一种在线社交网络中节点相似性与凝聚力并重的信息传播方法与流程
本发明属于信息传播技术领域,具体涉及在线社交网络中节点相似性与凝聚力并重的信息传播方法。
背景技术:
随着计算机科学和移动计算的飞速发展,在线社交网络(osn,onlinesocialnetwork)已成为信息交流与传播的主流平台,如facebook、twitter、网上购物等,甚至是电脑游戏玩家之间的体验分享。不同的个体可能共享相同的兴趣或偏好,即使他们在现实生活中互不认识彼此。一般地,在形成自己对创新、产品、经济和政治观点的过程中,人们易受到朋友、亲人的影响。因此,挖掘用户之间的关系,提高信息传播的速率与范围,已引起学者的广泛关注。
信息传播旨在让一个社交网络中的尽可能多用户接受该信息,其作用类似于广告推荐,如基于用户购买历史的推荐策略能为用户提供个性化推荐服务。信息传播的规律对于实现信息在整个社会网络中的扩散至关重要。并且,发起信息传播的第一个人对信息传播的效果有着至关重要的影响。因此,如何识别高影响力的用户,并将之作为传播发起者是提高信息传播效率的重要内容。
目前,应用最广泛的信息传播/广告推荐方法有:
(1)协同过滤算法。协同过滤算法分为两种,一种为基于产品的协同过滤算法,另一种为基于用户的协同过滤算法。基于产品的协同过滤算法,其主要思想是根据产品之间潜在的关系来预测用户对产品的偏好,而基于用户的协同过滤算法,则是根据用户的相似性来预测用户对产品的偏好。协同过滤算法可处理非结构化对象,不需要建模,因此在电子商务中得到了广泛的应用。然而,协同过滤面临三个挑战,即冷启动用户、冷启动产品和数据稀疏性。冷启动用户是指没有购买记录的新用户,冷启动产品是指没有销售记录可供参考的新产品,数据稀疏性是指很少有用户购买该产品。此外,由于高时间复杂性,现有的协同过滤算法不适用于大型在线社交网络。(2)病毒式营销策略。传统的传染病模型为解决广告推荐的冷启动问题开辟了一条新途径。sir(susceptible/infectious/removed)模型将用户分为三类:易感者、感染者和免疫者。感染者代表被感染的个体,可能会传播疾病给邻居;易感者是指那些当前健康但未来容易被已感染邻居感染的人;免疫者指的是已经治愈或对疾病免疫的用户。ic(independentcascade)模型假设种子节点以不确定的概率感染其邻居。无论感染是否成功,种子节点仅有一次机会感染其邻居。即使他的态度仍然为1,种子节点也会失去其传染性。在其推荐周期之后,种子节点将失去其传染性。lt(linearthreshold)模型中,多个节点可同时向同一节点推荐广告,当且仅当节点的信任度大于该节点的信任阈值时,该节点才会接纳该广告。然而,协同过滤算法与病毒式营销策略均未区分节点的影响力。若将影响力最大的节点作为传播发起者,则传播效果事半功倍。目前,社交网络中影响力最大化问题的解决方案有:
(1)pagerank算法:pagerank是google搜索引擎的核心算法,用于衡量网页的重要性。算法中用pr值来表示网页重要性的高低,若一个网页被很多其他网页指向,则意味着这个网页比较重要,pr值会相对较高;如果一个pr值很高的网页指向另一个网页,则被指向网页的pr值会因此而增加。pagerank算法适用于大规模网络,其时间复杂度为o(n),运行时间较短。
(2)贪心算法及其改进:社交网络中的影响力最大化问题为np难问题,社交网络中影响力最大化问题可由贪心算法解决。贪心算法是采用迭代方法,旨在找到最具影响力的节点集合。
这两种算法均不适用于社交网络。原因在于:贪心算法产生的不是全局最优解,而是局部最优解,且时间复杂度高;pagerank算法可以产生全局最优解,但未考虑节点的偏好,无法动态更新节点的信任度。
