一种基于位置信息的贝叶斯文本分类方法与流程
本发明涉及自然语言处理应用技术领域,具体的说是一种基于位置信息的贝叶斯文本分类方法。
背景技术:
随着网络信息以及大数据技术的高速发展,主要包括社交媒体(例如twitter,facebook,微博号等)和新闻媒体(例如新浪新闻,今日头条,搜狐新闻等)网站,以及维基百科和百度百科等百科类网站上非结构化/半结构化文本资源,如何对这些数据资源进行清洗,整合,归类,以及价值信息挖掘等等,都离不开自然语言处理(naturallanguageprocessing,nlp)技术的发挥。其中,文本情感分类是一种常用的nlp方法,如何对文本所涉及的情感倾向性进行有效分类,对于文本信息的归类整合具有至关重要的作用。
目前的文本分类(包括情感分类)方法主要包括三大类:贝叶斯方法,支持向量机方法,以及神经网络方法。其中目前的贝叶斯方法主要是基于词袋模型的多项式贝叶斯方法,然而词袋模型没有考虑到词语在文本中的位置信息,在情感分类中,位置信息显得尤为重要,如一些重要的情感词语在句子的前面和后面,对于文本整体的倾向性将会产生重要影响。
基于此,根据贝叶斯方法中词袋模型的缺陷性,本发明提出了一种基于位置函数的改进版词袋模型,利用性能较好的多项式朴素贝叶斯方法进行情感分类。
技术实现要素:
为了解决上述现有技术的问题,本发明提出了一种基于位置函数的改进版词袋模型,利用性能较好的多项式朴素贝叶斯方法进行情感分类。
本发明解决其技术问题所采用的技术方案是:
一种基于位置信息的贝叶斯文本分类方法,所述方法包括:
s1、对词袋模型通过输入转换模块进行转换,所述输入转换模块内设置有位置函数以对词袋模型的位置参数进行转换;
s2、将数据转换的结果通过学习模块进行训练,得到关于位置参数的不同测试结果,选取测试效果最佳的参数模型,所述学习模块内设置有mnb贝叶斯模型;
s3、利用已训练的模型对新入文本语料进行情感类别预测。
进一步地,所述步骤s1中的数据转换的结果包含有情感标签。
进一步地,所述步骤s1中转换的具体过程为:
s101、数据预处理,包括剔除空白行、乱码以及统一格式转换;
s102、存在性特征presence提取,具体为利用tf-idf方法对文本进行特征提取,存在于文本中对应特征值presence为1,反之则为0;
s103、位置特征wt_pos提取,具体为,根据每个特征词在该文本中对应的位置以及预置的位置函数,计算出对应的位置特征权重值;
s104、特征值归并,具体为,将步骤s102和步骤s103中得到的存在性特征值和位置特征值相加得到该特征对应的值value=presence+wt_pos。
更进一步地,所述预置的位置函数为
其中,wt_pos代表某词语对应的权重,n代表该词语所在句子对应的长度,p代表对应的位置(介于1到n之间),λ为模型超级参数,λ经过模型训练后得到。
进一步地,所述步骤s2中训练的过程还包括:利用步骤s1中得到的转换结果作为特征向量空间,每个特征向量对应的标签作为预测类别空间。
与现有技术相比,本发明的有益效果是:
1、本发明通过设置一种基于位置信息的权重计算方法,在不影响模型速度的前提下获得了更好的效果,这对于避免文本中特征词语之间的独立性假设提供了一种合理的方法。
2、本发明中采用位置函数对于特征词的贡献进行量化刻画,同时,超参数λ的设定给予了位置影响函数更多的灵活性,可以根据不同的语料进行不同的参数选择。
附图说明
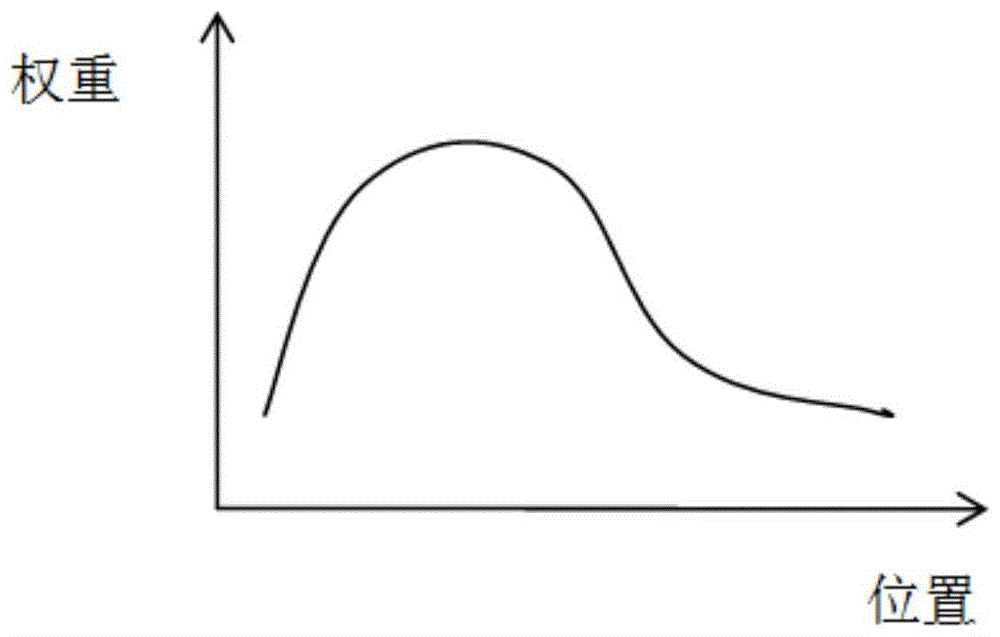
图1为本发明一个实施例背景中的词语权重-位置变化趋势示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例及附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
一种基于位置信息的贝叶斯文本分类方法,所述方法包括:
s1、对词袋模型通过输入转换模块进行转换,所述输入转换模块内设置有位置函数以对词袋模型的位置参数进行转换;
