一种自适应调整医疗保险覆盖策略的方法与流程
本发明涉及医疗大数据领域,更具体地说,本发明涉及一种自适应调整医疗保险覆盖策略的方法。
背景技术:
当社会向更好的方向发展时,医疗保险作为社会保障的一个重要环节则必不可少。在一定程度上,医疗保险制度的发展也影响了医疗资源配置水平、国民健康情况,甚至人口社会经济发展状况。然而,在资源不均等条件下,医疗领域的有限水平跟不上医疗需求的过快增长;同时,贫困人口对医疗保障的需求更面临着长期性的问题。在此情况下,如何及时地自适应调整医疗保险覆盖策略,保障人民的健康生活水平,成为了一个亟需解决的问题。
当前,医疗保险的覆盖策略主要集中于保障的广度、保障的范围以及保障的待遇水平三个维度。保障的广度就是不同等级收入人群的参保情况;保障的范围考虑了政府、雇主、个人筹资占医保筹资的比重,以及不同收入群体的医保筹资水平占其收入的比重;保障的待遇水平关注了城镇职工医保、城镇居民医保、新农合、残存公费医疗的医保目录、报销水平、起付线和封顶线。基于这三个维度信息,本发明结合人工智能的方法,设计一种基于深度强化学习的自适应调整医疗保险覆盖策略的方法。
技术实现要素:
为了克服现有技术的上述缺陷,本发明的实施例提供一种自适应调整医疗保险覆盖策略的方法,通过收集患者就医信息,构建“状态-动作-反馈”样本集合,设计深度强化学习神经网络,训练上述神经网络,得到可自适应调整的医疗保险覆盖策略,在现有的医疗保险覆盖策略下,运用深度强化学习方法,根据就医效果对现有的医疗保险覆盖策略进行自适应调整,这样使得受保群体享受的医疗保障覆盖策略更加完备,更好地保障人民的生活健康。
为实现上述目的,本发明提供如下技术方案:一种自适应调整医疗保险覆盖策略的方法,包括如下步骤:
s1、步骤s1,收集就诊患者的基本就诊信息,包括姓名、性别、年龄、所属的收入等级水平、参加的医疗保险种类、个人医疗保险筹资占总医疗保险筹资的比重、个人医疗保险筹资水平占其收入的比重,以及患病情况,将收集到的就诊信息标记为训练样本的“状态”信息;
s2、结合s1收集的基本就诊信息,整理患者就诊后对应的用药情况,包括所使用的医疗保险覆盖下药物的价格、用量以及非医疗保险覆盖下药物的价格、用量,将这些收集到的信息标记为训练样本的“动作”信息,收集就医治疗后对应的效果,包括患者用药后恢复健康情况、患者就医后的生活开支受到的影响;
s3、设计深度强化学习神经网络,将医保策略信息输入至卷积层网络中,对输入信息进行卷积操作,并使用padding操作,在进行padding操作时利用np.pad()函数,信息通过不同卷积核卷积并且加偏置bias,提取局部特征,每一个卷积核产生新的信息;
对卷积输出结果采用relu函数进行非线性激活函数处理,包括如下:
tf.nn.conv2d(x,w1,strides=[1,s,s,1],padding='same'):将输入x和w1进行卷积计算,第三个输入strides规定了在x(shape为(m,n_h_prev,n_w_prev,n_c_prev))各维度上的步长s,第四个输入padding规定padding的方式;
tf.nn.max_pool(a,ksize=[1,f,f,1],strides=[1,s,s,1],padding='same'):以ksize和strides规定的方式对输入a进行max-pooling操作;
tf.nn.relu(z1):relu作为激活函数;
tf.contrib.layers.flatten(p):将p中每个样本flatten成一维向量,最后返回一个flatten的shape为[batch_size,k]的图;
并增加若干个卷积层,然后全连接层(fc),与神经网络的隐藏层相对应,最后softmax层预测输出值y_hat;
其中,卷积操作后输出的矩阵信息需满足如下公式:
利用非线性编码器对患者的基本信息和疾病情况进行编码,通过深度强化学习神经网络得到对应的多元特征向量;
s4、将步骤s1和s2收集到的信息进行整理,构建“状态-动作-反馈”训练样本集合,对医疗保险覆盖策略进行迭代训练,利用深度强化学习神经网络对每一个训练样本的“状态”信息,采取对应的“动作”,最后基于“反馈”信息来调整当前的策略;
s5、利用s4的样本对深度强化学习神经网络进行迭代训练,作为新的医疗保险覆盖策略;
s6、测试阶段,即参照步骤s1和s2来收集新的患者样本信息,根据训练好的医疗保险覆盖策略,得到用药情况,并根据患者真实的就医效果对此进行评判。
在一个优选地实施方式中,所述s2中,患者在多次就诊时,需要对多次就诊后对应的效果分别进行整理。
