基于对抗学习的无监督领域适应方法、系统及介质与流程
本发明涉及计算机视觉和图像处理领域的方法,具体地,涉及基于对抗学习的无监督领域适应方法、系统及介质。
背景技术:
深度神经网络模型因为其在诸多领域的出色表现已经受到越来越多的关注。训练一个深度神经网络模型往往需要大量的有标注数据。然而为每一个新任务都收集一个大规模的有标注数据集是极为耗时耗力的。幸运的是,我们可以找到其他域的相关任务的数据,利用这些辅助数据或许可以帮助减少当前任务对标注一个新的数据集的依赖。然而,由于数据收集方式等的不同,两个不同领域的数据分布往往不同。由于“domainshift”的存在,在一个域上训练好的模型,直接在另外一个域上进行测试,模型的性能会下降许多。作为迁移学习的一个分支,领域适应就是为了解决不同域之间存在的“domainshift”问题。
根据目标领域有标注的样本的数量,领域适应可以分为:监督、半监督和无监督领域适应。对于无监督领域适应,目标领域没有相应的标注,模型需要根据有标注的源领域数据和无标注的目标领域数据,训练一个可以在目标领域上取得较好效果的模型。目前,很多无监督领域适应方法都试图通过各种机制对齐源领域和目标领域的统计分布,例如最大均值差异,相关性对齐,kl散度等。最近有研究采用对抗学习的方式,通过提取领域判别器不可区分的特征来对齐数据的分布。通常源领域和目标领域有两个不同的特征提取网络,并且源领域的特征提取网络是预先训练好并在之后的学习过程中保持固定不变。此外,有一些基于图像转换的领域适应方法出现,通过将源领域的图像转换成目标领域的图像,这些图像保留了源领域图像的标注信息,然后基于这些转换后的图像训练一个分类网络,用于对目标领域图像进行分类。
专利文献cn107958286a(申请号:201711183073.9)公开了一种领域适应性网络的深度迁移学习方法,其根据每一任务相关层对应的分布差异,分类错误率和错配度,确定领域适应性网络的损失函数的值,并基于损失函数的值,更新领域适应性网络的参数,以使领域适应性网络适配目标域。但是该专利文献没有使用对抗学习的方式,并且没有考虑特征的判别力对领域适应的重要性。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于对抗学习的无监督领域适应方法、系统及介质。
根据本发明提供的一种基于对抗学习的无监督领域适应方法,包括:
特征提取步骤:对源领域和目标领域的图像,使用特征提取网络提取图像的特征,获得源领域的图像特征和目标领域的图像特征;
类别预测步骤:根据获得的源领域的图像特征和目标领域的图像特征,预测图像属于各个类别的概率,获得类别预测概率;
领域判别步骤:根据获得的源领域的图像特征和目标领域的图像特征,通过领域判别网络预测图像特征来自源领域和目标领域的概率,获得领域预测概率;
对抗学习步骤:对获得的领域预测概率设计损失函数,使特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征;
特征判别力提升步骤:对获得的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐步骤:根据获得的类别预测概率,对获得的源领域的图像特征和目标领域的图像特征,进行条件概率对齐。
优选地,所述特征提取步骤:
利用特征提取网络,将源领域的图像和目标领域的图像输入特征提取网络,提取源领域的图像特征和目标领域的图像特征;
所述特征提取网络为深度卷积神经网络;
所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息。
优选地,所述类别预测步骤:
根据获得的源领域的图像特征和目标领域的图像特征,使用全连接层和softmax层构成的分类网络预测图像为各个类别的概率,获得类别预测概率;
所述类别指的是图像中包含的事物的类别;
所述类别预测步骤包括:
概率计算步骤:用e表示特征提取网络,e(xi)表示特征提取网络提取的图像xi的特征,维度为n维,c表示全连接层构成的分类网络,预设一共有k个类别,则全连接层的参数为n×k维的矩阵,记为w,全连接层的输出为:
c(e(xi))=wte(xi)
其中,
e(xi)表示特征提取网络提取的图像xi的特征;
c(e(xi))表示全连接层构成的分类网络c输入e(xi)后全连接层获得的输出;
上标t表示转置;
w表示全连接层的参数为n×k维的矩阵;
经过softmax层,将全连接层的输出转换为图像xi为各个类别的概率,其中图像xi为第k类的概率为:
其中,
pk(xi)表示图像xi为第k类的概率;
e表示自然常数;
[wte(xi)]k是wte(xi)第k维的值;
计算出图像为各个类别的概率后,可以得到图像xi的预测类别,即预测概率最大的类别如下:
其中,
分类网络学习步骤:对于有标注的源领域的图像,将所述概率计算步骤得到的图像xi为各个类别的概率与相应的标注进行对比,可以计算下面的分类网络损失函数:
其中,ls表示类别预测损失函数;
θe表示特征提取网络的参数;
θc表示类别预测网络的参数;
(xs,ys)表示源领域的图像和标签的分布;
p(xi)表示图像xi为各个类别的概率;
xi表示源领域的图像;
yi表示类别标签,以one-hot向量的形式,即第k类的标签为第k维为1其他维为0的k维向量;
h表示交叉熵函数;
