一种基于大数据的油价信息对比系统及方法与流程
本发明属于大数据领域,特别涉及一种基于大数据的油价信息对比系统及方法。
背景技术:
目前,业内常用的现有技术是这样的:
汽车已经成为人们的主要代步工具,而汽油作为汽车的主要燃料,其价格也是有车一族最关心的问题之一,甚至把耗油量作为买车时的影响因素。而石油作为一种不可再生资源决定了其价格的居高不下,油价也成了人们津津乐道的一个话题。油价不断上涨,并且人们对于汽油的需求量也随着汽车的增多而不断增加。所以,选择一个物美价廉的加油站是目前车主很关心的一个问题。
现有的油价信息对比系统不能够结合油价、路况、距离以及耗油量信息,对一定范围内所有加油站进行综合分析,导致用户不能利用信息终端模块发送查询指令并接收油价信息,进行油价对比,对加油站进行综合准确分析,使用户不能做出好的选择。现有技术中对数据进行判断,采用目前的算法,不能对异常的数据快速的进行识别,增加了判断的时间。现有技术中储存器对不平衡数据集进行处理储存,采用传统的算法,不能减少用于训练的数据和降低数据集的规模,延长了模型训练时间,降低了算法的分类效率。现有技术中对搜集的油价数据进行比对,得出油价的分布情况的过程中,采用传统的算法,不能有效的提高提高聚类精度和聚类的稳定性,降低了油价数据的分布质量。
综上所述,现有技术存在的问题是:
(1)现有的油价信息对比系统不能够结合油价、路况、距离以及耗油量信息,对一定范围内所有加油站进行综合分析,导致用户不能利用信息终端模块发送查询指令并接收油价信息,进行油价对比,对加油站进行综合准确分析,使用户不能做出好的选择。
(2)现有技术中对数据进行判断,采用目前的算法,不能对异常的数据快速的进行识别,增加了判断的时间。
(3)现有技术中储存器对不平衡数据集进行处理储存,采用传统的算法,不能减少用于训练的数据和降低数据集的规模,延长了模型训练时间,降低了算法的分类效率。
(4)现有技术中对搜集的油价数据进行比对,得出油价的分布情况的过程中,采用传统的算法,不能有效的提高提高聚类精度和聚类的稳定性,降低了油价数据的分布质量。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于大数据的油价信息对比系统及方法。
本发明是这样实现的,一种基于大数据的油价信息对比方法包括:
步骤一,首先,利用网络、日志、用户网络行为,获取油价的数据信息;
步骤二,根据获取的油价数据信息,进行分析,对采集的油价数据,进行判断是否是真实的油价,判断出不是真实的油价,偏离正常的油价范围,油价无效,不进行处理和储存输出;
步骤三,对搜集的油价数据进行比对,得出油价的分布情况;
步骤四,对采集的油价信息和油价分布数据进行储存,并通过显示屏显示出油价的分布结果。
进一步,利用储存器储存搜集的各种油价数据,进行数据分类储存,对整个数据集在保持分布的情况下进行欠采样处理减少训练的数据,降低数据集的规模,进行数据分类中采用rsboost算法进行不平衡数据分类,具体包括:
给定训练集s={(x1,y1),(x2,y2),…,(xm,ym)},样本xi∈xd是d维特征向量,类标记yi∈{p,n},其中p对应少数类,n对应多数类;
输入:训练集st,基分类模块wl,过采样率m,欠采样率n;
输出:分类模型h(x);
步骤一,初始化数据集中样本的权重:
d1(i)=1/m;
步骤二,根据过采样率m对少数类进行smote过采样处理后,在保持数据分布的情况下以欠采样率n对整个数据集进行随机欠采样处理,生成训练数据集st′,其权重分布为dt′;
步骤三,fort=1tot;
(1)根据训练数据集st′及其权重分布dt′,训练弱分类模块wl,并计算弱假设ht:x×y→[0,1];
(2)计算ht的伪损失:
(3)计算权重更新参数:
ωt=(1/2)·(1+ht(xi,yi)-ht(xi,y));
(4)更新权重分布dt
(5)归一化处理:
步骤四,通过t个弱假设权重投票得到最终分类模型:
进一步,采集油价数据,进行判断是否是真实的油价的过程中,对异常的油价数据进行识别,采用dbscan算法进行识别,具体包括:
