一种基于密文的多关键字扩展检索方法与流程
本发明涉及文字检索技术领域,具体涉及一种基于密文的多关键字扩展检索方法。
背景技术:
在以隐私保护为目标的研究中,可搜索加密方案占据着重要的地位,基于这一领域的研究也得到了充分的丰富于发展。但是随着数据的爆炸式增长与用户需求的日益多样化,该方案也面临着各种问题与挑战。目前的主流方案中大多是根据用户输入的查询关键字进行精确检索,并没有考虑到各种其它因素,当用户的查询关键字输入错误或者单一,并不能合理的返回给用户相应的结果。随着用户上传的数据量成线性增长,如何根据用户的喜爱和偏好进行结果过滤或者进行提升关键字优先级,减少用户的数据筛选,也是重要的改进之一。
随着个性化搜索的提出,这个问题得到了很好的解决,它的主要原理是对用户的信息进行采集,然后分析出用户的兴趣和偏好,然后根据分析对比将检索结果进行针对用户的个性化排序,使用户能够快速的找到想要的结果。但是由于该方案是在用户信息的基础上进行操作,对于密文检索这种注重隐私性的方案来说可能并不是一个很好的选择。
技术实现要素:
发明目的:为了克服现有技术的不足,本发明提供一种基于密文的多关键字扩展检索方法,该方法可以解决在进行模糊多关键字排序检索中的效率低,准确率不高,查询结果单一,智能程度低的问题。
技术方案:本发明所述的基于密文的多关键字扩展检索方法,包括:
(1)构建b+索引树组:根据数据源中关键字集合kw构建逆文档向量集idoc,利用逆文档向量集合idoc构建对应的分组b+索引树组io,并利用文档向量集合doc构建对应的分组文档数据集it;
(2)it和io加密:利用安全knn算法对io和it进行加密,加密后的数据分别记为eio和eit,并将加密后的数据上传至云服务器;
(3)模糊处理查询关键字:将用户输入的查询关键字组成的集合wq与关键字集合kw匹配,得到处理后的模糊关键字集合wm;
(4)模糊查询关键字集合wm的语义扩展:根据构建的语义树得到关键字间的语义相似度,对wm进行遍历并和关键字集kw进行语义相似度计算,对每一个模糊集合中的关键字进行语义扩展,形成语义扩展集,然后将每一个关键字的语义扩展集添加到wm,形成语义集合wy;
(5)构建陷门:对wy进行遍历,根据遍历的当前关键字是否存在kw中构建第一次查询向量qo和第二次查询向量qt,并采用安全knn算法对qo和qt进行加密,得到陷门,并将加密数据上传至云服务器;
(6)eqo和eqt二次排序匹配:利用eio和eqo中存储的加密后的tf值和idf值进行相关度分数score的计算,得到结果集result;根据第一次检索结果result,用eqt和找到的文档向量进行二次相关度分数score的计算和排序,得到eqti和eiti的最终相关度分数score,并返回给用户分数最高的前k个密文文档。
优选的,步骤(3)中,所述将用户输入的查询关键字组成的集合wq与关键字集合kw匹配,得到处理后的模糊关键字集合wm,包括:设用户输入的查询关键字个数为t,则查询关键字集可以表示为wq={wq1,wq2,…,wqt},对其进行遍历,若wqi∈kw始终为真时,其中,1≤i≤t,表示用户输入的查询关键字无拼写错误,此时wm=wq;若其中存在wqi∈kw为假,说明用户输入的该关键字不存在于关键字集合kw中,将关键字wqi与关键字集合kw中的每个关键字进行编辑距离ed的计算,若符合预设ed的阈值,则将关键字集合中kw中的该关键字添加到模糊关键字集合wm中,遍历完成后,将所有符合条件的关键字添加模糊关键字集合中,获得最终的wm。
优选的,步骤(3)中,所述模糊关键字集合wm记为cm,公式表示为:
优选的,步骤(4)中,所述对每一个模糊关键字集合中的关键字进行语义扩展,形成语义扩展集,包括以下步骤:
(41)定义两个关键字wi和wj,用sim(wi,wj)表示为关键字wi和关键字wj的语义相似度,相似度运算公式如下所示:
其中,γ和δ是控制最短距离路径长度以及近公共祖先节点在运算中的影响权重,γ≥0,δ≥0,len(wi,wj)表示在语义树中从关键字wi到关键字wj所经过的最短路径,且:
lso(wi,wj)表示在语义树中关键字wi和关键字wj最近公共祖先节点,deep(wi)表示关键字wi到根节点所经过的路径长度;