根据获得的分类网络损失函数,使分类网络c和特征提取网络e进行学习,获得学习后的分类网络c和特征提取网络e,返回概率计算步骤继续执行。
优选地,所述领域判别步骤:
特征提取网络e提取的图像xi的特征为e(xi),维度为n维,d表示由全连接层构成的领域判别网络,其输出为d(e(xi)),令d(e(xi))的维度为1,经过sigmoid函数h转换到[0,1]区间内,h(d(e(xi)))代表图像xi来自源领域的概率,则1-h(d(e(xi)))代表图像来自目标领域的概率,其中sigmoid函数可以表达为:
其中,
h(d(e(xi)))表示图像xi来自源领域的概率;
d(e(xi))表示由全连接层构成的领域判别网络的输出。
所述对抗学习步骤:
根据获得的领域预测概率,采用对抗学习目标函数对特征提取网络和领域判别网络进行对抗学习,使领域判别网络尽可能地区分源领域的图像和目标领域的图像,使特征提取网络提取域不变特征,从而混淆领域判别网络,使领域判别网络误判,即使领域判别网络不能区分图像特征来自于源领域还是目标领域;
所述领域不变特征指源领域和目标领域共享的图像语义信息;
所述对抗学习目标函数指特征提取网络最小化对抗损失函数及领域判别网络最大化对抗损失函数,对抗学习目标函数如下所示:
其中,
ladv表示对抗损失函数;
xs表示源领域的样本集合;
xt表示目标领域的样本集合;
θd是领域判别网络的参数。
优选地,所述特征判别力提升步骤:
设每个类别均有一个类中心点,通过添加中心损失函数,使源领域的图像特征向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力;
所述中心损失函数:通过计算每个特征与相应类别中心点的欧几里得距离,可以得到如下中心损失函数:
其中,
lcs表示源领域的中心损失函数,它与特征提取网络e有关;
cyi是类别yi的类中心点;
在第一次迭代时,使用当前批次的数据初始化各类别的中心点,然后采用下面的方式更新中心点:
其中,
γ是类别中心点的更新速率;
k是类别的数量;
其中,
bt是第t次迭代时的批数据;
i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;
nk是此批数据中第k类样本的数量。
优选地,所述条件概率对齐步骤:
根据获得的目标领域图像的类别预测标签
所述最小化目标领域的中心损失函数表示如下:
其中,
lct表示通过计算目标领域的样本特征与相应类中心点的欧几里得距离所得到的目标领域的中心损失函数;
φ(xt)是目标领域的子集,其中的样本满足如下条件:
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,
p(xi)表示一个k维向量,其第k维代表样本xi是第k类的概率;
t表示一个阈值,只有预测标签的概率大于此阈值时,该预测标签才可信。
根据本发明提供的一种基于对抗学习的无监督领域适应系统,包括:
特征提取模块:对源领域和目标领域的图像,使用特征提取网络提取图像的特征,获得源领域的图像特征和目标领域的图像特征;
类别预测模块:根据获得的源领域的图像特征和目标领域的图像特征,预测图像属于各个类别的概率,获得类别预测概率;
领域判别模块:根据获得的源领域的图像特征和目标领域的图像特征,通过领域判别网络预测图像特征来自源领域和目标领域的概率,获得领域预测概率;
对抗学习模块:对获得的领域预测概率设计损失函数,使特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征;
特征判别力提升模块:对获得的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐模块:根据获得的类别预测概率,对获得的源领域的图像特征和目标领域的图像特征,进行条件概率对齐。
优选地,所述特征提取模块:
利用特征提取网络,将源领域的图像和目标领域的图像输入特征提取网络,提取源领域的图像特征和目标领域的图像特征;
所述特征提取网络为深度卷积神经网络;
所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息;
所述类别预测模块:
根据获得的源领域的图像特征和目标领域的图像特征,使用全连接层和softmax层构成的分类网络预测图像为各个类别的概率,获得类别预测概率;
所述类别指的是图像中包含的事物的类别;
所述类别预测模块包括:
概率计算模块:用e表示特征提取网络,e(xi)表示特征提取网络提取的图像xi的特征,维度为n维,c表示全连接层构成的分类网络,预设一共有k个类别,则全连接层的参数为n×k维的矩阵,记为w,全连接层的输出为:
c(e(xi))=wte(xi)
其中,
e(xi)表示特征提取网络提取的图像xi的特征;
c(e(xi))表示全连接层构成的分类网络c输入e(xi)后全连接层获得的输出;
上标t表示转置;
w表示全连接层的参数为n×k维的矩阵;
经过softmax层,将全连接层的输出转换为图像xi为各个类别的概率,其中图像xi为第k类的概率为:
其中,
pk(xi)表示图像xi为第k类的概率;
e表示自然常数;
[wte(xi)]k是wte(xi)第k维的值;
计算出图像为各个类别的概率后,可以得到图像xi的预测类别,即预测概率最大的类别如下:
其中,
分类网络学习模块:对于有标注的源领域的图像,将所述概率计算模块得到的图像xi为各个类别的概率与相应的标注进行对比,可以计算下面的分类网络损失函数:
其中,ls表示类别预测损失函数;
θe表示特征提取网络的参数;
θc表示类别预测网络的参数;
(xs,ys)表示源领域的图像和标签的分布;
p(xi)表示图像xi为各个类别的概率;
xi表示源领域的图像;
yi表示类别标签,以one-hot向量的形式,即第k类的标签为第k维为1其他维为0的k维向量;
h表示交叉熵函数;
根据获得的分类网络损失函数,使分类网络c和特征提取网络e进行学习,获得学习后的分类网络c和特征提取网络e,返回概率计算模块继续执行。
优选地,所述领域判别模块:
特征提取网络e提取的图像xi的特征为e(xi),维度为n维,d表示由全连接层构成的领域判别网络,其输出为d(e(xi)),令d(e(xi))的维度为1,经过sigmoid函数h转换到[0,1]区间内,h(d(e(xi)))代表图像xi来自源领域的概率,则1-h(d(e(xi)))代表图像来自目标领域的概率,其中sigmoid函数可以表达为:
其中,
h(d(e(xi)))表示图像xi来自源领域的概率;
d(e(xi))表示由全连接层构成的领域判别网络的输出;
所述对抗学习模块:
根据获得的领域预测概率,采用对抗学习目标函数对特征提取网络和领域判别网络进行对抗学习,使领域判别网络尽可能地区分源领域的图像和目标领域的图像,使特征提取网络提取域不变特征,从而混淆领域判别网络,使领域判别网络误判,即使领域判别网络不能区分图像特征来自于源领域还是目标领域;
所述领域不变特征指源领域和目标领域共享的图像语义信息;
所述对抗学习目标函数指特征提取网络最小化对抗损失函数及领域判别网络最大化对抗损失函数,对抗学习目标函数如下所示:
其中,
ladv表示对抗损失函数;
xs表示源领域的样本集合;
xt表示目标领域的样本集合;
θd是领域判别网络的参数;
所述特征判别力提升模块:
设每个类别均有一个类中心点,通过添加中心损失函数,使源领域的图像特征向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力;
所述中心损失函数:通过计算每个特征与相应类别中心点的欧几里得距离,可以得到如下中心损失函数:
其中,
lcs表示源领域的中心损失函数,它与特征提取网络e有关;
在第一次迭代时,使用当前批次的数据初始化各类别的中心点,然后采用下面的方式更新中心点:
其中,
γ是类别中心点的更新速率;
k是类别的数量;
其中,
bt是第t次迭代时的批数据;
i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;
nk是此批数据中第k类样本的数量;
所述条件概率对齐模块:
根据获得的目标领域图像的类别预测标签
所述最小化目标领域的中心损失函数表示如下:
其中,
lct表示通过计算目标领域的样本特征与相应类中心点的欧几里得距离所得到的目标领域的中心损失函数;
φ(xt)是目标领域的子集,其中的样本满足如下条件:
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,
p(xi)表示一个k维向量,其第k维代表样本xi是第k类的概率;
t表示一个阈值,只有预测标签的概率大于此阈值时,该预测标签才可信。
根据本发明提供的一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现上述中任一项所述的基于对抗学习的无监督领域适应方法的步骤。
与现有技术相比,本发明具有如下的有益效果:
1、本发明能够对源领域和目标领域的图像提取领域不变的且具有较强判别力的特征,从而实现无监督领域适应。
2、本发明通过在两个域之间共享同一个特征提取网络,并且使领域判别网络无法判断特征的来源,迫使特征提取网络提取两个域之间共享的特征,即图像的语义信息,而忽略每个域特有的信息。由于提取的特征是领域不变的,因此由源领域的图像训练得到的类别预测网络也可以应用到目标领域上,从而实现领域适应。通过引入中心损失函数,源领域内同一类别的图像的特征会更加聚集和紧凑,从而提升了特征的判别力。除了边缘概率分布,本发明还考虑了两个域的条件概率分布,通过对齐两个域的条件概率分布,目标领域的特征也保持了较好的判别能力,从而提升了模型在目标领域上的类别预测准确率。此外,通过共享同一个特征提取网络,两个域的图像特征是联合学习的,并且在测试的时候,不需要知道图像来自源领域还是目标领域。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明优选例2提供的方法流程示意图。
图2为本发明优选例2提供的系统原理示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
根据本发明提供的一种基于对抗学习的无监督领域适应方法,包括:
特征提取步骤:对源领域和目标领域的图像,使用特征提取网络提取图像的特征,获得源领域的图像特征和目标领域的图像特征;
类别预测步骤:根据获得的源领域的图像特征和目标领域的图像特征,预测图像属于各个类别的概率,获得类别预测概率;