技术实现要素:
针对现有技术存在的问题,本发明旨在提供一种在线社交网络中相似性与凝聚力并重的信息传播方法,解决了目前信息传播方法不能适用于在线社交网络、信息传播影响力不能最大化的问题。
为实现上述信息传播过程,本发明采用的技术方案如下:
一种在线社交网络中相似性与凝聚力并重的信息传播方法,本方法用带权有向图g(v,e)表示社交网络,v是社交网络n个节点集合,其中p,q∈v,e是非对称的n×n矩阵,代表节点之间的影响力,其中ep,q∈e,ep,q表示节点p对节点q的影响力,且ep,q≠eq,p,包括以下步骤:
步骤1计算种子节点集合s:
步骤1.1计算g(v,e)中所有节点的中心度集合cen、所有节点的凝聚力集合cohes以及节点间的相似性集合sim:
cen={cen(p)|p∈v},
cohes={cohes(p)|p∈v},
sim={sim(p,q)|p,q∈v},
其中,cen(p)表示节点p的中心度,
步骤1.2计算impt:
d=λ·repmat(cohes,n,1)+(1-λ)·sim
其中,imp代表节点在g(v,e)中的重要性,impt为t时刻节点重要性等级矩阵,h是一个元素全为1的n×n矩阵,m为概率转移矩阵,m中任一行的所有元素之和等于1,d为阻尼系数矩阵,λ为权重因子,0<λ<1;
步骤1.3按照t时刻每个节点的imp对所有节点进行降序排列得到sortt,按照t+1时刻每个节点的imp对所有节点进行降序排列得到sortt+1,直至|sortt+1-sortt|=0,排序过程终止,此时选前k个节点形成种子节点集合s,剩余n-k个节点为普通节点,k≤n;
步骤2通过种子节点集合s向所有普通节点进行信息推荐;
步骤2.1判断所有普通节点中是否存在未接受信息推荐的节点,若不存在,算法结束;否则t=t+1,转步骤2.2;
步骤2.2在t时刻,种子节点y向其普通邻居节点x同时进行信息推荐,t处在普通邻居节点x和种子节点y的推荐周期t内,x∈{v-s},
其中,本发明定义推荐周期t为:只能在规定的t时间范围内推荐信息或者接受信息推荐;在推荐周期t内,种子节点y可向普通邻居节点x推荐信息,普通邻居节点x可接受种子节点y的信息推荐;
定义信任度更新规则为:
o代表信任度,ox,t表示t时刻普通邻居节点x的信任度,oy,t-1表示t-1时刻种子节点y的信任度;
w为影响力矩阵,w=(1-α-β)·e+α·repmat(cohes,n,1)+β·sim,wy,x表示种子节点y对普通邻居节点x的影响力,α和β是权重因子,且0<(α+β)<1;
步骤2.3普通邻居节点x在t时刻接受信息推荐与否,服从二项分布ax,t~b(1,ox,t),ax,t代表t时刻普通邻居节点x的态度,b(1,ox,t)代表普通邻居节点x以概率ox,t接受信息推荐,若二项分布结果为1,表示普通邻居节点x在t时刻接受信息推荐,则ax,t更新为1,转步骤2.4;否则转步骤2.1;
步骤2.4以普通邻居节点x在t时刻的恢复率rx,t进行随机恢复,rx,t=1-ox,t,恢复时服从二项分布ax,t~b(1,rx,t),b(1,rx,t)代表普通邻居节点x的态度ax,t以rx,t的恢复率从活跃状态1恢复至不活跃状态0,若恢复成功,则ax,t=0,从g(v,e)中移除普通邻居节点x,转步骤2.1;若恢复不成功则普通邻居节点x成为种子节点,转步骤2.1。
与现有技术相比,本发明带来的技术效果是:
本发明的方法,考察到节点的中心性、相似性与凝聚力,结合pagerank算法,按重要性对节点排序,设计了面向社交网络信息传播的信任度更新规则与并行推荐规则,不仅模拟信息在真实世界的传播过程,而且能找出最有影响力的用户,能做到信息传播最大化。
