一种面向手机文档的自动分类方法与流程
本发明涉及文档管理领域,特别是涉及一种面向手机文档的自动分类方法。
背景技术:
随着互联网的发展,数字化办公也在随其不断发展,但是在这个过程中也逐渐暴露出一些问题。而其中最明显的就是大量数字化办公带来的大量文件与人们固有的惰性所带来的文档积压,从而使得人们的文档分类混乱不堪,降低了办公效率和办公体验。根据国家档案局的调查显示:已有近80%的中央和国家机关、中央企业采用办公自动化或电子政务系统,产生各类电子文件近2亿件。由此不难预见,在不久的将来,电子文件将成为政府、企事业信息资源的主要承载体和表现形式。针对手机上的文档驳杂、管理与分类混乱等问题,致力于文档管理自动化,建立一个文档自动分类管理系统,使人们对自己手机中的文件一目了然,方便对手机中的文档进行分类和查找。不仅承载了对于文件的有效管理功能,更关键的是还对文档实现了文本智能化自动分类,使庞大驳杂的本地文档自动化、智能化归类。
而目前为止,非结构化文档(Word/PDF/PPT)分类只局限于依据文档中的文本进行分类,并且多数方法研究的重点是自然语言处理(NLP)。往往忽视了文档中图像的存在,但是图像也是人类主要的信息源之一,其中可能包含了该文件的重要信息,是不能被忽略的。并且在以图像为主的非结构化文档文件中,图像内容在分类时也是一个重要的影响因素。现有的办公软件注重文本、表格等过程上的处理,但真正注重对大量文档进行自动归纳分类的系统在市场上还是一片空白,并且现有文档分类方法,还存在着不足,存在有待研究改进的地方。
技术实现要素:
为解决上述技术问题,本发明提供一种面向手机文档的自动分类方法。
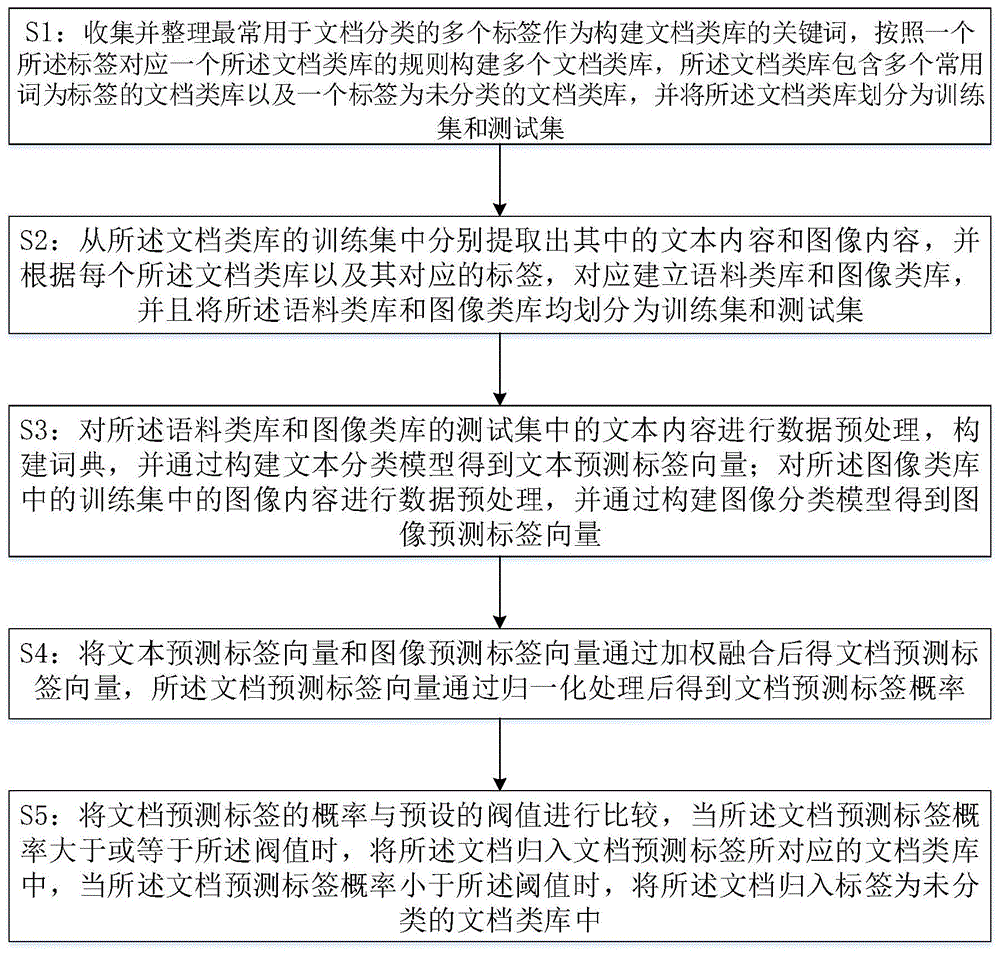
为解决上述技术问题,本发明采用的一个技术方案是:提供一种面向手机文档的自动分类方法,包括S1:收集并整理最常用于文档分类的多个标签作为构建文档类库的关键词,按照一个所述标签对应一个所述文档类库的规则构建多个文档类库,所述文档类库包含多个常用词为标签的文档类库以及一个标签为未分类的文档类库,并将所述文档类库划分为训练集和测试集;
S2:从所述文档类库的训练集中分别提取出其中的文本内容和图像内容,并根据每个所述文档类库以及其对应的标签,对应建立语料类库和图像类库,并且将所述语料类库和图像类库均划分为训练集和测试集;
S3:对所述语料类库和图像类库的测试集中的文本内容进行数据预处理,构建词典,并通过构建文本分类模型得到文本预测标签向量;对所述图像类库中的训练集中的图像内容进行数据预处理,并通过构建图像分类模型得到图像预测标签向量;
S4:将文本预测标签向量和图像预测标签向量通过加权融合后得文档预测标签向量,所述文档预测标签向量通过归一化处理后得到文档预测标签概率;
S5:将文档预测标签的概率与预设的阈值进行比较,当所述文档预测标签概率大于或等于所述阈值时,将所述文档归入文档预测标签所对应的常用分类词的文档类库中,当所述文档预测标签概率小于所述阈值时,将所述文档归入标签为未分类的文档类库中。
优选的,所述步骤S1中还包括一个文档在多个文档类库中出现的情形,即假设待分类文档为Xi,其中Yi为待分类文档Xi所对应的文档类库的集合,j为所有可能的文档类库个数。
优选的,所述步骤S2中将每个所述文本类库中的图像内容中的文字通过OCR技术识别后作为文本内容加入相应的语料类库中。
优选的,所述步骤S3具体包括S31:采用中文分词技术对所述文本内容进行文本分词;