步骤一,检查数据中没有被访问的数据对象p且这个数据对象没有处理过,检查它的eps领域neps(p),如果其neps(p)领域内包含的数据对象数目大于或等于minpts,则建立新簇c,并将p及其领域内包含的数据对象并入c中;
步骤二,如果c中有未被处理的数据对象q,检查它的eps领域neps(p),若果其neps(p)领域内包含的数据对象大于等于minpts,将q及其领域内包含的点代入c;
步骤三,重复步骤二,直到c中的对象都被处理过;
步骤四,重复步骤一到步骤三直到所有数据对象都被访问过,且所有的数据对象都标记为某个簇或者被认为是异常数据。
进一步,对搜集的油价数据进行比对,得出油价的分布情况的过程中,采用k-means进行比对,具体包括;
步骤一,基于公式
计算文本相似度,构建矩阵m;
步骤二,基于公式
p={a1,a2,…,an};
其中
步骤三,建立初始中心点集i和删除集,均设置为空集;
步骤四,在集合p中选择最大的一个所对应的文本dj作为一个中心点,并将其加入初始中心点集中,即i=i∪{dj};
步骤五,将矩阵m中与文本dj的文本相似度达到一定值(sim(di,dj)>β)的所有文本放到delete(delete=de-lete∪{ai}),并从集合p中删除,即p=p-{ai};
步骤六,判断是否p=φ、i<k,如果条件为真,则将de-lete中的数据覆盖到p中,即p=delete;
步骤七,除非满足终止条件,即i=k,否则重复执行步骤3到步骤六,最终得到k个初始聚类中心点;
步骤八,根据余弦公式计算每个类簇的中心文本与其他文本的文本相似度,根据相似度大小,将与类簇中心相似度最大的文本放到该簇中;
步骤九,计算
步骤十,除非满足终止条件,否则重复执行步骤八到步骤九。
进一步,对采集的油价信息和油价分布数据进行储存中,预先为数据库中的数据表建立记录缓存,所述记录缓存以数据行为单位进行数据读写;
当接收到客户端的数据查询请求时,在所述记录缓存中查找所请求的数据;
若查找失败,则在所述数据库的页缓存中查找所请求的数据,所述页缓存以页为基本单位进行数据读写;
将在所述记录缓存或所述页缓存中查找到的数据返回至客户端;
向所述记录缓存中添加数据,具体的,将在页缓存中查找到的数据添加至记录缓存中;
进一步,向所述记录缓存中添加数据的过程包括:
在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;
进一步,向所述记录缓存中添加数据的过程进一步包括:在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
进一步,获得与所述待添加数据具有相同数量级的记录数据的访问频率frec、以及与待添加数据具有不同数量级的记录缓存页的访问频率fpage;
判断frec>replace_page_ratio*fpage是否成立,如果是,则选择在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;否则选择在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
其中replace_page_ratio为预设的替换控制参数,replace_page_ratio∈(0,1];
所述与待添加数据具有不同数量级的记录缓存页的访问频率fpage的获得方法为:
fpage=(fmin+fmax)/2*n;
其中,fmin为该记录缓存页中时间戳最早的数据的访问频率,fmax为该记录缓存页中时间戳最晚的数据的访问频率,n为该记录缓存页的数据记录总量。
本发明的另一目的在于提供一种基于大数据的油价信息对比系统,所述的基于大数据的油价信息对比系统设置有:
网络数据收集模块,与大数据处理模块连接,利用互联网搜索对油价进行有针对性的数据抓取,并按照一定的规则和筛选标准进行数据的分类;
日志收集模块,与大数据处理模块连接,利用各个油站上的网站中的销售日志文件进行数据的收集;
