基于网络日志的用户行为刻画与预测方法及系统与流程
本发明涉及一种基于网络日志的用户行为刻画与预测方法及系统。
背景技术:
随着网络与信息资源的飞速发展,网络搜索引擎已成为人们获取信息的主要途径,网络搜索日志包含了用户的行为和需求,从网络日志可以判断出一个人的性格,甚至可以预测用户接下来要做的事情。这在安全领域尤其重要,可以根据用户接下来的行为来判断哪些用户可归为危险人群,如黑客经常使用社会工程学的方法利用人的弱点进行攻击。如用户信息泄露,犯罪分子在网络上搜索用户的身份信息、手机号码等实施盗取账号资金的目的。黑客首先进行信息侦探,收集名字、电话号码、身份证号等信息,从而伪装用户以实现对服务器端的欺骗,盗取用户账户。因此,如果安全部门通过分析网络日志,便可判断出危险的人群,甚至可以知道这类人群甚至特定的人接下来要做的事,就可以提前预警,防范危害的发生。
技术实现要素:
本发明的目的是提供一种基于网络日志的用户行为刻画与预测方法及系统,能够对用户的性格进行刻画预测,进而,根据用户性格预测用户的危险性,为防范危害的发生提供数据支持。
为实现上述目的,本发明提供了如下方案:
一种基于网络日志的用户行为刻画与预测方法,包括:
获取用户的网络日志;
根据所述网络日志提取所述用户的行为特征向量,所述行为特征向量为用户网络日志中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
获取标准性格特征向量,所述标准性格特征向量为标准性格中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
计算所述用户的行为特征向量与各所述标准性格特征向量的相似度;
将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征。
可选的,确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量;
根据用户的行为特征向量中理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为。
可选的,所述计算所述用户的行为特征向量与各所述标准性格特征向量的相似度,具体包括:
计算所述用户的行为特征向量与各所述标准性格特征向量的余弦相似度;
将余弦相似度最小的标准性格特征向量确定为与所述用户行为特征向量相似度最大的标准性格特征向量。
可选的,所述将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征,具体包括:
将所述标准性格特征向量划分为积极性格、中级性格和消极性格三种类型;
将与用户行为特征向量相似度最大的标准性格特征向量所属类型确定为所述用户的性格类型。
可选的,所述根据用户的行为特征向量中理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为,具体包括:
当所述用户的行为特征向量中理科类关键词数量与文科类关键词数量的比值为3:1时,预测所述用户有对他人造成伤害的可能性。
本发明还提供了一种基于网络日志的用户行为刻画与预测系统,包括:
网络日志获取模块,用于获取用户的网络日志;
用户行为特征向量提取模块,用于根据所述网络日志提取所述用户的行为特征向量,所述行为特征向量为用户网络日志中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
标准性格特征向量获取模块,用于获取标准性格特征向量,所述标准性格特征向量为标准性格中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
相似度计算模块,用于计算所述用户的行为特征向量与各所述标准性格特征向量的相似度;
用户性格刻画模块,用于将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征。
