一种基于情感词嵌入的细粒度情绪分析改进方法与流程
本发明属于中文文本情绪分析技术领域,特别涉及一种针对中文短文本如微博、网络评论的基于情感词嵌入的细粒度情绪分析改进方法细粒度情绪分析方法。
背景技术:
互联网发展如此迅猛,每天有数百万人使用社交网络,如微博、贴吧等在线平台表达他们对产品、服务、新闻、事件等的看法。分析用户所表达的意见或者观点对营销专业人员和研究人员来说非常重要。由于微博在中国社会的普及,微博文本的情绪分析变得越来越重要。自2013年起,中国计算机学会(简称ccf)在第二届自然语言处理与中文计算会议(简称nlpcc)中专门设立了中文微博情感分类评测任务,从此之后吸引了国内外众多研究人员和研究机构参与评测。2018年该会议已成功举办七届,为中文微博情绪分析做出了巨大贡献。
微博与电影评论等传统长文本的情绪分析有若干不同之处。首先,它不超过140个中文单词。内容极为的简短但是所包含的信息非常丰富。其次,中文在某种程度上与英语有很大的不同,如语法或句子结构,所以英文文本如twitter的情绪分析研究成果难以适用于中文微博分析。第三,微博中使用的词比正式文本更加随意。例如,网络流行词有“麻麻”、“跪了”。“跪了”原本指传统上没有情感极性的行为,但现在它等于一种令人沮丧的情绪。第四,这些网络流行词中的一些词由于其非正式性,甚至具有不同的意义和不同的情绪。
情绪分析是指从包含人们意见的潜在信息的原始数据集中识别主观信息的过程,通常包括对文本进行积极、消极、中性的识别。专利200910219161.9根据不同主题文本的语言表达方式估计主题语言模型,计算待处理文本的语言模型与正负情感模型的距离,选取距离最近的情感模型的情感倾向赋予该文本。专利201210088366.x基于正负情感词典判断所有包含主题词的句子的极性,计算结果集合中正面句子极性之和及负面句子极性之和,从而得出整条微博的情感倾向性。专利201310036034.1利用对象属性与情感词之间的关联信息以及情感词与修饰词之间的关系实现细粒度情感强度量化的统计和计算。专利201410178056.6基于细粒度情感词典,通过对语句结果关系进行判断,将语句拆分为简单句,计算句子情感值从而进行细粒度情感分析。专利201810569997.0对文本中包含的每一个语句构建词嵌入,将构建的每一个词嵌入输入至基于长短记忆网络模型训练得到的文本情感分析模型中,以输出每一个所述词嵌入的情感标签,作为对应于每一个语句的情感标签。
目前已有的情绪分析技术,主要分为基于规则的分析、基于无监督的分类和基于有监督的分类。相比较而言最后一类表现较好。基于监督分类技术的有效性依赖于分类任务中使用的特征。常用的特征如词袋(bow)、词汇和句法特征。词袋特征及其加权方案广泛用于自然语言处理,进而提供文档的简化表示。但是这些方法在情感分析任务中存在一定的局限性:词嵌入通过学习词的低维连续值向量表示实现许多nlp任务,然而传统的词嵌入方法所得到的词表示仅包含文本语料中的语义信息,未考虑文本语料中的情绪信息。而词语之间的情绪信息对于情绪分析来说同样至关重要。因此,本发明提出了一种基于情感词嵌入的细粒度情绪分析改进方法,将文本语料的语义信息与情绪信息相结合,共同构建情感词嵌入作为有监督分类器的输入,能够进行情绪的更加细粒度划分,并提高情绪分析的精度。
技术实现要素:
本发明的目的在于克服上述技术存在的不足,提供一种基于情感词嵌入进行细粒度的情绪分析方法,该方法不仅关注情感的褒义、贬义、中性等极性,而且关注情绪的细粒度类别,如“好、乐、哀、怒、惧、恶、惊”,这是一个更具挑战性的任务,可更好的支撑相关的应用研究,例如:通过对网络上各种信息,特别是主观性文本的倾向性分析可以更好地理解用户的消费习惯、用户对商品的评论分析等。
为了实现上述技术目的,本发明的技术方案是,
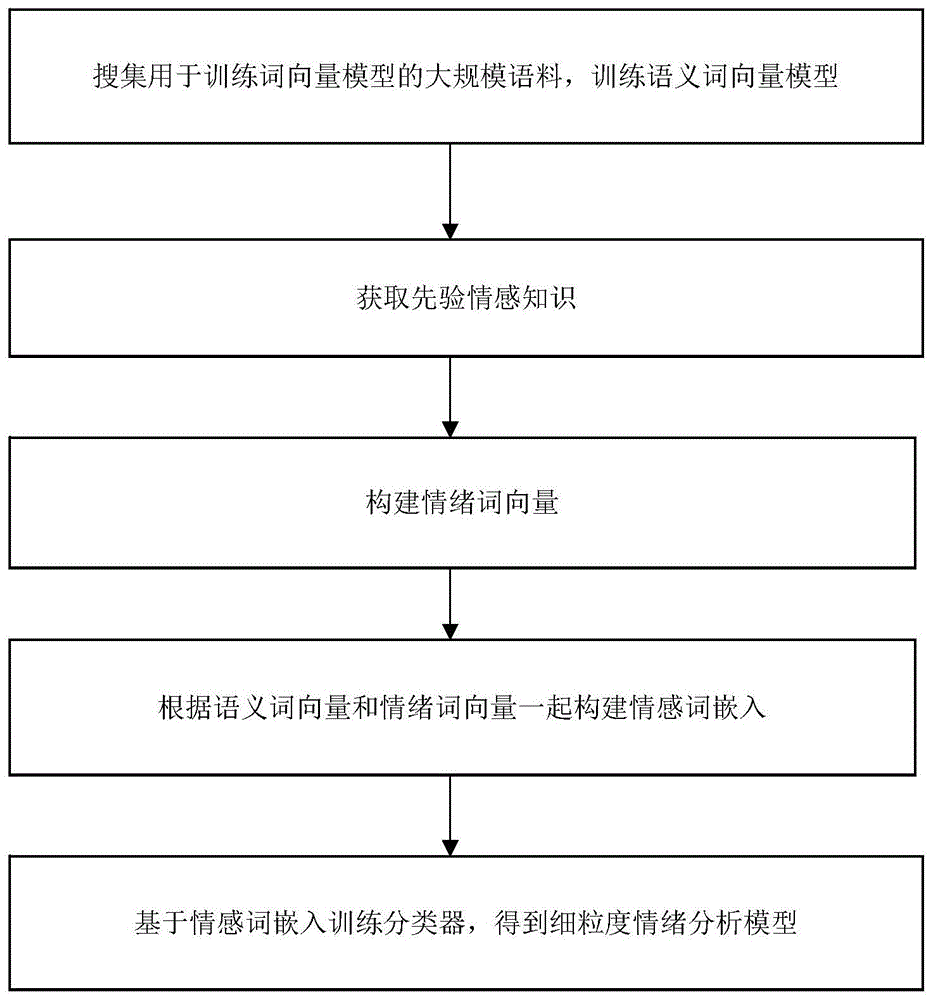
一种基于情感词嵌入的细粒度情绪分析改进方法,包括以下步骤:
步骤一:文本数据集的获取、人工标注及预处理:首先,获取用于情绪分析的文本数据集作为情绪分析模型的训练数据集,并对文本数据集中的单个句子进行人工标注;然后,对文本数据集进行预处理,预处理后的文本数据集被表示为一个个单词的集合;
步骤二:计算文本数据集中每个单词对应的语义词向量:搜集用于训练词向量模型的大规模语料,并利用词向量工具对该语料进行训练得到词向量模型,然后利用该模型对步骤一得到的集合中的每个单词进行词向量表示,进而得到每个单词对应的一个语义词向量;
