基于变分推断的逐层神经网络剪枝方法和系统与流程
本发明涉及深度学习技术领域,具体地,涉及基于变分推断的逐层神经网络剪枝方法和系统。
背景技术:
在深度学习领域,神经网络强大的函数拟合能力使得它能理想地完成诸如图像分类、物体检测、语音识别等任务。然而当神经网络的权重数量过于庞大时,往往需要耗费巨大的存储与计算开销,因此很难应用在移动端、嵌入式板等计算资源受限的设备上。为了实现神经网络的压缩与加速,技术人员提出了诸如剪枝、量化、低秩分解等方案。
目前,对神经网络进行剪枝处理,是进行神经网络压缩和加速的主流方案,其主要思想是删除神经网络中对输出结果影响极小的神经元或卷积核。基于此的各类算法,通常是利用正则项、hessian矩阵等定位并删除神经元或卷积核。但是,在保证神经网络精度情况下,实现大规模的剪枝依旧是研究的难点。近来,一些剪枝算法体现出了在精度与压缩率间的良好平衡,但大多出于启发式的设计,缺乏理论支持。随着贝叶斯框架在深度学习领域逐渐发展,变分推断作为一种近似贝叶斯推断,开始受到关注。其在特定任务下的良好表现的背后,是完备的数学理论基础。为将此理论基础赋予剪枝算法,最新的一些研究开始尝试通过向神经网络注入可优化的稀疏噪声,以实现低精度损失下的高度剪枝。
但是,上述方法中为降低计算难度,往往忽略了神经网络中的层间关系,继而影响神经网络的压缩率与精度。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于变分推断的逐层神经网络剪枝方法和系统。
第一方面,本发明实施例提供一种基于变分推断的逐层神经网络剪枝方法,包括:
通过采样方式在神经网络中注噪声,得到噪化的神经网络;
根据预设的目标函数对噪化的神经网络的权重进行训练,得到训练后的神经网络权重和训练后的神经网络;
根据变分推断得到的变分下界,训练注入的乘性高斯噪声对应的噪声参数,得到训练后的噪声参数;
基于所述训练后的噪声参数、训练后的神经网络权重,通过阈值函数逐层删除所述训练后的神经网络中相应的神经元或者卷积核。
可选地,通过采样方式在神经网络中注入噪声,得到噪化的神经网络,包括:
将神经网络第l层第j维度上的输入记为:
∈遵循标准高斯分布:
其中:
可选地,根据预设的目标函数对噪化的神经网络的权重进行训练,得到训练后的神经网络权重和训练后的神经网络,包括:
假设神经网络的权重为w,神经网络第l层注入的噪声为θl,则所述神经网络的权重最优解w*的计算公式如下:
其中:p(y|x,w,θl)表示在输入数据为x、权重为w,注入噪声为θl时,神经网络输出值为y的概率;d表示训练的数据集,其中x为输入数据,y为标签;
可选地,根据变分推断得到的变分下界,训练注入的乘性高斯噪声对应的噪声参数,得到训练后的噪声参数,包括:
最大化变分下界的计算公式如下:
其中:
设置诱导稀疏性的高斯先验分布如下:
其中:
得到训练后的噪声参数如下:
其中:
训练完成后的
为便于变分下界的计算,可将kullback-leibler散度做如下化简:
可选地,基于所述训练后的噪声参数、训练后的神经网络权重,通过阈值函数逐层删除所述训练后的神经网络中相应的神经元或者卷积核,包括:
当神经网络的第l层权重与噪声参数训练完成后,通过如下阈值函数修改注入的噪声:
其中,
通过修改后的注入噪声对第l层神经元或者卷积核进行剪枝处理,计算公式如下:
其中:等式左侧的
通过上述稀疏化的操作,神经网络的部分权重将被置为0,则对应的输入将被丢弃,不再参与神经网络的运算,从而实现将神经元或卷积核删除,即剪枝的效果。通过从神经网络第一层开始,直到最后一层结束,最终输出剪枝完成的神经网络。其中,因为所设计的逐层训练与剪枝的形式,所注入的噪声在训练过程中融入了神经网络的层级关系,使得在剪枝过程中充分考虑层间的依赖,继而保证了在高度剪枝下神经网络的输出结果依旧具备鲁棒性。
第二方面,本发明实施例提供一种基于变分推断的逐层神经网络剪枝系统,包括:处理器和存储器,所述存储器中存储有计算机程序,当该计算机程序被所述处理器调用时,所述处理器执行如第一方面中任一项所述的基于变分推断的逐层神经网络剪枝方法。
与现有技术相比,本发明具有如下的有益效果:
本发明提供的基于变分推断的逐层神经网络剪枝方法和系统,采用逐层训练与剪枝的方式,结合了神经网络中层间具有依赖关系的特点,在训练完成时能将各个层间关系融入到噪声参数中,从而更为精确地定位冗余的神经元或卷积核,保证了在高度剪枝下神经网络的输出结果依旧具备鲁棒性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明提供的基于变分推断的逐层神经网络剪枝方法的原理示意图;
