一种基于声音指导的遥感图像描述方法与流程
本发明属于信息处理技术领域,特别涉及一种遥感图像描述方法,可用于地震灾害评估和海洋监测等领域。
背景技术:
随着遥感以及相关技术的不断发展,更高分辨率的遥感图像的获取越来越方便。获取的高分辨率遥感图像已应用于地震灾害的分级评估和海洋观测等领域。每时每刻,都在产生大量的遥感图像,这些遥感图像从生成到传输都要耗费巨大的人力物力,如何能够更详尽的挖掘遥感图像当中的信息,以更有效地发挥遥感图像在全球观测等各个方面的重要作用具有重要意义。
为了挖掘遥感图像中的信息,需要研究基于遥感图像的语义理解,对高分辨率遥感图像进行描述,将高分辨率的遥感图像信息转化成为人类能够理解的文本信息。遥感图像不同于普通的自然图像:首先,遥感图像是利用传感器(卫星,航空航天器等)从远处来感知物体的手段;其次,传感器位置不同,对相同的物质会呈现出不同的大小和相对位置,使得遥感图像的语义理解更加困难;最后,因为遥感图像对于普通人而言不熟悉,在标注的时候存在一个不完全标注的问题,更使得遥感图像的语义理解与自然图像的语义理解大有不同。
为了利用有监督的机器学习手段解决遥感图像语义理解的问题,业内研究人员标注了相应的机器学习数据库。文献“B.Qu,X.Li,D.Tao,and X.Lu,“Deep semantic understanding of high resolution remote sensing image,”in Proceedings of the International Conference on Computer,Information and Telecommunication Systems,2016,pp.124–128”首次提出基于机器学习来研究遥感图像的语义理解方法,并提出了两个遥感语义理解方法的数据库,这两个数据库分别是UCM-captions和Sydney-captions。其中,UCM-captions包含2100张遥感图像,每张图像对应五句不同的文本标注,Sydney-captions包含613遥感图像,每张图像对应五句不同的文本标注。文献“X.Lu,B.Wang,X.Zheng,and X.Li,“Exploring models and data for remote sensing image caption generation,”IEEE Transactions on Geoscience and Remote Sensing,vol.56,no.4,pp.2183–2195,2017.”针对遥感图像不同于自然图像的类别模糊,尺度多变等特点,推出了数据库RSICD(Remote Sensing Image Caption Dataset),其中包含10921张遥感图像,并邀请不同的志愿者对图像进行了标注,每个图像对应五句不同的文本标注。
由于从数据库中通过图像检索生成句子是非常困难的,为了有效利用上述遥感图像数据库中的信息,技术人员采用了以下两类方法从数据库中获取遥感图像对应的句子:
一是基于循环神经网络来生成遥感图像描述的方法,这种方法通过循环神经网络来逐个单词地生成对应遥感图像的描述。B.Qu等人在文献“B.Qu,X.Li,D.Tao,and X.Lu,“Deep semantic understanding ofhigh resolution remote sensing image,”International Conference onComputer,Information and Telecommunication Systems,pp.124–128,2016.”中提出一种句子生成的框架,该框架基于两种不同的循环神经网络来进行句子的生成。利用神经网络的强大表征能力,图像使用预训练的深度模型后端全连接层的输出,然后利用循环神经网络来逐个单词地生成最终的描述。这种方法对数据库的依赖较强,因为最终生成的句子是和数据库当中的句子作对比,而且一个句子可能偏向于数据库中五个句子当中的简单句子,无法充分利用数据库每一句标注中的细分信息。
