一种基于混合采样和机器学习的不平衡数据分类方法与流程
本发明涉及不平衡数据分类技术领域,特别涉及一种基于混合采样和机器学习的不平衡数据分类方法。
背景技术:
当数据集中一类样本的数目远远低于另一类样本的数目时,就称为数据不平衡。基于不平衡数据集的决策在现实问题中非常常见。例如,如果一个样本的人被检测出某种特定的疾病,那么只有一小部分人会真的患上这种疾病。又例如,在金融信用卡欺诈检测中,整个交易样本中,只有少数交易实际上是欺诈。
目前,对于常规分类算法,一般是在认为两类数据的数量是平衡的基础上以提高总体识别的精确率为目标的,识别少数类的成功率一般较低,结果往往是有利于多数类的,也就是说,大部分少数类例子将被归类为多数类以达到高的总体准确率。
但是,在实际应用中,往往少数类的预测精度至关重要,因为少数类通常是感兴趣的类别。因此,对少数类的错误分类比对多数类的错误分类有更高的成本。为了更清楚地说明这一点,例如,将癌症患者误诊为非癌患者的成本与将非癌患者误诊为癌患者的成本进行比较,在前一种情况下,误诊可能导致一个人死亡,但在后一种情况下,会有更多的检查和筛查。因此,不平衡数据学习在基于不平衡数据集的分类中具有极其重要的作用。
不平衡数据分类算法一个重要的方式就是改变样本的分布,使数据集中两类数据达到某种程度的平衡分布。改变样本分布的方法可以分为两大类,一类是对多数类进行欠采样,另一类是对少数类进行过采样。在欠采样方法中,多数类中的一些数据被删除,因此,类的分布将更加平衡。欠采样方法的主要缺点是,通过删除某些数据,可能会丢失数据中潜在的重要信息。另一方面,过采样则是重新抽样或生成少数类的方式。最基本的过采样方法是随机过采样,其中数据中的少数实例是随机复制的,随机过采样的主要缺点是拟合过度。另一种过采样的主要方法是生成合成数据。smote(合成少数抽样技术)是合成数据生成中最著名的方法之一,在这种方法中,在将少数类样本与其k个最近的少数类邻域连接的线上生成合成数据点。smote的主要缺点是它可能导致过度泛化,因为它盲目地生成合成数据点,而偏离少数类的真实分布。因此,单一地采用欠采样或过采样技术都不能很好地实现对信息的完全获取或者恰当的拟合。
集成学习是机器学习的一个分支,它将各种基本分类器集成到基于特定学习算法的新学习算法中。因此,集成学习方法优于单个学习算法。boosting是一种集成学习分类算法,通过训练将弱分类器增强为强分类器,实现准确的分类。所谓弱分类器就是每次迭代产生的子模型,强分类器是最终的预测模型,每次迭代生成的分类器在所有迭代完成后都将以一定的权重添加到最终模型中。xgboost模型就是基于梯度增强决策树的一个集成模型,它具有梯度增强、决策树、正则化及并行处理的共同特点,它的训练效果好,不易过拟合,且训练速度快。
因此,本发明在基于混合采样和xgboost的优点上,设计出一种新的基于混合采样和机器学习的不平衡数据分类方法。
技术实现要素:
本发明的目的在于,针对上述现有技术的不足,提供一种基于混合采样和机器学习的不平衡数据分类方法。
为解决上述技术问题,本发明所采用的技术方案是:
一种基于混合采样和机器学习的不平衡数据分类方法,包括:
步骤一,在原始学习样本集中的多数类样本集中抽取若干多数类样本,在原始学习样本集中的少数类样本集中抽取若干少数类样本,利用抽取的多数类样本和少数类样本合成训练集;
其特点是还包括以下步骤:
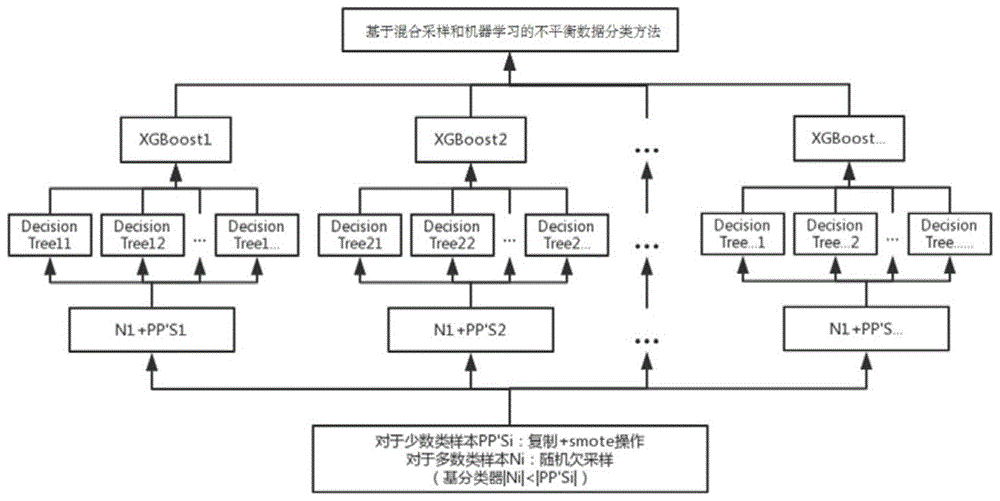
步骤二,针对训练集中的少数类样本集p,复制p生成样本集p',利用p和p'合成合集pp',p和p'的合集pp'中会存在重叠的两份样本,在pp'的基础上采用smote算法生成人工样本集s,同时p、p'和s共同构成新的少数类样本集pp's;
步骤三,针对训练集中的多数类样本集n,不放回地随机欠采样得到t个数据子集ni,其中,每个子集ni的数目为原少数类样本集p数目的m倍,且每个子集ni中样本的数目小于新的少数类样本集pp's中样本的数目,m为大于1的整数,i=1,2,.....,t;也即,新的多数类子集样本ni数目为|ni|=m*|p|,且满足|ni|<|pp's|,t为正整数,且