s2、将数据转换的结果通过学习模块进行训练,得到关于位置参数的不同测试结果,选取测试效果最佳的参数模型,所述学习模块内设置有mnb贝叶斯模型;
s3、利用已训练的模型对新入文本语料进行情感类别预测。
具体实施时,所述步骤s1中的数据转换的结果包含有情感标签。
具体实施时,所述步骤s1中转换的具体过程为:
s101、数据预处理,包括剔除空白行、乱码以及统一格式转换;
s102、存在性特征presence提取,具体为利用tf-idf方法对文本进行特征提取,考虑到本方法主要针对短文本,一般一个词语出现的次数都为1,所以特征提取主要是存在性特征,存在于文本中对应特征值presence为1,反之则为0;
s103、位置特征wt_pos提取,具体为,根据每个特征词在该文本中对应的位置以及预置的位置函数,计算出对应的位置特征权重值;
s104、特征值归并,具体为,将步骤s102和步骤s103中得到的存在性特征值和位置特征值相加得到该特征对应的值value=presence+wt_pos。
具体实施时,由于在上述技术方案中,主要是对于位置函数的选取,根据某个词出现位置的先后顺序,确定该词对于所在句子整体情感倾向性的影响程度。如“我和弟弟讨厌住在一个偏远不方便的村庄”,这句话重点在“讨厌”,后面的描述某个地方的文本对于情感的倾向性影响较小,大多文本的描述习惯都与此类似。所以某些词语的位置重要性会随着所在位置一般是先增加,然后再递减的,如图1所示。图1中,随着词语的位置靠近句子的结尾,它所贡献的权重就会越来越低,最后趋向于一个相对较低的水平。假定一个词对于句子情感倾向的判定考虑简单位置函数如线性函数,但是不足以描述上述图例关系,为了更好的描述这种趋势关系,可以考虑基于logit函数的分段函数,得到预置的位置函数为
其中,wt_pos代表某词语对应的权重,n代表该词语所在句子对应的长度,p代表对应的位置(介于1到n之间),λ为模型超级参数,λ经过模型训练后得到。
λ可以先给定一个初始区间[0,5],上式假定将一个句子平均划分成三个部分,第一个部分内的词语的权重根据词语所在位置的增加而增加,中间第二部分对应的权重基本不变,而第三部分中的词语对应的权重将随着位置的后移而逐渐变小,因为一个文本句子的情感倾向性在描述到后面的时候基本上已经确定了。
作为一个较佳的实施例,根据每个特征词在该文本中对应的位置,以及预置的位置函数,计算出对应的位置特征权重值。如“我和弟弟讨厌住在一个偏远不方便的村庄”,对应的unigram特征词为[“我”,“弟弟”,“讨厌”,“住在”,“偏远”,“不方便”,“村庄”],各个词对应的位置p分别从1到7(停用词去掉不计算在内),对应文本长度n为7。其中超参数λ设置多组值(0.1,0.5,1.0,1.5,2.0,3.0,5.0)。
具体实施时,所述步骤s2中训练的过程还包括:利用步骤s1中得到的转换结果作为特征向量空间,每个特征向量对应的标签作为预测类别空间。
本发明提供的模型方法属于一种判别式的分类方法,训练速度较快,针对网络上搜集的五个nlp数据集(不同时间,不同领域的短文本评论数据),经过数据清洗后得到的有效数据基本统计如表1所示:
表1
采用“五折”交叉验证方法得到准确率如表2所示(经过筛选对比,超参数λ=1性能最好):
表2
由上述验证结果可知,基于存在性和位置特征的mnb分类方法在情感预测方面相对较好。
综上可知,贝叶斯文本分类方法一般假设各个特征词语之间相互独立(仅仅是考虑存在性特征),因而没有考虑到位置信息对于情感倾向性的影响。本发明方法引入一种基于位置信息的权重计算方法,在不影响模型速度的前提下获得了更好的效果。这对于避免文本中特征词语之间的独立性假设提供了一种合理的方法:其一,采用位置函数对于特征词的贡献进行量化刻画;其二,超参数λ的设定给予了位置影响函数更多的灵活性,可以根据不同的语料进行不同的参数选择;其三,λ=1对于此情感分类方法的训练说明位置信息有一定的影响,但其峰值为0.5,小于存在性特征的影响。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!