步骤三:获取情感词集合:搜集中文情感词典,并基于步骤二中得到的语义词向量,逐一筛选符合条件的情感词,得到筛选后的情感词集合;
步骤四:计算训练数据集中每个单词对应的一组情感词组:基于步骤三中得到的情感词集合,为步骤一中训练数据集的每个单词选取一组对应的情感词组,该情感词组在语义上和情感极性上都与该单词最为相似;
步骤五:计算训练数据集中每个单词对应的情绪词向量:基于步骤四中得到的每个单词对应的一组情感词组,对该情感词组的语义词向量进行修正,并在该修正后的语义词向量基础上,构建情绪词向量;
步骤六:构建训练数据集中每个单词对应的情感词嵌入:基于步骤二中单词对应的语义词向量,以及步骤五中单词对应的情绪词向量,构建该单词的情感词嵌入,最后得到训练数据集的情感词嵌入;
步骤七:训练分类器得到细粒度情绪分析模型:将训练数据集的情感词嵌入作为分类器的输入,训练分类器,得到细粒度情绪分析模型。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤一,具体为采用如下步骤:
a、通过爬虫采集微博数据作为文本数据集;
b、人工对所有文本数据集中的句子进行情绪标注,标注的情绪标签分为七大类:“好、乐、哀、怒、惧、恶、惊”,标注后每个句子对应一个情绪标签,用于后续分类器的训练和测试集的精度验证;
c、对文本数据集进行包括文本分词、删除特殊符号和停用词在内的预处理,其中文本分词指的是将文本数据集中的句子切分成一个个单独的词。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤二,具体为采用如下步骤:
a、首先,搜集大规模中文语料作为训练词向量模型的语料,并且进行数据预处理,预处理过程同步骤一中的预处理;
b、然后,使用python的gensim软件包,利用word2vec工具对经过预处理后的大规模语料进行训练,得到词向量模型;
c、接下来,利用该词向量模型对步骤一中得到的每个单词进行词向量表示,并将该词向量作为单词的语义词向量,使单词集合被表示为一个语义词向量集合,每个单词对应一个语义词向量。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤三,具体为采用如下步骤:
a、首先,搜集中文情感词典;
b、然后,对该情感词典中的情感词进行逐一筛选,若某个情感词经过语义词向量表示后,在步骤二中得到的语义词向量集合中找不到对应的语义词向量,则将其删除,得到经过筛选后的情感词集合。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤四,具体为采用如下步骤:
a、语义筛选:计算步骤一中训练数据集的每个单词与步骤三中的所有情感词的余弦相似度,通过设定相似度阈值,高于该阈值的情感词均归为一组,作为与该单词对应的语义上最为相似的一组情感词组;
b、情感筛选:在步骤a得到的与该单词对应的语义上最为相似的一组情感词组中,进一步进行情感极性的筛选,此处所述情感极性是指褒义、贬义、中性三大极性,每个单词在情感词典中都有其对应的极性,情感极性的筛选是查找这组情感词组中的每个情感词在情感词典中的极性是否与该单词一致,删除语义上一致但极性上不一致的情感词,保留语义和极性上都一致的情感词。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤五,具体为采用如下步骤:
a、首先,基于步骤二中得到的词向量模型,对步骤四中得到的情感词组中的每个情感词进行语义词向量表示;
b、由于在情感上完全相反的两个单词可能在词向量空间中反而具有相当高的余弦相似度,故对情感词组的语义词向量进行修正:
对于某单词和对应的一组情感词组,其情感词组的语义词向量的修正步骤如下:基于该情感词组的语义词向量构建表示相似情感词组的语义词向量与经过修正后的语义词向量之间的距离之和的目标函数,然后,通过最小化目标函数,求解情感词组经过修正后的语义词向量,进一步地具体如下:
设v={v(1),v(2)…,v(n)}为该情感词组对应的语义词向量空间,x为该情感词组经过修正后的语义词向量,目标函数
其中,n表示情感词组中情感词的个数,vj(i)表示第i个情感词对应的语义词向量的第j个维度,xj表示向量x的第j个维度,k为语义词向量的维度;