可选的,关键词数量确定模块,用于确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量;
用户行为预测模块,用于根据用户的行为特征向量中理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为。
可选的,所述相似度计算模块,具体包括:
相似度计算单元,用于计算所述用户的行为特征向量与各所述标准性格特征向量的余弦相似度;
性格确定单元,用于将余弦相似度最小的标准性格特征向量确定为与所述用户行为特征向量相似度最大的标准性格特征向量。
可选的,所述用户性格刻画模块,具体包括:
性格类型划分单元,用于将所述标准性格特征向量划分为积极性格、中级性格和消极性格三种类型;
用户性格刻画单元,用于将与用户行为特征向量相似度最大的标准性格特征向量所属类型确定为所述用户的性格类型。
可选的,所述用户行为预测模块,具体包括:
用户行为预测单元,用于当所述用户的行为特征向量中理科类关键词数量与文科类关键词数量的比值为3:1时,预测所述用户有对他人造成伤害的可能性。
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的基于网络日志的用户行为刻画与预测方法及系统,根据用户网络日志提取用户的行为特征向量,计算用户的行为特征向量与各标准性格特征向量的相似度,将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征,根据获得的用户性格特征确定用户的危险性。同时,确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量,根据理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为危险性,进行提前预警,防范危害的发生。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例基于网络日志的用户行为刻画与预测方法流程图;
图2为本发明实施例基于网络日志的用户行为刻画与预测方法的又一流程图;
图3为本发明实施例集合x的上近似、下近似、边界域示意图;
图4为本发明实施例基于网络日志的用户行为刻画与预测系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于网络日志的用户行为刻画与预测方法及系统,能够对用户的性格、行为进行预测,进而,为防范危害的发生提供数据支持。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
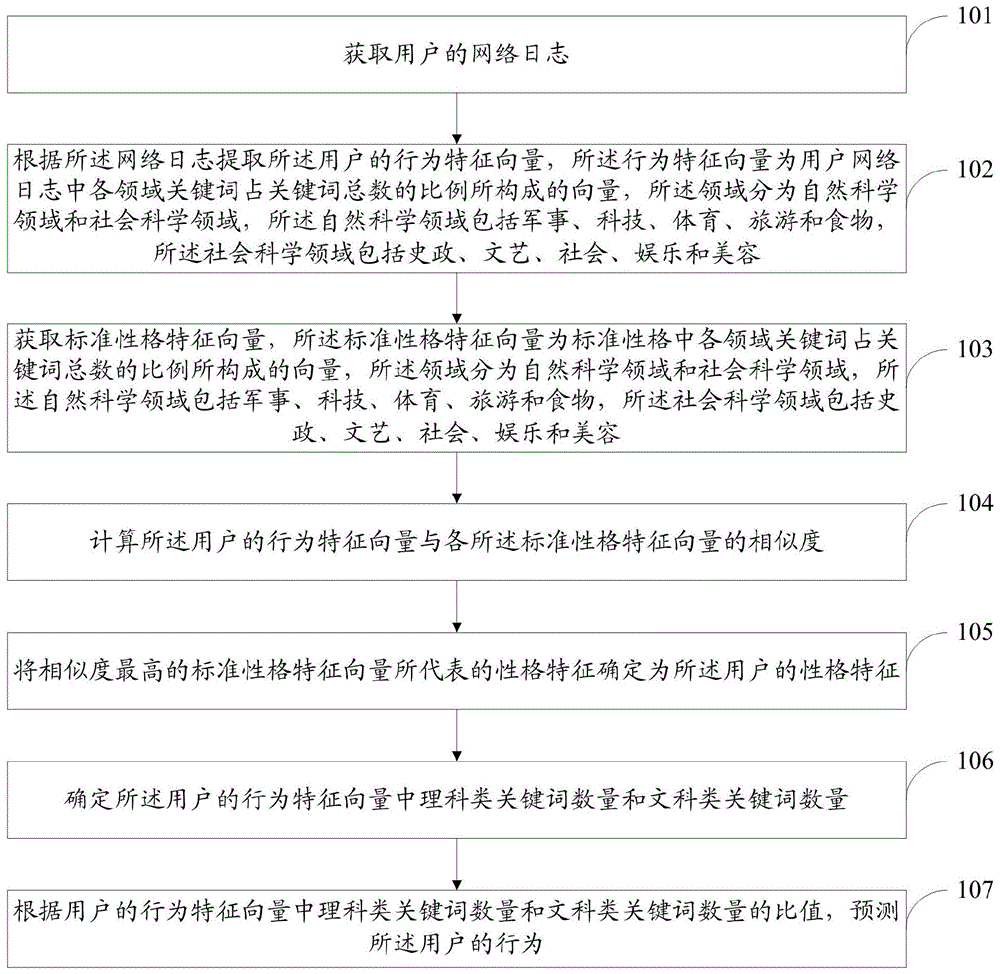
如图1所示,本发明提供的基于网络日志的用户行为刻画与预测方法包括以下步骤:
步骤101:的网络日志;
步骤102:根据所述网络日志提取所述用户的行为特征向量,所述行为特征向量为用户网络日志中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
步骤103:获取标准性格特征向量,所述标准性格特征向量为标准性格中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
步骤104:计算所述用户的行为特征向量与各所述标准性格特征向量的相似度;
步骤105:将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征;
作为本发明的一个实施例,在上述实施例的基础上,本发明还包括;
步骤106:确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量;
步骤107:根据用户的行为特征向量中理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为。
