基于环境元嵌入和深度学习的情感倾向性分析方法与流程
本发明涉及计算机文本情感分析领域,尤其涉及一种基于环境元嵌入和深度学习的情感倾向性分析方法。
背景技术:
在移动互联网时代,网络已经逐渐渗入到人们生活中的各个方面,成为生活中必不可少的应用元素。随着言论的发表越发的自由,人们不再只是信息的被动获取者,而是更多扮演着信息制造者的角色。人们会通过各类网络平台,发表对热门事件的看法和见解,分享自己的心情感受,或是对某些产品的使用评价、心得体会等。这样随之而来的就是产生大量以文本方式呈现、包含大量情感信息的具有很大分析价值的评论信息,而怎样从这些具有研究价值的文本中提取出有用的情感信息,也成为了自然语言处理领域的一个热门课题。《心理学大辞典》定义情感是人对客观事物是否满足自己的需要而产生的态度体验,所以赋予计算机情感分析能力的研究引起了社会的广泛关注。而人工智能之父marvinminsky于1985年在《thesocietyofmind》中指出,问题不在于智能机器能否拥有情感,而是在于机器实现智能化时一定不能没有情感,这也让情感分析的研究成为更加热门的课题。
20世纪六十年代,机器学习(machinelearning,ml)开始崭露头角,并在80年代后开始在理论、算法、应用等方面都取得了可喜的成果。2006年以来,深度学习作为ml领域的一个延伸课题,走进了各大研究学者的视野并引起了广泛的关注,到现在,深度学习已成为各大领域的重要研究课题。深度学习是机器学习的延伸,所以准确说来,深度学习不能说是一种不同于的机器学习的全新方法,它可以被认为是一种特征学习,通过一些相对不复杂的但是却是非线性的模型,或者经过很多次的组合变换,将原始数据转化成更加抽象、更高层次的表达。因此,将深度学习应用到各种自然语言处理任务中,有着很大的研究意义和探索空间。
在自然语言处理相关研究任务中,文本情感分析是一个重要研究方向。情感分析又可以称为情感倾向性分析和观点信息挖掘,是对收集来的带有情感色彩的文本数据,进行预处理,然后进行归纳分类等操作进行情感倾向性分析的过程。文本情感分析的目标是给定一个文本作为输入,挖掘出文本中全部或部分的情感信息。现如今,越来越多的用户喜欢在一些公共社交平台上畅所欲言,抒发心情,或者表明自己的立场、观点或态度。随之而来的是大量主题分散、不规范且繁琐的文本信息数据的产生。但这些数据中涵盖了众多的话题,包含大量的情感信息,通过这些信息进行文本情感倾向性分析可以实现很多有价值的事。例如:政府部门可以通过人们对社会热点事件的看法,进行及时的舆情监控,控制舆论走向,稳定人心;娱乐明星根据大众评价,可及时进行自身的形象维护;通过对产品评价文本进行情感倾向性分析,不仅消费者可以据此进行产品选择、决策购买,而且商家可以据此进行产品改进优化,适当进行产品推广,提高市场占有率;另外,还可以对评论中的高压力人群或者抑郁患者进行及时的情感疏导。所以,从以上来看对这些文本信息进行情感分析,不仅是具有商业意义,还具有一定的社会意义,包括对社会稳定、国家治安都起到一定程度的积极维护作用。
然而,由于网络评论短文本的语言大多不规范、主题较为分散、网络新词较多,面对如此庞大的文本数据,如果只是通过人工翻阅浏览的方法来分析总结用户情感,那将是一件十分繁琐与困难的事情,情感分析结果并不理想。尤其是对中文进行文本情感倾向性分析研究,现阶段的研究成果可以完成一些相对简单的任务,准确率相对不高,对此还有很大的探索空间和研究意义,同时也是一个有趣且具有挑战的问题。面对文本情感分析任务中,情感分析对象的复杂以及复杂文本语义的表达方法等挑战,需要更加深层次的深度学习技术去解决。
