一种物品识别的训练、推理以及增加新种类的方法和系统与流程
本发明涉及图像识别领域,具体是一种物品识别的训练、推理以及增加新种类的方法和系统。
背景技术:
目前使用的物体识别方法有目标检测技术、人脸识别技术。
主流的目标检测技术,例如yolo,faster_rcnn,目前主流目标检测技术可以相对精确的确定物体的位置和种类。目标检测技术存在的问题:a.需求数据量大。识别一个种类需要海量的数据,通常想要达到95%以上的识别正确率需要5000+张图片。b.种类间特征相近时(如颜色,纹理等)误识别风险高且种类总数有限。一个识别模型能识别的种类数有限,当超过一定数量的种类后或者其中有些种类间特征较为近似,会大大增加类别间误识别的风险。c.在现有模型中新增一个新种类所需要的时间相对而言较长,通常是按天来计算的。
而人脸识别技术可以在极短的时间内和使用较少图片来增加一个新类别,但应用场景狭隘,只能用于人脸识别。
技术实现要素:
为解决上述现有技术的缺陷,本发明提供物品种类识别方法及在现有模型中增加新种类的方法,本发明下层模型将特征较为相似的若干种细分种类再针对性的提取各自特有的特征进行分类,从而识别更为精准,粒度更细,增加一个细分种类时,只需采集较少图片,对每张图片进行固定特征提取,无需改动之前已存在的类别,所以时间较短所需图片较少,运用上下文模型,先定位粗分类别,再细分类别,这样可容纳的种类数量更多。
为实现上述技术目的,本发明采用如下技术方案:一种物品识别的训练、推理以及增加新种类的方法,包括
模型训练,训练出物品识别所需的上层模型和下层模型,并生成特征库;
模型推理,推理出目标对象的粗分类别、细分类别和二维空间位置;
增加新种类,快速在现有模型中增加可识别的细分种类。
优选的,所述模型训练包括以下步骤,
a1将所有待训练类别分为多个粗分类别以及细分类别;
a2分别采集各粗分类别的图片数据,作为上层模型训练数据;
a3对所述上层模型训练数据进行数据增强;
a4标定所述目标对象对应的粗分类别;
a5将所述上层模型训练数据训练出目标检测模型,并作为上层模型;
a6分别采集各细分类别的图片数据,作为下层模型训练数据;
a7对所述下层模型训练数据进行数据增强;
a8裁剪所述下层模型训练数据;
a9将所述下层模型训练数据训练出特征提取网络,并作为下层模型;
a10提取所述目标对象的结构化特征,形成特征库。
优选的,所述步骤a1中,把所有需要识别的所述目标对象的类别作为细分类别,然后将各特征相近的细分类别合并为同一个粗分类别;
所述步骤a2中,采集各粗分类别的图片数据时,在光线、角度、远近、纹理等维度的组合变换下采集多张照片,作为上层模型训练数据;
所述步骤a3中,按照明暗度、颜色、锐利度,利用图像处理方式对所述上层模型数据进行数据增强,并将数据增强得到的数据加入到所述上层模型训练数据中;
所述步骤a4中,标定所述上层模型训练数据中目标对象的位置及其粗分类别;
所述步骤a5中,利用目标检测算法训练所述上层模型训练数据,训练得到的目标检测模型作为上层模型;
所述步骤a6中,采集所述目标对象的图片数据时,将物品旋转360°,每隔5°在平视和俯视两个视角各采集一张图片,作为下层模型训练数据;
所述步骤a7中,按照明暗度、颜色、锐利度,利用图像处理方式对所述下层模型训练数据进行数据增强,并将数据增强得到的数据加入到所述下层模型训练数据中;
所述步骤a8中,裁剪所述下层模型训练数据,按照图片中所述目标对象的边界矩形裁剪,去除无效数据;
