一种面向栅格数据的区域与流域数据程序化提取方法与流程
本发明涉及气象数据的提取领域,更具体地,涉及一种面向栅格数据的区域与流域数据程序化提取方法。
背景技术:
netcdf类型文件能够灵活的传输、处理面向阵列的海量数据,目前广泛应用于大气科学、水文、海洋学、环境模拟、地球物理等诸多领域。相关技术中,当长时间序列的栅格数据量较大时,通常采用空间分析软件批处理起来很不方便,且操作繁琐,其制图过程也必须跨平台操作,具体包括:
1.常用的空间分析软件批量提取多个文件的栅格像元值,但对于单个文件的大量长序列数据仅能读取和提取一个单元格的首个像元值,直接限制了数据的一次性提取。
2.常用的数据软件提取栅格像元值的操作繁琐,灵活性差,不能实现观测与预测图形数据的空间叠加分析、自动化读写功能。
因此,构建高效的数据提取方法,不仅是分析气象数据,探究气象水文规律的前提,也是适应科学研究中大数据分析趋势的重要基础。
技术实现要素:
本发明为克服上述现有技术中长时间序列的栅格数据量较大时,批处理不方便,操作繁琐的缺陷,提供一种面向栅格数据的区域与流域数据程序化提取方法。
本发明旨在至少在一定程度上解决上述技术问题。
本发明的首要目的是为解决上述技术问题,本发明的技术方案如下:
一种面向栅格数据的区域与流域数据程序化提取方法,所述方法包括:
s1:将栅格netcdf文件和矢量shape文件作为输入数据,利用开源栅格空间数据转换库netcdf4的dataset函数读取栅格netcdf文件中的气象栅格数据,利用矢量空间数据库shapefile的reader函数读取矢量shape文件中的区域矢量边界数据;
s2:以shp文件矢量边界数据中的矩形边界为计算区域,以计算区域内包含的所有坐标点为中心,利用shapely数据库的buffer函数依次建立若干与气象栅格数据中原始栅格像元大小一致的缓冲区;
s3:利用shapely数据库中的points、polygon函数,遍历shp文件中所有不规则图斑边界的points,并将points点绘制成新图形;所述points为不规则图斑边界顶点。
s4:采用shapely数据库中的intersection函数,依次将步骤s2中建立的原始栅格像元点的缓冲区与步骤s3中建立的新图形进行重叠计算,利用pyproj.proj函数计算出重叠栅格的面积属性,将重叠栅格面积比重与栅格像元值相乘计算出单个重叠栅格内的温度加权值,将温度加权值进行累计求平均得到计算区域加权平均温度值,具体公式如下:
其中,i,j分别代表具有重合范围的栅格经度和纬度范围,temij、aij指代重合栅格ij的温度和面积;cij代表重叠栅格个数;temave为计算区域加权平均温度;
s5:利用datetime函数将float浮点型的日期改成str字符型日期显示,以便于输出区域加权温度值的日期标识;
s6:采用pandas数据库中的dataframe函数将计算区域加权平均温度值、重叠栅格面积值、重叠栅格像元的原始值进行存储到字典中,然后输出并保存重叠栅格面积图、重叠栅格像元图、平均温度历年变化图和原始栅格对应像元温度表格;
s7:将步骤s1-s6封装成独立函数模块class,以点序列文件或shp边界文件为输入,得到定量温度或其他气象指标元组作为输出,实现对netcdf长序列数据的程序化提取。
进一步地,步骤s2中建立的缓冲区的个数与计算区域内包含的坐标点个数一致。
进一步地,步骤s2中建立缓冲区后将进行缓冲区的重叠分析。
进一步地,步骤s4中重叠计算得到的重叠栅格的面积若属于同一栅格时,则相加处理后输出,否则直接输出该栅格的重叠面积,且只输出面积大于零的栅格数据。
进一步地,步骤s4得到的计算区域加权平均温度值包括:计算区域年度加权平均温度值、计算区域月加权平均温度值、计算区域日加权平均温度值。
进一步地,所述区域年度加权平均温度值、区域月加权平均温度值由pandas数据库中的describe函数直接统计得到。