领域判别步骤:根据获得的源领域的图像特征和目标领域的图像特征,通过领域判别网络预测图像特征来自源领域和目标领域的概率,获得领域预测概率;
对抗学习步骤:对获得的领域预测概率设计损失函数,使特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征;
特征判别力提升步骤:对获得的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐步骤:根据获得的类别预测概率,对获得的源领域的图像特征和目标领域的图像特征,进行条件概率对齐。
具体地,所述特征提取步骤:
利用特征提取网络,将源领域的图像和目标领域的图像输入特征提取网络,提取源领域的图像特征和目标领域的图像特征;
所述特征提取网络为深度卷积神经网络;
所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息。
具体地,所述类别预测步骤:
根据获得的源领域的图像特征和目标领域的图像特征,使用全连接层和softmax层构成的分类网络预测图像为各个类别的概率,获得类别预测概率;
所述类别指的是图像中包含的事物的类别;
所述类别预测步骤包括:
概率计算步骤:用e表示特征提取网络,e(xi)表示特征提取网络提取的图像xi的特征,维度为n维,c表示全连接层构成的分类网络,预设一共有k个类别,则全连接层的参数为n×k维的矩阵,记为w,全连接层的输出为:
c(e(xi))=wte(xi)
其中,
e(xi)表示特征提取网络提取的图像xi的特征;
c(e(xi))表示全连接层构成的分类网络c输入e(xi)后全连接层获得的输出;
上标t表示转置;
w表示全连接层的参数为n×k维的矩阵;
经过softmax层,将全连接层的输出转换为图像xi为各个类别的概率,其中图像xi为第k类的概率为:
其中,
pk(xi)表示图像xi为第k类的概率;
e表示自然常数;
[wte(xi)]k是wte(xi)第k维的值;
计算出图像为各个类别的概率后,可以得到图像xi的预测类别,即预测概率最大的类别如下:
其中,
分类网络学习步骤:对于有标注的源领域的图像,将所述概率计算步骤得到的图像xi为各个类别的概率与相应的标注进行对比,可以计算下面的分类网络损失函数:
其中,ls表示类别预测损失函数;
θe表示特征提取网络的参数;
θc表示类别预测网络的参数;
(xs,ys)表示源领域的图像和标签的分布;
p(xi)表示图像xi为各个类别的概率;
xi表示源领域的图像;
yi表示类别标签,以one-hot向量的形式,即第k类的标签为第k维为1其他维为0的k维向量;
h表示交叉熵函数;
根据获得的分类网络损失函数,使分类网络c和特征提取网络e进行学习,获得学习后的分类网络c和特征提取网络e,返回概率计算步骤继续执行。
具体地,所述领域判别步骤:
特征提取网络e提取的图像xi的特征为e(xi),维度为n维,d表示由全连接层构成的领域判别网络,其输出为d(e(xi)),令d(e(xi))的维度为1,经过sigmoid函数h转换到[0,1]区间内,h(d(e(xi)))代表图像xi来自源领域的概率,则1-h(d(e(xi)))代表图像来自目标领域的概率,其中sigmoid函数可以表达为:
其中,
h(d(e(xi)))表示图像xi来自源领域的概率;
d(e(xi))表示由全连接层构成的领域判别网络的输出。
所述对抗学习步骤:
根据获得的领域预测概率,采用对抗学习目标函数对特征提取网络和领域判别网络进行对抗学习,使领域判别网络尽可能地区分源领域的图像和目标领域的图像,使特征提取网络提取域不变特征,从而混淆领域判别网络,使领域判别网络误判,即使领域判别网络不能区分图像特征来自于源领域还是目标领域;
所述领域不变特征指源领域和目标领域共享的图像语义信息;
所述对抗学习目标函数指特征提取网络最小化对抗损失函数及领域判别网络最大化对抗损失函数,对抗学习目标函数如下所示:
其中,
ladv表示对抗损失函数;
xs表示源领域的样本集合;
xt表示目标领域的样本集合;
θd是领域判别网络的参数。
具体地,所述特征判别力提升步骤:
设每个类别均有一个类中心点,通过添加中心损失函数,使源领域的图像特征向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力;
所述中心损失函数:通过计算每个特征与相应类别中心点的欧几里得距离,可以得到如下中心损失函数:
其中,
lcs表示源领域的中心损失函数,它与特征提取网络e有关;
在第一次迭代时,使用当前批次的数据初始化各类别的中心点,然后采用下面的方式更新中心点:
其中,
γ是类别中心点的更新速率;
k是类别的数量;
其中,
bt是第t次迭代时的批数据;
i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;
nk是此批数据中第k类样本的数量。
具体地,所述条件概率对齐步骤:
根据获得的目标领域图像的类别预测标签
所述最小化目标领域的中心损失函数表示如下:
其中,
lct表示通过计算目标领域的样本特征与相应类中心点的欧几里得距离所得到的目标领域的中心损失函数;
φ(xt)是目标领域的子集,其中的样本满足如下条件:
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,