二是基于目标检测的方法。这种方法的核心思想是通过目标检测的算法来获取图像当中存在的目标,然后将目标填充到预定义的句子模板当中来进行句子的生成。句子模板是一些缺乏单词的句子,将任务转换为将检测到的目标准确的填充到句子对应的空位置上去。Z.Shi等人在文献“Z.Shi and Z.Zou,“Can a machine generate humanlike language descriptionsfor a remote sensing image?”IEEE Transactions on Geoscienceand Remote Sensing,vol.55,no.6,pp.3623–3634,2017.”中提出一种方法,不同于传统卷积神经网络,这个方法使用全卷积网络来编码图像的特征,并将目标按照视野的大小分为三个等级:单个目标级别,小场景级别和大场景级别。在获取到目标之后,再将这些获取到的目标填充到预定义的句子模板当中。句子模板的生成考虑了人的用法习惯,但是这种生成方式生成的句子相对比较固化,一些复杂的场景并不能有效的适用。
技术实现要素:
为解决现有的遥感图像描述方法无法充分利用数据库当中的标注、在一些复杂场景不能有效适用的问题,本发明提供了一种基于声音指导的遥感图像描述方法。
本发明的技术方案是:
一种基于声音指导的遥感图像描述方法,其特殊之处在于,包括以下步骤:
1)构建训练样本集和测试样本集:
首先为数据库中每一张原始遥感图像添加单词语音标注,所添加的单词语音标注的语义内容与原始遥感图像所描述的内容相关,然后将数据库中原始遥感图像及其对应的文本标注和单词语音标注进行划分,将一部分原始遥感图像及其对应的文本标注和单词语音标注划入训练样本集,其余划入测试样本集;
2)对训练样本集中的原始遥感图像及其对应的文本标注和单词语音标注进行表达:
2.1)利用预训练好的深度神经网络提取每张原始遥感图像的图像特征;
2.2)利用预训练好的词向量提取每张原始遥感图像所对应的五句文本标注的文本特征;
2.3)提取每张原始遥感图像所对应的单词语音标注的初步语音特征;
3)构建基于单词语音指导的网络框架,所述网络框架包括依次连接的声音模块、特征融合模块和输出模块;声音模块用于从步骤2.3)提取的初步语音特征中进一步进行单词语音信息的特征提取;特征融合模块用于对步骤2.1)得到的图像特征和声音模块输出的单词语音特征进行融合;输出模块用于逐个单词地生成描述句子;
4)对所述网络框架进行训练:
采用损失函数,结合训练样本集中的文本标注来反馈训练输出模块的模型参数、特征融合模块的模型参数和声音模块的模型参数;在训练的过程中,逐个选取文本标注当中的每一句进行训练,每一句当中的每个单词对应各个模块当中的一步;
5)待测遥感图像的描述:
5.1)输入待测遥感图像和用户语音;
5.2)利用预训练好的深度神经网络提取待测遥感图像的图像特征;
5.3)提取输入的用户语音特征;
5.4)将步骤5.2)得到的图像特征和步骤5.3)得到的用户语音特征输入到步骤4)中训练好的网络框架中,得到待测遥感图像的文本描述。
进一步地,步骤1)在划分时,将数据库中90%的原始遥感图像及其对应的文本标注和单词语音标注划入训练样本集,10%的原始遥感图像及其对应的文本标注和单词语音标注划入测试样本集。
进一步地,步骤2.1)中的所述深度神经网络采用VGG16、VGG19、AlexNet、GoogLeNet或ResNet。
进一步地,步骤2.2)具体为:将每个单词利用预训练好的词向量模型映射到固定的维度。
进一步地,步骤2.3)具体采用Mel-Frequency Cepstral Coefficients(MFCC)进行语音特征的初步提取。
进一步地,步骤3)中的声音模块、特征融合模块和输出模块均采用Gated Recurrent Unit(GRU)构建。