其中,步骤104,具体包括:
计算所述用户的行为特征向量与各所述标准性格特征向量的余弦相似度;
将余弦相似度最小的标准性格特征向量确定为与所述用户行为特征向量相似度最大的标准性格特征向量。
步骤105,具体包括:
将所述标准性格特征向量划分为积极性格、中级性格和消极性格三种类型;
将与用户行为特征向量相似度最大的标准性格特征向量所属类型确定为所述用户的性格类型。
步骤107,具体包括:
当所述用户的行为特征向量中理科类关键词数量与文科类关键词数量的比值为3:1时,预测所述用户有对他人造成伤害的可能性。
作为本发明的又一实施例,如图2所示,本发明提供的基于网络日志的用户行为刻画与预测方法包括以下内容:
1.1日志获取
源日志主要来自于搜索引擎服务器或网络爬虫,将爬虫系统与各个站点连接,从而获取网络日志。目前常用的爬虫系统有百度统计、cnzz等。本发明采用搜狗实验室2008年6月部分网页查询需求及用户点击情况的网页查询日志。数据格式为:“用户|查询词|该url在返回结果中的排名|用户点击的顺序号|用户点击的url”。日志样本如表1所示。注:本文选取个体用户查询信息多于8条的用户作为实验对象。
表1日志样本
1.2日志的预处理
定义1:同义词集合:同义词集合包含该词以及具有与该词含义相同或相近词的集合。
定义2:上位词:上位词指概念范围更广的词。如“车”是“汽车”的上位词;“交通工具”是“车”的上位词。同位词集合包含于上位词中。
1.2.1性格模型的构建
性格模型的构建包含两部分:(1)性格的划分;(2)上位词的分类与选取。本发明参照大五人格理论,性格包含开放性、责任心、外倾性、宜人性和情绪化人格。人们受社会环境、社会文化和各种思潮的影响,性格特点具有多样性,其多样性根据大五人格理论可大致分为积极、中级与消极三个方面。通过结合个人特点的自身优势、不足进行客观地评价。人们接触到多元的价值观,接受主流思想,具有思维活跃、勇于展现自我、热情奔放、社会责任感强、团队合作意识、创新意识、感恩意识等特点,具体性格表现与相关分类如表2所示。上位词的分类可分为自然科学类词汇与社会科学类词汇。自然科学类词汇选取军事、科技、体育、旅游、食物5类;社会科学类词汇选取史政、文艺、社会、娱乐、美容5类。划分的依据有:1)自然科学与社会科学本身的特点,例如科技、史政、文艺等标志明显词汇;2)依据人的性格特点,如社会责任感强的人,会讨论并分析国家时事,故有一定概率关注军事类内容;兴趣广泛的人通常性格开朗,会有一定几率关注体育类、旅游类的内容,而体育类和旅游类需要团体的配合与周密的安排,符合自然科学类的特点。社会科学类词汇倾向于发散思维,考虑到多方面,例如社会、娱乐。社会科学类思维的人不喜拘束,随性,故有一定几率关注美容类。其涉猎范围广,人们关注范围广,符合社会科学类的性格特点。包含上位词的用户标准性格特征向量库如表3所示。表3中数字代表不同性格的人群搜索的具有相同上位词的关键词个数的百分比的统计平均值。
1.2.2预处理算法(算法1)
预处理算法如下(算法1):
输入:用户的原始日志
输出:用户的特征向量
步骤1首先对原始日志中url进行爬取,获取网页摘要并加入用户日志中
步骤2找出日志中的关键词,统计搜索关键词的个数
步骤3统计关键词的上位词出现的个数
步骤4求得每类上位词占所有上位词的比例并将比值以百分比形式构成特征向量
算法1举例:输出结果例如表2样本中用户125254918559和828687165269搜索的上位次比例构成的向量分别为:
125254918559:(0.0,20.0,0.0,0.0,0.0,40.0,20.0,0.0,0.0,20.0)828687165269:(25.0,56.25,0.0,0.0,0.0,0.0,12.5,6.25,0.0,0.0)
表2性格模型与性格关键词分类
核心算法
步骤1:相似度匹配