有鉴于此,有必要设计一种基于环境元嵌入和深度学习的情感倾向性分析方法,以解决上述问题。
技术实现要素:
本发明的目的在于提供一种准确性高的基于环境元嵌入和深度学习的情感倾向性分析方法。
为实现上述发明目的,本发明提供了一种基于环境元嵌入和深度学习的情感倾向性分析方法,包括如下步骤:
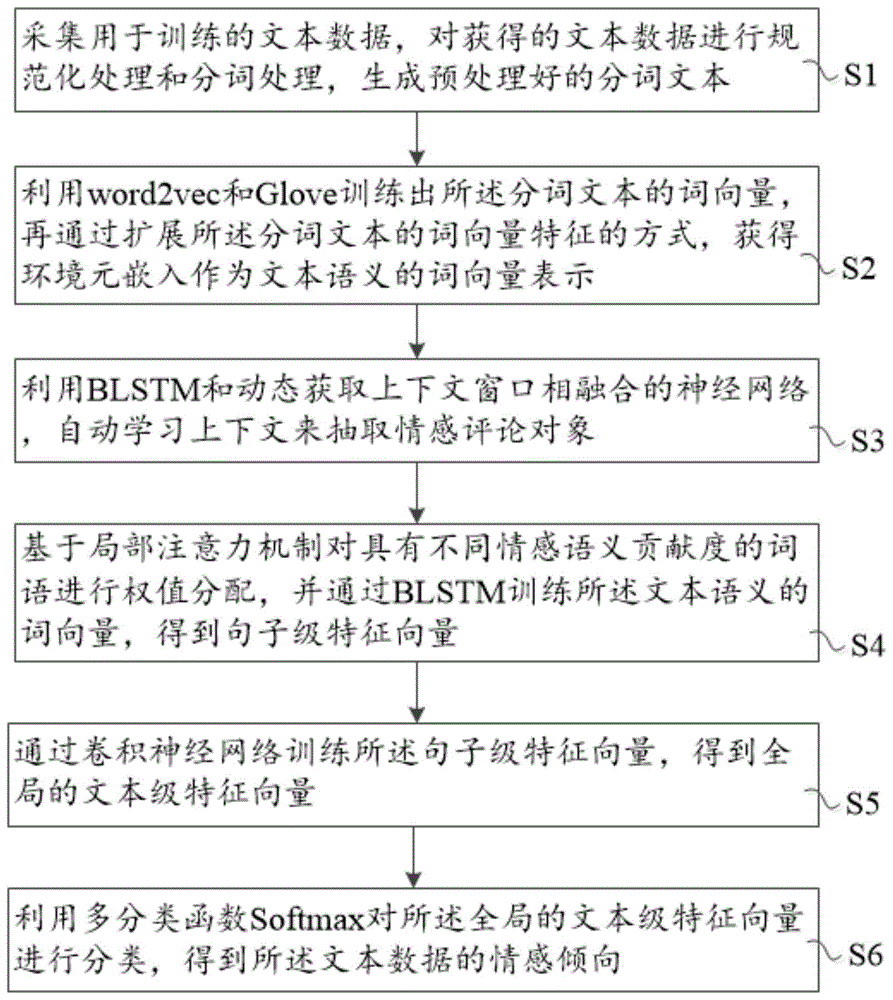
s1,采集用于训练的文本数据,对获得的文本数据进行规范化处理和分词处理,生成预处理好的分词文本;
s2,利用word2vec和glove训练出所述分词文本的词向量,再通过扩展所述分词文本的词向量特征的方式,获得环境元嵌入作为文本语义的词向量表示;
s3,利用blstm和动态获取上下文窗口相融合的神经网络,自动学习上下文来抽取情感评论对象;
s4,基于局部注意力机制对具有不同情感语义贡献度的词语进行权值分配,并通过blstm训练所述文本语义的词向量,得到句子级特征向量;
s5,通过卷积神经网络训练所述句子级特征向量,得到全局的文本级特征向量;
s6,利用多分类函数softmax对所述全局的文本级特征向量进行分类,得到所述文本数据的情感倾向。
作为本发明的进一步改进,所述步骤s2包括如下步骤:
s21,利用word2vec训练得到所述分词文本的词向量w1,j,利用glove训练得到所述分词文本的词向量w2,j,其中,j为当前词;
s22,将w1,j和w2,j进行加权计算得到基于word2vec和glove的环境元嵌入wj,所述wj满足如下关系式:
wj=α1,jw′1,j+α2,jw′2,j,
其中,
其中,w′i,j=piwi,j+bi,(i=1,2);pi表示权值矩阵;bi表示偏置向量;
s23,将所述环境元嵌入wj作为文本语义的词向量表示输入层级神经网络情感分析模型中。
作为本发明的进一步改进,所述步骤s3包括如下步骤:
s31,使用最小化负对数似然函数对blstm和动态获取上下文窗口相融合模型进行有指导的学习;
s32,使用步骤s2中的所述环境元嵌入作为文本语义的词向量进行blstm和动态获取上下文窗口相融合模型的参数的学习,随机初始化参数,随机梯度下降更新参数值,以自动学习上下文来抽取情感评论对象。
作为本发明的进一步改进,所述步骤s4包括如下步骤:
s41,使用双向lstm对步骤s2得到的环境元嵌入wj进行编码,所述编码过程为:
s42,连接前后向lstm得到隐状态,结合如下公式获得词语的分布式向量:
s43,使用
s44,使用加权公式
作为本发明的进一步改进,所述步骤s5具体为:将步骤s4得到的句子级特征向量作为卷积神经网络的输入基元,经过卷积层、下采样层、全连接层的向前传播卷积操作训练得到全局的文本级特征向量。