在一个优选地实施方式中,所述s4中,利用深度强化学习神经网络调节策略具体为:对每一个患者的就诊和患病情况,在当前的深度强化学习神经网络策略下,给出治疗药物,并基于治疗效果对深度强化学习神经网络再训练,最后将深度强化学习神经网络作为医疗保险覆盖策略。
本发明的技术效果和优点:
本发明通过收集患者就医信息,构建“状态-动作-反馈”样本集合,设计深度强化学习神经网络,训练上述神经网络,得到可自适应调整的医疗保险覆盖策略,在现有的医疗保险覆盖策略下,运用深度强化学习方法,根据就医效果对现有的医疗保险覆盖策略进行自适应调整,这样使得受保群体享受的医疗保障覆盖策略更加完备,更好地保障人民的生活健康。
附图说明
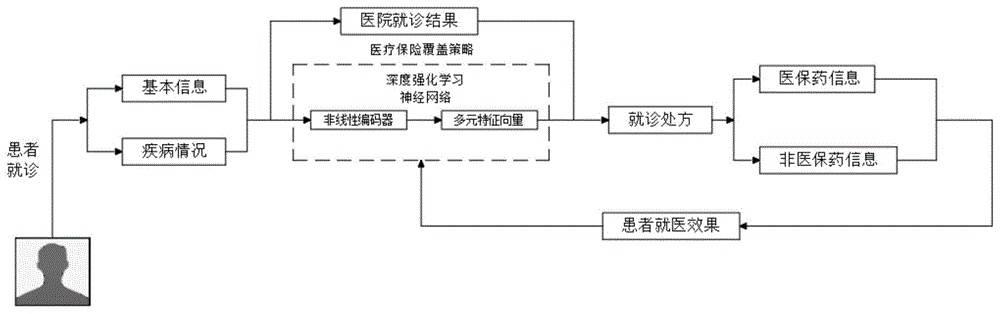
图1为本发明的算法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了如图1所示的一种自适应调整医疗保险覆盖策略的方法,包括如下步骤:
s1、步骤s1,收集就诊患者的基本就诊信息,包括姓名、性别、年龄、所属的收入等级水平、参加的医疗保险种类、个人医疗保险筹资占总医疗保险筹资的比重、个人医疗保险筹资水平占其收入的比重,以及患病情况,将收集到的就诊信息标记为训练样本的“状态”信息;
s2、结合s1收集的基本就诊信息,整理患者就诊后对应的用药情况,包括所使用的医疗保险覆盖下药物的价格、用量以及非医疗保险覆盖下药物的价格、用量,将这些收集到的信息标记为训练样本的“动作”信息,收集就医治疗后对应的效果,包括患者用药后恢复健康情况、患者就医后的生活开支受到的影响,当患者在多次就诊时,需要对多次就诊后对应的效果分别进行整理。
s3、设计深度强化学习神经网络,将医保策略信息输入至卷积层网络中,对输入信息进行卷积操作,并使用padding操作,在进行padding操作时利用np.pad()函数,信息通过不同卷积核卷积并且加偏置bias,提取局部特征,每一个卷积核产生新的信息;
对卷积输出结果采用relu函数进行非线性激活函数处理,包括如下:
tf.nn.conv2d(x,w1,strides=[1,s,s,1],padding='same'):将输入x和w1进行卷积计算,第三个输入strides规定了在x(shape为(m,n_h_prev,n_w_prev,n_c_prev))各维度上的步长s,第四个输入padding规定padding的方式;
tf.nn.max_pool(a,ksize=[1,f,f,1],strides=[1,s,s,1],padding='same'):以ksize和strides规定的方式对输入a进行max-pooling操作;
tf.nn.relu(z1):relu作为激活函数;
tf.contrib.layers.flatten(p):将p中每个样本flatten成一维向量,最后返回一个flatten的shape为[batch_size,k]的图;
并增加若干个卷积层,然后全连接层(fc),与神经网络的隐藏层相对应,最后softmax层预测输出值y_hat;
其中,卷积操作后输出的矩阵信息需满足如下公式:
利用非线性编码器对患者的基本信息和疾病情况进行编码,通过深度强化学习神经网络得到对应的多元特征向量;
s4、将步骤s1和s2收集到的信息进行整理,构建“状态-动作-反馈”训练样本集合,对医疗保险覆盖策略进行迭代训练,利用深度强化学习神经网络对每一个训练样本的“状态”信息,采取对应的“动作”,最后基于“反馈”信息来调整当前的策略,具体为:对每一个患者的就诊和患病情况,在当前的深度强化学习神经网络策略下,给出治疗药物,并基于治疗效果对深度强化学习神经网络再训练,最后将深度强化学习神经网络作为医疗保险覆盖策略。
s5、利用s4的样本对深度强化学习神经网络进行迭代训练,作为新的医疗保险覆盖策略;
s6、测试阶段,即参照步骤s1和s2来收集新的患者样本信息,根据训练好的医疗保险覆盖策略,得到用药情况,并根据患者真实的就医效果对此进行评判。
通过收集患者就医信息,构建“状态-动作-反馈”样本集合,设计深度强化学习神经网络,训练上述神经网络,得到可自适应调整的医疗保险覆盖策略,在现有的医疗保险覆盖策略下,运用深度强化学习方法,根据就医效果对现有的医疗保险覆盖策略进行自适应调整,这样使得受保群体享受的医疗保障覆盖策略更加完备,更好地保障人民的生活健康。
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!