附图说明
图1为本发明所提方法的流程图;
图2为社交网络示例;
图3为本发明中社交网络并发性实例;
图4为本发明的运行流程;
图5至图11为本发明方法与现有方法算法性能分析比较图。其中:
图5为epinions网络中,节点数为2000,受影响节点数量-迭代次数关系图;
图6为epinions网络中,节点数为6000,受影响节点数量-迭代次数关系图;
图7为epinions网络中,节点数为2000,受影响节点数量-种子节点数量关系图;
图8为epinions网络中,节点数为6000,受影响节点数量-种子节点数量关系图;
图9为epinions网络中,节点数为2000,运行时间-种子节点数量关系图;
图10为epinions网络中,节点数为6000,运行时间-种子节点数量关系图;
图11为epinions网络中,运行时间-网络规模关系图;
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
具体实施方式
社交网络中已有的信息传播策略均未解决在线社交网络中影响力最大化问题。对于社交网络中的影响力最大化问题,大多数解决方案采用启发式算法、贪心算法或贪心算法的改进算法,但从未考虑社交网络中节点的拓扑属性(即中心性、凝聚力和相似性)的影响。贪心算法的改进算法提高了算法的整体效率,但牺牲了精度,贪心算法的劣势在于算法的高时间复杂度。pagerank算法利用网页间的拓扑对网页重要性排序,该排序算法采用迭代思想,结合社交网络的有向边随机游走模型,更新网页的排序,该算法以其高效性而被研究者广泛应用于各个领域。但pagerank无法动态更新每个节点的状态,不能直接解决节点相似性与中心性的影响力最大化问题。传统pagerank算法用pr值代表网络中节点的影响力等级,但在社交网络中受阻尼系数的影响,导致pr值不会收敛,可能导致算法陷入死循环,无法保障种子节点选择的正确性。本发明将节点的中心性、凝聚力和相似性作为衡量节点影响力的重要因素,动态更新每个节点的信任度与态度,能模拟信息在现实世界的传播。
信息传播过程中存在另一个重要特征,即用户偏好。用户对同一信息/产品有着不同的偏好,由于偏好的不同,用户产生的初始信任度不同。在信息传播过程中,受其邻居节点的影响,节点的信任度动态变化。有效的信息传播策略应确定影响力最大的节点集合,采用合理的信任度更新规则,最大化受影响节点的数量。
sir模型、ic模型和lt模型能实现信息的传播,但这三种模型未考虑节点的中心性、凝聚力和相似性对传播速度及范围的影响,因此,本发明提出相似度与凝聚力并重的信息传播方法,考虑用户偏好,结合用户的相似度、中心度和凝聚力,定义imp值作为节点影响力,解决影响力最大化问题,选择影响力大的节点作为传播发起者,动态更新普通节点的信任度,计算节点的态度,最终提升信息传播的速率与范围。
本发明借鉴sir、ic与lt模型的思想,为节点设计了推荐周期,普通节点在其推荐周期内处于活跃状态,接受种子节点的推荐,而种子节点在其推荐周期之后,将失去其传染性。例如,如图1所示的社交网络中,深色节点u和v是网络中的种子节点,浅色节点是网络中的普通节点,影响力大的节点被选为种子节点,种子节点向其邻居节点推荐信息,黑色箭头代表信息推荐的方向。同时,本发明设计了并行推荐规则,即多个种子节点可向同一普通节点推荐,一个普通节点亦可同时接受多个种子节点的推荐。本发明的方法,选择前k个影响力最大的节点作为传播发起者,即种子节点,并行推荐信息/广告到相邻的处于活跃状态的普通节点,普通节点随后更新自身的信任度,然后采用概率为自身信任度的二项分布,更新节点的态度,若态度为1,则该节点接受被推荐的信息,并且该节点可被选作种子节点。在信息传播过程中,节点的相似性不同于凝聚力,对社交网络中信息传播的效果产生不同影响,节点的相似性意味着偏好一致,有利于信息的迅速扩散,而节点的凝聚力表示该节点对周围邻居的影响力,决定信息传播能到达的范围。相似性与凝聚力对信任度有着不同的影响,且信任度的值随着邻居节点的影响而动态变化。