进一步地,步骤4)中对声音模块的模型参数进行训练的过程具体为:
第1步声音模块的模型当中,Gated Recurrent Unit(GRU)的表达式如下:
z1=σ(WzWss+bz),
其中:
ο表示Hadamard乘积;
σ的表达式如下:
Ws、Wz、Wh是需要学习的权重参数;
z1是更新门;
是中间变量;
h1是第一步输出的语音特征;
bz是计算z1时的偏置;bh是计算时的偏置;
s是步骤2.3)提取的初步语音特征;
tanh为双曲正切函数;
第2步至第t步中声音模块的模型当中,Gated Recurrent Unit(GRU)的表达式如下:
zt=σ(Uzht-1+bz),
rt=σ(Urht-1+br),
其中:ht-1是第t-1步输出的语音特征;
zt是更新门;
rt是重置门;
br是计算rt时的偏置;
ht是第t步输出的语音特征;
是中间变量;
Uz是计算zt时上一步的ht-1作为输入的映射权重;
Ur是计算rt时上一步的ht-1作为输入的映射权重;
Uh是计算时上一步的ht-1作为输入的映射权重。
进一步地,步骤4)中对特征融合模块的模型参数进行训练的过程具体为:
第1步特征融合模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z′1=σ(W′z(Wv′v+h1)+U′zh′0+b′z),
r1′=σ(W′rh1+U′rh′0+b′r),
其中:
W′s、W′z、W′h是需要学习的权重参数;
z′1是更新门;
b′z是计算z′1时的偏置;
v是步骤2.1)中提取到的图像特征;
b′h是计算时的偏置;
是中间变量;
h1是声音模块第1步输出的特征;
第2步至第t步特征融合模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z′t=σ(W′zht+U′zh′t-1+b′z),
rt′=σ(Wr′ht+U′rh′t-1+b′r),
其中:
W′r、W′z、W′h、U′r、U′z、U′h是需要学习的权重参数;
z′t是更新门;
h′t-1是第t-1步输出的融合特征;
h′t是第t步输出的融合特征;
ht是声音模块第t步输出的语音特征;
rt′是重置门;
b′r是计算rt′时的偏置;
是中间变量。
进一步地,步骤4)中对输出模块的模型参数进行训练的过程具体为:
第1步输出模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z1″=σ(Wz″h′T+U″zh″0+b″z),
r1″=σ(Wrh′T+U″rh″0+b″r),
w1=softmax(h1″),
其中:
Wr″、Wz″、W″h,U″r,U″z,U″h是需要学习的权重参数;
z″1是更新门;
h′T是特征融合模块最终输出的融合特征;
h″0是一个句子开始的标志;
b″z是计算z″1时的偏置;
r″1是重置门;
b″r是计算r″1时的偏置;
是中间变量;
h″1是第一步中间输出;
w1是第1步后经全连接层生成的单词;
第2步至第t步声音模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z″t=σ(U″zh″t-1+b″z),
rt″=σ(U″rh″t-1+b″r),
wt=softmax(h″t),
其中:
z″t是更新门;
r″t是重置门;
h″t-1是第t-1步的输出;
是中间变量;
h″t是第t步的中间输出;
wt是第t步后经全连接层生成的单词。
进一步地,步骤4)训练过程中采用的损失函数为进行深度神经网络训练;其中:
yt+1是真实标注句子当中的一个单词;
wt+1是对应的生成的单词;
损失函数的第二项是权重的正则化,λ是正则化权重系数。
本发明的优点:
本发明考虑到了遥感图像涉及目标分布复杂的特点,从观察者的角度出发,通过为现有数据库中的原始遥感图像添加对应的单词语音标注(以单词作为约束条件),以限定观察者感兴趣的区域范围,将语音标注当中包含的信息作为描述遥感图像的指导信息,使得生成的句子更贴近观察者的目的,也有利于适应复杂的场景。比如同样是一个机场,包含飞机等物体,有的观察者想要获得的描述是针对飞机的,有的观察者想要获得的描述是针对机场的。而针对这两个不同的需求,现有的方法是无法实现的。而且,采用单词语音标注,方便人机交互,也更加符合实际人机交互的应用需求。
附图说明
图1为本发明基于声音指导的遥感图像描述方法流程图。
具体实施方式
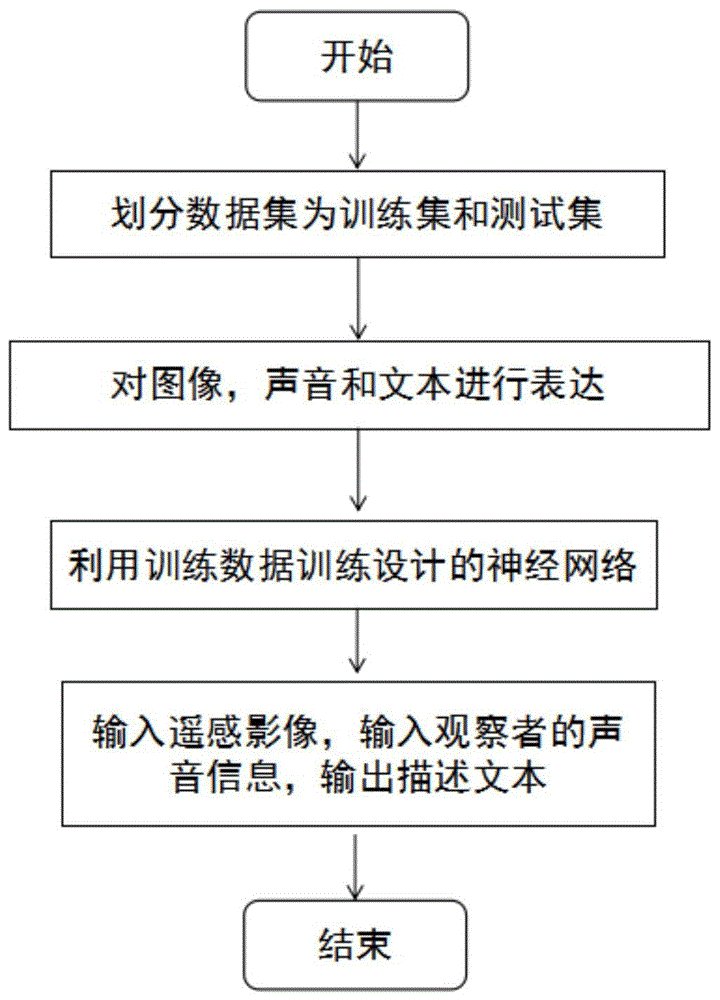
参照图1,本发明所提供的基于声音指导的遥感图像描述方法的实现的步骤如下:
步骤1)构建训练样本集和测试样本集:
首先为数据库中每一张原始遥感图像添加单词语音标注,所添加的单词语音标注的语义内容与原始遥感图像所描述的内容相关,然后将数据库中原始遥感图像及其对应的文本标注和单词语音标注进行划分,将一部分原始遥感图像及其对应的文本标注和单词语音标注划入训练样本集,其余划入测试样本集;需要说明的是,本发明也可以不采用现有数据库,而重新构建数据库。本步骤在划分时,可以将数据库中90%的原始遥感图像及其对应的文本标注和单词语音标注划入训练样本集,10%的原始遥感图像及其对应的文本标注和单词语音标注划入测试样本集。
步骤2)对训练样本集中的原始遥感图像及其对应的文本标注和单词语音标注进行表达:
2.1)利用预训练好的深度神经网络提取每张原始遥感图像的图像特征;所述深度神经网络可以采用VGG16、VGG19、AlexNet、GoogLeNet或ResNet。
2.2)利用预训练好的词向量提取每张原始遥感图像所对应的五句文本标注的文本特征,具体为:
将每个单词利用预训练好的词向量模型映射到固定的维度;其中,预训练好的词向量模型使用Global Vectors(GloVe,出自论文:J.Pennington,R.Socher,and C.Manning,“Glove:Global vectors forword representation,”in Proc.Conf.Empirical Methods Natural Lang.Process.,2014,pp.1532–1543.),其中固定的维度和词向量模型有关,随后该固定的维度被映射到后续步骤4.3)当中h″0的维度。
2.3)提取每张原始遥感图像所对应的单词语音标注的初步语音特征,具体可采用Mel-Frequency Cepstral Coefficients(MFCC)进行语音特征的初步提取。
步骤3)采用Gated Recurrent Unit(GRU构建基于单词语音指导的网络框架,所述网络框架包括依次连接的声音模块、特征融合模块和输出模块;声音模块用于从步骤2.3)提取的初步语音特征中进一步进行单词语音信息的特征提取;特征融合模块用于对步骤2.1)得到的图像特征和声音模块输出的单词语音特征进行融合;输出模块用于逐个单词的生成描述句子。声音模块、特征融合模块和输出模块也可采用其它Recurrent NeuralNetwork及其变种构建。
步骤4)对所述网络框架进行训练:
采用损失函数,结合训练样本集中的文本标注来反馈训练输出模块的模型参数、特征融合模块的模型参数和声音模块的模型参数;在训练的过程中,逐个选取文本标注当中的每一句进行训练(例如可以先选择第一张原始遥感图像对应的第一句文本标注,然后选择第五张原始遥感图像对应的第三句文本标注,再选择第二张原始遥感图像对应的第二句文本标注……,选择的顺序不做特定要求,只要能够遍历每一句文本标注进行训练即可),每一句当中的每个单词对应各个模块当中的一步;具体训练过程如下:
4.1)对声音模块的模型参数进行训练的过程具体为:
第1步声音模块的模型当中,Gated Recurrent Unit(GRU)的表达式如下:
z1=σ(WzWss+bz),