本发明的有益效果是:本发明基于环境元嵌入和深度学习的情感倾向性分析方法首先利用基于word2vec和glove获得的环境元嵌入(contextualizeddynamicmeta-embeddings,cdme)作为文本语义的词向量表示;将获得的词向量采用blstm和动态获取上下文窗口相融合的神经网络来抽取情感评论对象,并基于注意力机制,融合上下文词语对于评论对象的有效信息,得到句子级特征向量;将获得的句子级特征向量作为卷积神经网络的输入基元,并基于注意力机制训练生成文本级特征向量,经过softmax得到文本数据的情感倾向。该方法在神经网络框架下有效地融合文本信息,更好的实现了对文本数据情感倾向性的判断,提高了文本数据情感倾向判定的准确性。
附图说明
图1为本发明的基于环境元嵌入和深度学习的情感倾向性分析方法的流程图。
图2为本发明中的层级神经网络的模型图。
图3为注意力机制的原理图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
在此,还需要说明的是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与本发明的方案密切相关的结构和/或处理步骤,而省略了与本发明关系不大的其他细节。
请参阅图1所示,本发明提供了一种基于环境元嵌入和深度学习的情感倾向性分析方法,包括如下步骤:
s1,采集用于训练的文本数据,对获得的文本数据进行规范化处理和分词处理,生成预处理好的分词文本;
s2,利用word2vec和glove训练出分词文本的词向量,再通过扩展分词文本的词向量特征的方式,获得环境元嵌入作为文本语义的词向量表示;
s3,利用blstm和动态获取上下文窗口相融合的神经网络,自动学习上下文来抽取情感评论对象;
s4,基于局部注意力机制对具有不同情感语义贡献度的词语进行权值分配,并通过blstm训练文本语义的词向量,得到句子级特征向量;
s5,通过卷积神经网络训练句子级特征向量,得到全局的文本级特征向量;
s6,利用多分类函数softmax对全局的文本级特征向量进行分类,得到文本数据的情感倾向。
其中,步骤s2包括如下步骤:
s21,利用word2vec训练得到分词文本的词向量w1,j,利用glove训练得到分词文本的词向量w2,j,其中,j为当前词;
s22,将w1,j和w2,j进行加权计算得到基于word2vec和glove的环境元嵌入wj,wj满足如下关系式:
wj=α1,jw′1,j+α2,jw′2,j,
其中,
其中,w′i,j=piwi,j+bi,(i=1,2);pi表示权值矩阵;bi表示偏置向量;
s23,将环境元嵌入wj作为文本语义的词向量表示输入层级神经网络情感分析模型中。
在本发明中,分别基于word2vec和glove训练得到的分词文本的词向量w1,j与w2,j,通过扩展预训练中词向量特征的方式,获取融合更多特征的文本语义词向量表示的环境元嵌入(cdme),实现从数据中自动学习出有效的语义特征表示,从而减少对特征工程的依赖,使得情感倾向分析算法更加智能化,提高了模型效果。
其中,步骤s3包括如下步骤:
s31,使用最小化负对数似然函数对blstm和动态获取上下文窗口相融合模型进行有指导的学习;
s32,使用步骤s2中的所述环境元嵌入作为文本语义的词向量进行blstm和动态获取上下文窗口相融合模型的参数的学习,随机初始化参数,随机梯度下降更新参数值,以自动学习上下文来抽取情感评论对象。