所述步骤a9中,利用神经网络训练所述下层模型训练数据,并将训练得到的特征提取网络作为下层模型;
所述步骤a10中,利用颜色特征提取算法提取所述目标对象的颜色分布比例特征;
利用ocr技术提取所述目标对象的文字信息特征;
利用下层模型提取所述目标对象的卷积特征;
结构化所述目标对象细分类别的卷积特征、颜色分布比例特征和文字信息特征,形成特征库。
优选的,所述模型推理包括
b1利用上层模型推理出待识别图片中所述目标对象的空间位置及粗分类别;
b2利用下层模型提取出待识别图片中所述目标对象的卷积特征,利用颜色特征提取算法提取所述目标对象的颜色分布比例特征,利用ocr技术提取所述目标对象的文字信息特征;
b3结构化b2中所得的特征信息并与上层模型推理得到的粗分类别对应的特征库进行特征比对,得到所述目标对象的细分类别。
优选的,所述增加新种类包括以下步骤,
c1采集待新增细分类别的图片数据,作为新类别训练数据;
c2对c1中采集的数据进行数据增强,并将数据增强得到的数据加入到所述新类别训练数据中;
c3裁剪所述新类别训练数据;
c4提取所述待新增细分类别的结构化特征,加入特征库。
优选的,所述步骤c1中,采集待新增细分类别的图片数据时,将具有代表性的待新增物品旋转360°,每隔5°在平视和俯视两个视角各采集一张图片,作为新类别训练数据;
所述步骤c2中,按照明暗度、颜色、锐利度,利用图像处理方式对所述新类别训练数据进行数据增强,并将数据增强得到的数据加入到新类别训练数据中;
所述步骤c3中,裁剪所述新类别训练数据,按照图片中待新增物品的边界矩形裁剪,去除无效数据;
所述步骤c4中,利用下层模型提取所述待新增物品的卷积特征,利用颜色特征提取算法提取所述待新增物品的颜色分布比例特征,利用ocr技术提取所述待新增物品的文字信息特征,结构化所述待新增物品的卷积特征、颜色分布比例特征、文字信息特征,并加入特征库。
优选的,一种物品识别的训练、推理以及增加新种类的系统,包括
训练模块,用于训练上层模型和下层模型;
特征提取模块,用于针对性的提取各细分种类的独有特征,形成特征库;
推理模块,用于利用上层模型、下层模型以及特征库推理出图片中所述目标对象的二维空间位置和细分类别;
类别管理模块,用于快速增加新的细分类别和删除现有类别;
通信模块,用于各模块间相互通信。
优选的,所述训练模块包括
上层数据采集子模块,用于采集所述目标对象的各个维度的数据,作为上层模型训练数据;
上层数据增强子模块,用于对所述上层模型训练数据进行数据增强;
上层模型数据标定子模块,用于标定所述上层模型训练数据,在图片中标定出所述目标对象的二维空间位置和所属的粗分类别;
上层模型训练子模块,利用目标检测算法将所述上层模型训练数据训练出目标检测模型,作为上层模型;
下层数据采集子模块,用于采集所述目标对象的360°全方位的图片数据,作为下层模型训练数据;
下层数据增强子模块,用于对所述下层模型训练数据进行数据增强;
下层模型裁剪子模块,裁剪所述下层模型训练数据;
下层模型训练子模块,选取一个特征提取网络,训练出相应的下层模型;
所述特征提取模块包括
卷积特征提取子模块,利用下层模型提取细分种类的卷积特征,加入特征库;
颜色分布特征提取子模块,利用颜色特征提取算法提取细分种类颜色分布比例特征,加入特征库;
文字特征提取子模块,利用ocr技术提取细分种类的文字信息特征,加入特征库;
所述推理模块包括
上层推理模块,用于根据所述上层模型推理出所述目标对象的二维空间位置和粗分类别;