基于余弦相似度特征聚类的性格分析算法在构建上述标准性格特征向量库的基础上,对新日志中各类上位词的比例进行统计,与向量库中每一行进行余弦相似度比较,夹角越小,越接近其性格特征向量。求得余弦值最大的分量,即夹角最小的分量,即可得出其性格特征。
对未知性格的新用户提取出日志中的关键字并统计其上位词分别出现的频率,求得统计平均值,将关键字的上位词所占比例构建特征向量,并与标准性格特征向量库中的分量进行相似度计算,得出的差值越小,表明越接近该行向量,进而得出用户在标准性格特征向量库中最接近的性格,即为本用户的性格。
基于余弦相似度特征聚类的性格分析算法如下(算法2):
输入:用户的特征向量(由算法1输出生成)
输出:用户的性格特征
步骤1构建性格模型向量集合
步骤2构建用户测试向量
步骤3相似度比较,找出特征向量库中余弦值最大的分量
步骤4输出该分量对应的性格特征
算法2举例:输出结果例如表2样本中用户125254918559的性格特征为积极性格:家庭观念强,自立自强,尊老爱幼(较好的家庭观念/体恤父母/自立自强/理解父母的艰辛与良苦用心/吃苦耐劳,适应力强);用户828687165269的性格特征为消极性格:缺乏沟通技巧(沟通不畅/表达能力差/与他人关系紧张/朋友圈子较小/容易遭遇尴尬)。
用户性格趋向是用户性格特征向量与标准性格特征向量库中行向量的相似度的反映。矩阵m为标准性格特征向量库,c1-cn表示上位词,w1-wn表示上位词比例权重的平均值,每行代表标准性格特征向量库的分量,记为
本发明中
步骤2关键词的上位词分类,性格分类,构建行为库与行为向量
基于粗糙集模糊分析的行为预测算法采用知识简约的方法,将性格特征向量库中的性格进一步分为积极、中级和消极三个等级。
关键词的上位词进一步分为自然科学类和社会科学类词汇,将两类词汇的搜索比例分为三个等级。分析三个因素(性格等级,自然科学词汇等级,社会科学词汇等级)的不同组合,共有33=27种组合,将27种组合参考霍兰德职业性格倾向测试结果,可得具有27种行为方向的行为库。将用户日志中的3个因素做相同处理,与行为库进行比对,输出符合的行为。
定义3近似:k=(u,s)为给定的知识库,u表示论域,s为u上的等价关系簇。则
定义4知识简约:知识库中的知识并非同等重要,有些知识冗余。知识简约是将一些五环或多余特征丢弃,在不影响原有分析的前提下将信息量减少。即在不影响原知识分类的情况下,将n维信息空间{x1,x2,…,xn}减小为m维信息空间{x1,x2,…,xm},(m<n)。通过约简,产生新的决策规则。
知识表达系统是粗糙集理论中主要的知识表示方法,记为s=(u,a,v,f),其中u表示对象的非空有限集合,即论域,a为属性的非空有限集合,即属性集。v=uα∈avα,vα表示属性α的值域,f为u×a→v,f为信息函数,v为每个对象的每个属性赋予一个信息值,即
表3知识表达系统
步骤3匹配相等,输出用户行为
首先将性格与各个上位词搜索百分比作为知识库。然后将性格简约为积极、中级和消极。上位词简约为自然科学类词汇的百分比和社会科学类词汇百分比。最后根据百分比所在不同区间分别将自然科学类词汇和社会科学类词汇简约为3个等级。
基于粗糙集模糊分析的行为预测算法如下(算法3):
输入:用户的性格特征(由算法2输出生成),用户的特征向量(由预处理算法输出生成)
输出:用户的行为预测
步骤1构建索引表为长度为4的二维数组作为行为分析库
步骤2构建长度为3的一维数组分别表示性格等级、自然科学词汇等级与社会科学词汇等级
步骤3将用户测试向量中关键词按照自然科学类和社会科学类分别求统计平均值并划分等级,存入一维数组对应的空间中
步骤4划分用户性格等级,存入一维数组对应的空间中
步骤5将一维数组在行为分析库中匹配对应的行,输出行为
算法3举例:如表1样本中用户125254918559的行为通过采用算法3得到的预测结果为:理科类与文科类兴趣比例约为1:3,(行为具体解释:)社会责任感强,擅长分析政治局势/关注国家政策/喜欢政治类的新闻、报纸、名人自传;用户828687165269的行为通过采用算法3得到的预测结果为:理科类与文科类兴趣比例约为3:1,(行为具体解释:)自闭/对科学内容有较高理解力,如计算机、物理、生物/可能采取技术性的极端行为,对他人造成人身/财产伤害。
