、s3,选择适量有标签的样本构建成特征矩阵fn,选择两倍数量的无标签的样本构建成特征矩阵fm;
步骤s3、恶意软件检测:运用半监督k-means算法对特征矩阵fn和特征矩阵fm中的样本进行恶意软件的检测。
所述步骤s1中获取每个样本的权限特征集合的过程包括:
步骤s11、反编译classes.dex文件获取源代码,遍历所有源代码得到api集合,api集合对照公开的权限-函数映射关系表获得其对应的权限集合p2;
步骤s12、根据androidmainfest.xml文件解析得到的权限集合p1和权限集合p2得到非过度申请的权限集合p3,其中p3=p1∩p2;
所述步骤s2中构建特征矩阵的过程包括:
步骤s21、通过信息增益算法处理多个非恶意软件和恶意软件得到不同权限的属性评分结果;定义权限变量y为恶意软件中的权限,一共有n种权限,在恶意软件中每一种权限存在的概率为p(yi),在非恶意软件中每一种权限存在的概率为q(yi),计算y的信息量为:
步骤s22、根据步骤s21中得到的不同权限的属性评分结果,运用公式s=∑ig(y)(y∈p),计算每个样本的权限集合p1、p2以及p3的属性评分结果分别为s1、s2、s3;
步骤s23、选取m个有标签样本,构建有标签样本的特征向量v1,v1=(s1,s2,s3,type),type=0代表该样本为恶意软件,type=1代表该样本为非恶意软件,将有标签的样本集合集制成一个m×4特征矩阵fn;所述fn的表达式如下:
步骤s24、选n个无标签样本,构建无标签样本的特征向量v2,v2=(s1,s2,s3),将无签的样本集合集制成一个n×3特征矩阵fm;所述fm表达式如下:
所述步骤s3中运用半监督k-means算法进行非恶意软件和恶意软件的检测过程包括:步骤s31、根据特征矩阵fn将m个有标签样本表示成三维空间中的点{x(1),…,x(m)},其中x(i)=(ai1,ai2,ai3),样本x(i)的类别表示成c(i)=ai4,所有恶意样本构成恶意样本簇,所有非恶意样本构成非恶意样本簇,通过计算质心的方式分别得出恶意样本簇和非恶意样本簇的一个估计值,并将其作为初始聚类中心;
其中计算类别j初始聚类中心μ_j的公式是:
步骤s32、根据特征矩阵fm将n个无标签样本表示成三维空间中的点{x(m+1),...,x(m+n)},其中x(i)=(ai1,ai2,ai3),样本x(i)的类别表示成c(i)=-1,定义索引index(i)=-1,定义标志位flag=true;
步骤s33、聚类过程:初始flag=false,对于每一个样本x(i)计算其索引
index(i)=argminj||x(i)-μj||2,如果index(i)=c(i),改变标志位flag=true,重置样本x(i)的类别c(i)=index(i);
步骤s34、如果一次聚类结束后,标志位flag=true,对于恶意样本簇和非恶意样本簇,重新计算它们的聚类中心,重复聚类过程;
其中计算类别j聚类中心μj的公式是:
步骤s34、如果一次聚类结束后,flag=false,代表聚类结果不再发生变化,{c(1),...,c(m)}为特征矩阵fn的样本的最终的聚类结果,可用于计算该算法检测的准确率,{c(m+1),...,c(m+n)}为特征矩阵fm的样本的最终的聚类结果,c(i)=0代表待检测的无标签样本x(i)所代表的android应用软件包的检测结果为恶意软件;c(i)=1代表待检测的无标签样本x(i)所代表的android应用软件包的检测结果为非恶意软件。
本发明的有益效果:本发明技术方案运用半监督k-means聚类算法进行android恶意软件检测,首先通过约束种子即有标签的样本集合确定初始聚类中心,然后运用kmeans聚类算法根据欧式距离对无标签的样本集合进行聚类,直到每个类别中的样本不再发生变化,使用大量的无标签样本,同时使用尽量少的有标签样本,来进行分类,对恶意软件检测具有较高的准确性。
附图说明
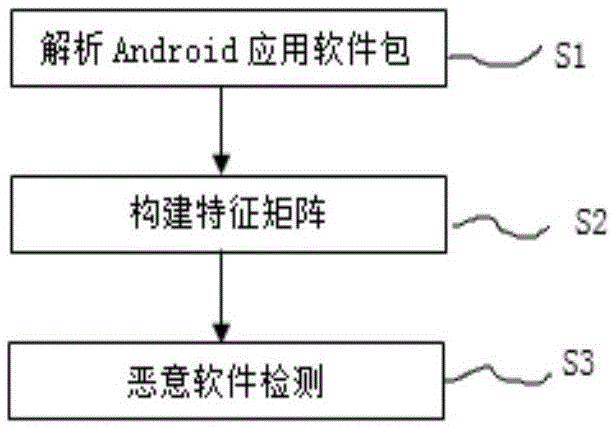
图1为本发明的一种基于半监督k-means聚类算法的android恶意软件检测方法的方法流程图。