图2为本发明提供的基于变分推断的逐层神经网络剪枝装置的结构示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
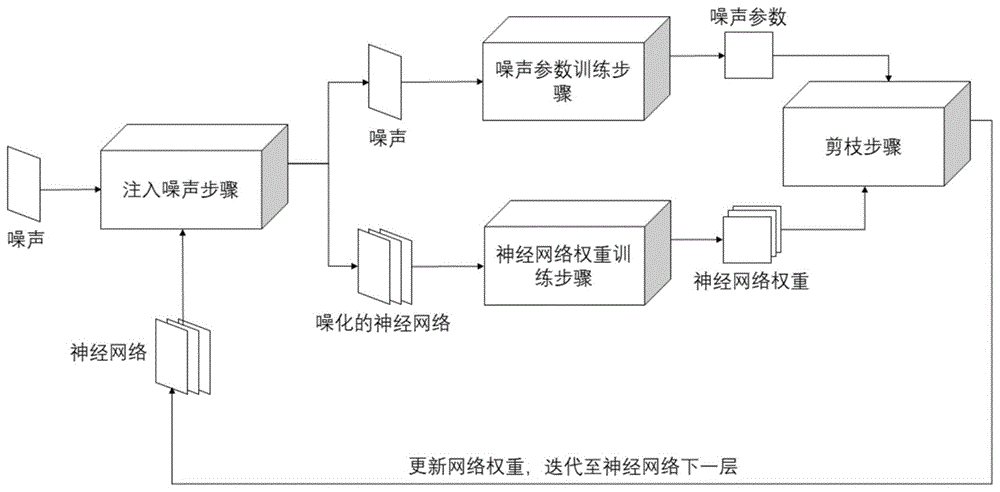
如图1所示,为本发明基于变分推断的逐层神经网络剪枝方法实施例的流程图,该方法通过注入噪声步骤将所设计的高斯噪声注入神经网络,并分别在神经网络权重训练步骤与噪声参数训练步骤中,针对特定任务训练网络权重与噪声参数,最后在剪枝步骤利用训练完成的噪声参数通过阈值函数实现剪枝。上述流程从神经网络第一层开始并逐层重复进行,直到最后一层结束。
本发明能够在低精度损失下实现神经网络的高度剪枝。因为基于变分推断,本发明吸收了贝叶斯框架完备的理论基础,同时由于所设计的逐层训练与剪枝的模式,在理论基础上结合了神经网络中层间具有依赖关系的特点,在训练完成时能将此层间关系融入到噪声参数中,更为精确地定位冗余的神经元或卷积核。
具体地,参照图1,所述方法包括如下步骤:
注入噪声步骤:设计一种乘性的高斯噪声,通过采样注入神经网络;
神经网络权重训练步骤:根据任务特定的目标函数训练神经网络权重;
噪声参数训练步骤:根据变分推断得到的变分下界训练所注入的噪声的参数;
剪枝步骤:根据训练完成的噪声参数,通过阈值函数删除所训练的神经网络中相应的神经元或卷积核。
对应于上述方法,参照图2,一种基于变分推断的逐层神经网络剪枝装置,包括:
注入噪声模块:设计一种乘性的高斯噪声,通过采样注入神经网络;
神经网络权重训练模块:根据任务特定的目标函数训练神经网络权重;
噪声参数训练模块:根据变分推断得到的变分下界训练所注入的噪声的参数;
剪枝模块:根据训练完成的噪声参数,通过阈值函数删除所训练的神经网络中相应的神经元或卷积核。
以下对上述各个步骤和模块的具体实现进行详细的描述,以便理解本发明技术方案。
在本发明部分实施例中,所述注入噪声步骤,其中:针对神经网络的任意层,设计一种与该层输入同维度的乘性高斯噪声,在神经网络进行计算时,该噪声将通过采样以相乘的方式注入该层的输入。为便于采样,可将所设计的噪声进行等价的参数化转换。
在本发明部分实施例中,所述神经网络权重训练步骤,其中:针对任意训练数据集,神经网络权重的训练目标是最大化已知输入数据而输出对应标签的概率。
在本发明部分实施例中,所述噪声参数训练步骤,其中:利用变分推断计算得到变分下界,噪声参数的训练目标为最大化该变分下界。训练完成的噪声为其后验分布的近似解。
在本发明部分实施例中,所述剪枝步骤,其具体如下:将训练完成的噪声输入阈值函数得到新噪声,随后以相乘的形式用新噪声稀疏化对应层的神经网络权重,实现剪枝的效果。稀疏化操作后该层的输入将不再需要乘以噪声。
如图2所示,剪枝系统由注入噪声模块、神经网络权重训练模块、噪声参数训练模块、剪枝模块组成,整个系统框架能够端到端地进行训练。
在如图2所示的实施例的系统框架中,对于神经网络第l层,高斯噪声
其中,
在如图2所示的实施例的系统框架中,针对训练噪声参数的目标函数为
其中,d为训练数据集,x为输入数据,y为标签,w为神经网络权重,θl为
则噪声参数的训练目标为
在图2所示的实施例的系统框架中,训练神经网络权重的目标函数为训练数据的极大似然,计算公式为
其中,
噪声参数的训练始于神经网络第一层,当目标函数
进一步地,由于
其中,
在图2所示的实施例的系统框架中,结束该层的噪声参数训练、当前轮次的网络权重训练及剪枝后,整个训练与剪枝过程将重复应用于神经网络的下一层上,直到神经网络的最后一层。如此逐层训练与剪枝的形式使得所注入的噪声在训练过程中融入了神经网络的层级关系。
综上,本发明将所注入噪声作为冗余性的指标,利用变分推断近似求得噪声的后验分布之后通过阈值函数定位冗余的神经元或卷积核,并进行剪枝。同时,由于训练与剪枝是逐层进行,所注入的噪声在训练过程中融入了神经网络的层级关系,使得在剪枝过程中充分考虑层间的依赖,继而保证了在高度剪枝下神经网络的输出结果依旧具备鲁棒性。
需要说明的是,本发明提供的所述基于变分推断的逐层神经网络剪枝方法中的步骤,可以利用所述基于变分推断的逐层神经网络剪枝系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照所述系统的技术方案实现所述方法的步骤流程,即,所述系统中的实施例可理解为实现所述方法的优选例,在此不予赘述。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!