用户网路行为数据收集模块,与大数据处理模块连接,根据用户在网络上的油价成交行为,搜集油价的数据;
数据分析模块,与大数据处理模块连接,对搜集的油价数据进行比对,得出油价的分布情况;
数据储存模块,与大数据处理模块连接,利用储存器储存搜集的各种油价数据,进行数据分类储存;
结果输出模块,与大数据处理模块连接,利用显示屏输出油价的分布情况;
大数据处理模块,与网络数据收集模块、日志收集模块、用户网路行为数据收集模块、数据分析模块、数据储存模块、结果输出模块、数据判断模块连接,协调各个模块的工作运行;
数据判断模块,与大数据处理模块连接,对采集的油价数据,进行判断是否是真实的油价。
本发明的另一目的在于提供一种搭载所述基于大数据的油价信息对比系统的基于大数据的油价信息对比平台。
所述数据储存模块利用储存器储存搜集的各种油价数据,进行数据分类储存的过程中,为了增加少数类数据数量来调节不平衡数据集的平衡度,从而平衡数据分布;对整个数据集在保持分布的情况下进行欠采样处理来减少用于训练的数据,降低数据集的规模,从而能够减少模型训练时间,提高算法的分类效率。
综上所述,本发明的优点及积极效果为:
本发明利用信息终端模块,完成油价的查询对比。信息处理模块能够结合油价、路况、距离以及耗油量信息,对一定范围内所有加油站进行综合分析。用户可以利用信息终端模块发送查询指令并接收油价信息;可以有效完成油价对比,对加油站的各个方面进行准确分析,帮助用户做出最佳的选择。
本发明中数据判断模块采集的油价数据,进行判断是否是真实的油价的过程中,为了对异常的油价数据快速的进行识别,减少判断的时间,采用dbscan算法。
本发明中数据储存模块利用储存器储存搜集的各种油价数据,进行数据分类储存的过程中,为了增加少数类数据数量来调节不平衡数据集的平衡度,从而平衡数据分布;对整个数据集在保持分布的情况下进行欠采样处理来减少用于训练的数据,降低数据集的规模,从而能够减少模型训练时间,提高算法的分类效率,采用基于rsboost算法的不平衡数据分类方法。
本发明中数据储存模块利用储存器储存搜集的各种油价数据,进行数据分类储存的过程中,为了增加少数类数据数量来调节不平衡数据集的平衡度,从而平衡数据分布;对整个数据集在保持分布的情况下进行欠采样处理来减少用于训练的数据,降低数据集的规模,从而能够减少模型训练时间,提高算法的分类效率,采用基于rsboost算法的不平衡数据分类方法。
本发明中数据分析模块对搜集的油价数据进行比对,得出油价的分布情况的过程中,为了提高聚类精度和聚类的稳定性,提高油价数据的分布质量,采用k-means。在初始中心选择上必须注意的是要根据平均文本相似度排序情况依次选择相似度最大的文本,只有这样才能保证选出的中心点与数据集中的数据有较大的相关性,能更优地代表一部分数据,保证了中心点分布的均匀。
对采集的油价信息和油价分布数据进行储存中,预先为数据库中的数据表建立记录缓存,所述记录缓存以数据行为单位进行数据读写;
当接收到客户端的数据查询请求时,在所述记录缓存中查找所请求的数据;
若查找失败,则在所述数据库的页缓存中查找所请求的数据,所述页缓存以页为基本单位进行数据读写;
将在所述记录缓存或所述页缓存中查找到的数据返回至客户端;
向所述记录缓存中添加数据,具体的,将在页缓存中查找到的数据添加至记录缓存中;
本发明向所述记录缓存中添加数据的过程包括:
在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;
向所述记录缓存中添加数据的过程进一步包括:在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
获得与所述待添加数据具有相同数量级的记录数据的访问频率frec、以及与待添加数据具有不同数量级的记录缓存页的访问频率fpage;
判断frec>replace_page_ratio*fpage是否成立,如果是,则选择在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;否则选择在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
