一种基于编辑距离的字符串模糊匹配和查询方法与流程
本发明属于计算机数据查询技术领域,涉及一种基于编辑距离的字符串模糊匹配和查询方法。
背景技术:
编辑距离在一种计算字符串间相似程度的度量方法,同时也被经常使用。但是计算编辑距离采用的是一种动态规划的思想,如果在数据集中计算每一对字符串间的编辑距离来判断字符串的匹配与否将会有巨大的开销。近几年来关于字符串的模糊查询问题有很多研究,他们多数是基于一种过滤-验证框架进行的。在过滤阶段,使用一个阈值t作为一个有效的过滤器,可以用来过滤大部分不相似的字符串,得到一个候选者集合。然后在验证阶段,通过计算候选者集合中字符串与查询串之间实际的编辑距离,得到结果集合。
阿里巴巴集团控股有限公司申请的专利“模糊查询方法,装置及查询系统”(申请号:cn201710372075,公开号:cn107436911a)提供了一种模糊查询的方法,所述方法包括:提供单字符倒排索引,所述单字符倒排索引包括将文档分割为单个字符后存入倒排索引构建生成;获取查询字符串,将所述的查询字符串分割为单个字符,其所述单个字符作为词组在所述单字符倒排索引中进行词组匹配方式查询。该方法不足的是:直接将字符串完全化成单字符的操作,计算较为复杂。
清华大学李国良老师团队的一篇论文“aunifiedframeworkforstringsimilaritysearchwithedit-distanceconstraint”中提到了一种hs-search的方法进行模糊查询,他分为了过滤和验证两个阶段。首先,我们需将s按照长度进行划分组,用sl代表长度为l|q|-t的字符串集合组。对每一个字符串集合组sl,我们都构造一棵二叉树。我们将sl中的字符串按照长度划分成两部分,第一个部分是s中前缀长度为
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供了一种基于编辑距离的字符串模糊匹配和查询方法,该方法能够反映不同长度段落对匹配结果不影响的不同,同时编辑距离验证操作次数较少。
为达到上述目的,本发明所述的基于编辑距离的字符串模糊匹配和查询方法包括以下步骤:
对数据集中的字符串按照长度进行分组,其中,将长度相同的字符串划为一个组,对每一字符串组按照长度构建一棵完全二叉树,并将该二叉树记作字符串搜索树,该字符串搜索树中的每个节点内均存储有划分后的字符串、该字符串的原字符串id、该字符串的长度及该字符串的开始位置;
当需要进行字符串查询时,则输入查询字符串的长度及距离阈值t,利用字符串的长度q及距离阈值t查找对应的字符串;
当需要进行长度过滤时,则只需查询长度在[|q|-τ,|q|+τ]之间的字符串即可;
当需要匹配过滤时,则先按照段落中字符串的长度对查询串依次进行划分,得查询串子串集合,然后进行字符串间的匹配操作,当段落内的字符串与查询串中的字符串相匹配时,则该字符串对应索引的原字符串的匹配度加上该字符串的长度,当该字符串的匹配度大于预设上界值时,则对匹配字符串在原字符串的位置列表以及在查询串中的位置列表进行验证,当该位置列表中没有重复的元素时,说明在匹配查询操作中没有引入字符串位置互换或者重复匹配的情况,则将该字符串添加到结果集合中,否则,则对该字符串进行编辑距离的验证;当该字符串的匹配度小于预设下界值时,则直接过滤掉该字符串;当该字符串的匹配度在预设下界值与预设上界值之间时,则对该字符串进行编辑距离验证,即,当该字符串的编辑距离小于等于距离阈值t时,则将该字符串添加到结果集合中,当该字符串的编辑距离大于距离阈值t时,则直接过滤掉该字符串。