(42)对wm进行遍历并和关键字集合kw进行相似度计算,对每一个模糊关键字集合中的关键字进行语义扩展,取相似度最高的前τ个关键字形成语义扩展集。
优选的,步骤(5)中,具体包括以下步骤:
(51)对wy进行遍历,如果遍历的当前关键字存在于kw中,则qo的对应位上存储该关键字的idf值,否则,存储0进行占位处理;
(52)对wy进行遍历,如果遍历的当前关键字存在于kw中,则qt的对应位上存储该关键字的idf值,否则,存储0进行占位处理,qt和qo组成了完整的查询向量;
(53)采用安全knn算法对qo进行加密,用qoi[j]表示qo中第i组的第j位数据,若随机位为0时,qo′i[j]+qo″i[j]=qoi[j];若随机位为1时,qo′i[j]=qo″i[j]=qoi[j],qo加密后的形式记为eqo,qoi[j]加密后产生的两个新向量为qoi'[j]和qoi”[j];
(54)用安全knn算法对qt进行加密,用qti[j]表示qt中第i组的第j位数据,qti[j]加密后产生的两个新向量为qti'[j]和qti”[j]。若随机位为0时,qti'[j]+qti”[j]=qti[j];若随机位为1时,qti'[j]=qti”[j]=qti[j],qt加密后的形式记为eqt。
优选的,所述步骤(6)具体包括以下步骤:
(61)将eio和eqo采用基于tf-idf模型进行匹配计算,当eqo中有null标记时,直接跳过不予计算;否则,加密后的ioi在加密后的qoi上进行检索,获得每组相关性最高的前h个加密文档,形成结果集{result1,result2,…,resultf},其中resulti的长度为h,且f≤b,去重后得到结果集result;
(62)
(63)通过result找到eit中有效的文档向量,用eqt和找到的文档向量进行二次相关度分数score的计算和排序,并将score最高的前k个文档标识符返回给查询用户,用户根据文档标识符fid找到对应的密文文档,下载到本地解密后获取对应的明文信息;
(64)
有益效果:本发明与现有技术相比,其显著优点是:1、本发明从陷门扩展的角度出发,对用户输入的检索关键字进行模糊处理以及语义分析,提升用户的使用体验;2、在高效的多关键字可排序密文检索的基础之上,在陷门构建的步骤当中首先增加关键字模糊处理,丰富查询返回的结果,即使用户输入错误的关键字信息,也可以对其纠正从而返回正确的结果;3、本发明对用户查询关键字集合进行语义分析处理,扩大搜索条件,丰富查询返回的结果,使查询不再精确化,降低关键字的局限性,帮助用户更加深入的挖掘数据中有用的信息。
附图说明
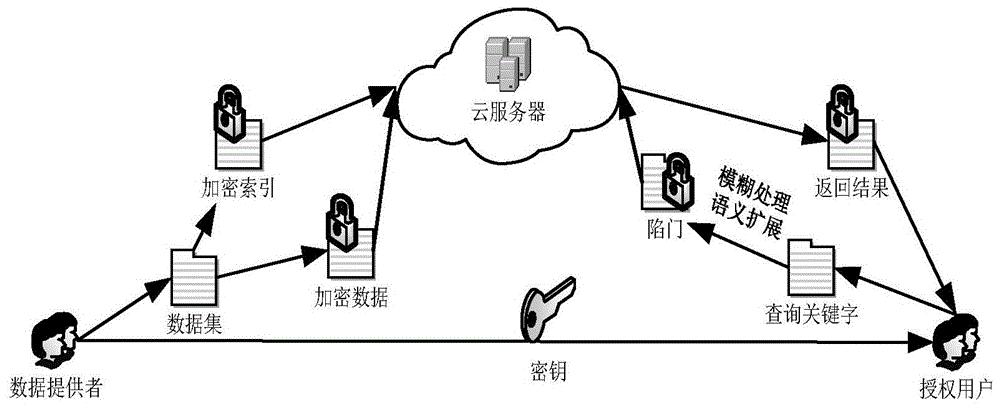
图1为本发明所述方法实现框架;
图2为本发明所述的方法流程图;
图3为图2中的步骤1和2的具体流程图;
图4为图2中的步骤3的具体流程图;
图5为图2中的步骤3中的模糊处理方法流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,本发明提供一种基于密文的多关键字扩展检索方法,首先通过ik分词器对数据提供者提供的数据源进行关键字集提取,形成关键字集合,然后基于关键字集合构建逆文档向量集并做分组处理操作,再对每组向量集进行b+索引树构建,通过安全knn算法进行加密,然后利用对称加密算法对数据源加密,最后将加密后的索引树组和数据源一块上传至云服务器中,保证了检索的高效性。在陷门生成过程中,模糊多关键字排序检索方法首先对用户输入的检索关键字做模糊处理,针对用户输入错误的情况进行纠正;然后对模糊处理后的查询关键字集合做语义分析操作,对查询关键字集进行扩展;最后,根据经过语义分析后的关键字集合进行查询向量的生成,同样利用安全knn算法加密处理后获得陷门,对陷门做分组处理并上传至云服务器。云服务器根据tf-idf模型将分组陷门和b+索引树组做匹配,并按照相关度分数排序,最终返回给授权用户相关度最高的前k个密文文档。
具体包括:
如图2-5所示,步骤1、数据提供者提数据源,根据ik分词器对数据源做分词处理,获取关键字集合,构建逆文档向量集并对其分组,采用对称加密算法加密数据源。