求解目标函数:在此选择拟牛顿法进行求解,该方法使得修正后的词向量距离修正前的词向量以及相似情感词的词向量之间的距离之和最小;
c、最后,在该修正后的语义词向量空间基础上,构建情绪词向量,具体步骤如下:对修正后的语义词向量进行加权平均,构造该词语的情绪词向量:
以x={x(1),x(2),…x(m)}为修正后的语义词向量,其中x(i)(1<i<m)表示第i个情感词对应的语义词向量,αi为给每个语义词向量赋予的权重,权重根据其情感词的情感强度以及与目标单词的相似度进行赋值,则为目标单词t构建的情绪词向量et为:
其中,m为词向量个数。上述步骤在具体计算过程中,还需对αi进行归一化处理,用归一化后的向量权重α′i参与运算,标准化公式如下:
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤六,具体为采用如下步骤:
当语义词向量与情绪词向量具有不同的维度时,则将语义词向量与情绪词向量直接连接进行结合;
当语义词向量与情绪词向量具有相同的维度时,则将语义词向量与情绪词向量相加进行结合。
所述的一种基于情感词嵌入的细粒度情绪分析改进方法,所述的步骤七,具体为采用如下步骤:
对训练数据集中的所有单词构建情感词嵌入,将构建好的情感词嵌入输入常用分类器进行训练,通过训练分类器得到情绪分析模型。
本发明的技术效果在于,(1)目前已有的情绪分析方法主要将情绪分为两类:正向和负向,在情绪类别的划分方面属于粗粒度的文本情绪分析。为了进一步挖掘文本中的情绪信息,本发明对中文微博文本做进一步的细粒度情绪分析。(2)本发明提出的方法是对词向量在情感领域的扩展和应用。对word2vec神经网络模型的神经网络结构进行改进后,将原始只包含语义的词向量作为词嵌入的前一部分,本发明中构建的情绪词向量作为词嵌入的后一部分,并提出了两种构建情感词嵌入的方法,用于文本的细粒度情绪分类。本发明可以避免原始词向量语义近似但情感差距较大的缺陷,同时又能够从大量未标注的语料中学习词的语义信息,因此可以取得较好的情绪分类结果。
附图说明
图1为本发明的语义词向量修正流程图;
图2为基于情感词嵌入进行细粒度情绪分类流程图。
具体实施方式
下面结合附图和具体实施例对本发明的技术方案作进一步详细地说明。
本发明包括如下步骤:
步骤一:文本数据集的获取、人工标注及预处理。首先,获取用于情绪分析的文本数据集,并对文本数据集中的单个句子进行人工标注。然后,对文本数据集进行预处理,预处理后的文本数据集被表示为一个个单词的集合。具体为采用如下步骤:
a、通过爬虫采集微博数据作为文本数据集;
b、人工对所有文本数据集中的句子进行情绪标注,标注的情绪标签分为七大类:“好、乐、哀、怒、惧、恶、惊”。标注后每个句子对应一个情绪标签,用于后续分类器的训练和测试集的精度验证;
c、对文本数据集进行包括文本分词、删除特殊符号和停用词在内的预处理,其中文本分词指的是将文本数据集中的句子切分成一个个单独的词。采用的分词工具为中科院分词工具ictcla2018。由于网络文本数据中包含很多未知符号和表情,因此在处理的过程中将“@#!$&”等特殊符号删除,并去掉对于情绪分析任务无用的停用词,比如“了”、“呢”等。
步骤二:计算文本数据集中每个单词对应的语义词向量。搜集用于训练词向量模型的大规模语料,并利用词向量工具对该语料进行训练得到词向量模型,然后利用该模型对步骤一得到的集合中的每个单词进行词向量表示,进而得到每个单词对应的一个语义词向量。具体为采用如下步骤:
a、首先,搜集大规模中文语料作为训练词向量模型的语料,语料规模越大越好。对其进行数据预处理,预处理过程同步骤一中的预处理;
b、然后,使用python的gensim软件包,利用word2vec工具对经过预处理后的大规模语料进行训练,得到词向量模型。其中gensim是一款开源的第三方python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括tf-idf、lsa、lda和word2vec在内的多种主题模型算法。word2vec是google开源的一款用于词向量计算的工具。word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练,该工具得到的训练结果——词向量,可以很好地度量词与词之间的相似性;