其中replace_page_ratio为预设的替换控制参数,replace_page_ratio∈(0,1]。可实现数据的实时储存。
附图说明
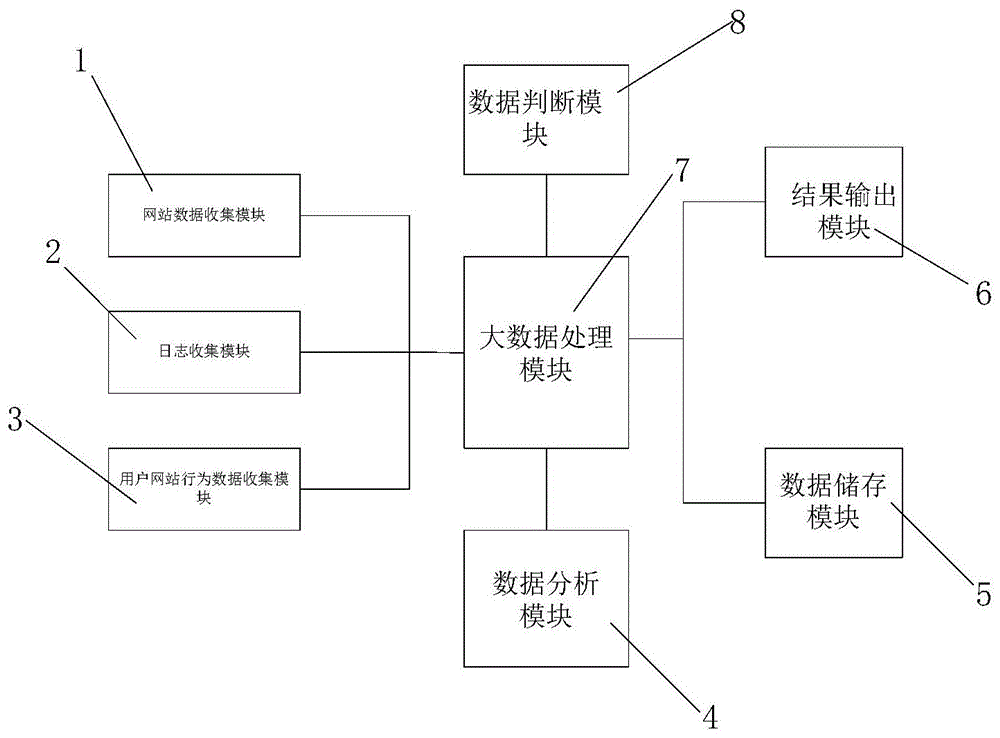
图1是本发明实施例提供的基于大数据的油价信息对比系统结构示意图。
图2是本发明实施例提供的基于大数据的油价信息对比方法流程图。
图中:1、网络数据收集模块;2、日志收集模块;3、用户网路行为数据收集模块;4、数据分析模块;5、数据储存模块;6、数据判断模块;7、大数据处理模块;8、数据判断模块。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于大数据的油价信息对比系统包括:网络数据收集模块1、日志收集模块2、用户网路行为数据收集模块3、数据分析模块4、数据储存模块5、数据判断模块6、大数据处理模块7、数据判断模块8。
网络数据收集模块1,与大数据处理模块7连接,利用互联网搜索对油价进行有针对性的数据抓取,并按照一定的规则和筛选标准进行数据的分类;
日志收集模块2,与大数据处理模块7连接,利用各个油站上的网站中的销售日志文件进行数据的收集;
用户网路行为数据收集模块3,与大数据处理模块7连接,根据用户在网络上的油价成交行为,搜集油价的数据;
数据分析模块4,与大数据处理模块7连接,对搜集的油价数据进行比对,得出油价的分布情况;
数据储存模块5,与大数据处理模块7连接,利用储存器储存搜集的各种油价数据,进行数据分类储存;
结果输出模块6,与大数据处理模块7连接,利用显示屏输出油价的分布情况;
大数据处理模块7,与网络数据收集模块1、日志收集模块2、用户网路行为数据收集模块3、数据分析模块4、数据储存模块5、结果输出模块6、数据判断模块8连接,协调各个模块的工作运行;
数据判断模块8,与大数据处理模块7连接,对采集的油价数据,进行判断是否是真实的油价。
如图2所示,本发明实施例提供的基于大数据的油价信息对比方法,具体包括以下步骤:
s101:首先,利用网络、日志、用户网络行为,获取油价的数据信息;
s102:根据获取的油价数据信息,进行分析,对采集的油价数据,进行判断是否是真实的油价,如判断出不是真实的油价,偏离正常的油价范围很多,则是该油价无效,不进行处理和储存输出;
s103:对搜集的油价数据进行比对,得出油价的分布情况;
s104:对采集的油价信息和油价分布数据进行储存,并通过显示屏显示出油价的分布结果。
所述数据储存模块5利用储存器储存搜集的各种油价数据,进行数据分类储存的过程中,为了增加少数类数据数量来调节不平衡数据集的平衡度,从而平衡数据分布;对整个数据集在保持分布的情况下进行欠采样处理来减少用于训练的数据,降低数据集的规模,从而能够减少模型训练时间,提高算法的分类效率,采用基于rsboost算法的不平衡数据分类方法,具体过程如下:
给定训练集s={(x1,y1),(x2,y2),…,(xm,ym)},样本xi∈xd是d维特征向量,类标记yi∈{p,n},其中p对应少数类,n对应多数类;
输入:训练集si,基分类模块wl,过采样率m,欠采样率n;
输出:分类模型h(x);
步骤一,初始化数据集中样本的权重:
d1(i)=1/m;
步骤二,根据过采样率m对少数类进行smote过采样处理后,在保持数据分布的情况下以欠采样率n对整个数据集进行随机欠采样处理,生成训练数据集st′,其权重分布为dt′;
步骤三,fort=1tot;
(1)根据训练数据集st′及其权重分布dt′,训练弱分类模块wl,并计算弱假设ht:x×y→[0,1];
(2)计算ht的伪损失:
(3)计算权重更新参数:
ωt=(1/2)·(1+ht(xi,yi)-ht(xi,y));
(4)更新权重分布dt
(5)归一化处理:
步骤四,通过t个弱假设权重投票得到最终分类模型:
所述数据判断模块8采集的油价数据,进行判断是否是真实的油价的过程中,为了对异常的油价数据快速的进行识别,减少判断的时间,采用dbscan算法,具体包括以下步骤:
步骤一,检查数据中没有被访问的数据对象p且这个数据对象没有处理过,检查它的eps领域neps(p),如果其neps(p)领域内包含的数据对象数目大于或等于minpts,则建立新簇c,并将p及其领域内包含的数据对象并入c中;
步骤二,如果c中有未被处理的数据对象q,检查它的eps领域neps(p),若果其neps(p)领域内包含的数据对象大于等于minpts,将q及其领域内包含的点代入c;
步骤三,重复步骤二,直到c中的对象都被处理过;
步骤四,重复步骤一到步骤三直到所有数据对象都被访问过,且所有的数据对象都标记为某个簇或者被认为是异常数据。
所述数据分析模块4对搜集的油价数据进行比对,得出油价的分布情况的过程中,为了提高聚类精度和聚类的稳定性,提高油价数据的分布质量,采用k-means,具体包括以下步骤;
步骤一,基于公式
计算文本相似度,构建矩阵m;
步骤二,基于公式
p={a1,a2,…,an};
其中
步骤三,建立初始中心点集i和删除集,均设置为空集;
步骤四,在集合p中选择最大的一个所对应的文本dj作为一个中心点,并将其加入初始中心点集中,即i=i∪{dj};
步骤五,将矩阵m中与文本dj的文本相似度达到一定值(sim(di,dj)>β)的所有文本放到delete(delete=de-lete∪{ai}),并从集合p中删除,即p=p-{ai};
步骤六,判断是否p=φ、i<k,如果条件为真,则将de-lete中的数据覆盖到p中,即p=delete;
步骤七,除非满足终止条件,即i=k,否则重复执行步骤3到步骤六,最终得到k个初始聚类中心点;
步骤八,根据余弦公式计算每个类簇的中心文本与其他文本的文本相似度,根据相似度大小,将与类簇中心相似度最大的文本放到该簇中;
步骤九,计算
步骤十,除非满足终止条件,否则重复执行步骤8到步骤九。
在本发明实施例中,对采集的油价信息和油价分布数据进行储存中,预先为数据库中的数据表建立记录缓存,所述记录缓存以数据行为单位进行数据读写;
当接收到客户端的数据查询请求时,在所述记录缓存中查找所请求的数据;
若查找失败,则在所述数据库的页缓存中查找所请求的数据,所述页缓存以页为基本单位进行数据读写;
将在所述记录缓存或所述页缓存中查找到的数据返回至客户端;
向所述记录缓存中添加数据,具体的,将在页缓存中查找到的数据添加至记录缓存中;
在本发明实施例中,向所述记录缓存中添加数据的过程包括:
在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;
向所述记录缓存中添加数据的过程进一步包括:在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
获得与所述待添加数据具有相同数量级的记录数据的访问频率frec、以及与待添加数据具有不同数量级的记录缓存页的访问频率fpage;
判断frec>replace_page_ratio*fpage是否成立,如果是,则选择在记录缓存中,选择与待添加数据具有相同数量级的记录数据进行替换;否则选择在记录缓存中,选择与待添加数据具有不同数量级的记录缓存页,回收该缓存页所占用的空间,利用所回收的空间为所述待添加数据分配新的记录缓存页,将所述待添加数据写入该新的记录缓存页。
其中replace_page_ratio为预设的替换控制参数,replace_page_ratio∈(0,1];
所述与待添加数据具有不同数量级的记录缓存页的访问频率fpage的获得方法为:
fpage=(fmin+fmax)/2*n;
其中,fmin为该记录缓存页中时间戳最早的数据的访问频率,fmax为该记录缓存页中时间戳最晚的数据的访问频率,n为该记录缓存页的数据记录总量。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!