图2本发明的一种基于半监督k-means聚类算法的android恶意软件检测方法的聚类算法流程图。
具体实施方式
为使本发明的目的、技术方案以及优点更加清楚明白,下面结合附图和实施例对本发明作进一步详细说明,应当理解的是,此处所描述的具体实施方式仅是本发明的一种最佳实施例,仅用以解释本发明,并不限定本发明的保护范围,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:如图1所示,一种基于半监督k-means聚类算法的android恶意软件检测方法,所述方法包括:
步骤s1、解析android应用软件包:选择适量有标签的样本和两倍数量的无标签的样本,使用解压缩工具打开这些样本的android应用软件包,得到classes.dex文件androidmanifest.xml文件,解析androidmanifest.xml文件提取每个样本的权限的特征集合p1,反编译classes.dex文件提取调用的api,构建每个样本api对应的权限的特征集合p2,通过每个样本的权限集合p1和p2得到该样本的非过度申请的权限集合p3。
步骤s2、构建特征矩阵:通过信息增益算法得到不同权限的属性评分结果,统计每个样本的权限集合p1、p2、p3的评分结果为s1、s2、s3,选择适量有标签的样本构建成特征矩阵fn,选择两倍数量的无标签的样本构建成特征矩阵fm;
步骤s3、恶意软件检测:运用半监督k-means算法对特征矩阵fn和特征矩阵fm中的样本进行恶意软件的检测。
所述步骤s1中获取每个样本的权限特征集合的过程包括:
步骤s11、反编译classes.dex文件获取源代码,遍历所有源代码得到api集合,api集合对照公开的权限-函数映射关系表获得其对应的权限集合p2;
步骤s12、根据androidmainfest.xml文件解析得到的权限集合p1和权限集合p2得到非过度申请的权限集合p3,其中p3=p1∩p2;
本实施例中,设有标签样本1如下:
p1={access_network_state,add_system_service,read_contacts,read_sms,send_sms,write_sms,receive_sms,internet,write_apn_settings,add_system_service,change_network_state,call_phone,modify_phone_state,read_phone_state,com.android.launcher.permission.install_shortcut,com.android.launcher.permission.uninstall_shortcut,modify_audio_settings,process_outgoing_calls,change_wifi_state,access_wifi_state,get_tasks,receive_boot_completed,wake_lock,com.android.browser.permission.read_history_bookmarks,com.android.browser.permission.write_history_bookmarks};
反编译classes.dex文件获取源代码,遍历所有源代码得到api集合,api集合对照公开的权限-函数映射关系表获得其对应的权限集合p2;
p2={change_network_state,connectivity_internal,interact_across_users,backup,interact_across_users_full,dump,internet,bluetooth_admin,write_sms};
根据androidmainfest.xml文件解析得到的权限集合p1和权限集合p2得到非过度申请的权限集合p3,其中p3=p1∩p2;
则p3={change_network_state,internet,write_sms}。