S32:对所述步骤S31中的文本分词结果去除停用词和低频词,具体为,通过在所述分词结果中剔除常用的停用词表中的停用词,根据文档文本大小设置最小词频,过滤掉低于所述最小词频的低频词;
S33:使用Wor2vec工具包把步骤S32中去除了停用词和低频词后的文本内容通过映射的方法将所述文本内容以词向量的形式表示;
S34:使用卷积神经网络进行进一步特征提取,其中卷积层对所述步骤S33中的所述词向量进行初步特征提取,并将提取的初步特征输入池化层产生特征向量,然后全连接层将所有的所述特征向量连接,并且添加一个输出层,并使用sigmoid激活函数,计算出每个标签的概率,最后输出文本预测标签向量。
优选的,所述步骤S3还具体包括S35:对图像内容进行旋转、缩放、裁剪以及归一化;
S36:对所述步骤S35处理后的图像内容进行卷积层初步特征提取,并将提取的初步特征输入池化层产生特征向量,然后全连接层将所有的所述特征向量连接,并且添加一个输出层,并使用sigmoid激活函数,计算出每个标签的概率,最后输出图像预测标签向量。
优选的,所述文本分类模型采用交叉熵公式衡量性能,所述图像分类模型采用平均方差评估学习过程中的损失。
区别于现有技术的情况,本发明的有益效果是:
1.能够实现非结构化文档快速有效的分类
2.利用机器学习方法构建文本分类模型和图像分类模型,从完整文档抽取出文字内容以及图像内容两个部分并对应建立语料类库和图像类库,进行分类,在这个过程中通过大量数据训练学习,使文档实现了机器自动化分类,节约了人力物力,进而提高了工作效率。
3.将语料类库以及图像类库的分类结果,作为分类指标衡量文档分类结果,这样使分类结果更为精确,适用的文档内容以及格式更为广泛。
附图说明
图1是本发明实施例的面向手机文档的自动分类方法的流程示意图;
图2是图1所示的面向手机文档的自动分类方法的步骤S3的具体流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明包括S1:收集并整理最常用于文档分类的多个标签作为构建文档类库的关键词,按照一个所述标签对应一个所述文档类库的规则构建多个文档类库,所述文档类库包含多个常用词为标签的文档类库以及一个标签为未分类的文档类库,并将所述文档类库划分为训练集和测试集。
其中,在整理收集文档类库的标签时,分类的的标签数据的可以采用爬行器爬取,也可以选取搜索引擎在文档分类中相关度较高的词语来综合选取每个文档类库的标签。构建类库的方式采用爬行器爬取或开源文档获取或手动收集等方式。在本实施例中,共构建了N+1个文档类库,包括N个以常用词作为标签的文档类库和一个标签为未分类的类库,标签为未分类的文档类库中包含不属于以常用于文档分类的常用词作为标签的文档,在初始状态下,该文档类库中不含任意文档,在后续的步骤中,除了在步骤S5的文档分类结果中需要使用,其余情况均不考虑该文档类库参与。
在本实施例中,所述步骤S1中还包括一个文档在多个文档类库中出现的情形,即假设待分类文档为Xi,其中Yi为待分类文档Xi所对应的多个标签的文档类库的集合,j为所有可能的标签对应的文档类库个数。
S2:从所述文档类库的训练集中分别提取出其中的文本内容和图像内容,并根据每个所述文档类库以及其对应的标签,对应建立语料类库和图像类库,并且将所述语料类库和图像类库均划分为80%的训练集和 20%的测试集。
其中,将图像类库中的图像内容抽取到一个文件夹中保存将图像内容中的文字通过OCR技术识别后作为文本内容加入相应的语料类库中。在本实施例中,每个文本类库中的图像内容中的文字通过OCR技术识别后作为文本内容加入相应的语料类库中。例如可以采用百度OCR API接口,其功能包括高精度通用文字API、表格文字识别API以及二维码识别API,能够提取图片中的通用文字、生僻字、表格文字、证件文字等。