字符串搜索树中的每个节点内还设置有倒序索引,该倒序索引包括该字符段落的原字符串所对应的id号。
字符串的长度为l∈[|q|-t,|q|)时,则预设上界值为|q|-t,预设下界值为
字符串的长度为l∈[|q|,|q|+t]时,则预设上界值为|l|-t,预设下界值为
本发明具有以下有益效果:
本发明所述的基于编辑距离的字符串模糊匹配和查询方法在具体操作时,将字符串划分为确定匹配的集合、可能匹配的集合以及不匹配的集合,当该字符串的编辑距离小于等于距离阈值t时,则将该字符串直接添加到结果集合中,当该字符串的编辑距离大于距离阈值t时,则直接过滤掉该字符串,从而减少编辑距离验证操作的次数;当该字符串的匹配度大于预设上界值时,则对匹配字符串在原字符串的位置列表以及在查询串中的位置列表进行验证,避免字符串互换位置及字符串段落重复匹配的问题。另外,当段落内的字符串与查询串中的字符串相匹配时,则该字符串对应索引的原字符串的匹配度加上该字符串的长度,以体现不同长度的段落对匹配度影响的不同。
附图说明
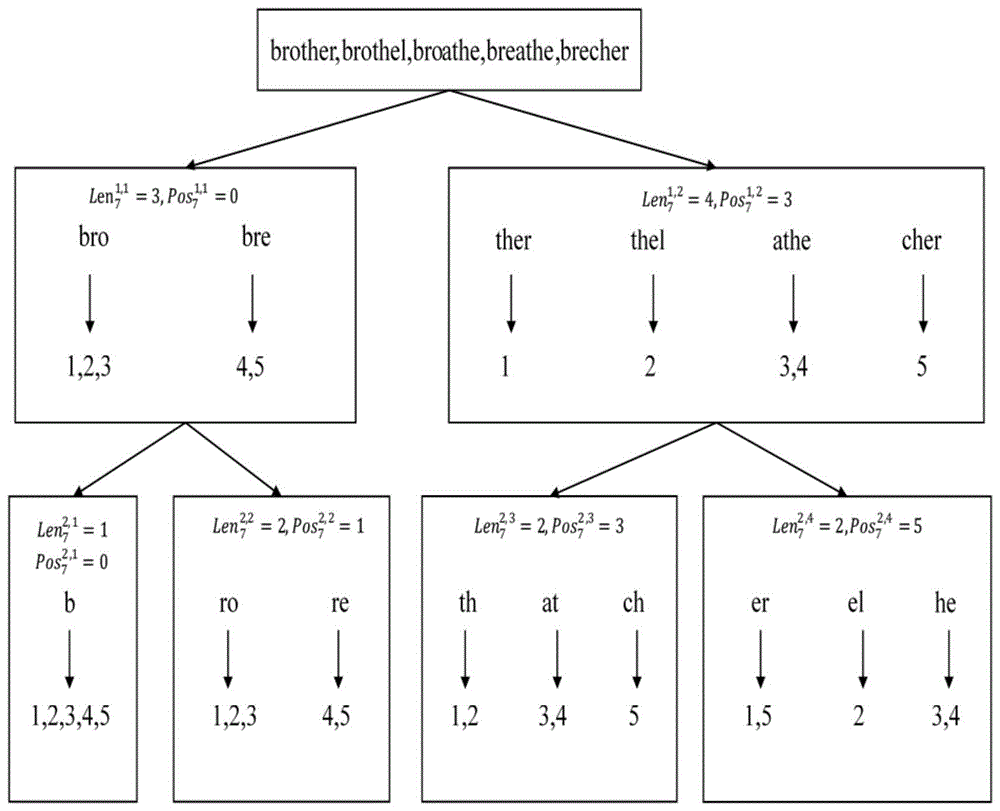
图1为本发明的字符串搜索树的结构示意图;
图2为本发明的流程图;
图3为本发明中匹配操作的流程图。
具体实施方式
下面结合附图对本发明做进一步详细描述:
参考图1,本发明在具体操作时,将字符串按照长度进行分组,对相同长度的字符串sl,按照字符串的长度进行划分,以构造一个二叉树结构,同时为每个节点中的字符串添加一个倒序索引,通过该倒序索引指示包含该字符串的原字符串的id号,并且需要记录该字符串段落内字符串的长度及字符串的开始位置,以生成字符串搜索树,其中,以长度为7的几个字符串为例按照字符串搜索树的划分原理,得一棵字符串搜索树。
参考图2,本发明使用的数据集为具有不同长度字符串的大数据集,其中,不同长度的字符串用sl表示,l表示该字符串的长度。
在进行匹配操作的时候,为每个id的字符串构造一个匹配度,用来显示它和查询串之间的匹配程度,当查询串子串与节点中的字符串匹配时,则将该匹配段落对应的原字符串id的匹配度加上段落的长度,同时记录匹配段落的段落号,在进行过滤时,判断匹配字符段落之间的位置关系,仅当位置关系和查询串一致且没有重复匹配时,则将该字符串直接添加到结果集合中,对于候选者集合中的字符串,需要验证他们与查询串之间的编辑距离,判断是否在距离阈值内,从而得到匹配结果。
参考图3,本发明的基于编辑距离的字符串模糊匹配和查询方法包括以下步骤:
对数据集中的字符串按照长度进行分组,其中,将长度相同的字符串划为一个组,其中,sl代表长度为l的字符串组,对每一字符串组按照长度构建一棵完全二叉树,并将该二叉树记作字符串搜索树,该字符串搜索树中的每个节点内均存储有划分后的字符串、该字符串的原字符串id、该字符串的长度及该字符串的开始位置,具体的,将sl中的字符串按照长度划分成两部分,第一个部分为sl中前缀长度为
当需要进行字符串查询时,则输入查询字符串的长度及距离阈值t,利用字符串的长度q及距离阈值t查找对应的字符串;
当需要进行长度过滤时,则只需查询长度在[|q|-τ,|q|+τ]之间的字符串即可;
当需要匹配过滤时,则先需要将查询的层数定位在
字符串的长度为l∈[|q|-t,|q|)时,则预设上界值为|q|-t,预设下界值为
- 还没有人留言评论。精彩留言会获得点赞!