以下是本发明详细步骤:
社交网络用带权有向图g(v,e)表示,其中v是网络中节点的集合,有n个节点,e是一个非对称的n×n矩阵,代表节点之间的影响力关系,ep,q∈e,ep,q表示节点p对节点q的影响力,且ep,q≠eq,p;信任度o是一个n×n矩阵,op,t∈o表示节点p在时刻t的信任度。
本发明做如下定义:
定义1(推荐周期):用户只能在指定时间范围t内向其邻居节点推荐,或接收邻居节点的推荐。t={ti=(til,tiu),i∈v},til和tiu分别是节点i的推荐周期的下界与上界;在其推荐周期内,种子节点处于活跃状态,可向其邻居推荐信息,处于活跃状态的普通节点,可接受其相邻的种子节点的推荐。当系统时间超出了该用户的推荐时间范围,该用户即从网络中移除。
定义2(恢复过程):根据用户的个人偏好,接受过推荐的用户具有免疫力,称之为恢复过程,成功恢复后,该用户即从网络中移除。
定义3(并行关系):种子集合s中的每个用户均可多次向其邻居节点推荐信息,每个普通节点亦可同时接受多个相邻的种子节点的推荐。当节点i被多个节点同时推荐时,该过程称为并行关系。
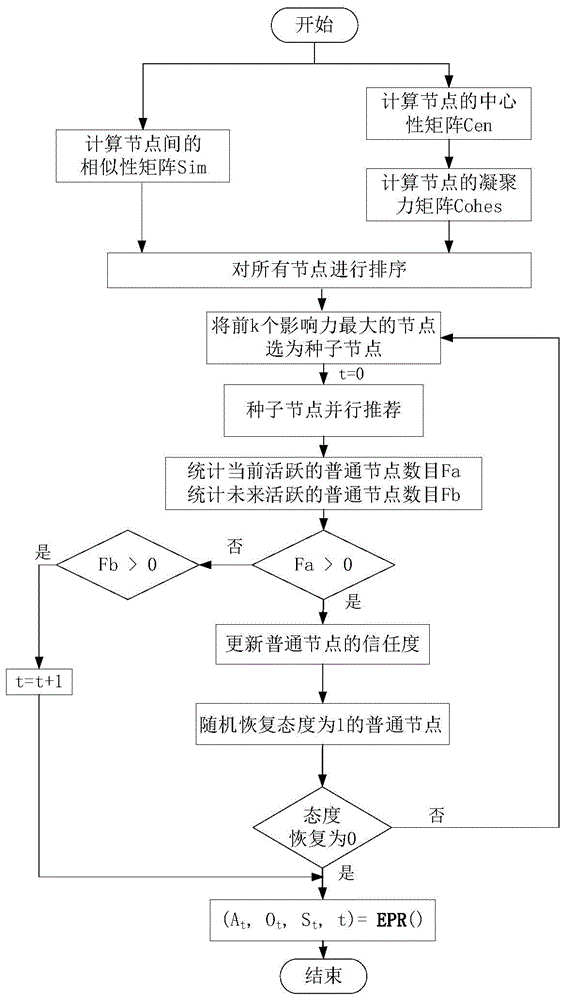
初始阶段,被选为种子节点的用户,其网络影响力越大,信息在网络中传播得越快,传播范围越广。由于中心性和相似性对网络中信息传播有着重要影响,本发明提出epr算法,该算法用imp值代表节点在网络中的重要性,对节点按其重要性排序,找出前k个社交网络中影响力最大的节点,作为种子节点,种子节点集合用s表示。
集合s中的k个种子节点同时向其相邻的普通节点推荐信息。t时刻,当种子节点i向节点i推荐信息时,i对信息的信任度更新为
本发明提出相似性与凝聚力并重的信息传播方法,在整个方法执行过程中,节点对信息的信任度随邻居节点的影响动态变化,具体算法如下:
(1)节点重要性排序:
步骤1:计算社交网络中节点间的相似性sim={sim(i,j)|i,j∈v},节点的中心性cen={cen(i)|i∈v}与凝聚力cohes={cohes(i)|i∈v},可得:
cen(i)表示节点的中心度,即节点i的邻居节点数目与整个网络中最大节点的度的比值。其中,
其中,nfp(i)表示节点i的邻居节点当前组成的朋友对数目,nfpp(i)表示节点i的所有邻居节点组成的最大可能朋友对。
步骤2:基于相似性与凝聚力,计算节点的影响力矩阵w,影响力矩阵w是基于e,并考虑了节点的凝聚力与相似性后重新定义的影响力矩阵,可得
w=(1-α-β)·e+α·repmat(cohes,n,1)+β·sim(公式4)
其中,α和β是权重因子且0<(α+β)<1,repmat(cohes,n,1)是将凝聚力cohes的1×n矩阵按行复制为n×n矩阵,即
步骤3:基于pagerank算法的思想,采用随机游走的方式,找到前k个最有影响力的节点集合s,作为种子节点集合,向其邻居节点传播信息,用imp值表示节点在社交网络中的影响力,按照imp值进行排序。
首先,计算概率转移矩阵m,可得
然后,计算阻尼系数矩阵d,可得
d=λ·repmat(cohes,n,1)+(1-λ)·sim(公式7)
其中,d的元素阻尼系数di,j=λ·cohes(j)+(1-λ)·sim,di,j∈dn×n。
计算矩阵q,可得