S3:对所述语料类库和图像类库的训练集中的文本内容进行数据预处理,构建词典,并通过构建文本分类模型得到文本预测标签向量;对所述图像类库中的训练集中的图像内容进行数据预处理,并通过构建图像分类模型得到图像预测标签向量。
如图2所示,其中步骤S3具体包括S31:采用中文分词技术对所述文本内容进行文本分词;
英文以空格作为天然的分隔符,而中文因其语言的特殊性除标点符号外,文字不存在间隔,所以中文分词是自然语言处理的基础,影响后续处理结构。中文分词技术现较为成熟,所以可以直接采用现有技术算法或开源项目工具对语料类库中的文本进行分词处理,例如:jieba、 SnowNLP、THULAC。
S32:对所述步骤S31中的文本分词结果去除停用词和低频词,具体为,通过在所述分词结果中剔除常用的停用词表中的停用词,根据文档文本大小设置最小词频,过滤掉低于所述最小词频的低频词;
S33:使用Wor2vec工具包把步骤S32中去除了停用词和低频词后的文本内容通过映射的方法将所述文本内容以词向量的形式表示;
S34:使用卷积神经网络进行进一步特征提取,其中卷积层对所述步骤S33中的所述词向量进行初步特征提取,并将提取的初步特征输入池化层产生特征向量,然后全连接层将所有的所述特征向量连接,并且添加一个输出层,并使用sigmoid激活函数,计算出每个标签的概率,最后输出文本预测标签向量。
具体为,构造A*B的矩阵,其中A是单词数,B代表词向量维度。为了进行批向量处理,将文本固定为长度A。然后对每个文本进行卷积操作,采用过滤器W∈Rhb,滤波器的大小为h*b,其中h是n-gram的长度,则卷积的目标为ci=f(Wxi:i+h-1+d(c)),其中d是偏移量,f非线性激活函数。在卷积过程中,此过滤器在可能会在N-h+1窗口上产生一组特征{c1,c2,…,cN-h+1}。然后将这组特征输入至池化层产生特征向量这样就实现了从一组特征中提取单个特征的目标,然后在全连接层中将所有的特征向量连接,并且添加一个输出层,使用sigmoid激活函数,计算出每个标签的概率,最后输出文本预测标签向量
为了评估文本分类模型的性能,在原有输出层再加上一层输出层,,根据交叉熵公式进行衡量,具体为:其中p(x) 表示分类x是正确分类的概率,p的取值只能是0或者1,q(x)则为x 种类为正确分类的预测概率,取值范围为(0,1)。
S35:对图像内容进行旋转、缩放、裁剪以及归一化;
S36:对所述步骤S35处理后的图像内容进行卷积层初步特征提取,并将提取的初步特征输入池化层产生特征向量,然后全连接层将所有的所述特征向量连接,并且添加一个输出层,并使用sigmoid激活函数,计算出每个标签的概率,最后输出图像预测标签向量。本步骤中的具体处理过程和步骤S34的具体处理过程相同,最后输出图像预测标签向量
为了衡量图像分类模型的性能,在模型上再加上一层输出层,利用平均方差评估学习过程中的损失,具体代价函数为:其中Ocnn代表图像分类模型预测的数据集的标签,Oreal代表数据集真实的标签,当e越小时,说明模型预测性能更好。
S4:将文本预测标签向量和图像预测标签向量通过加权融合后得文档预测标签向量,所述文档预测标签向量通过归一化处理后得到文档预测标签概率。