p(xi)表示一个k维向量,其第k维代表样本xi是第k类的概率;
t表示一个阈值,只有预测标签的概率大于此阈值时,该预测标签才可信。
本发明提供的基于对抗学习的无监督领域适应系统,可以通过本发明给的基于对抗学习的无监督领域适应方法的步骤流程实现。本领域技术人员可以将所述基于对抗学习的无监督领域适应方法,理解为所述基于对抗学习的无监督领域适应系统的一个优选例。
根据本发明提供的一种基于对抗学习的无监督领域适应系统,包括:
特征提取模块:对源领域和目标领域的图像,使用特征提取网络提取图像的特征,获得源领域的图像特征和目标领域的图像特征;
类别预测模块:根据获得的源领域的图像特征和目标领域的图像特征,预测图像属于各个类别的概率,获得类别预测概率;
领域判别模块:根据获得的源领域的图像特征和目标领域的图像特征,通过领域判别网络预测图像特征来自源领域和目标领域的概率,获得领域预测概率;
对抗学习模块:对获得的领域预测概率设计损失函数,使特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征;
特征判别力提升模块:对获得的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐模块:根据获得的类别预测概率,对获得的源领域的图像特征和目标领域的图像特征,进行条件概率对齐。
具体地,所述特征提取模块:
利用特征提取网络,将源领域的图像和目标领域的图像输入特征提取网络,提取源领域的图像特征和目标领域的图像特征;
所述特征提取网络为深度卷积神经网络;
所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息;
所述类别预测模块:
根据获得的源领域的图像特征和目标领域的图像特征,使用全连接层和softmax层构成的分类网络预测图像为各个类别的概率,获得类别预测概率;
所述类别指的是图像中包含的事物的类别;
所述类别预测模块包括:
概率计算模块:用e表示特征提取网络,e(xi)表示特征提取网络提取的图像xi的特征,维度为n维,c表示全连接层构成的分类网络,预设一共有k个类别,则全连接层的参数为n×k维的矩阵,记为w,全连接层的输出为:
c(e(xi))=wte(xi)
其中,
e(xi)表示特征提取网络提取的图像xi的特征;
c(e(xi))表示全连接层构成的分类网络c输入e(xi)后全连接层获得的输出;
上标t表示转置;
w表示全连接层的参数为n×k维的矩阵;
经过softmax层,将全连接层的输出转换为图像xi为各个类别的概率,其中图像xi为第k类的概率为:
其中,
pk(xi)表示图像xi为第k类的概率;
e表示自然常数;
[wte(xi)]k是wte(xi)第k维的值;
计算出图像为各个类别的概率后,可以得到图像xi的预测类别,即预测概率最大的类别如下:
其中,
分类网络学习模块:对于有标注的源领域的图像,将所述概率计算模块得到的图像xi为各个类别的概率与相应的标注进行对比,可以计算下面的分类网络损失函数:
其中,ls表示类别预测损失函数;
θe表示特征提取网络的参数;
θc表示类别预测网络的参数;
(xs,ys)表示源领域的图像和标签的分布;
p(xi)表示图像xi为各个类别的概率;
xi表示源领域的图像;
yi表示类别标签,以one-hot向量的形式,即第k类的标签为第k维为1其他维为0的k维向量;
h表示交叉熵函数;
根据获得的分类网络损失函数,使分类网络c和特征提取网络e进行学习,获得学习后的分类网络c和特征提取网络e,返回概率计算模块继续执行。
具体地,所述领域判别模块:
特征提取网络e提取的图像xi的特征为e(xi),维度为n维,d表示由全连接层构成的领域判别网络,其输出为d(e(xi)),令d(e(xi))的维度为1,经过sigmoid函数h转换到[0,1]区间内,h(d(e(xi)))代表图像xi来自源领域的概率,则1-h(d(e(xi)))代表图像来自目标领域的概率,其中sigmoid函数可以表达为:
其中,
h(d(e(xi)))表示图像xi来自源领域的概率;
d(e(xi))表示由全连接层构成的领域判别网络的输出;
所述对抗学习模块:
根据获得的领域预测概率,采用对抗学习目标函数对特征提取网络和领域判别网络进行对抗学习,使领域判别网络尽可能地区分源领域的图像和目标领域的图像,使特征提取网络提取域不变特征,从而混淆领域判别网络,使领域判别网络误判,即使领域判别网络不能区分图像特征来自于源领域还是目标领域;
所述领域不变特征指源领域和目标领域共享的图像语义信息;
所述对抗学习目标函数指特征提取网络最小化对抗损失函数及领域判别网络最大化对抗损失函数,对抗学习目标函数如下所示:
其中,
ladv表示对抗损失函数;
xs表示源领域的样本集合;
xt表示目标领域的样本集合;
θd是领域判别网络的参数;
所述特征判别力提升模块:
设每个类别均有一个类中心点,通过添加中心损失函数,使源领域的图像特征向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力;
所述中心损失函数:通过计算每个特征与相应类别中心点的欧几里得距离,可以得到如下中心损失函数:
其中,
lcs表示源领域的中心损失函数,它与特征提取网络e有关;
在第一次迭代时,使用当前批次的数据初始化各类别的中心点,然后采用下面的方式更新中心点:
其中,
γ是类别中心点的更新速率;
k是类别的数量;
其中,
bt是第t次迭代时的批数据;
i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;
nk是此批数据中第k类样本的数量;
所述条件概率对齐模块:
根据获得的目标领域图像的类别预测标签
所述最小化目标领域的中心损失函数表示如下:
其中,
lct表示通过计算目标领域的样本特征与相应类中心点的欧几里得距离所得到的目标领域的中心损失函数;
φ(xt)是目标领域的子集,其中的样本满足如下条件:
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,
p(xi)表示一个k维向量,其第k维代表样本xi是第k类的概率;
t表示一个阈值,只有预测标签的概率大于此阈值时,该预测标签才可信。
根据本发明提供的一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现上述中任一项所述的基于对抗学习的无监督领域适应方法的步骤。
下面通过优选例,对本发明进行更为具体地说明。
优选例1:
一种基于领域不变对抗学习的无监督领域适应方法,包括:
特征提取步骤:对源领域和目标领域的图像,使用深度卷积神经网络提取图像的特征,获得源领域的图像特征和目标领域的图像特征;
类别预测步骤:根据获得的源领域的图像特征和目标领域的图像特征,使用全连接层和softmax层构成的分类网络预测图像为各个类别的概率;类别指的是图像中包含的事物的类别,例如猫,狗,汽车等。
领域判别步骤:对所述特征提取步骤得到的源领域的图像特征和目标领域的图像的特征,通过领域判别网络预测特征来自源领域和目标领域的概率;
对抗学习步骤:对所述领域判别步骤得到的领域预测概率设计损失函数,特征提取网络和领域判别网络进行对抗学习使得特征提取网络能够提取领域不变特征,即源领域和目标领域共享的图像语义信息;
特征判别力提升步骤:对所述特征提取步骤得到的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐步骤:对所述特征提取步骤得到的源领域的图像特征和目标领域的图像特征进行条件概率对齐。
所述特征提取步骤,其中:
利用深度卷积神经网络模型,将源领域的图像和目标领域的图像输入共享的特征提取网络,提取源领域的图像特征和目标领域的图像特征,即源领域和目标领域共享的语义信息,而忽略与领域有关的信息;
所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息。
所述类别预测步骤,其中:利用全连接层和softmax层构成的分类网络,对源领域的图像和目标领域的图像进行类别预测。
所述类别预测步骤,具体如下:
我们用e表示特征提取网络,e(xi)表示特征提取网络提取的图像xi的特征,维度为n维,c表示全连接层构成的分类网络。假设一共有k个类别,则全连接层的参数为n×k维的矩阵,记为w,全连接层的输出为:
c(e(xi))=wte(xi)
经过softmax层,将全连接层的输出转换为图像xi为各个类别的概率,其中图像xi为第k类的概率为:
其中,[wte(xi)]k是wte(xi)第k维的值。计算出图像为各个类别的概率后,我们可以得到图像xi的预测类别,即预测概率最大的类别:
对于有标注的源领域的图像,将所述类别预测步骤得到的概率与相应的标注进行对比,可以计算下面的损失函数:(此损失函数是用来帮助分类网络进行学习的,使模型能够学会预测图像的类别)
其中,ls表示类别预测损失函数;
θe表示特征提取网络的参数;
θc表示类别预测网络的参数;
(xs,ys)表示源领域的图像和标签的分布;
xi表示源领域的图像;
yi表示类别标签,以one-hot向量的形式,即第k类的标签为第k维为1其他维为0的k维向量;
h表示交叉熵函数。
所述领域判别步骤,其中:所述领域判别网络是一个由全连接层构成的网络(此处所述全连接层为3层全连接层,并且学到的参数不同,因此和上文的全连接层构成的网络不同),它能够输出特征属于源领域和目标领域的概率。
所述领域判别步骤,具体如下:
假设特征提取网络e提取的图像xi的特征为e(xi),维度为n维,d表示由3层全连接层构成的领域判别网络,其输出为d(e(xi))。因为一共有2个领域(源领域和目标领域),我们令d(e(xi))的维度为1,经过sigmoid函数h转换到[0,1]区间内,h(d(e(xi)))代表图像xi来自源领域的概率,则1-h(d(e(xi)))代表图像来自目标领域的概率。其中sigmoid函数可以表达为:
所述对抗学习步骤,其中:特征提取网络和领域判别网络进行min-max的游戏(指特征提取网络最小化对抗损失函数,领域判别网络最大化对抗损失函数),领域判别网络尽可能地区分源领域的图像和目标领域的图像,而特征提取网络尽可能地混淆领域判别网络,通过提取域不变的特征使得领域判别网络不能区分特征来自于哪个域。
所述对抗学习步骤,具体如下:
特征提取网络和领域判别网络进行min-max的游戏(指特征提取网络最小化对抗损失函数,领域判别网络最大化对抗损失函数),目标函数如下:
其中,
ladv表示对抗损失函数;
xs表示源领域的样本集合;
xt表示目标领域的样本集合;