当τ=0,imp值等于节点初始信任度集合o,即imp0=o0。对节点的imp值按降序排列,得到初始状态排序sort0。
再次,计算在τ+1时刻的impτ+1值,计算规则如下:
impτ+1=impτ·q(公式9)
sortτ=sort(impτ+1)(公式10)
最后,对τ+1时刻所有节点的imp值进行降序排列,得到sorti,τ+1;若τ+1时刻的排序sorti,τ+1与τ时刻排序sorti,τ一致时,即:
节点排序程序终止,选择排序靠前的k个节点添加进种子节点集合s中。否则,节点排序过程继续迭代。
(2)节点信任度及态度更新:
步骤1:更新t时刻所有普通节点的信任度,可得
其中
步骤2:基于信任度,更改节点的态度:
ai,t~b(1,oi,t),i∈v(公式13)
节点的态度ai,t(接受推荐与否),t时刻节点i的态度服从以oi,t为概率的二项分布。
(3)节点相似度与凝聚力并重的信息传播算法epr:
对于社交网络g(v,e)以及初始信任度集合o0,当t=0,s为传播发起者节点集合,即种子节点集合。在信息传播过程中,若用户接受推荐,则该用户可被选作种子节点。具体的信息传播过程如下:
步骤1:判断社交网络中是否存在未接受推荐的节点,若不存在,信息传播算法结束,否则t=t+1,转步骤2;
步骤2:s中所有节点同时向其邻居节点实施推荐,若普通节点i处于活跃状态,则i可同时接受多个相邻的种子节点j(j∈s)的推荐。
步骤2.1:基于信任度更新规则,更新t时刻所有普通节点的信任度。
步骤2.2:t时刻,节点i的信任度更新为oi,t。节点i在t时刻接受推荐与否,服从概率为oi.t的二项分布ai,t~b(1,oi,t),若二项分布结果为1,表示节点i在t时刻接受推荐,节点i的态度更新为1,转步骤3,否则转步骤1。
步骤3:对步骤2.2中态度刚更新为1的节点i,以恢复率ri,t=1-oi,t进行随机恢复,恢复时同样服从二项分布ai,t~b(1,ri,t),若恢复成功则ai,t=0,代表节点i对该信息具有免疫力,从网络g中移除节点i。若恢复不成功,则该节点可被选为种子节点,转步骤1。
一、本发明实例及分析
社交网络由6个节点a、b、c、d、e、f组成,如图4所示。节点的初始信任度为o0={0.6,0.5,0.1,0.8,0.4,0.7},6个节点的推荐周期为t={(1,5),(3,8),(4,7),(1,4),(1,5),(2,5)},种子节点的数量k=1。
本发明所提方法具体包括:(1)基于给定的社交网络g(v,e),计算节点的中心性、相似性和凝聚力;(2)计算节点的影响力,选择前k个影响力最大的节点作为种子节点;(3)种子节点作为传播发起者,将信息传播到整个网络。
(1)相似性、中心性、凝聚力的计算:
在如图4所示的社交网络中,节点集合v={a,b,c,d,e,f},节点间的关系集合为:
根据公式1-3,deg={(b,d,e),(a,c,e),(b,e,f),(a,e),(a,b,c,d,f),(c,f)}。
中心性:由公式1可知,
凝聚力:凝聚力是对中心性的扩展,由公式2可知,凝聚力不仅与中心性有关,也与节点的邻居节点形成的朋友对数量有关,设μ=θ=0.5。对于节点a,其邻居节点的朋友对为{(d,e),(b,e)},因此nfp(a)=2,
同理,可计算得到网络所有节点的凝聚力cohes={0.63,0.63,0.63,0.45,0.7,0.45},于是
相似性:根据公式3,节点a和b的相似性为
(2)影响力最大化算法epr:对于给定的社交网络,根据epr算法找到社交网络中前k个影响力最大的节点。首先根据公式6和公式7计算概率转移矩阵m和联合相似性、凝聚力和中心性的阻尼系数矩阵d,可得
为方便计算,epr算法中定义矩阵