下层推理模块,提取所述目标对象的结构化特征并与特征库内特征作对比,推理出所述目标对象的细分类别;
所述类别管理模块包括
快速增加细分类别子模块,用于在现有上下文模型中快速添加一个新的细分类别;
删除类别模块,用于删除现有模型中可识别的类别。
综上所述,本发明取得了以下技术效果:
1、下层模型将特征较为相似的若干种细分种类再针对性的提取各自特有的特征进行分类,从而识别更为精准。
2、增加一个细分种类时,只需采集较少图片,对每张图片进行固定特征提取,无需改动之前已存在的类别,所以时间较短所需图片较少。
3、运用上下文模型,先定位粗分类别,再细分类别,这样可容纳的种类数量更多。
附图说明
图1是上层模型训练方法流程图;
图2是下层模型训练方法流程图;
图3是特征库生成流程图;
图4是推理流程图;
图5是快速增加细分种类流程图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
本具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
实施例:
本发明还包括一个硬件摄像头,用于数据采集。
一种物品识别的训练、推理以及增加新种类的方法,包括
模型训练,训练出物品识别所需的上层模型和下层模型,并生成特征库;
模型推理,推理出目标对象的粗分类别、细分类别和二维空间位置;
增加新种类,快速在现有模型中增加可识别的细分种类。
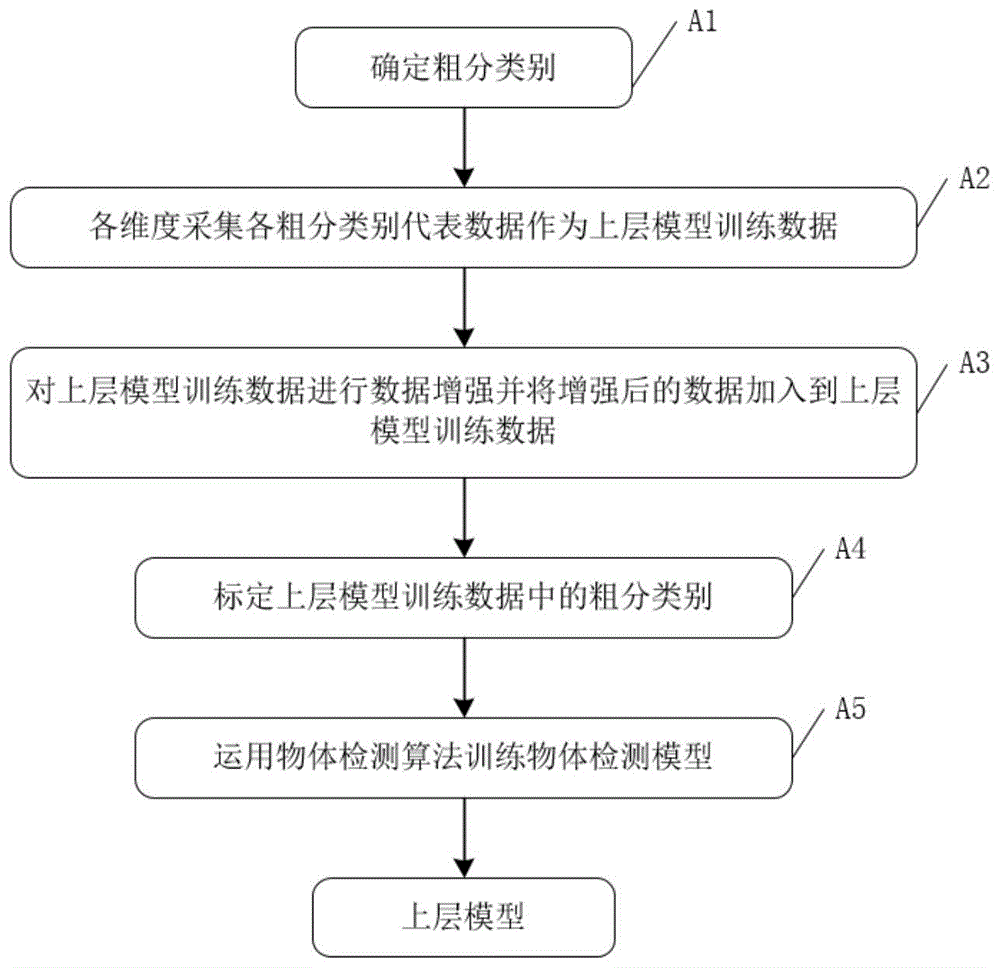
如图1、图2所示,所述模型训练包括以下步骤,
a1将所有待训练类别分为多个粗分类别以及细分类别;
a2分别采集各粗分类别的图片数据,作为上层模型训练数据;
a3对所述上层模型训练数据进行数据增强;
a4标定所述目标对象对应的粗分类别;
a5将所述上层模型训练数据训练出目标检测模型,并作为上层模型;
a6分别采集各细分类别的图片数据,作为下层模型训练数据;
a7对所述下层模型训练数据进行数据增强;
a8裁剪所述下层模型训练数据;
a9将所述下层模型训练数据训练出特征提取网络,并作为下层模型;
a10提取所述目标对象的结构化特征,形成特征库。
所述步骤a1中,把所有需要识别的所述目标对象的类别作为细分类别,然后将各特征相近的细分类别合并为同一个粗分类别;应该理解的是,细分类别包含于粗分类别。
所述步骤a2中,采集各粗分类别的图片数据时,在光线、角度、远近、纹理等维度的组合变换下采集多张照片,作为上层模型训练数据;
所述步骤a3中,按照明暗度、颜色、锐利度,利用图像处理方式对所述上层模型数据进行数据增强,并将数据增强得到的数据加入到所述上层模型训练数据中;可以利用opencv库,pil库编写图像处理函数,例如利用opencv库函数高斯模糊给图像增加噪音,或者实现retinex算法进行图像增强等,也可以通过其他适于实施的方式进行数据增强。
所述步骤a4中,标定所述上层模型训练数据中目标对象的位置及其粗分类别;
所述步骤a5中,利用目标检测算法训练所述上层模型训练数据,训练得到的目标检测模型作为上层模型。目标检测算法包括但不限于faster_rcnn算法,本实施例使用faster_rcnn算法作为目标检测算法,例如,faster_rcnn算法首先将图片分成约2000个很小的矩形区域作为待选区域,然后利用卷积神经网络提取整张图片的特征图谱,将2000个待选区域进行分类,最后将这2000个小区域中属于同一个物体的小区域进行合并,最终得到这张图片中目标区域的位置和类别。同样在本实施例中将要检测的图片利用faster_rcnn算法进行检测,检测出目标货物的粗分类别和位置。