步骤1.1生成文档向量集:在数据源中,通过ik分词器做关键字拆分处理,获取的关键字集合为kw,设定n为关键字集合中关键字的数量,则关键字集合可以表达为kw=(kw1,kw2,…,kwn)。通过kw可以将数据源中的文档集合转换为文档向量集合doc,设定数据源中的文档个数为m,则文档向量集合可以表示为doc=(doc1,doc2,…,docm),其中doci表示doc中第i(0≤i≤m)个文档向量,其向量长度为n,向量中的每位对应kw中相应关键字,如果该关键字出现在当前文档中,则存储该关键字在当前文档中的tf值,否则对应位存储0做占位处理。
步骤1.2生成逆文档向量集:通过步骤1.1中的kw构建逆文档向量集idoc,其长度和kw相等,同样位n,其构建原理是通过关键字找到包含该关键字的文档集,可以表示为idoc={idoc(kw1),idoc(kw2),…,idoc(kwn)},其中,idoc(kwi)表示idoc中第i(0≤i≤n)个逆文档向量,存储包含关键字kwi的所有doc,在本步骤中限定为所有idoc的长度为a,也即是存储包含kwi且tf值最高的前a个文档向量。
步骤1.3逆文档向量集合分组:将步骤1.2中的idoc进行分组处理,设定分为b组,则分组后的idoc可以表示为idocg=(idocg1,idocg2,…,idocgb),每组的关键字集个数为o,其中
步骤2、利用逆文档向量集构建b+索引树组,通过改进的安全knn算法加密后,和加密后的数据源一同上传至云服务器;
步骤2.1:构建逆文档向量集合对应索引树组:根据步骤1.3中的idoc构建对应的分组b+索引树组io,表示为io={io1,io2,…,iob}。b+树中的节点存储的关键字结构为为<fid,children[m],inf>,fid为密文索引对应的文档标识符,只出现在叶子节点中,非叶子节点该值为null,children[m]存储指向孩子节点的指针信息,m为b+树阶数,叶子节点的inf存储对应关键字组在文档的tf值,非叶子节点的inf为对应孩子节点存储的所有关键字的inf按位取最大值获得。设节点存储的其中一个关键字为key,其对应的孩子节点为child,key表示child所有存储的关键字信息,则该节点的inf的第c位可以由如下公式获得:
key.inf[c]=max{child.key[c]|key∈key}
步骤2.2:构建分组文档数据集:根据步骤1.1中的doc构建it={it1,it2,…,itm},用iti表示it的其中一项,基于doci构建结构为iti=<fid,inf1,inf2,…,infb>,其中infi是长度为o的向量,第j位存储的数据可以表示为infi[j]=it(doci<kwgi,j>)(j=1,…,o)。io和it组成完整的索引,io用于步骤4.1中的第一次排序计算,it用于步骤4.2中的第二次排序计算。
步骤2.3:加密io和it:利用安全knn算法对步骤2.1中的io和步骤2.2中的it进行加密,也即是生成随机的0和1序列,将io和it加密成两个新的数据。
用ioi[j]表示io中第i组的第j位数据,当随机位为0时,io′i[j]=io″i[j]=ioi[j];当随机位为1时,io′i[j]=io″i[j]=ioi[j]。it的加密步骤与io一致,最终获得加密后的eio和eit,并将这两组加密数据上传至云服务器。
步骤3、以授权用户输入的查询关键字为基础,首先进行模糊处理操作获取模糊查询关键字集,然后通过模糊查询关键字集做语义分析处理获取语义查询关键字集,并以此为基础构建查询向量,利用安全knn加密后得到陷门,做分组处理后上传至云服务器。
步骤3.1:以提升检索健壮性为目的,防止出现用户输入检索关键字拼写错误而出现无检索结果的情况,对用户输入的查询关键字wq做模糊处理。
设用户输入的查询关键字个数为t,则查询关键字集可以表示为wq={wq1,wq2,…,wqt},对其进行遍历,
当wqi∈kw(1≤i≤t)始终为true时,表示用户输入的查询关键字无拼写错误,用wm表示处理后的模糊查询关键字集合,此时wm=wq。
如果wqi∈kw为false,说明用户输入的该关键字不存在于关键字集合kw中,因此需要对用户输入错误这种情况进行处理,用ed(s′,s)表示字符串s′和字符串s的编辑距离,针对上述错误情况,将关键字wqi与关键字集合kw中的每个关键字进行编辑距离ed计算,获取与该关键字对应的模糊关键字集合,然后将wqi从wq中移除。