根据impτ+1=impτ·q,采用迭代,更新节点的重要性排序,imp值的具体迭代更新过程如表1所示,初始状态τ=0,impτ={0.6,0.5,0.1,0.8,0.4,0.7},节点imp值的排序为d,f,a,b,e,c,经过5次迭代后,epr算法收敛。k=1,则选择节点a作为种子节点,即传播发起者,将广告传播给符号网络中其他节点。
表1imp值计算结果
(4)广告传播过程:用epr算法选择出相应的种子节点后,根据信任度及态度更新规则,模拟信息在现实世界中的传播。方便起见,在此次案例中不考虑节点的恢复,假设一旦节点的态度更新为1,则加入种子集合s。为简单起见,若信任度大于0.7,则节点被视为接受推荐,自动加入种子集合。
初始种子节点集合s={a}。设α=β=0.25,根据公式4,计算影响力矩阵w,可得
表2社交网络的广告推荐过程
初始t=0,初始信任度o0={0.6,0.5,0.1,0.8,0.4,0.7},推荐周期t0={(1,2),(3,8),(4,7),(1,4),(1,5),(2,5)}。随时间的推移,节点信任度具体更新如表2所示,具体过程如下:
t=1:节点a向d和e推荐,t处于节点a、d和e的推荐周期内,即t∈ta,t∈td,t∈te,d和e的信任度更新如下:
od,1=od,0+w1,4·(oa,0-od,0)=0.702,
oe,1=oe,0+w1,5·(oa,0-oe,0)=0.5;
信任度集合o1={0.6,0.5,0.1,0.702,0.5,0.7},节点d的信任度od,1>0.7,将节点d加入种子节点集合,有s={a,d}。
t=2:节点a和d同时向节点e推荐,系统时间t处于节点a、d、e的推荐周期内,即t∈ta,t∈td,t∈te,节点e的信任度更新如下:
oe,2=oe,1+w1,5·(oa,1-oe,1)+w4,5·(od,1-oe,1)=0.698;
信任度集合o2={0.6,0.5,0.1,0.702,0.698,0.7},节点e的信任度oe,2<0.7,种子节点集合仍为s={a,d}。
t=3:节点a和d同时向节点e推荐,系统时间t处于节点d、e的推荐周期,但超出节点a的推荐周期,即
oe,3=oe,2+w4,5·(od,2-oe,2)=0.701;
信任度集合o3={0.6,0.5,0.1,0.702,0.701,0.7},节点e的信任度oe,2>0.7,将节点e加入种子节点集合,有s={a,d,e}。
t=4:节点e向b和f推荐,系统时间t处于节点b、e、f的推荐周期内,即t∈td,t∈te,t∈tf,则节点b和f的信任度更新如下:
ob,4=ob,3+w5,2·(oe,3-ob,3)=0.587,
of,4=of,3+w5,6·(oe,3-of,3)=0.7003。
信任度集合o4={0.6,0.587,0.1,0.702,0.701,0.7003},节点f的信任度of,4>0.7,将节点f加入种子节点集合,有s={a,d,e,f}。
t=5:节点e向节点b推荐,节点f向节点c推荐,系统时间t处于节点b,c,d,e的推荐周期内,即t∈tc,t∈td,t∈te,t∈tf,因此节点b和c的信任度更新如下:
ob,5=ob,4+w5,2·(oe,4-ob,4)=0.638,
oc,5=oc,4+w6,3·(of,4-oc,4)=0.225;
信任度集合o5={0.6,0.638,0.225,0.702,0.701,0.7003},节点f的信任度of,4>0.7,将节点f加入种子节点集合,有s={a,d,e,f}。
t=6:节点e向节点b推荐,节点f向节点c推荐,系统时间t不再处于节点e和f的推荐周期内,即
经过6轮推荐,广告推荐过程结束,网络中有4个节点接受推荐,由于节点推荐周期的限制,并不是每个节点都会接受推荐,这种情况更符合现实网络中的信息传播。