与现有技术相比,本发明技术方案的有益效果是:本发明通过结构化脚本编程能够自动化提取特征;数据提取流程简单,效率高。
附图说明
图1为本发明具体操作流程示意图。
图2为全球网格示意图。
图3为gd省提取数据的网格图。
图4为gz省提取数据的网格图。
图5为gd省shp行政边界与netcdf栅格像元叠加图。
图6为gz省shp行政边界与netcdf栅格像元叠加图。
图7为gd省、gz省逐月温度数据。
图8为gd省、gz省1982~2015年月平均温度比较。
具体实施方式
下面结合附图和实施例对本发明的技术方案做进一步的说明。
一种面向栅格数据的区域与流域数据程序化提取方法,所述方法包括:
s1:将栅格netcdf文件和矢量shape文件作为输入数据,利用开源栅格空间数据转换库netcdf4的dataset函数读取栅格netcdf文件中的气象栅格数据,利用矢量空间数据库shapefile的reader函数读取矢量shape文件中的区域矢量边界数据;
s2:以shp文件矢量边界数据中的矩形边界为计算区域,以计算区域内包含的所有坐标点为中心,利用shapely数据库的buffer函数依次建立若干与气象栅格数据中原始栅格像元大小一致的缓冲区;
s3:利用shapely数据库中的points、polygon函数,遍历shp文件中所有不规则图斑边界的points,并将points点绘制成新图形;
s4:采用shapely数据库中的intersection函数,依次将步骤s2中建立的原始栅格像元点的缓冲区与步骤s3中建立的新图形进行重叠计算,利用pyproj.proj函数计算出重叠栅格的面积属性,将重叠栅格面积比重与栅格像元值相乘计算出单个重叠栅格内的温度加权值,将温度加权值进行累计求平均得到计算区域加权平均温度值,具体公式如下:
其中,i,j分别代表具有重合范围的栅格经度和纬度范围,temij、aij指代重合栅格ij的温度和面积;cij代表重叠栅格个数;temave为计算区域加权平均温度;
s5:利用datetime函数将float浮点型的日期改成str字符型日期显示,以便于输出区域加权温度值的日期标识;s6:采用pandas数据库中的dataframe函数将计算区域加权平均温度值、重叠栅格面积值、重叠栅格像元的原始值进行存储到字典中,然后输出并保存重叠栅格面积图、重叠栅格像元图、平均温度历年变化图和原始栅格对应像元温度表格;
s7:将步骤s1-s6封装成独立函数模块class,以点序列文件或shp边界文件为输入,得到定量温度或其他气象指标元组作为输出,实现对netcdf长序列数据的程序化提取。
进一步地,步骤s2中建立的缓冲区的个数与计算区域内包含的坐标点个数一致。
进一步地,步骤s2中建立缓冲区后将进行缓冲区的重叠分析。
进一步地,步骤s4中重叠计算得到的重叠栅格的面积若属于同一栅格时,则相加处理后输出,否则直接输出该栅格的重叠面积,且只输出面积大于零的栅格数据。
进一步地,步骤s4得到的计算区域加权平均温度值包括:计算区域年度加权平均温度值、计算区域月加权平均温度值、计算区域日加权平均温度值。
进一步地,所述区域年度加权平均温度值、区域月加权平均温度值由pandas数据库中的describe函数直接统计得到。
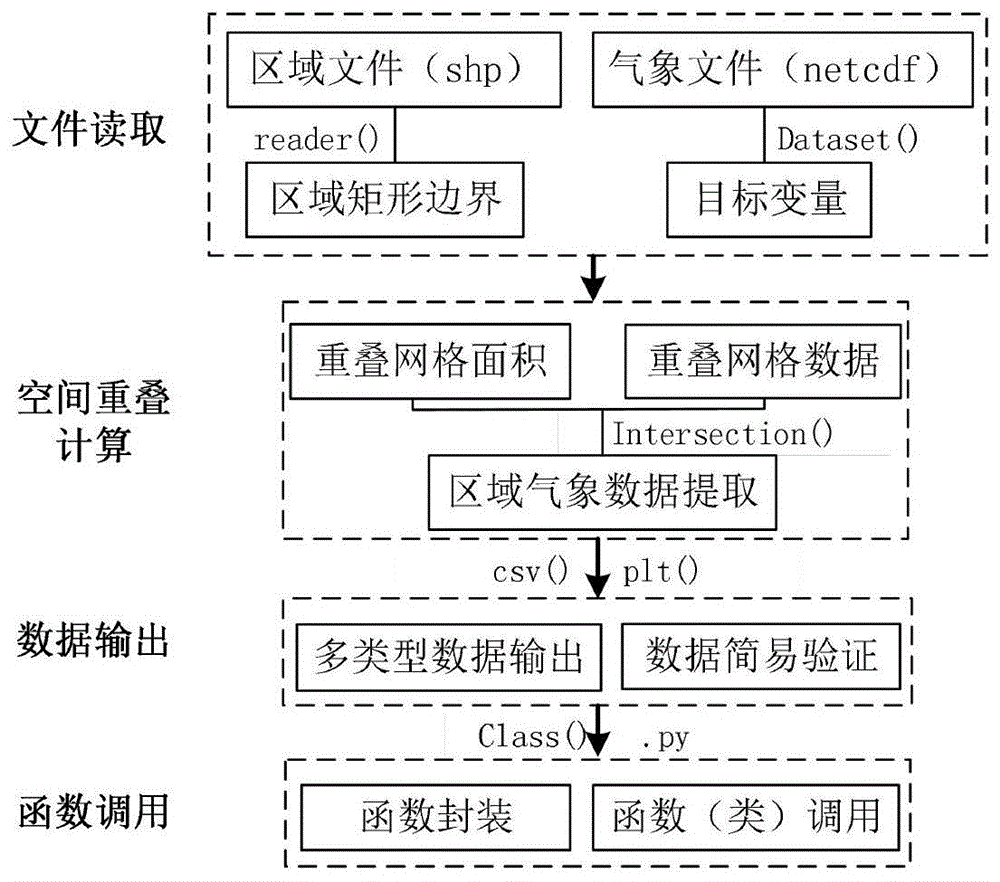
将步骤s1-s6封装成独立函数模块class,所述的独立函数模块的执行流程如图1所示,具体包括有:文件读取、空间重叠计算、数据输出、函数调用。
(1)文件读取:其步骤包括采用reader()函数和dataset()分别读取目标区域文件和需要提取的数据文件,以shp文件为目标区域的矩形边界文件,netcdf文件为包含目标变量的气象文件。
(2)空间重叠计算:其步骤包括采用intersection函数实现重叠网格面积和重叠网格数据的计算与提取,对重叠网格的面积和数据依次相乘、求和,得到该网格温度的月份值,进一步对区域温度的月份平均值。