其中:
ο表示Hadamard乘积;
σ的表达式如下:
Ws、Wz、Wh是需要学习的权重参数;
z1是更新门;
是中间变量;
h1是第一步输出的语音特征;
bz是计算z1时的偏置;bh是计算时的偏置;
s是步骤2.3)提取的初步语音特征;
tanh为双曲正切函数;
第2步至第t步中声音模块的模型当中,Gated Recurrent Unit(GRU)的表达式如下:
zt=σ(Uzht-1+bz),
rt=σ(Urht-1+br),
其中:ht-1是第t-1步输出的语音特征;
zt是更新门;
rt是重置门;
br是计算rt时的偏置;
ht是第t步输出的语音特征;
是中间变量;
Uz是计算zt时上一步的ht-1作为输入的映射权重;
Ur是计算rt时上一步的ht-1作为输入的映射权重;
Uh是计算时上一步的ht-1作为输入的映射权重。
4.2)对特征融合模块的模型参数进行训练的过程具体为:
第1步特征融合模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z′1=σ(W′z(Wv′v+h1)+U′zh′0+b′z),
r1′=σ(Wr′h1+U′rh′0+b′r),
其中:
Ws′、W′z、W′h是需要学习的权重参数;
z′1是更新门;
b′z是计算z′1时的偏置;
v是步骤2.1)中提取到的图像特征;
b′h是计算时的偏置;
是中间变量;
h1是声音模块第1步输出的特征;
第2步至第t步特征融合模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z′t=σ(Wz′ht+U′zh′t-1+b′z),
rt′=σ(Wr′ht+U′rh′t-1+b′r),
其中:
W′r、W′z、W′h、U′r、U′z、U′h是需要学习的权重参数;
z′t是更新门;
h′t-1是第t-1步输出的融合特征;
h′t是第t步输出的融合特征;
ht是声音模块第t步输出的语音特征;
rt′是重置门;
b′r是计算rt′时的偏置;
是中间变量。
4.3)对输出模块的模型参数进行训练的过程具体为:
第1步输出模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z″1=σ(Wz″hT′+U″zh″0+b″z),
r1″=σ(Wr″h′T+U″rh″0+b″r),
w1=softmax(h″1),
其中:
W″r、W″z、W″h,U″r,U″z,U″h是需要学习的权重参数;
z″1是更新门;
h′T是特征融合模块最终输出的融合特征;
h″0是一个句子开始的标志;
b″z是计算z″1时的偏置;
r1″是重置门;
b″r是计算r″1时的偏置;
是中间变量;
h″1是第一步中间输出;
w1是第1步后经全连接层生成的单词;
第2步至第t步声音模块的模型中,Gated Recurrent Unit(GRU)的表达式如下:
z″t=σ(U″zh″t-1+b″z),
rt″=σ(U″rh″t-1+b″r),
wt=softmax(h″t),
其中:
z″t是更新门;
rt″是重置门;
h″t-1是第t-1步的输出;
是中间变量;
h″t是第t步的中间输出;
wt是第t步后经全连接层生成的单词。
上述训练得到的权重参数构成了所述网络框架的参数。
上述训练过程中采用的损失函数为进行深度神经网络训练;其中:
yt+1是真实标注句子当中的一个单词;
wt+1是对应的生成的单词;
损失函数的第二项是权重的正则化,λ是正则化权重系数。
步骤5)生成遥感图像的描述:
5.1)从测试样本集中任意选取一张原始遥感图像作为待测图像,或者输入一张待测遥感图像并输入用户语音;
5.2)利用预训练好的深度神经网络提取所述待测图像的图像特征;
5.3)提取所述待测图像所对应的单词语音标注的初步语音特征,或者提取输入的用户语音的用户语音特征;