二、本发明性能分析
用真实数据集的子集验证本发明所提方法的性能,为平衡社交网络中节点的相似性性和凝聚力对信息传播的影响,将α、β、λ三个参数预设为0.25,0.25和0.5。数据集是epinions,epinions是国外对购买商品的评价网站,用户根据别人对产品的评论来确定是否购买该商品;用户根据其他用户的评论,可以动态更新自己对产品的信任度。epinions评论网站数据集是来自斯坦福大学的snap栏目,实验数据集属性情况如下表3所示:
表3实验数据集属性
本发明方法(图例中epr)与两个启发式算法以及经典的贪心算法进行比较。贪心算法与imp算法的相同之处在于两者均解决了社交网络中的影响力最大化问题,但贪心算法在k轮循环中边际增益最大的节点,为保证算法精度,在每一轮循环中嵌套x轮循环,x一般取值为20000,x轮循环结束后得到节点的平均增益作为该节点的最终边际增益,k轮循环结束后得到的前k个最终边际增益最大的节点就是选取的影响力最大的种子节点;其缺点是算法的时间复杂度较高导致了运行时间过长。两种启发式算法分别是:(1)随机启发式算法rand,随机选择k个节点作为种子节点,向其他节点推送广告,图例中用rand表示;(2)最大出度启发式算法d+,选择网络中出度影响力最高的前k个节点作为种子节点推送广告,图例中用表示d+。
图5、图6是社交网络中受影响节点数量与迭代次数对比图,对应的节点数量分别2000个和6000个。图7、图8是社交网络中受影响节点数量与种子节点数量对比图,对应的节点数量分别2000个和6000个。实验中将四种算法在两个网络中运行500次记录每次迭代的受影响节点数量并取平均值,得到推送过程中每一时刻的接受广告的节点数量。
如图5,图6所示,两种网络在不同节点数量的条件下,本发明方法最优,贪心算法和最大出度启发式算法d+次之,随机启发式算法rand最差。
对比图5、图6,本发明所提出的epr继承了病毒式营销的优点,在初始状态时影响力扩散的速度并不是很大,随着迭代次数的增加,影响力扩散的速度呈指数级增长并最终达到稳定。
如图7、图8所示,将种子节点数量k的范围设置在10与100之间,本发明的影响力扩散范围最大,且受影响节点的数量高于其他三个算法10%。
图9、图10是社交网络中运行时间与种子节点数量对比图,对应的节点数量分别2000个和6000个。由于贪心算法效率低下,在epinions网络中,其运行时间在1分钟以上,而其他三个算法的运行时间都是秒级,为方便记录,我们在实验结果图中便不再记录贪心算法的运行时间。实验中将三种算法在两个网络中运行500次记录每次迭代的受影响节点数量并取平均值,得到算法的运行时间。
如图9、图10所示,三种算法的运行时间随种子节点数量的增加呈指数级减小最终达到平衡,且本发明的运行时间明显小于其他三者,种子节点数量越多,影响力扩散的速度会越来越快。
其原因在于,两种启发式方法能得到一个可行解,非最优解。随机启发式算法随机选择节点添加到种子节点集合,并不考虑社交网络中用户之间的关系对该节点影响力产生的变化;最大出度启发式算法找到出度节点数量最大的节点作为种子节点,并未考虑用户的信任度。而贪心算法是一个局部最优的方法,并且该方法的时间复杂度较高导致了过长的运行时间,进一步证实本发明所提方法的优越性。
为验证算法运行时间与网络规模的关系,将epinions的网络规模设为1500至6000,种子节点的数量设置为5,四种算法分别运行500次,再取运行时间的平均值,得到图11,随网络规模的增加,算法的运行时间显著增加,且本发明的运行时间比其他两个算法小40%。
- 还没有人留言评论。精彩留言会获得点赞!