基于成分句法压缩树的指代消解方法与流程
本发明涉及机器语言处理领域,具体涉及一种基于成分句法压缩树的指代消解方法。
背景技术:
指代是一种常见的语言现象,大量出现在篇章或者对话中。它保持了语言的简练,减少了冗余。比如句子“玛丽居里开创了放射性理论,发明了放射性同位素的技术。在她的指导下,人们第一次将放射性同位素用于治疗肿瘤”中,“她”指代“玛丽居里”。在语言学中,用于指向的语言单位成为照应语,如例中的“她”;所指向的对象或者内容成为先行词,如例中的“玛丽居里”。
一般情况下,指代分为两种:回指和共指。回指是指当前的照应语与上文出现的词、短语或句子存在密切的语义关联性,指代依存于上下文语义中,在不同的语言环境中可能指代不同的实体,具有非对称性与非传递性;共指是指两个名词或者名词短语指向真实世界中的同一参照体,这种指代脱离上下文依然存在。目前的指代消解研究偏重于共指消解,本文亦然。
指代消解的研究历史悠久。早期的研究主要通过专家构建领域知识,形成消解规则进行指代消解。近年来,得益于自然语言处理会议的召开和其公布的标注良好的指代消解语料,指代消解的研究转向了数据驱动的方法。特别是随着深度学习技术的兴起和发展,越来越多的学者开始应用深度学习方法于指代消解研究。
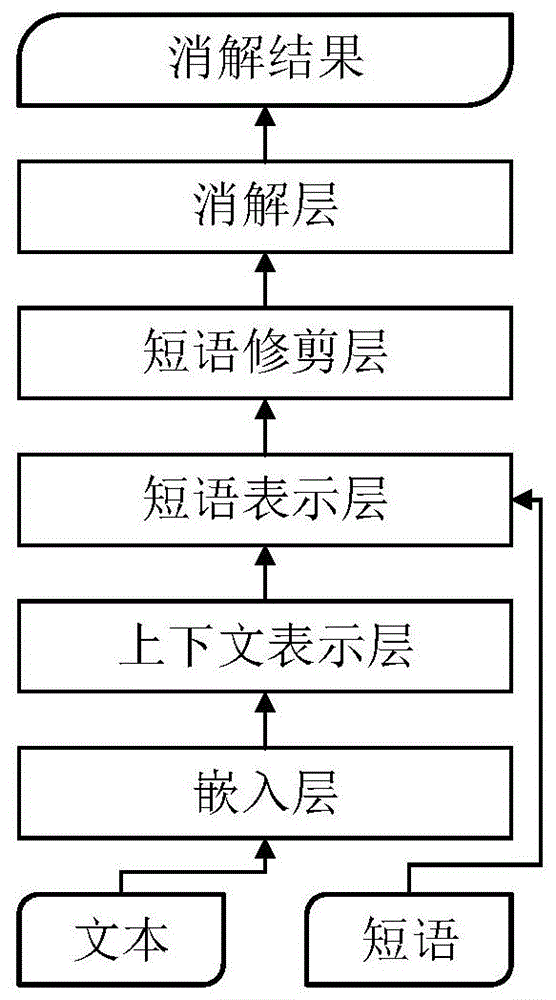
目前深度学习技术在指代消解任务上应用最为广泛。其中典型的工作是lee等人[1]于2017年提出的基于神经网络的端到端指代消解框架,该框架构成如图1所示。
对于输入文本
该模型的主要思想是利用嵌入层、上下文表示层与注意力机制对短语进行表示,然后通过前馈神经网络对短语进行打分,并根据得分进行修剪,保留置信度较高的短语成为待消解项;对于每一个待消解项,与之前的所有候选先行词分别配对,并使用前馈神经网络计算其间存在指代关系的置信度,取置信度最高的候选先行词作为最终的消解结果。下面对图中的每一层进行简要阐述:
嵌入层:对于
上下文表示层:给定
短语表示层与修剪层:给定短语
其中fi表示额外的特征向量(此处编码短语的宽度特征),
得到所有短语的向量表示后,使用前馈神经网络对其进行打分:
scorem(i)=ffnnm(si)(0.5)
然后取得分最高的前k个短语作为待消解项集合a,参与后续的消解操作。
消解层:给定待消解项si与其候选先行词sj,其中si∈a,sj∈{ε}∪{sk|1≤k≤i-1},0≤j<i≤k。当j=0时,sj=ε,表示si不存在任何候选先行词。类似地,使用前馈神经网络来获得si与sj之间的先行词得分:
scorea(i,j)=ffnna([si,sj,si⊙sj,fi,j])(0.6)
其中,fi,j编码si与sj之间的讲述者、篇章类型与距离特征。
进一步地,可以得到si与sj之间的指代得分:
最终,取si的候选先行词集合中与si指代得分最高的
传统技术存在以下技术问题:
大量的研究表明结构信息对于指代消解任务来说至关重要,同时语料中存在的大量的表述间嵌套情况也侧面反映了结构信息的普遍性与研究意义。但是基准平台只编码了文本的线性结构,忽略了文本内部潜在的树形结构信息。
参考文献:
[1]leek,hel,lewism,etal.end-to-endneuralcoreferenceresolution[c]//proceedingsofthe2017conferenceonempiricalmethodsinnaturallanguageprocessing.2017:188-197.
技术实现要素:
本发明要解决的技术问题是提供一种基于成分句法压缩树的指代消解方法;利用针对成分句法树的压缩算法,简化原有成分句法树的结构,减少与指代消解任务无关的冗余结点的影响,增强结构信息与层次关系在指代消解系统中的表现。
为了解决上述技术问题,本发明提供了一种基于文档句法压缩树的指代消解方法,包括:
定义“压缩”操作:
给定成分句法树t的某一结点nt,其孩子结点列表记为nt.children=[n′1,n′2,...,n′m],若其双亲结点不为空,记其双亲结点为parent,其孩子结点列表为parent.children=[...,nt-1,nt,nt+1,...],对结点nt进行压缩操作:
①从结点nt中移除所有其孩子结点并保留;
②从nt的双亲结点中移除该结点;
③将所有孩子结点插入到原nt在双亲结点中的对应位置;
最终,得到parent.children=[...,nt-1,n′1,n′2,...,n′m,nt+1,...];
针对成分句法树的压缩算法:
输入:原始成分句法树t,记起根结点为root
输出:成分句法压缩树t′
①对树t进行后序遍历,得到后序遍历的结点序列nodes;
②如果nodes不为空,弹出序列头部结点node,否则转到⑥;
③如果node为叶子结点,无需对其进行操作,转到②,否则继续执行;
④如果node存在双亲结点,且:(1)如果node只有一个孩子结点,则对结点node执行压缩操作;(2)如果结点node不是名词短语(即标签不为np)结点,认为其蕴含的结构信息对消解任务的完成没有帮助,故同样对结点node执行压缩操作;其他情况返回②;
⑤如果node不存在双亲结点(即为根结点root),且只有一个孩子结点,则对该孩子结点执行压缩操作;否则返回②;
⑥返回成分句法压缩树,程序结束;
通过上述算法可以得到成分句法压缩树;
从成分句法压缩树中抽取出“深度”与“左右兄弟数”特征加入指代消解模型。其中“深度”与“左右兄弟数”的定义如下:
结点x的深度:从树t的根结点到结点x的一条简单路径的长度即为x在t中的深度;因此根结点的深度为0;
结点x的左右兄弟数:如果两个结点拥有相同的双亲,则称它们为兄弟;由于成分句法树是有序树,定义结点x的左右兄弟数为:[x左侧(或之前)兄弟的数目,x左右(或之后)兄弟的数目];
两者的取值范围均为自然数。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
本发明的有益效果:
减小了原始成分句法树的复杂结构,消除了对于指代消解任务无关的冗余结点的信息,为指代消解任务提供了简洁而精确的结构信息,增强了结构信息与层次关系在神经指代消解系统中的表达。
附图说明
图1是背景技术中的基于神经网络的端到端指代消解框架的示意图。
图2是本发明基于成分句法压缩树的指代消解方法中的压缩算法流程图。
图3是本发明基于成分句法压缩树的指代消解方法中的压缩算法适用情况示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
首先定义“压缩”操作:
给定成分句法树t的某一结点nt,其孩子结点列表记为nt.children=[n′1,n′2,...,n′m],若其双亲结点不为空,记其双亲结点为parent,其孩子结点列表为parent.children=[...,nt-1,nt,nt+1,...],对结点nt进行压缩操作:
①从结点nt中移除所有其孩子结点并保留;
②从nt的双亲结点中移除该结点;
③将所有孩子结点插入到原nt在双亲结点中的对应位置;
最终,得到parent.children=[...,nt-1,n′1,n′2,...,n′m,nt+1,...]。