在本发明中,抽取情感评价对象时,相较于传统的基于特征的crf(conditionalrandomfield)算法依赖设计的特征模板、情感词典、句法分析器等外部资源,本发明中基于神经网络的算法,结合局部上下文对信息抽取的影响,基于blstm和动态获取上下文窗口(context-window)融合的情感分析算法,自动学习上下文以从文本数据中学习潜在特征来抽取情感评价对象,不需要人工设计特征,优化了抽取过程。
请参阅图3并结合图1所示,步骤s4包括如下步骤:
s41,使用双向lstm对步骤s2得到的环境元嵌入wj进行编码,编码过程为:
s42,连接前后向lstm得到隐状态,结合如下公式获得词语的分布式向量:
s43,使用
s44,使用加权公式
本发明通过引入注意力机制来更好的学习从词语级到句子级再到文本级模态之间的相互关系,让情感分析任务更专注于找到输入文本数据中显著的与情感信息输出相关的有用特征,从而更好的表示这些信息,提高了情感分析模型的效果。
步骤s5具体为:将步骤s4得到的句子级特征向量作为卷积神经网络的输入基元,经过卷积层、下采样层、全连接层的向前传播卷积操作训练得到全局的文本级特征向量。
下面针对基于word2vec和glove获得的词向量w1,j与w2,j,对其做以下四种不同的线性变换,将得到的不同词向量分别输入至图2所示的层级神经网络模型中,进行情感倾向分析效果的对比实验。
(1)将w1,j和w2,j分别作为层级神经网络模型输入。
(2)w1和w2级联后作为层级神经网络模型输入,其处理过程如下:
wj=[w1,j,w2,j]
该方式实现了各种词向量的简单拼接,但是,随着拼接的词向量越来越多,层级神经网络模型会变得低效。
(3)w1和w2投影后级联作为层级神经网络模型输入,其处理过程如下:
①通过线性映射将词向量投影到同一向量空间中,映射过程满足如下关系式:
w′i,j=piwi,j+bi(i=1,2)
其中,pi表示权值矩阵;bi表示偏置向量;
②对映射后的词向量级联得到层级神经网络模型输入:
wj=w′1,j+w′2,j
(4)dynamicmeta-embeddings(dme),其处理过程如下:
①通过线性映射将词向量投影到同一向量空间中,映射过程满足如下关系式:
w′i,j=piwi,j+bi(i=1,2)
其中,pi表示权值矩阵;bi表示偏置向量;
②对映射后的词向量加权求和得到层级神经网络模型输入:
wj=α1,jw′1,j+α2,jw′2,j
其中,
将通过上述四种方式得到的词向量与本发明步骤s2得到的环境元嵌入(cdme)输入如图2所示的层级神经网络模型中,可知,基于环境元嵌入(cdme)得到的情感倾向分析相比其他四种文本词向量得到的情感倾向分析更高效、更准确。
综上所述,本发明基于环境元嵌入和深度学习的情感倾向性分析方法首先利用基于word2vec和glove获得的环境元嵌入(cdme)作为文本语义的词向量表示;将获得的词向量采用blstm和动态获取上下文窗口相融合的神经网络来抽取情感评论对象,并基于注意力机制,融合上下文词语对于评价对象的有效信息,得到句子级特征向量;将获得的句子级特征向量作为卷积神经网络的输入基元,并基于注意力机制训练生成文本级特征向量,经过softmax得到文本数据的情感倾向。该方法在神经网络框架下有效地融合文本信息,更好的实现了对文本数据情感倾向性的判断,提高了文本数据情感倾向判定的准确性。
以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!