所述步骤a6中,采集所述目标对象的图片数据时,将物品旋转360°,每隔5°在平视和俯视两个视角各采集一张图片,作为下层模型训练数据。
所述步骤a7中,按照明暗度、颜色、锐利度,利用图像处理方式对所述下层模型训练数据进行数据增强,并将数据增强得到的数据加入到所述下层模型训练数据中;
所述步骤a8中,裁剪所述下层模型训练数据,按照图片中所述目标对象的边界矩形裁剪,去除无效数据;
所述步骤a9中,利用神经网络训练所述下层模型训练数据,并将训练得到的特征提取网络作为下层模型。神经网络包括但不限于cnn(卷积神经网络)、vggnet,restnet(深度残差网络)。本实施例使用vgg16网络进行特征提取,vgg16共16层,分别有最大池化层,卷积层,全连接层,利用vgg16里面的各层网络对图片像素点进行运算,从而能得到图片的共性特征,避免过拟合。
如图3所示,所述步骤a10中,利用下层模型提取所述目标对象的卷积特征;利用颜色特征提取算法提取所述目标对象的颜色分布比例特征;利用ocr(光学字符识别)技术提取所述目标对象的文字信息特征;结构化所述目标对象细分类别的卷积特征、颜色分布比例特征和文字信息特征,形成特征库。
本实施例中利用步骤a9中训练好的vgg16网络模型中的参数对图片各像素进行运算,从而得到卷积特征。
ocr是光学字符识别的简称,本实施例使用预训练的faster_rcnn文字识别模型,识别货物上的文本区域和文字,从而得到文字信息特征。
其中,颜色特征提取公式为:
v=max③
由公式①②③将图片颜色由rgb转换到hsv空间中,并进行归一化操作:
其中,max表示某像素点颜色rgb值中的最大值,min表示某像素点颜色rgb值中的最小值,g表示某像素点颜色中g的值,r表示某像素点颜色中r的值,b表示某像素点颜色中b的值。h,s,v则对应表示此像素点转换到hsv空间并归一化后的hsv的值。
将训练数据中的主体颜色变换到hsv空间,提取颜色分布比例特征。
如图4所示,所述模型推理包括
b1利用上层模型推理出待识别图片中所述目标对象的空间位置及粗分类别;
b2利用下层模型提取出待识别图片中所述目标对象的卷积特征,利用颜色特征提取算法提取所述目标对象的颜色分布比例特征,利用ocr技术提取所述目标对象的文字信息特征;
b3结构化b2中所得的特征信息并与上层模型推理得到的粗分类别对应的特征库进行特征比对,得到所述目标对象的细分类别。比对方法包括但不限于knn(k最近邻),knn是通过计算训练样本中特征与待分类数据的差值距离,从而选取与待分类数据中特征最为相近的样本,通过这些样本的类别算出各个类别的概率,从而待分类数据的类别就是样本概率最高的那个类别。本实施例中利用目标对象的特征与特征库里面各个样本的特征进行knn比较,算出目标对象所属的类别。
如图5所示,所述增加新种类包括以下步骤,
c1采集待新增细分类别的图片数据,作为新类别训练数据;
c2对c1中采集的数据进行数据增强,并将数据增强得到的数据加入到所述新类别训练数据中;
c3裁剪所述新类别训练数据;
c4提取所述待新增细分类别的结构化特征,加入特征库。
所述步骤c1中,采集待新增细分类别的图片数据时,将具有代表性的待新增物品旋转360°,每隔5°在平视和俯视两个视角各采集一张图片,作为新类别训练数据;