S5:将文档预测标签概率与预设的阈值进行比较,当所述文档预测标签概率大于或等于所述阈值时,将所述文档归入文档预测标签所对应的常用分类词文档类库中,当所述文档预测标签概率小于所述阈值时,将所述文档归入标签为未分类的文档类库中。
具体为,将文本预测标签向量和图像预测标签向量进行加权融合,计算得出文档标签向量计算公式如下:其中a为文本特征相似度权重,b为图像特征相似度权重,并使用 sigmoid函数进行数值处理,将多个分类的输出数据归一化,转化为最终的文档与猜测标签概率Pj,这样相当于在原有的两个模型上,利用加权平均的方法,添加一层LR分类器,完成文本分类模型和图像分类模型的融合,最后当文档预测标签概率Pj(1≤j≤N)大于阈值,则将所述文档归入文档预测标签所对应的常用分类词的文档类库中。
进一步地,阈值不能过高或者过低,过高则文档无法被同时归类于几个相关度较高的类别中,过低则不利于正确分类,失去意义。为了确定阈值,首先将文本测试集以及图像测试集均分为多等分,利用交叉验证的方法,验证模型并保留效果最好的文档分类模型,这里采用汉明损失(Hamming loss)来衡量文档分类模型的准确度,Hamming loss可表示所有标签中错误样本的比例,所以该值越小则网络的分类能力越强。计算公式如下:
其中|D|表示样本总数,|L|表示标签总数,xi和yi分别表示预测结果和真值,xor表示异或运算,并且规定在此过程中,a、b权重为固定值,且a、b满足a+b=1,由文档类库测试集多次测试,可得阈值。
在得出文本特征相似度权重a和图像特征相似度权重b时,引入精度与召回率,准确率(Precision)是指对于给定的测试数据集,正确被检索的相关文档数占文档类库中实际被检索到的相关文档数的比例。召回率(Recall Rate)是指给定的测试数据集,被正确检索出的相关文档数占文档类库中所有的相关文档数的比例。在多标签时,其计算公式变形如下:
其中|D|表示样本总数,xi和yi分别表示预测结果和真值,同理固定阈值为最优值,将a、b同样等分为为[0,1]区间内以0.01为刻度增长的多等分,且a、b满足a+b=1。由文档类库测试集多次测试,并综合考虑精度与召回率两个指标,可得出文本特征相似度权重a为以及图像特征相似度权重b。
当Pj大于或者等于阈值时,Xi成功被归类到标签为j的文档类库中,并更新当前文档类库以及当前模型;但Pj小于阈值的时候,Xi被归类到具有未分类标签的文档类库,而未被归类到任意具有常用词标签的文档类库中,并且更新未分类的文档类库。
根据文档预测标签概率与阈值的关系,文档可能被分入多个常用分类词的标签对应的多个文档类库中,也可能会被划入具有未分类标签的文档类库中,即待分类文档Xi分类后,Z 代表更新的文档类库。其中Y'i为文档Xi所对应的标签的文档集合,I(1≤I≤N+1)为所有可能的标签个数,当I为N+1 时,表示待分类文档Xi被归类至标签标签为未分类的文档类库,未被归类至N个常用分类词标签对应的文档类库中;为I为l时表示待分类文档Xi被同时归入l个标签对应的文档类库中。
通过上述方式,本发明能够实现非结构化文档快速有效的分类,利用机器学习方法构建文本分类模型和图像分类模型,从完整文档抽取出文字内容以及图像内容两个部分并对应建立语料类库和图像类库,进行分类,在这个过程中通过大量数据训练学习,使文档实现了机器自动化分类,节约了人力物力,进而提高了工作效率;并将语料类库以及图像类库的分类结果,作为分类指标衡量文档分类结果,这样使分类结果更为精确,适用的文档内容以及格式更为广泛。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!