θe是特征提取网络的参数;
θd是领域判别网络的参数;
h(d(e(xi)))是图像xi来自源领域的概率,
通过这样的对抗学习,领域判别网络使得预测的源领域的图像来自源领域的概率尽可能大,而目标领域的图像来自源领域的概率尽可能小;特征提取网络则是相反的作用,它的目的是提取域不变的特征,从而混淆领域判别网络,使领域判别网络误判。
所述特征判别力提升步骤,其中:假设每个类别均有一个类中心点,通过添加中心损失函数,源领域的图像特征将会向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力。
所述特征判别力提升步骤,具体如下:
假设每个类别均有一个类中心点,在得到源领域的样本的特征之后,通过计算每个特征与相应类别中心点的欧几里得距离,可以得到如下中心损失函数:
其中,
lcs表示源领域的中心损失函数,它与特征提取网络e有关;
通常类别的中心点由整个数据集中属于此类别的图像的特征计算得到,但是由于网络训练时采用批处理的方式,无法用整个数据集进行计算,因此通过下面介绍的迭代更新的方式,在网络训练的过程中不断更新各类别的中心点。在第一次迭代时,使用当前批次的数据初始化各类别的中心点,然后采用下面的方式更新中心点:
其中,
γ是类别中心点的更新速率,
k是类别的数量,
其中,
bt是第t次迭代时的批数据;
i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;
nk是此批数据中第k类样本的数量,
所述条件概率对齐步骤,其中:因为缺少目标领域的图像标签,直接对齐两个领域的条件概率p(y|x)是很困难的,因此我们通过对齐两个领域的类条件概率p(x|y)来近似地对齐条件概率。我们利用所述类别预测步骤得到的目标领域图像的类别预测标签
所述条件概率对齐步骤,具体如下:
除边缘概率分布外,两个域的条件概率分布通常也不一样,即p(y|x)不同。由于目标领域没有标注信息,直接对齐两个域的条件概率分布较为困难,因此,通过对齐类边缘分布p(x|y)来近似。利用所述类别预测步骤得到的目标领域的图像的类别,设计如下损失函数来对齐p(x|y):
其中,
lct表示通过计算目标领域的样本特征与相应类中心点的欧几里得距离所得到的目标领域的中心损失函数;
φ(xt)是目标领域的子集,其中的样本满足如下条件:
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,p(xi)是一个k维向量,其第k维代表样本xi是第k类的概率,t是一个阈值,只有预测标签的概率大于此阈值时,才认为该预测标签是可信的。
优选例2:
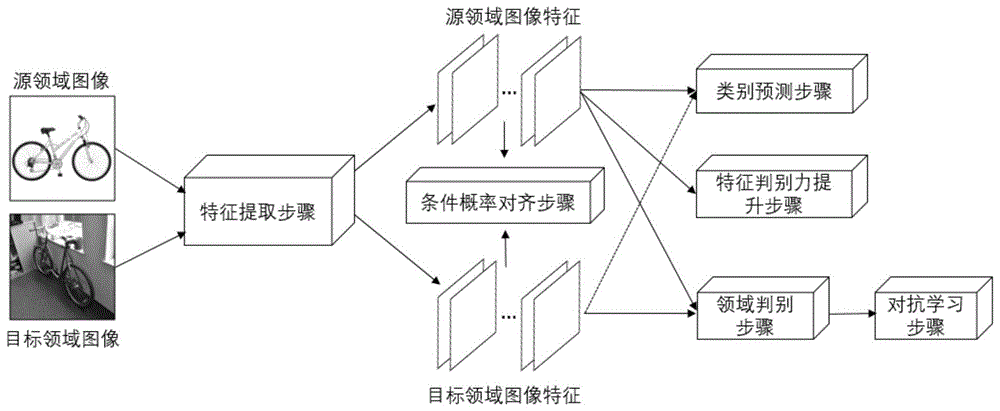
如图1所示,为本发明基于领域不变对抗学习的无监督领域适应方法实施例的流程图,该方法通过特征提取步骤将源领域的图像和目标领域的图像处理成为源领域的图像特征和目标领域的图像特征,并使用类别预测步骤预测源领域的图像和目标领域的图像的类别,通过领域判别步骤和对抗学习步骤使得提取的特征是域不变的,因此由源领域的图像优化得到的类别预测网络也可以应用到目标领域上,实现领域适应。通过特征判别力提升步骤,源领域内同一类别的图像的特征更加聚集和紧凑,从而提升了特征的判别力。此外,条件概率对齐步骤对齐了两个域的条件概率,使得目标领域的特征也保持了较好的判别能力,从而提升了在目标领域上的类别预测准确率。
本发明通过在两个域之间共享同一个特征提取网络,并且使领域判别网络无法判断特征的来源,迫使特征提取网络能够提取两个域之间共享的特征,即图像的语义信息,而忽略两个域特有的信息。通过共享同一个特征提取网络,两个域的图像特征是联合学习的,并且在测试的时候,不需要知道图像来自源领域还是目标领域。
具体地,参照图1,所述方法包括如下步骤:
特征提取步骤:对源领域和目标领域的图像,使用深度卷积神经网络提取图像的特征,得到源领域的图像特征和目标领域的图像特征;
类别预测步骤:对所述特征提取步骤得到的源领域的图像特征和目标领域的图像特征,使用全连接层构成的分类网络预测图像为各个类别的概率;
领域判别步骤:对所述特征提取步骤得到的源领域的图像特征和目标领域的图像的特征,通过领域判别网络预测特征来自源领域和目标领域的概率;
对抗学习步骤:对所述领域判别步骤得到的领域预测概率设计损失函数,特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征,即源领域和目标领域共享的图像语义信息;
特征判别力提升步骤:对所述特征提取步骤得到的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐步骤:对所述特征提取步骤得到的源领域的图像特征和目标领域的图像特征进行条件概率对齐。
对应于上述方法,本发明还提供一种基于领域不变对抗学习的无监督领域适应系统的实施例,包括:
特征提取模块:对源领域和目标领域的图像,使用深度卷积神经网络提取图像的特征,得到源领域的图像特征和目标领域的图像特征;
类别预测模块:对所述特征提取模块得到的源领域的图像特征和目标领域的图像特征,使用全连接层构成的分类网络预测图像为各个类别的概率;
领域判别模块:对所述特征提取模块得到的源领域的图像特征和目标领域的图像的特征,通过领域判别网络预测特征来自源领域和目标领域的概率;