(3)数据输出:其步骤包括采用dataframe()函数输出区域温度的时序值、单个像元格原始数据、重叠面积,并分别保存为csv文件。进一步采用plt()函数输出目标区域与栅格像元的叠加图,直观比较csv文件输出网格的大致面积和个数与叠加图中的是否一致。
(4)函数调用:其步骤包括将数据提取语句封装成独立的函数模块,并在其他程序中直接调用。
实施例1
本实施例以gd省和gz省1982年-2015年的数据为基础,详细阐述本发明的实施的具体步骤:
1、以全球1982~2015年1×1°分辨率的标准netcdf文件格式的温度月平均值数据作为数据源,其地理覆盖范围如图2所示,利用gd省、gz省行政边界(含海岛)的shp文件提取省域内温度的月、年际数据。
(1)采用shapefile的reader函数,读取gd省、gz省边界经度、纬度的最大值、最小值,因range函数只针对整形参数以及“五舍六入”的原则,利用range函数将四至点确定为栅格数据分析的矩形边界,进一步筛选出与gd省、gz省存在面积重叠的网格,重叠网格如图3-4所示。
(2)采用netcdf4的dataset函数读取数据文件的纬度、属性值,得到文件变量包括经度、纬度、时间、温度值(目标变量),其变量名称为'x'、'y'、't'、'sst'。
2、重叠计算共有3个for循环,分别对netcdf数据文件网格经度、纬度和shp文件的图斑进行循环,前两次循环用于遍历矩形边界内的网格单元中心坐标的缓冲区,后一次循环用于遍历两个省行政辖区图斑,包括大陆和海岛。
(1)采用shapely的intersection函数对缓冲区和行政区图斑分别做面积重叠计算,并输出投影后的面积值(单位:m2),投影坐标系统为albersequal-areaconic。
(2)按照网格经纬度标识输出重叠面积大于零的原始温度值(℃)、将原始温度值与网格重叠面积相乘,得到单个网格内的温度值,并输出到各个字典中。
3、将得到的重叠网格的面积值、原始温度值、加权温度值输出为csv格式的文件,便于跨平台读取与操作。
其中,i,j分别代表具有重合范围的栅格经度和纬度范围,temij、aij指代重合栅格ij的温度和面积;cij代表重叠栅格个数;temave为计算区域加权平均温度;
式中:i,j分别代表gd省重合范围的网格经度和纬度范围,temij为原始网格温度值,cij代表省域范围内重叠栅格个数,aij、a分别为单个网格的重叠面积和总面积(因经纬度不同而不同)。
(1)将float型的time通过datetime.date()函数转化成string型显示。由于float值代表的是1960年开始距离记录时间间隔的月份数(如264.5代表1960年1月1日延后260.5个月后的日期,即1982年1月16日),故将其转换成字符型的月份时间,日期一律采用半个间隔周期的第一天,即16日。
(2)采用plt.figure函数绘制出gd省行政边界与经纬度网格的重叠图,从图中直观的验证不同网格的重叠面积以及重叠网格的数量与位置,各网格与shp文件的实际重叠区域如图5、图6所示。
(3)采用panda的.dataframe函数将存储于inter_area{}字典的重叠面积值、ori_tem{}字典的原始温度值、tem_s{}字典的加权温度存储为列名为日期,行名为经纬度(占两列)的温度矩阵,如图7所示。并利用csv函数将其存储的结果输出为csv文件,然后出图结果如图8所示(为比较输出结果的可靠性,将gz省一并纳入比较)。
4、通过定义函数def的方式,将该提取方法封装成函数模块class,并将完整代码保存为intersection_module.py文件格式。把该函数模块放在固定文件夹(或相对固定文件夹),使用sys.append(r'调用的模块路径'),将该函数模块所在路径添加到搜索路径,当需要在不同的程序代码编写过程中,可采用import工具直接调用该函数模块(类)。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!