c、接下来,利用该词向量模型对步骤一中得到的每个单词进行词向量表示。并将该词向量作为单词的语义词向量,使单词集合被表示为一个语义词向量集合,每个单词对应一个语义词向量。
步骤三:获取情感词集合。搜集中文情感词典,并基于步骤二中得到的语义词向量,逐一筛选符合条件的情感词,得到筛选后的情感词集合。具体为采用如下步骤:
a、首先,本发明使用的中文情感词典为发布的公开情感词典,由大连理工大学信息检索研究室整理和标注的一个中文情感词典。词典中的情绪共分为7大类:“好、乐、哀、怒、惧、恶、惊”,共含有情感词27466个,情感强度分为:1,3,5,7,9这5档,9表示强度最大,1为强度最小。该词典从不同角度描述一个中文单词或者短语,包括单词的词性种类、情感类别、情感强度及极性等信息;
情感词典中,一般的格式如表1所示。情绪分类举例如表2所示:
表1情感词典格式举例
表2情绪分类举例
b、然后,对该情感词典中的情感词进行逐一筛选,若某个情感词经过语义词向量表示后,在步骤二中得到的语义词向量集合中找不到对应的语义词向量,则将其删除,得到经过筛选后的情感词集合。
步骤四:计算训练数据集中每个单词对应的一组情感词组。基于步骤三中得到的情感词集合,为步骤一中训练数据集的每个单词选取一组对应的情感词组,该情感词组在语义上和情感极性上都与该单词最为相似。具体为采用如下步骤:
a、语义筛选:计算步骤一中训练数据集的每个单词与步骤三中的所有情感词的相似度,通过设定相似度阈值,高于该阈值的情感词均归为一组,作为与该单词对应的语义上最为相似的一组情感词组。具体如下:相似度计算公式采用余弦相似度,设定相似度阈值选择与该单词最为相似的一组情感词,阈值选择一般为0.8或0.9,阈值越大则该情感词在语义上与该单词越相近。公式如下:
cos(wi,wj)=consine(wi,wj)
式中wi,wj为词语对应的词向量,consine(wi,wj)为两个向量的余弦相似度;
b、情感筛选:在步骤a得到的与该单词对应的语义上最为相似的一组情感词组中,进一步进行情感极性的筛选。此处所述情感极性是指褒义、贬义、中性三大极性,每个单词在情感词典中都有其对应的极性。情感极性的筛选是查找这组情感词组中的每个情感词在情感词典中的极性是否与该单词一致,删除语义上一致但极性上不一致的情感词,保留语义和极性上都一致的情感词,如“好吃”和“难吃”,因为通常出现在相同的上下文中,所以词嵌入模型捕捉到的语义信息相同,即词向量语义距离往往非常接近,但是情感极性完全相反。
步骤五:计算训练数据集中每个单词对应的情绪词向量。基于步骤四中得到的每个单词对应的一组情感词组,对该情感词组的语义词向量进行修正,并在该修正后的语义词向量基础上,构建情绪词向量。具体为采用如下步骤:
a、首先,基于步骤二中得到的词向量模型,对步骤四中得到的情感词组中的每个情感词进行语义词向量表示;
b、然后,对情感词组的语义词向量进行修正。需要进行修正的原因如下:由于现有的词向量模型存在一些缺点:在情感上完全相反的两个单词可能在词向量空间中反而具有相当高的余弦相似度,导致得到的语义词向量可能存在一定的误差,因此需要进行修正。
以某个单词和其对应的一组情感词组为例,其情感词组的语义词向量的修正步骤如下:基于该情感词组的语义词向量构建表示相似情感词组的语义词向量与经过修正后的语义词向量之间的距离之和的目标函数。然后,通过最小化目标函数,求解情感词组经过修正后的语义词向量。进一步地具体如下:
设v={v(1),v(2)…,v(n)}为该情感词组对应的语义词向量空间,x为该情感词组经过修正后的语义词向量,目标函数
其中,n表示情感词组中情感词的个数,vj(i)表示第i个情感词对应的语义词向量的第j个维度,xj表示向量x的第j个维度,k为语义词向量的维度。
求解目标函数:在此选择拟牛顿法进行求解。拟牛顿法在求解无约束极小化问题方面,是一种常用且高效的方法。该方法使得修正后的词向量距离修正前的词向量以及相似情感词的词向量之间的距离之和最小。
c、最后,在该修正后的语义词向量空间基础上,构建情绪词向量。具体步骤如下:对修正后的语义词向量进行加权平均,构造该词语的情绪词向量:
假设x={x(1),x(2),…x(m)}为修正后的语义词向量,其中x(i)(1<i<m)表示第i个情感词对应的语义词向量,αi为给每个语义词向量赋予的权重,权重根据其情感词的情感强度以及与目标单词的相似度进行赋值,则为目标单词t构建的情绪词向量et为:
其中,m为词向量个数。上述步骤在具体计算过程中,还需对αi进行归一化处理,用归一化后的向量权重α′i参与运算,标准化公式如下:
步骤六:构建训练数据集中每个单词对应的情感词嵌入。基于步骤二中单词对应的语义词向量,以及步骤五中单词对应的情绪词向量,构建该单词的情感词嵌入。具体为采用如下步骤:
本发明提出了两种构建情感词嵌入的方法,分别适用于不同的情形。
方法一:将语义词向量与情绪词向量直接连接进行结合,形成情感词嵌入。具体方法为:将给定单词的语义词向量和情绪词向量直接进行连接。该方法适用的情形:语义词向量与情绪词向量具有不同的维度。
其中xnew为混合词向量,xe为情感词向量,xs为语义词向量。
由于本发明采用余弦相似度来计算两个向量之间的相似性,对于余弦相似度来说,关键因素是点积。假设
从点积结果来看,余弦相似性由矢量分量点积的线性组合来确定,因此将两个词语之间的语义关系和情绪关系一起作为特征进行区分,其中x1·y1分代表语义关系特征的区分,x2·y2代表情绪关系特征的区分;
方法二:将语义词向量与情绪词向量相加进行结合,形成情感词嵌入。具体方法为:将语义词向量与情绪词向量进行累加。该方法适用的情形:语义词向量与情绪词向量具有相同的维度。
xnew=xe+xs
对于两个向量的直接叠加,从向量的点积结果来看是将两个向量的特征分量进行组合来进行特征区分,使得不同情感特征之间的区分度提高。
步骤七:训练分类器得到细粒度情绪分析模型。将情感词嵌入作为分类器的输入,训练分类器,得到情绪分析模型。具体为采用如下步骤:
对训练数据集中的所有单词构建情感词嵌入,将构建好的情感词嵌入输入常用分类器进行训练,常用的分类器有supportvectormachine(svm)、逻辑回归、神经网络等,通过训练分类器得到情绪分析模型。
下面给出现有技术作为对比例,并给出本申请的具体实施例。
对比例1:
中国专利201810569997.0在构建神经网络模型的输入时,采用当前流行的词嵌入方法,通过在大型语料库中使用无监督方法学习单词的低维向量来进行表示。但该专利中的词嵌入方法仅考虑来自文档的统计信息,而仅考虑统计信息如两个单词的共现规律,并不能充分的学习到这两个单词的情绪信息。对于一个给定的情感分析任务来说,其它辅助信息如语义信息、情绪信息等等同样非常重要,而且这些辅助信息已被证明有助于提高这种任务的精度。
对比例2:
中国专利201410178056.6基于细粒度情感词典,通过对语句结果关系进行判断,将语句拆分为简单句,从而计算句子的情感值来进行细粒度情感分析。该专利是基于规则的文本情感分析,其句子的情感倾向是通过计算句内情感词的情感倾向得来。该专利未考虑句子中的语义信息,而对于包含复杂语义的句子,仅仅通过分析句子中的情感词的极性无法准确判断该句子的情感极性。基于规则的情感分析方法无法适用于数据集中所有的句子,而且人工构造规则的方法在面对大规模的微博文本时过于复杂,耗费时间太长。
实施例1:
本实施例将本专利提出的基于情感词嵌入进行情绪分析的方法应用于网络购物平台评论数据。
步骤一:文本数据集的获取、人工标注及预处理。具体为采用如下步骤:
a、收集用于情感分析任务的网络评论数据;
b、人工对所有网络评论数据中的句子进行情绪标注,本专利将其情感标签分为三分类的情感标签:“积极、消极、中立”,标注后每个句子对应一个情绪标签;
c、对文本数据集进行包括文本分词、删除特殊符号和停用词在内的预处理,其中文本分词指的是将文本数据集中的句子切分成一个个单独的词。采用的分词工具为中科院分词工具ictcla2018。由于网络文本数据中包含很多未知符号和表情,因此在处理的过程中将“@#!$&”等特殊符号删除,并去掉对于情绪分析任务无用的停用词,比如“了”、“呢”等。
步骤二:计算文本数据集中每个单词对应的语义词向量。搜集用于训练词向量模型的大规模语料,并利用词向量工具对该语料进行训练得到词向量模型,然后利用该模型对上述单词集合中的每个单词进行词向量表示,进而得到每个单词对应的一个语义词向量。具体为采用如下步骤:
a、首先,搜集大规模中文语料作为训练词向量模型的语料,语料规模越大越好。此处搜集的大规模语料为从复旦和搜狗实验室以及维基百科下载的开源中文语料,规模为500万条左右。对其进行数据预处理,预处理过程同步骤一中的预处理;