下面介绍针对成分句法树的压缩算法:
输入:原始成分句法树t,记起根结点为root
输出:成分句法压缩树t′
①对树t进行后序遍历,得到后序遍历的结点序列nodes;
②如果nodes不为空,弹出序列头部结点node,否则转到⑥;
③如果node为叶子结点,无需对其进行操作,转到②,否则继续执行;
④如果node存在双亲结点,且:(1)如果node只有一个孩子结点,则对结点node执行压缩操作;(2)如果结点node不是名词短语(即标签不为np)结点,认为其蕴含的结构信息对消解任务的完成没有帮助,故同样对结点node执行压缩操作;其他情况返回②;
⑤如果node不存在双亲结点(即为根结点root),且只有一个孩子结点,则对该孩子结点执行压缩操作;否则返回②;
⑥返回成分句法压缩树,程序结束;
算法流程图如图2所示。
通过上述算法可以得到成分句法压缩树。然后,从其中抽取出两个典型的结构特征——深度与左右兄弟数加入模型中。其定义如下:
结点x的深度:从树t的根结点到结点x的一条简单路径的长度即为x在t中的深度。因此根结点的深度为0。
结点x的左右兄弟数:如果两个结点拥有相同的双亲,则称它们为兄弟。由于成分句法树是有序树,定义结点x的左右兄弟数为:[x左侧(或之前)兄弟的数目,x左右(或之后)兄弟的数目]。
两者的取值范围均为自然数。为了减少误差的影响,参考文献[2]中的做法,使用数据装箱技术,它是一种将一定数量的连续值放入相对较少的数量的“箱子”中的做法。这里,对深度及左右兄弟数进行装箱,它们的值将会放入[0,1,2,3,4,5-7,8-15,16-31,32-63,64+]中的一个。例如,假设某结点的深度是10,需要将其放入6号箱子(箱子下标从0开始),最终得到深度为6。然后使用嵌入技术将上述两个特征变成可训练的固定维度的实值向量,得到最终的结构嵌入表示。
参考文献:
[2]clarkk,manningcd.improvingcoreferenceresolutionbylearningentity-leveldistributedrepresentations[c]//proceedingsofthe54thannualmeetingoftheassociationforcomputationallinguistics(volume1:longpapers).2016,1:643-653.
利用基准框架在conll2012指代消解评测语料上进行了实验。实验结果如下表1所示。
表1各个实验配置在开发集上的结果(conllf1值)
从表1可以看出,从成分句法压缩树中提取出的结构嵌入明显好于原始成分句法树,中文上以左右兄弟数特征对系统提升最大,而英文上则以深度特征对系统提升最大。
结合词性、命名实体与sect结构嵌入[3]三种额外特征,在conll2012的测试集上进行了最终的实验,实验结果如表2所示。
表2的系统在测试集上的结果(conllf1值)
图3展示了压缩算法适用的三种情况:
(a)表示结点node只有一个孩子结点,此时对node进行压缩,使得child成为parent新的孩子结点,接替node的位置;
(b)表示结点node不是np结点,此时对node进行压缩,使得parent成为children新的双亲结点;
(c)表示结点node只有一个孩子结点child,此时对child进行压缩,使得parent成为grandchildren新的双亲结点。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!