一种基于大数据的医保数据分析方法与流程
本发明涉及医保数据分析领域,尤其涉及一种基于大数据的医保数据分析方法。
背景技术:
医保指社会医疗保险。社会医疗保险是国家和社会根据一定的法律法规,为向保障范围内的劳动者提供患病时基本医疗需求保障而建立的社会保险制度。基本医疗保险基金由统筹基金和个人账户构成。职工个人缴纳的基本医疗保险费全部计入个人账户;用人单位缴纳的基本医疗保险费分为两部分,一部分划入个人账户,一部分用于建立统筹基金。
基于医保大数据的医保行业分类和医保需求预测建模分析,主要是通过挖掘与分析地区医保人群的医保模式掌控医保群体构成及其使用特性,识别影响医保的关键因素,对不同人群的医保量进行预测,从而实现医保的精细化管理,提供优质的医保服务。
技术实现要素:
本发明的目的是为了解决现有无法对大数据按照需求进行分类整理并建立有效的医保预测模型的问题,而提出的一种基于大数据的医保数据分析方法。
为了实现上述目的,本发明采用了如下技术方案:
一种基于大数据的医保数据分析方法,包括以下步骤;
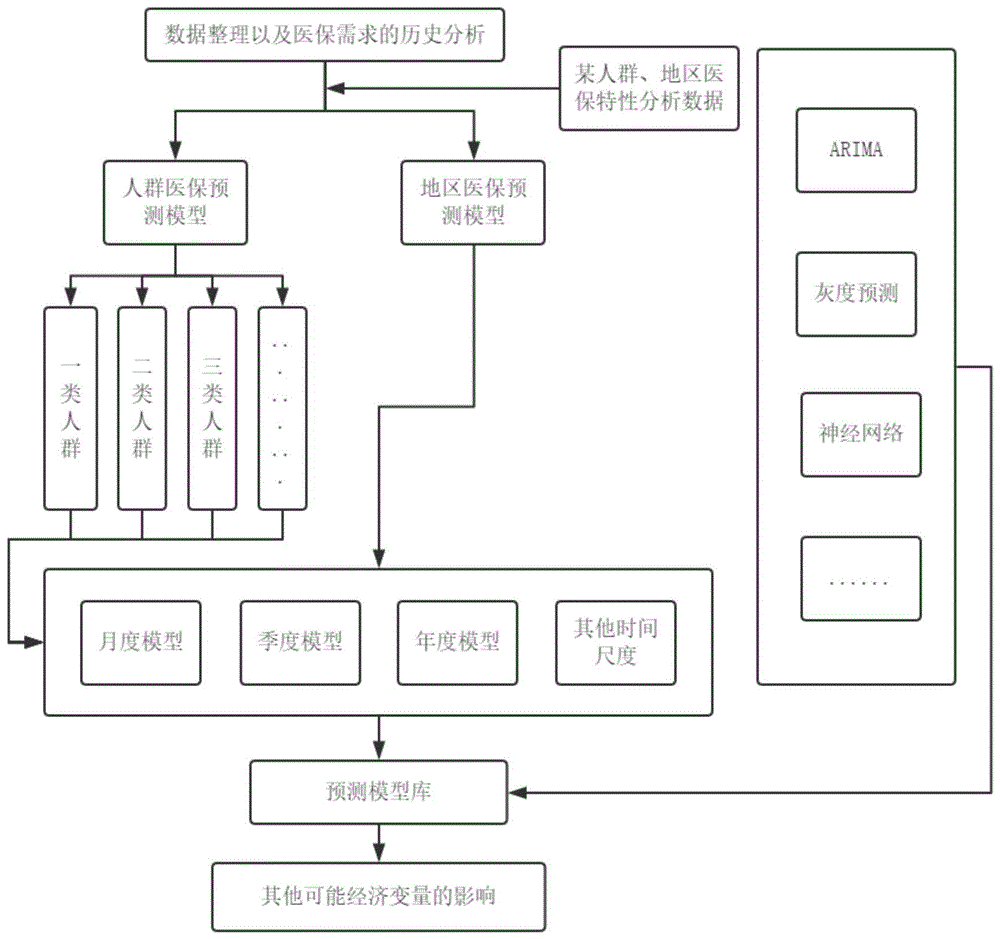
s1、对某地区医保数据进行整理,包括有效性检查、错误数据剔
除与修改;
s2、初步统计,对波动规律形成初步认识。对不同行业和地区的用电数据分类,针对不同数据的特点,分析数据曲线的趋势,结合初步的自相关分析,研究导致重大疾病和阶段性传染病不规则变化的内外因素。在针对不同数据研究整理时,将其按照月度、季度和年度时间跨度整合;
s3、医保数据预测模型的构建,分类别分尺度的寻找预测精度较高、拟合优度较高的预测模型,每一具体类别的月度、季度和年度的预测模型构建,在对比若干个预测模型的拟合和预测结果的基础上进行筛选;
s4、在s3中医保数据预测模型建立之后,筛选和分析相关变量对医保数据波动的影响;
s5、筛选完毕之后将相关变量导入模型,之后导入基础数据,启动模型,并开始预测,将预测结果与实际结果持续比对,对模型进行持续修正。
优选地,所述s1中对某地区医保数据整理的过程中,将人群类别按照年龄层次进行划分,具体如下:1-4岁幼儿、5-11岁儿童、12-18岁少年、18-35岁青年、36-59岁中年、60岁以上老年。
优选地,所述s1中对采用聚类算法对医保数据进行处理,假设所收集数据包含n个年龄层次,每个年龄层次序列有d个数据点,数据集可表示为:x={x1,x2,l,xi,lxn},其中xi∈rd,聚类算法将年龄层次k划分为c={c1,c2,l,ck,l,ck},每个划分代表一个类ck,每
类都有一个中心uk,该中心为类内各对象的平均值,采用欧几里得距离作为距离度量,计算各类别中的对象,到其聚类中心uk距离平方和:
本次将k值设为5,模型将可输出5个年龄层次,以及每个年龄中包含的具体数据,每个类别中的人群在相应时间维度上都具有相似的医保数据。
优选地,所述s1中整合数据之后,采用gregoryc.chow检验法对上述数据进行识别,判断年龄层次对医保数据的变化是否产生了影响,具体如下:
假设数据模型为:
y=a+bx1+cx2+ε
若将被检验数据分为两组,则有:
y=a1+b1x1+c1x2+ε
y=a1+b1x1+c1x2+ε。
假设sc是组合数据的残差平方和,s1是第一组数据的残差平方和,s2是第二组数据的残差平方和。n1和n2分别是每一组数据的观察树木,k是参数的总数,得到以下f统计量:
通过以上方式对原假设进行检验:若f<f(k,n1+n2-2k)时
拒绝原假设情况;若f>f(k,n1+n2-2k)时,接收原假设情况。
优选地,所述s3中建立模型包括以下步骤:
a1、arima模型构件流程如下:
arima模型公式中,每个函数意义为:
a2、利用gm(1,1)模型,设原始数列为:
x(0)=(x(0)(1),x(0)(2),λ,x(0)(n))
gm(1,1)模型相应的微分方程为:
基本步骤为:原始数据累加生成;再用构造累加矩阵b与常数项向量;采用最小二乘法求解灰参数;然后将灰参数带入时间函数;对时间函数求导再还原;最后载利用模型开展预测;
a3、将各个预测模型的结论进行适当加权平均作为预测结果,即:
式中,
模型的权重,将问题转变为求解目标函数
a4、神经网络模型的建立,网络初始化,隐含层输出计算,输出层输出计算,权值更新,阀值更新,判断算法迭代是否结束,若未结束,返回隐含层输出计算;
a5、采用二次指数平滑技术,计算一次、二次指数平滑序列,计算预测直线的截距和斜率,医保数据预测;
a6、通过二次指数平滑技术,并在此基础上,通过预测误差情况的判断,持续调整平滑系数at,具体如下:设定初始值,计算自适应系数,应用二次平滑技术预测。
与现有技术相比,本发明提供了一种基于大数据的医保数据分析方法,具备以下有益效果:
1.本发明通过建立模型并分析,我们发现宏观经济的各项指标对这些模型预测的精度有较大影响,而且本次研究的人群分类医保,从数据维度和数据规模上只占医保数据的一少部分,未来医保大数据的分析与研究一定是数据范围更广,数据体量更大并且与宏观经济指标深度结合。本发明医保大数据技术和应用的主要在以下三个方面。计量自动化设备技术的发展和信息系统水平的提升。计量自动化设备的发展可以多维度的进行信息采集同时保证采集信息的准确性和及时性,而信息系统的发展可以带来更好的数据整合、存储、统计,为大数据提供数据支撑。算法的迭代升级,随着算法的迭代与升级可以为2.数据分析提供更多样模型,从而满足各种不同的需求,并且随着算法的升级提升数据准确性。其他数据参与医保数据的分析,随着宏观经济数据,海量用户数据,消费数据等其他数据的参与医保数据的分析,不但可以提升医保数据分析与预测的精度,并且使医保数据发挥更大价值。
附图说明
图1为本发明提出的一种基于大数据的医保数据分析方法的整体流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
实施例1:
一种基于大数据的医保数据分析方法,包括以下步骤;
s1、对某地区医保数据进行整理,包括有效性检查、错误数据剔除与修改;
s2、初步统计,对波动规律形成初步认识。对不同行业和地区的用电数据分类,针对不同数据的特点,分析数据曲线的趋势,结合初步的自相关分析,研究导致重大疾病和阶段性传染病不规则变化的内外因素。在针对不同数据研究整理时,将其按照月度、季度和年度时间跨度整合;
s3、医保数据预测模型的构建,分类别分尺度的寻找预测精度较高、拟合优度较高的预测模型,每一具体类别的月度、季度和年度的预测模型构建,在对比若干个预测模型的拟合和预测结果的基础上进行筛选;
s4、在s3中医保数据预测模型建立之后,筛选和分析相关变量对医保数据波动的影响;
s5、筛选完毕之后将相关变量导入模型,之后导入基础数据,启动模型,并开始预测,将预测结果与实际结果持续比对,对模型进行持续修正。
进一步,优选地,s1中对某地区医保数据整理的过程中,将人群类别按照年龄层次进行划分,具体如下:1-4岁幼儿、5-11岁儿童、12-18岁少年、18-35岁青年、36-59岁中年、60岁以上老年。
进一步,优选地,s1中对采用聚类算法对医保数据进行处理,假设所收集数据包含n个年龄层次,每个年龄层次序列有d个数据点,数据集可表示为:x={x1,x2,l,xi,lxn},其中xi∈rd,聚类算法将年龄层次k划分为c={c1,c2,l,ck,l,ck},每个划分代表一个类ck,每类都有一个中心uk,该中心为类内各对象的平均值,采用欧
几里得距离作为距离度量,计算各类别中的对象,到其聚类中心uk距离平方和:
本次将k值设为5,模型将可输出5个年龄层次,以及每个年龄中包含的具体数据,每个类别中的人群在相应时间维度上都具有相似的医保数据。
进一步,优选地,s1中整合数据之后,采用gregoryc.chow检验法对上述数据进行识别,判断年龄层次对医保数据的变化是否产生了影响,具体如下:
假设数据模型为:
y=a+bx1+cx2+ε
若将被检验数据分为两组,则有:
y=a1+b1x1+c1x2+ε
y=a1+b1x1+c1x2+ε。
假设sc是组合数据的残差平方和,s1是第一组数据的残差平方和,s2是第二组数据的残差平方和。n1和n2分别是每一组数据的观察树木,k是参数的总数,得到以下f统计量:
通过以上方式对原假设进行检验:若f<f(k,n1+n2-2k)时拒绝原假设情况;若f>f(k,n1+n2-2k)时,接收原假设情况。
进一步,优选地,s3中建立模型包括以下步骤:
a1、arima模型构件流程如下:
arima模型公式中,每个函数意义为:
a2、利用gm(1,1)模型,设原始数列为:
x(0)=(x(0)(1),x(0)(2),λ,x(0)(n))
gm(1,1)模型相应的微分方程为:
基本步骤为:原始数据累加生成;再用构造累加矩阵b与常数项向量;采用最小二乘法求解灰参数;然后将灰参数带入时间函数;对时间函数求导再还原;最后载利用模型开展预测;
a3、将各个预测模型的结论进行适当加权平均作为预测结果,即:
式中,
形成最终医保数据季度需求的预测区间;
a4、神经网络模型的建立,网络初始化,隐含层输出计算,输出层输出计算,权值更新,阀值更新,判断算法迭代是否结束,若未结束,返回隐含层输出计算;
a5、采用二次指数平滑技术,计算一次、二次指数平滑序列,计算预测直线的截距和斜率,医保数据预测;
a6、通过二次指数平滑技术,并在此基础上,通过预测误差情况的判断,持续调整平滑系数at,具体如下:设定初始值,计算自适应系数,应用二次平滑技术预测。
实施例2:基于实施例1但有所不同的是;
某地区医保月度预测误差
某地区医保季度预测误差
某地区医保年度预测误差
通过模型库中代表模型,对某地区医保数据进行拟合与预测,结果显示,对于月度和季度数据选取arima模型可以得到较好的预测结果,对于年度数据,选取灰色系统模型,可以得到较好的预测结果。
实施例3:基于实施例1和2但有所不同的是;
通过对该地区各人群的医保情况进行分析,提出了基于月度医保序列聚类的人群分类方法。对各影响因素的分析结果表明,该分类方法所得到的分类结果稳定可靠。基于所得到的分类结果,本研究对各类人群的医保占比和医保波动影响进行分析,并选取了3类共10个具体人群作为关键医保人群。这10个人群在所有人群中的医保占比最大,同时对总体医保量的波动影响最大。基于医保人群分类基础,构建分人群与地区的医保需求预测模型,实现对关键医保人群的医保需求预测。第一,在医保特征不同的情况下,关键医保人群在不同类型的模型预测下,月度数据、季度数据和年度数据体现出了不同的精度差异,最终的测试结果表明,对于月度和季度人群医保量,用arima模型预测的精度较高,对于年度数据,用灰色系统模型预测精度较好。第二,通过对该地区的医保预测模型进行构建,结合各类人群医保模型的选择。最终研究表明,在该地区使用arima模型预测,月度和季度人群医保量,预测结果的精度均较好,但是在年度数据的预
测方面,用灰色系统模型得到的精度较为理想。最后,利用先行医保量的经济变量,构建改进的预测模型。模型分析结果表明,滞后1阶的规上增加值和实际利用金额两经济变量,与医保预测的残差序列有显著的相关性。随着与医保相关的先行经济变量的加入,能提高模型的预测精度。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!