b、然后,使用python的gensim软件包,利用word2vec工具对经过预处理后的大规模语料进行训练,得到词向量模型;
c、接下来,利用该词向量模型对步骤一中得到的每个单词进行词向量表示。并将该词向量作为单词的语义词向量,使单词集合被表示为一个语义词向量集合,每个单词对应一个语义词向量。
步骤三:获取情感词集合。搜集中文情感词典,并基于步骤二中得到的语义词向量,逐一筛选符合条件的情感词,得到筛选后的情感词集合。具体为采用如下步骤:
a、首先,使用的中文情感词典为从大连理工大学信息检索研究室发布的公开情感词典。该情感词典从不同角度描述一个中文单词或者短语,包括单词的词性种类、情感类别、情感强度及情感极性等信息;
b、然后,对该情感词典中的情感词进行逐一筛选,若某个情感词经过语义词向量表示后,在步骤二中得到的语义词向量集合中找不到对应的语义词向量,则将其删除,得到经过筛选后的情感词集合。
步骤四:计算训练数据集中每个单词对应的一组情感词组。基于步骤三中得到的情感词集合,为步骤一中训练数据集的每个单词选取一组对应的情感词组,该情感词组在语义上和情感极性上都与该单词最为相似。具体为采用如下步骤:
a、语义筛选:计算步骤一中训练数据集的每个单词与步骤三中的所有情感词的余弦相似度,通过设定相似度阈值,高于该阈值的情感词均归为一组,作为与该单词对应的语义上最为相似的一组情感词组。具体如下:通过设定相似度阈值选择与该单词最为相似的一组情感词,阈值选择一般为0.8或0.9,阈值越大则该情感词在语义上与该单词越相近。余弦相似度的公式如下:
cos(wi,wj)=consine(wi,wj)
式中wi,wj为词语对应的词向量,consine(wi,wj)为两个向量的余弦相似度;
b、情感筛选:在步骤a得到的与该单词对应的语义上最为相似的一组情感词组中,进一步进行情感极性的筛选。此处所述情感极性是指褒义、贬义、中性三大极性,每个单词在情感词典中都有其对应的极性。情感极性的筛选是查找这组情感词组中的每个情感词在情感词典中的极性是否与该单词一致,删除语义上一致但极性上不一致的情感词,保留语义和极性上都一致的情感词。
步骤五:计算训练数据集中每个单词对应的情绪词向量。基于步骤四中得到的每个单词对应的一组情感词组,对该情感词组的语义词向量进行修正,并在该修正后的语义词向量基础上,构建情绪词向量。具体为采用如下步骤:
a、首先,基于步骤二中得到的词向量模型,对步骤四中得到的情感词组中的每个情感词进行语义词向量表示。
b、然后,对情感词组的语义词向量进行修正。需要进行修正的原因如下:由于现有的词向量模型存在一些缺点:在情感上完全相反的两个单词可能在词向量空间中反而具有相当高的余弦相似度,导致得到的语义词向量可能存在一定的误差,因此需要进行修正。
以某个单词和其对应的一组情感词组为例,其情感词组的语义词向量的修正步骤如下:基于该情感词组的语义词向量构建表示相似情感词组的语义词向量与经过修正后的语义词向量之间的距离之和的目标函数。然后,通过最小化目标函数,求解情感词组经过修正后的语义词向量。进一步地具体如下:
设v={v(1),v(2)…,v(n)}为该情感词组对应的语义词向量空间,x为该情感词组经过修正后的语义词向量,目标函数
其中,n表示情感词组中情感词的个数,vj(i)表示第i个情感词对应的语义词向量的第j个维度,xj表示向量x的第j个维度,k为语义词向量的维度。
求解目标函数:在此选择拟牛顿法进行求解。拟牛顿法在求解无约束极小化问题方面,是一种常用且高效的方法。该方法使得修正后的词向量距离修正前的词向量以及相似情感词的词向量之间的距离之和最小。
c、最后,在该修正后的语义词向量空间基础上,构建情绪词向量。具体步骤如下:对修正后的语义词向量进行加权平均,构造该词语的情绪词向量:
假设x={x(1),x(2),…x(m)}为修正后的语义词向量,其中x(i)(1<i<m)表示第i个情感词对应的语义词向量,αi为给每个语义词向量赋予的权重,权重根据其情感词的情感强度以及与目标单词的相似度进行赋值,则为目标单词t构建的情绪词向量et为:
其中,m为词向量个数。上述步骤在具体计算过程中,还需对αi进行归一化处理,用归一化后的向量权重α′i参与运算,标准化公式如下:
例如,对于“好评”一词,通过以上步骤选取出其相似情感词组为:“赞叹不已”、“交口称赞”、“有口皆碑”、“好评如潮”等。这些情感词组即代表了“好评”一词的情感信息,利用这些词语的修正词向量求“好评”一词的情绪词向量。假设“赞叹不已”、“交口称赞”、“有口皆碑”、“好评如潮”一组词的修正词向量为v“赞叹不已”、v“交口称赞”、v“有口皆碑”、v“好评如潮”,对应相似度为
步骤六:构建训练数据集中每个单词对应的情感词嵌入。基于步骤二中单词对应的语义词向量,以及步骤五中单词对应的情绪词向量,构建该单词的情感词嵌入,最后得到训练数据集的情感词嵌入。具体为采用如下步骤:
本发明提出了两种构建情感词嵌入的方法,分别适用于不同的情形。
方法一:将语义词向量与情绪词向量直接连接进行结合,形成情感词嵌入。具体方法为:将给定单词的语义词向量和情绪词向量直接进行连接。该方法适用的情形:语义词向量与情绪词向量具有不同的维度。
其中xnew为混合词向量,xe为情感词向量,xs为语义词向量;
方法二:将语义词向量与情绪词向量相加进行结合,形成情感词嵌入。具体方法为:将语义词向量与情绪词向量进行累加。该方法适用的情形:语义词向量与情绪词向量具有相同的维度:
xnew=xe+xs
步骤七:训练分类器得到细粒度情绪分析模型。将训练数据集的情感词嵌入作为分类器的输入,训练分类器,得到细粒度情绪分析模型。具体为采用如下步骤:
对训练数据集中的所有单词构建情感词嵌入,将构建好的情感词嵌入输入分类器进行训练,常用的分类器有supportvectormachine(svm)、逻辑回归、神经网络等,通过训练分类器得到情绪分析模型。
实施例2:
本实施例将本专利提出的基于情感词嵌入进行情绪分析的方法应用于微博文本数据。
步骤一:文本数据集的获取、人工标注及预处理。具体为采用如下步骤:
a、收集用于情感分析任务的微博数据;
b、人工对所有网络评论数据中的句子进行情绪标注,本专利将其情感标签分为七分类的情感标签:“好、乐、哀、怒、惧、恶、惊”。标注后每个句子对应一个情绪标签;
c、对文本数据集进行包括文本分词、删除特殊符号和停用词在内的预处理,其中文本分词指的是将文本数据集中的句子切分成一个个单独的词。采用的分词工具为中科院分词工具ictcla2018。由于网络文本数据中包含很多未知符号和表情,因此在处理的过程中将“@#!$&”等特殊符号删除,并去掉对于情绪分析任务无用的停用词,比如“了”、“呢”等。
步骤二:计算文本数据集中每个单词对应的语义词向量。搜集用于训练词向量模型的大规模语料,并利用词向量工具对该语料进行训练得到词向量模型,然后利用该模型对上述单词集合中的每个单词进行词向量表示,进而得到每个单词对应的一个语义词向量。具体为采用如下步骤:
a、首先,搜集大规模中文语料作为训练词向量模型的语料,语料规模越大越好。此处搜集的大规模语料为从复旦和搜狗实验室以及维基百科下载的开源中文语料,规模为500万条左右。对其进行数据预处理,预处理过程同步骤一中的预处理;
b、然后,使用python的gensim软件包,利用word2vec工具对经过预处理后的大规模语料进行训练,得到词向量模型;
c、接下来,利用该词向量模型对步骤一中得到的每个单词进行词向量表示。并将该词向量作为单词的语义词向量,使单词集合被表示为一个语义词向量集合,每个单词对应一个语义词向量。
步骤三:获取情感词集合。搜集中文情感词典,并基于步骤二中得到的语义词向量,逐一筛选符合条件的情感词,得到筛选后的情感词集合。具体为采用如下步骤:
a、首先,使用的中文情感词典为从大连理工大学信息检索研究室发布的公开情感词典。该情感词典从不同角度描述一个中文单词或者短语,包括单词的词性种类、情感类别、情感强度及情感极性等信息;
b、然后,对该情感词典中的情感词进行逐一筛选,若某个情感词经过语义词向量表示后,在步骤二中得到的语义词向量集合中找不到对应的语义词向量,则将其删除,得到经过筛选后的情感词集合。
步骤四:计算训练数据集中每个单词对应的一组情感词组。基于步骤三中得到的情感词集合,为步骤一中训练数据集的每个单词选取一组对应的情感词组,该情感词组在语义上和情感极性上都与该单词最为相似。具体为采用如下步骤:
a、语义筛选:计算步骤一中训练数据集的每个单词与步骤三中的所有情感词的余弦相似度,通过设定相似度阈值,高于该阈值的情感词均归为一组,作为与该单词对应的语义上最为相似的一组情感词组。具体如下:通过设定相似度阈值选择与该单词最为相似的一组情感词,阈值选择一般为0.8或0.9,阈值越大则该情感词在语义上与该单词越相近。余弦相似度的公式如下:
cos(wi,wj)=consine(wi,wj)
式中wi,wj为词语对应的词向量,consine(wi,wj)为两个向量的余弦相似度;
b、情感筛选:在步骤a得到的与该单词对应的语义上最为相似的一组情感词组中,进一步进行情感极性的筛选。此处所述情感极性是指褒义、贬义、中性三大极性,每个单词在情感词典中都有其对应的极性。情感极性的筛选是查找这组情感词组中的每个情感词在情感词典中的极性是否与该单词一致,删除语义上一致但极性上不一致的情感词,保留语义和极性上都一致的情感词。
步骤五:计算训练数据集中每个单词对应的情绪词向量。基于步骤四中得到的每个单词对应的一组情感词组,对该情感词组的语义词向量进行修正,并在该修正后的语义词向量基础上,构建情绪词向量。具体为采用如下步骤:
a、首先,基于步骤二中得到的词向量模型,对步骤四中得到的情感词组中的每个情感词进行语义词向量表示;
b、然后,对情感词组的语义词向量进行修正。需要进行修正的原因如下:由于现有的词向量模型存在一些缺点:在情感上完全相反的两个单词可能在词向量空间中反而具有相当高的余弦相似度,导致得到的语义词向量可能存在一定的误差,因此需要进行修正。
以某个单词和其对应的一组情感词组为例,其情感词组的语义词向量的修正步骤如下:基于该情感词组的语义词向量构建表示相似情感词组的语义词向量与经过修正后的语义词向量之间的距离之和的目标函数。然后,通过最小化目标函数,求解情感词组经过修正后的语义词向量。进一步地具体如下:
设v={v(1),v(2)…,v(n)}为该情感词组对应的语义词向量空间,x为该情感词组经过修正后的语义词向量,目标函数
其中,n表示情感词组中情感词的个数,vj(i)表示第i个情感词对应的语义词向量的第j个维度,xj表示向量x的第j个维度,k为语义词向量的维度。
求解目标函数:在此选择拟牛顿法进行求解。拟牛顿法在求解无约束极小化问题方面,是一种常用且高效的方法。该方法使得修正后的词向量距离修正前的词向量以及相似情感词的词向量之间的距离之和最小。
c、最后,在该修正后的语义词向量空间基础上,构建情绪词向量。具体步骤如下:对修正后的语义词向量进行加权平均,构造该词语的情绪词向量:
假设x={x(1),x(2),…x(m)}为修正后的语义词向量,其中x(i)(1<i<m)表示第i个情感词对应的语义词向量,αi为给每个语义词向量赋予的权重,权重根据其情感词的情感强度以及与目标单词的相似度进行赋值,则为目标单词t构建的情绪词向量et为:
其中,m为词向量个数。上述步骤在具体计算过程中,还需对αi进行归一化处理,用归一化后的向量权重α′i参与运算,标准化公式如下:
例如,对于“高兴”一词,通过以上步骤选取出其相似情感词组为:“愉悦”,“幽默”,“兴高采烈”,“神采飞扬”等。这些情感词组即代表了“高兴”一词的情感信息,利用这些词语的修正词向量求“高兴”一词的情绪词向量。假设“愉悦”,“幽默”,“兴高采烈”,“神采飞扬”一组词的修正词向量为v“愉悦”、v“幽默”、v“兴高采烈”、v“神采飞扬”,对应相似度为
步骤六:构建训练数据集中每个单词对应的情感词嵌入。基于步骤二中单词对应的语义词向量,以及步骤五中单词对应的情绪词向量,构建该单词的情感词嵌入,最后得到训练数据集的情感词嵌入。具体为采用如下步骤:
本发明提出了两种构建情感词嵌入的方法,分别适用于不同的情形。
方法一:将语义词向量与情绪词向量直接连接进行结合,形成情感词嵌入。具体方法为:将给定单词的语义词向量和情绪词向量直接进行连接。该方法适用的情形:语义词向量与情绪词向量具有不同的维度。
其中xnew为混合词向量,xe为情感词向量,xs为语义词向量;
方法二:将语义词向量与情绪词向量相加进行结合,形成情感词嵌入。具体方法为:将语义词向量与情绪词向量进行累加。该方法适用的情形:语义词向量与情绪词向量具有相同的维度:
xnew=xe+xs
步骤七:训练分类器得到细粒度情绪分析模型。将情感词嵌入作为分类器的输入,训练分类器,得到细粒度情绪分析模型。具体为采用如下步骤:
对训练数据集中的所有单词构建情感词嵌入,将构建好的情感词嵌入输入分类器进行训练,常用的分类器有supportvectormachine(svm)、逻辑回归、神经网络等,通过训练分类器得到情绪分析模型。
- 还没有人留言评论。精彩留言会获得点赞!