步骤四,重复执行步骤二t次,得到t个不同的少数类集样本集pp'si,将每个多数类子集ni与对应的少数类样本集pp'si合成新的训练集,得到t个不同的子集;其中,复执行步骤二得到少数类集样本集pp'si,由于步骤二中存在两个随机操作,包括k个最近邻中随机抽取一个样本和后续合成新样本时随机取0到1之间的值,因此,每次获得的样本集都是不同的;
步骤五,对于步骤四中得到的t个不同的子集,利用机器学习方法,分别对应训练生成t个分类器hi;
步骤六,集成t个分类器hi,得到最终的分类器h,利用分类器h完成对不平衡数据集的分类。
作为一种优选方式,所述步骤二中,在pp'的基础上生成s的过程为:
对于pp'中每个样本x,计算x与pp'中除x外其他样本的欧氏距离,获取x的k(k的大小根据需要设定)个最近邻,从k个最近邻中随机选取一个样本o,合成一个新样本x'=x+rand(0,1)*(x-o);rand(0,1)表示在0到1的范围内随机取一值。新的样本集pp's总数|pp's|为|pp'|+|pp'|*n。
作为一种优选方式,训练生成t个xgboosti分类器hi。
作为一种优选方式,所述步骤六中,利用公式
进一步地,所述步骤一中,还包括:将训练集在原始学习样本集中的补集定义为测试集;其中,训练集中少数类样本数目与多数类样本数目之比为p,测试集中少数类样本数目与多数类样本数目之比为q,p=q;在步骤六之后还包括步骤七,用测试集对分类器h进行测试验证。
与现有技术相比,本发明具有以下优点:
(1)对于多数类进行欠采样,对少数类样本进行混合过采样,可以更充分的学习到数据的信息,少数类分类精度高,提高了少数类样本的关注度同时不会过分丢失多数类的信息。
(2)对少数类样本先复制后smote合成的方式,增大了样本的范围且增加了数据的真实分布的比重,减小了过拟合和过度泛化的可能。
(3)以xgboost分类器为基分类器,具有梯度增强、决策树、正则化及并行处理的共同特点,因此训练效果好,不易过拟合,且训练速度快。
附图说明
图1为本发明流程图。
图2为本发明的结构框图。
具体实施方式
如图1和图2所示,基于混合采样和机器学习的不平衡数据分类方法包括以下步骤:
步骤一,在原始学习样本集中的多数类样本集中抽取若干多数类样本,在原始学习样本集中的少数类样本集中抽取若干少数类样本,利用抽取的多数类样本和少数类样本合成训练集;将训练集在原始学习样本集中的补集定义为测试集;其中,训练集中少数类样本数目与多数类样本数目之比为p,测试集中少数类样本数目与多数类样本数目之比为q,p=q。
步骤二,针对训练集中的少数类样本集p,复制p生成样本集p',利用p和p'合成合集pp',p和p'的合集pp'中会存在重叠的两份样本,在pp'的基础上采用smote算法生成人工样本集s,同时p、p'和s共同构成新的少数类样本集pp's。
其中,在pp'的基础上生成s的过程为:
对于pp'中每个样本x,计算x与pp'中除x外其他样本的欧氏距离,获取x的k个最近邻,从k个最近邻中随机选取一个样本o,合成一个新样本x'=x+rand(0,1)*(x-o);rand(0,1)表示在0到1的范围内随机取一值。新的样本集pp's总数|pp's|为|pp'|+|pp'|*n。
步骤三,针对训练集中的多数类样本集n,不放回地随机欠采样得到t个数据子集ni,其中,每个子集ni的数目为原少数类样本集p数目的m倍,且每个子集ni中样本的数目小于新的少数类样本集pp's中样本的数目,m为大于1的整数,i=1,2,.....,t;也即,新的多数类子集样本ni数目为|ni|=m*|p|,且满足|ni|<|pp's|,t为正整数,且
步骤四,重复执行步骤二t次,得到t个不同的少数类集样本集pp'si,将每个多数类子集ni与对应的少数类样本集pp'si合成新的训练集,得到t个不同的子集;其中,复执行步骤二得到少数类集样本集pp'si,由于步骤二中存在两个随机操作,包括k个最近邻中随机抽取一个样本和后续合成新样本时随机取0到1之间的值,因此,每次获得的样本集都是不同的。