所述步骤c2中,按照明暗度、颜色、锐利度,利用图像处理方式对所述新类别训练数据进行数据增强,并将数据增强得到的数据加入到新类别训练数据中;
所述步骤c3中,裁剪所述新类别训练数据,按照图片中待新增物品的边界矩形裁剪,去除无效数据;
所述步骤c4中,利用下层模型提取所述待新增物品的卷积特征,利用颜色特征提取算法提取所述待新增物品的颜色分布比例特征,利用ocr技术提取所述待新增物品的文字信息特征,结构化所述待新增物品的卷积特征、颜色分布比例特征、文字信息特征,并加入特征库。
一种物品识别的训练、推理以及增加新种类的系统,包括
训练模块,用于训练上层模型和下层模型;
特征提取模块,用于针对性的提取各细分种类的独有特征,形成特征库;
推理模块,用于利用上层模型、下层模型以及特征库推理出图片中所述目标对象的二维空间位置和细分类别;
类别管理模块,用于快速增加新的细分类别和删除现有类别;
通信模块,用于各模块间相互通信、数据传输。
所述训练模块包括
上层数据采集子模块,用于采集所述目标对象的各个维度的数据,作为上层模型训练数据;上层数据采集子模块包括但不限于相机。
上层数据增强子模块,用于对所述上层模型训练数据进行数据增强;
上层模型数据标定子模块,用于标定所述上层模型训练数据,在图片中标定出所述目标对象的二维空间位置和所属的粗分类别;
上层模型训练子模块,利用目标检测算法将所述上层模型训练数据训练出目标检测模型,作为上层模型;
下层数据采集子模块,用于采集所述目标对象的360°全方位的图片数据,作为下层模型训练数据;下层数据采集子模块包括但不限于相机。
下层数据增强子模块,用于对所述下层模型训练数据进行数据增强;
下层模型裁剪子模块,裁剪所述下层模型训练数据;
下层模型训练子模块,选取一个特征提取网络,训练出相应的下层模型;
所述特征提取模块包括
卷积特征提取子模块,利用下层模型提取细分种类的卷积特征,加入特征库;
颜色分布特征提取子模块,利用颜色特征提取算法提取细分种类颜色分布比例特征,加入特征库;
文字特征提取子模块,利用ocr技术提取细分种类的文字信息特征,加入特征库;
所述推理模块包括
上层推理模块,用于根据所述上层模型推理出所述目标对象的二维空间位置和粗分类别;
下层推理模块,提取所述目标对象的结构化特征并与特征库内特征作对比,推理出所述目标对象的细分类别;
所述类别管理模块包括
快速增加细分类别子模块,用于在现有上下文模型中快速添加一个新的细分类别;
删除类别模块,用于删除现有模型中可识别的类别。
通信模块用于各模块间相互通信以及接收用户输入。
下面以零售业货物种类识别为例进行说明,应当注意的是,本发明包括但不限于本示例。
现在要对一批零售的货物进行种类识别,比如,零售货物包括瓶装雪碧、瓶装百事可乐、瓶装可口可乐、罐装雪碧、罐装百事可乐、罐装可口可乐等。
根据步骤a1,将待识别货物划分为瓶装雪碧、瓶装百事可乐、瓶装可口可乐、罐装雪碧、罐装百事可乐、罐装可口可乐等细分类别,然后根据形态学等将相似度较高的细分类别都归类为同一个粗分类别,所以粗分类别就是罐装、瓶装、盒装、袋装等,本示例中粗分类别指瓶装和罐装。
根据步骤a2,选取部分能代表各粗分类别的货物放在货架上采集上层模型训练数据。其中在采集原始数据时要进行各个维度的变换,来保证模型的泛化能力,提升识别准确率。上层模型数据采集如下:
1.变换货物在货架上的空间位置来丰富货物在摄像头中视角的变化。
2.旋转货物来获得货物各个角度的纹理。
3.改变货架周边的光线,来丰富不同光线下的训练素材。