ed的大小影响关键字的语义相似度标准,可根据实际需求进行设置,本发明对关键字模糊处理设置ed=1,则且由于目的是对用户在查询关键字拼写错误的情况下进行处理,所以采用基于字典的方式构建模糊关键字集合。关键字集合kw遍历完成后,将所有关键字wqi与关键字集合kw中的ed=1的关键字添加到模糊关键字集合中,遍历完成后,将所有模糊集合中的关键字添加到wq中最终获得wm,,且用cm表示通过错误关键字获取的模糊关键字集合,则cm可以用如下公式表示:
以下是查询关键字wq做模糊处理算法的过程:
输入:查询关键字集wq,关键字集kw,编辑距离α
输出:模糊关键字集wm
步骤3.2模糊查询关键字集合语义扩展:利用步骤3.1中得到的wm进行语义扩展操作,帮助授权用户完善查询关键字信息,更深层次的挖掘有价值的数据。
定义两个关键字wi和wj,用deep(wi)表示关键字wi在语义树中的层次,也即是到根节点所经过的路径长度,所以根节点层次的设定影响着其所有子节点层次的运算。
将根节点层次设定为1,因此子节点的深度也即是到根节点的距离加1。用len(wi,wj)表示在语义树中从关键字wi到关键字wj所经过的最短路径,也即是它们之间的距离长度。用lso(wi,wj)表示在语义树中关键字wi和关键字wj最近公共祖先节点。
用sim(wi,wj)表示为关键字wi和关键字wj的语义相似度,且满足:
两种计算方式,其中δ是非负数,则相似度运算公式如下所示:
在上述公式中,γ和δ是控制最短距离路径长度以及近公共祖先节点在运算中的影响权重,并采用γ=0.2,δ=0.6的最优设置。由上述公式可以看出,两个关键字的相似度与最短路径距离len成反比关系,与两个关键字的lso满足正比关系,且sim(wi,wj)的取值范围是0至1。
对wm进行遍历并和关键字集kw进行相似度计算,对每一个模糊关键字集合中的关键字进行语义扩展,取相似度最高的前τ个关键字形成语义扩展集,然后将每一个关键字的语义扩展集添加到wm,形成语义集合wy。
步骤3.3:构建查询向量qo和qt:根据步骤3.2中的wy构建第一次查询向量qo。构建过程为:首先对wy进行遍历,如果遍历的当前关键字存在于kw中,则qo的对应位上存储该关键字的idf值,否则,存储0进行占位处理。将qo同样分为b组,当一组存储的数据全为0时,说明该组不包含检索关键字,将该组做null标记,后续计算中可以直接跳过不予计算,提升检索效率。第二次查询向量qt的构建方法和最后的形式和qo相同,qt和qo组成了完整的查询向量。qo用于和io计算做第一次排序,qt用于和it进行计算做第二次排序。
步骤3.4:qo和qt加密:用安全knn算法对步骤3.3中的qo和qt进行加密,加密过程基本同步骤2.3。用qoi[j]表示qo中第i组的第j位数据,对qoi[j]进行加密,产生的两个新向量为qoi'[j]和qoi”[j]。和索引加密的不同点是,当随机位为0时,qo′i[j]=qo″i[j]=qoi[j];当随机位为1时,qo′i[j]=qo″i[j]=qoi[j]。qt的加密步骤与qo一致,qo和qt加密后的形式为eqo和eqt,然后将这两组加密数据上传至云服务器。
步骤4、通过tf-idf模型,对步骤2中的分组b+索引树和步骤3中的分组陷门进行匹配,根据相关度分数对匹配结果进行排序,并返回给用户前top-k个密文文档。
具体如下:
步骤4.1:将eio和eqo采用基于tf-idf模型进行匹配计算,当eqo中有null标记时,和对应b+索引树直接跳过不予计算,
否则,利用eio和eqo中存储的加密后的tf值和idf值进行相关度分数score的计算,也就是说加密后的ioi在加密后的qoi上进行检索,然后获得每组相关性最高的前h(h为一个随机正整数)个加密文档,形成结果集{result1,result2,…,resultf},其中resulti的长度为h,且f≤b,去重后得到结果集result。
步骤4.2:利用步骤4.1得到的第一次检索结果result,进行二次排序计算,通过result找到eit中有效的文档向量,然后用eqt和找到的文档向量进行二次相关度分数score的计算和排序,并将score最高的前k个文档标识符返回给查询用户,用户根据文档标识符fid找到对应的密文文档,下载到本地解密后获取对应的明文信息。
- 还没有人留言评论。精彩留言会获得点赞!