步骤五,对于步骤四中得到的t个不同的子集,利用机器学习方法,分别对应训练生成t个xgboosti分类器hi。
步骤六,利用公式
步骤七,用测试集对分类器h进行测试验证。
将集成算法adaboost,xgboost,不平衡算法easyensemble,smotebagging算法与本发明算法分别进行测试,最后比较评价指标。因为这里针对的是不平衡集,采用recall(召回率),specifity(特异度)来进行验证,precision(精确度)不考虑是因为在不平衡数据里,少数类远远少于多数类,例如少数类与多数类数量比为1:99,即使把全部的样本全部预测为多数类,那么也达到了99%的精确度,不能说明分类器的好坏。
具体实例如下:
本发明的实验配置为:64位windows10,python3.6,内存16g,cpu为i5-6500。
本实例采用的原始学习样本集为湘雅医学院提供的数据集,包括54214名曾去检查过的病人(可能患有各种疾病),其中有802名确诊为主动脉夹层患者,其他53412名为非主动脉夹层患者,不平衡比例约为1:67。标记802个主动脉夹层样本为1,其他53412名为非主动脉夹层样本为0。本发明从此实验数据集中提取到76个指标作为特征,包括红细胞计数,白细胞计数,d-二聚体等。
本发明方法按图1所示流程的仿真实验步骤如下:
步骤一,实验将所选取的每个数据集随机分为样本数相等的7份,运用7折交叉验证,即每一次不重复地使用1份数据当作测试数据集,另外6份作为训练数据集,以7折的平均实验结果作为参考。因此,对原始学习样本集中的多数类样本和少数类样本,分别分成等量的7份数据集,各取其中一份合在一起作为测试集,两类样本剩余的六份合成训练集,保证训练集和测试集的两类样本比例相同,更换测试集和训练集进行7次交叉实验。
步骤二、针对训练集中的少数类样本p,含有802个样本,先将样本集p复制一倍,得到集合p',p和p'的合集pp'样本数为2*|p|,其中会出现重叠的两份样本。对于pp'中每个样本x,计算x与pp'中其他样本的欧氏距离,获取x的5个最近邻,从5个最近邻随机选取一个样本o,合成一个新样本x'=x+rand(0,1)*(x-o),重复2次得到含有2个人工合成样本的集合s,新的样本集pp's总数|pp's|为|pp'|+|pp'|*2,即802*2*3个样本数;rand函数值由python提供函数随机设置。
步骤三、针对训练集中的多数类样本n,含有53412个样本,不放回地随机欠采样得到33个数据子集ni(i=1,2,.....,30),设定每个子集ni的数目为原少数类样本p数目的2倍,新的多数类子集样本ni数目为|ni|=2*|p|,即有802*2个样本,且满足|ni|<|pp's|。
步骤四、重复执行步骤二t次,得到t个不同的少数类集样本集pp'si,将每个多数类子集ni与对应的少数类样本集pp'si合成新的训练集,得到33个不同的子集;其中,复执行步骤二得到少数类集样本集pp'si,由于步骤二中存在两个随机操作,包括5个近邻中随机抽取一个样本和后续合成新样本时随机取0到1之间的值,因此,每次获得样本集都是不同的。
步骤五、对于33个不同的子集,训练生成33个xgboosti分类器hi。
步骤六,利用公式
步骤七,用测试集对分类器h进行测试验证。
实验中,与本发明方法对比的4种方法分别为:adaboost,xgboost,easyensemble,smotebagging。本发明方法与另外4种方法均在python上进行仿真实验,经过不断调参后取了每个方法最好的结果如下表1所示。
表15种方法的实验结果对比
从表1的实验结果可以看出,本发明方法在给出的不平衡度为1:65的数据集上表现出的性能皆优于其他4种方法;其召回率和特异度均高于其他算法,并且时间开销一般,因此其综合性能在不平衡数据集的分类中要优于其他算法,对于主动脉夹层的筛查具有更高的可应用性。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是局限性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!