4.不断改变摄像头焦距或者货架离摄像头的远近距离来获得货物的不同尺寸数据。
根据步骤a3,将采集到的上层模型训练数据进行数据增强,可增强的方面有:
1.颜色、对比度、明暗度;
2.锐化;
3.增加噪声、模糊。
根据步骤a4,在上层数据标定子模块中,在每张图片数据上框定出想要识别的货物的边界矩形并且标记上对应的粗分类别,形成faster_rcnn训练所需要的标定文件。
根据步骤a5,将上层模型训练数据和标定文件进行faster_rcnn算法进行训练。实现faster_rcnn算法可以基于深度学习框架caffe、tensorflow等。
根据步骤a6,近距离的采集每个种类的图片数据,第一次要求采集的时候将摄像头视角与待采集的货物齐平,然后旋转货物,要求每旋转5°,采集一张图片。第二次要求采集的时候摄像头向下俯视30°看到货物,然后旋转货物,要求每旋转5°,采集一张图片。此步骤采集到的数据就是下层模型训练数据。
根据步骤a7,将采集到的下层模型训练数据进行数据增强,可增强的方面有:
1.颜色、对比度、明暗度;
2.锐化;
3.增加噪声、模糊。
根据步骤a8,将采集到的细分种类的图片数据中只保留货物边界矩形区域,其余部分裁剪掉。
根据步骤a9,基于caffe或者tensorflow实现一个vggnet的特征提取网络,并利用下层模型训练数据训练这个vggnet。
利用特征库提取模块形成特征库:
根据步骤a10,利用下层模型提取下层模型训练数据中各个细分类别的卷积特征。
利用颜色特征提取算法提取下层模型训练数据中的颜色分布比例特征。
利用east+ctc等ocr技术提取下层模型训练数据中的文字信息特征。
综合这三个特征形成每个细分类别的特征库。
根据步骤b1,利用上层模型推理出待识别图片中货物的空间位置及粗分类别。
根据步骤b2,利用下层模型提取待识别货物的卷积特征,利用颜色特征提取算法提取待识别货物的颜色分布比例特征,利用ocr技术提取待识别货物的文字信息特征。
根据步骤b3,将待识别货物的特征与特征库中的特征利用knn算法进行比对,得出货物的细分类别。
下面阐述如何快速增加细分种类:
根据步骤c1,近距离采集新种类的图片数据,第一次要求采集的时候将摄像头视角与待采集的货物齐平,然后旋转货物,要求每旋转5°,采集一张图片。第二次要求采集的时候摄像头向下俯视30°看到货物,然后旋转货物,要求每旋转5°,采集一张图片。
根据步骤c2,将采集到的新类别的代表数据进行数据增强,可增强的方面有:
1.颜色、对比度、明暗度;
2.锐化;
3.增加噪声、模糊。
根据步骤c3,将采集到新的细分种类的图片数据中只保留货物边界矩形区域,其余部分裁剪掉。
根据步骤c4,利用下层模型提取新细分类别的卷积特征。
利用步骤a10中提到的颜色特征提取算法提取新类别数据中的颜色分布比例特征。
利用ocr技术提取新类别数据中的文字信息特征。
综合卷积特征、颜色分布比例特征、文字信息特征,形成新细分类别的特征库。
本发明将特征相近的物品归类为同一粗分类别,再在下层模型中用更加多更细致的特征来区分这些近似物品,相较于现主流目标检测技术的误识别率,大大减少。本发明利用上下文模型的方式,可以扩展更多的类别。本发明增加一种新的细分类别物品,只需10分钟左右的时间和若干张图片(20张左右)就可以达到较高识别准确率。此方法可以应用于各行各业,比人脸识别算法更具扩展性。
以上所述仅是对本发明的较佳实施方式而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!