首先将性格按照积极、中级、消极划分为三个等级;然后将用户搜索日志中自然科学类中5类词汇的比例求和,得到自然科学类词汇的比例。将百分比按照[0,33),[33,66),
[66,100]三个区间分为三个等级。社会科学类词汇同理。因此,a={性格等级,自然科学类词汇等级,社会科学类词汇等级},u={x1,x2,…,x27}。对属性集不同元素的27种组合,根据霍兰德职业性格倾向测试结果对每种情况分别进行分析,建立行为分析库,行为的集合即为u,如表4所示。其中消极性格记为1,中级性格记为2,积极性格记为3。自然科学和社会科学词频将百分比按照[0,33)记为1,[33,66)记为2,[66,100]记为3。x1--x27表示行为的编号。
最后将用户的属性集合与行为分析库比对,找到使得用户属性集与行为分析库中的属性集相等的记录,输出符合的行为特征。
表4用户行为分析表
本发明还提供了一种基于网络日志的用户行为刻画与预测系统,如图4所示,该系统包括:
网络日志获取模块401,用于获取用户的网络日志;
用户行为特征向量提取模块402,用于根据所述网络日志提取所述用户的行为特征向量,所述行为特征向量为用户网络日志中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
标准性格特征向量获取模块403,用于获取标准性格特征向量,所述标准性格特征向量为标准性格中各领域关键词占关键词总数的比例所构成的向量,所述领域分为自然科学领域和社会科学领域,所述自然科学领域包括军事、科技、体育、旅游和食物,所述社会科学领域包括史政、文艺、社会、娱乐和美容;
相似度计算模块404,用于计算所述用户的行为特征向量与各所述标准性格特征向量的相似度;
用户性格刻画模块405,用于将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征;
作为本发明的一个实施例,在上述实施例的基础上,本发明还包括:
关键词数量确定模块406,用于确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量;
用户行为预测模块407,用于根据用户的行为特征向量中理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为。
其中,所述相似度计算模块404,具体包括:
相似度计算单元,用于计算所述用户的行为特征向量与各所述标准性格特征向量的余弦相似度;
性格确定单元,用于将余弦相似度最小的标准性格特征向量确定为与所述用户行为特征向量相似度最大的标准性格特征向量。
所述用户性格刻画模块405,具体包括:
性格类型划分单元,用于将所述标准性格特征向量划分为积极性格、中级性格和消极性格三种类型;
用户性格刻画单元,用于将与用户行为特征向量相似度最大的标准性格特征向量所属类型确定为所述用户的性格类型。
所述用户行为预测模块407,具体包括:
用户行为预测单元,用于当所述用户的行为特征向量中理科类关键词数量与文科类关键词数量的比值为3:1时,预测所述用户有对他人造成伤害的可能性。
本发明提供的基于网络日志的用户行为刻画与预测方法及系统,根据用户网络日志提取用户的行为特征向量,计算用户的行为特征向量与各标准性格特征向量的相似度,将相似度最高的标准性格特征向量所代表的性格特征确定为所述用户的性格特征,根据获得的用户性格特征确定用户的危险性。同时,确定所述用户的行为特征向量中理科类关键词数量和文科类关键词数量,根据理科类关键词数量和文科类关键词数量的比值,预测所述用户的行为危险性,进行提前预警,防范危害的发生。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!