如图2所示,所述步骤s2中构建特征矩阵的过程包括:
步骤s21、通过信息增益算法处理多个非恶意软件和恶意软件得到不同权限的属性评分结果;定义权限变量y为恶意软件中的权限,一共有n种权限,在恶意软件中每一种权限存在的概率为p(yi),在非恶意软件中每一种权限存在的概率为q(yi),计算y的信息量为:
步骤s22、根据步骤s21中得到的不同权限的属性评分结果,运用公式s=∑ig(y)(y∈p),计算每个样本的权限集合p1、p2以及p3的属性评分结果分别为s1、s2、s3;
步骤s23、选取m个有标签样本,构建有标签样本的特征向量v1,v1=(s1,s2,s3,type),type=0代表该样本为恶意软件,type=1代表该样本为非恶意软件,将有标签的样本集合集制成一个m×4特征矩阵fn;所述fn的表达式如下:
步骤s24、选n个无标签样本,构建无标签样本的特征向量v2,v2=(s1,s2,s3),将无签的样本集合集制成一个n×3特征矩阵fm;所述fm表达式如下:
本实施例中,标签样本1的p1属性评分结果s1为1.19279,p2属性评分结果s2为0.179746,p3属性评分结果s3为0.179746;选择4个有标签样本构成特征矩阵fn;
选择8个无标签样本构成特征矩阵fm;
所述步骤s3中运用半监督k-means算法进行非恶意软件和恶意软件的检测过程包括:
步骤s31、根据特征矩阵fn将m个有标签样本表示成三维空间中的点{x(1),...,x(m)},其中x(i)=(ai1,ai2,ai3),样本x(i)的类别表示成c(i)=ai4,所有恶意样本构成恶意样本簇,所有非恶意样本构成非恶意样本簇,通过计算质心的方式分别得出恶意样本簇和非恶意样本簇的一个估计值,并将其作为初始聚类中心;
其中计算类别j初始聚类中心μ_j的公式是:
步骤s32、根据特征矩阵fm将n个无标签样本表示成三维空间中的点{x(m+1),...,x(m+n)},其中x(i)=(ai1,ai2,ai3),样本x(i)的类别表示成c(i)=-1,定义索引index(i)=-1,定义标志位flag=true;
步骤s33、聚类过程:初始flag=false,对于每一个样本x(i)计算其索引index(i)=argminj||x(i)-μj||2,如果index(i)=c(i),改变标志位flag=true,重置样本x(i)的类别c(i)=index(i);
步骤s34、如果一次聚类结束后,标志位flag=true,对于恶意样本簇和非恶意样本簇,重新计算它们的聚类中心,重复聚类过程;
其中计算类别j聚类中心μj的公式是:
步骤s34、如果一次聚类结束后,flag=false,代表聚类结果不再发生变化,{c(1),...,c(m)}为特征矩阵fn的样本的最终的聚类结果,可用于计算该算法检测的准确率,{c(m+1),...,c(m+n)}为特征矩阵fm的样本的最终的聚类结果,c(i)=0代表待检测的无标签样本x(i)所代表的android应用软件包的检测结果为恶意软件;c(i)=1代表待检测的无标签样本x(i)所代表的android应用软件包的检测结果为非恶意软件。
本实施例中,
μ0=(0.963775,0.095647,0.0933045);
μ1=(0.9312885,0.193458,0.02292);
{c(1),...,c12}={0,0,1,1,1,1,0,0,1,1,0,1};
s{c(1),...,c(4)}={0,0,1,1};
{c(5),...,c(12)}={1,1,0,0,1,1,0,1};
其中通过特征矩阵fn的样本初始类别和最终的聚类结果计算该算法检测的准确率的公式是:acc=类别不变的样本个数/样本总个数;
即acc=4/4=100%。
以上所述之具体实施方式为本发明一种基于半监督k-means聚类算法的android恶意软件检测方法的较佳实施方式,并非以此限定本发明的具体实施范围,本发明的范围包括并不限于本具体实施方式,凡依照本发明之形状、结构所作的等效变化均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!