5.4)将步骤5.2)得到的图像特征和步骤5.3)得到的初步语音特征/用户语音特征输入到步骤4)中训练好的网络框架中,得到待测图像的文本描述。
技术效果实验验证:
1.仿真条件
在中央处理器为Intel(R)Xeon(R)CPU E5-2650 V4@2.20GHz、内存500G、Ubuntu 14.04.5操作系统上,运用Python软件进行仿真。
实验中使用的图像数据库为公开的数据集RSICD,并为该数据集RSICD中的每一张遥感图像添加了单词语音标注。一般情况下,要求单词语音标注只要为单词即可,比如airport,bridges,buildings,trees,pond,port,railway,river等;最好使单词语音标注的内容与遥感图像有关,例如,输入的声音包含的语义内容与数据库中的至少一张遥感图像相关。
2.仿真内容
在RSICD数据集上,对本发明方法进行实验验证。数据集的划分标准为90%训练,10%测试。为了证明方法的有效性,我们选取了五个现有方法作为对比方法进行比较,所选取的五个对比方法为:VLAD+RNN(Vector of Locally Aggregated Descriptors+Recurrent Neural Networks),VLAD+LSTM(Vector of Locally Aggregated Descriptors+Long Short-Term Memory),mRNN(multimodal Recurrent Neural Networks),mLSTM(multimodal Long Short-Term Memory),mGRU(multimodal Gated Recurrent Units)。其中,
1)VLAD+RNN和VLAD+LSTM是在文献“X.Lu,B.Wang,X.Zheng,and X.Li,“Exploring models and data for remote sensing image caption generation,”IEEE Transactions on Geoscience and Remote Sensing,vol.56,no.4,pp.2183–2195,2017.”中提出的。
2)mRNN,mLSTM在文献“B.Qu,X.Li,D.Tao,and X.Lu,“Deep semantic understanding of high resolution remote sensing image,”International Conference on Computer,Information and Telecommunication Systems,pp.124–128,2016.”中有详细介绍。
3)mGRU是在文献“X.Li,A.Yuan,and X.Lu,“Multi-modal gated recurrent units for image description,”Multimedia Tools and Applications,pp.1–23,2018.”中提出的。
按照具体实施方式部分的步骤进行试验,得到本发明的实验结果,再在同样的数据集上完成对比方法的实验。
使用的评价标准是针对图像描述算法公认的评价指标,包括BLEU-1,BLEU-2,BLEU-3,BLUE-4,METEOR,ROUGE_L,CIDEr,SPICE。BLEU代表的是生成句子中单词的数量和标准句子的单词重合度,其中后缀1,2,3,4分别代表连续多少个单词相似。METEOR用过学习生成句子和标准句子之间的映射来评价句子的生成质量。ROUGE_L通过计算准确率和召回率的加权调和平均来评价句子质量。CIDEr从词频和逆文本频率指数来衡量生成句子的好坏。SPICE从语义图结构的角度来评价生成句子的质量。指标得分越高,代表句子描述的效果越好,实验结果如下表所示(“-”代表对应方法的论文没有提供该指标)。
- 还没有人留言评论。精彩留言会获得点赞!