对抗学习模块:对所述领域判别模块得到的领域预测概率设计损失函数,特征提取网络和领域判别网络进行对抗学习,使得特征提取网络能够提取领域不变特征,即源领域和目标领域共享的图像语义信息;
特征判别力提升模块:对所述特征提取模块得到的源领域的图像特征,使用中心损失函数提升特征的判别力;
条件概率对齐模块:对所述特征提取模块得到的源领域的图像特征和目标领域的图像特征进行条件概率对齐。
上述基于领域不变对抗学习的无监督领域适应系统各个模块实现的技术特征可以与上述基于领域不变对抗学习的无监督领域适应方法中对应步骤实现的技术特征相同。
以下对上述各个步骤和模块的具体实现进行详细的描述,以便理解本发明技术方案。
在本发明部分实施例中,所述特征提取步骤,其中:利用深度卷积神经网络模型,将源领域的图像和目标领域的图像输入共享的特征提取网络,提取领域不变特征,即源领域和目标领域共享的语义信息,而忽略与领域有关的信息。所述源领域的图像和目标领域的图像是来自两个不同分布的针对同一分类任务的图像,源领域的图像有相应的标注,目标领域的图像没有标注信息。
在本发明部分实施例中,所述类别预测步骤,其中:利用全连接层构成的分类网络,对源领域的图像和目标领域的图像进行类别预测。
在本发明部分实施例中,所述领域判别步骤,其中:所述领域判别网络是一个由全连接层构成的网络,它能够输出特征属于源领域和目标领域的概率。
在本发明部分实施例中,所述对抗学习步骤,其中:特征提取网络和领域判别网络进行min-max的游戏,领域判别网络尽可能地区分源领域的图像和目标领域的图像,而特征提取网络尽可能地混淆领域判别网络,通过提取领域不变的特征使得领域判别网络不能区分特征来自于哪个域。
在本发明部分实施例中,所述特征判别力提升步骤,其中:假设每个类别均有一个类中心点,通过添加中心损失函数,源领域的图像特征将会向其对应的类别的中心点靠近,从而减少散落在类间区域的样本,提升所提取的特征的判别力。
在本发明部分实施例中,所述条件概率对齐步骤,其中:利用所述类别预测步骤得到的类别标签,将源领域的图像和目标领域的图像的类条件概率p(x|y)对齐,使得目标领域的图像也靠近相应的类别中心,从而使无标注的目标领域的图像特征也具有较好的判别力。
具体地,特征提取模块、类别预测模块、领域判别模块、对抗学习模块、特征判别力提升模块和条件概率对齐模块组成的领域适应系统网络框架如图2所示,整个系统框架能够端到端地进行训练。
在如图2所示的实施例的系统框架中,源领域的图像和目标领域的图像输入特征提取模块,输出源领域的图像的特征和目标领域的图像的特征,特征提取模块是由一系列卷积层(+batchnorm层+relu层)组成的下采样模块构成的,可以使用现有的网络结构,例如alexnet,vgg,resnet等。源领域的图像的特征会输入类别预测模块,预测图像的类别,产生如下损失函数:
其中,θe是特征提取网络的参数,θc是类别预测网络的参数,(xs,ys)代表源领域的图像和标签的分布,xi代表源领域的图像,yi是其类别标签,e代表特征提取网络,c代表类别预测网络,h代表交叉熵函数。
为了提取领域不变特征,如图2所示,提取的源领域的图像特征和目标领域的图像特征会通过领域判别模块,领域判别网络是一个由全连接层构成的网络,它能够输出特征属于源领域和目标领域的概率。特征提取网络和领域判别网络进行min-max的游戏,领域判别网络尽可能地区分源领域的图像和目标领域的图像,而特征提取网络尽可能地混淆领域判别网络,通过提取领域不变的特征使得领域判别网络不能区分特征来自于哪个域。具体的目标函数如下所示:
其中,θe是特征提取网络的参数,θd是领域判别网络的参数,d(e(xi))是图像xi来自源领域的概率,通过这样的对抗学习,领域判别网络使得预测的源领域的图像来自源领域的概率尽可能大,而目标领域的图像来自源领域的概率尽可能小;特征提取网络则是相反的作用,它的目的是提取领域不变的特征,从而混淆领域判别网络,使领域判别网络误判。
为了使提取的源领域特征更具有判别力,如图2所示,提取的源领域的图像特征会通过特征判别力提升模块,假设每个类别具有一个类别中心,源领域的图像的特征需要靠近其对应类别的中心,这样可以减少类间区域的样本数,因此定义如下中心损失函数:
其中,
其中,
其中,bt是第t次迭代时的批数据;i(.)代表指示函数,当yi=k成立时,i(yi=k)=1,否则为0;nk是此批数据中第k类样本的数量,
通过中心损失函数,特征提取模块得到的同一类别的图像的特征会更加聚集在一起,从而增加特征的判别力。
除边缘概率分布外,两个域的条件概率分布也不一样,即p(y|x)不同。由于目标领域没有标注信息,直接对齐两个域的条件概率分布较为困难,因此,通过对齐类边缘分布p(x|y)来近似。利用类别预测步骤得到的目标领域的图像的类别,设计如下损失函数:
其中,
φ(xt)={xi∈xtandmax(p(xi))>t}
其中,p(xi)是一个k维向量,其第k维代表样本xi是第k类的概率,t是一个阈值,只有预测标签的概率大于此阈值时,才认为该预测标签是可信的。
综上,本发明通过在两个域之间共享同一个特征提取网络,并且使领域判别网络无法判断特征的来源,迫使特征提取网络能够提取两个域之间共享的特征,即图像的语义信息,而忽略每个域特有的信息。由于提取的特征是领域不变的,因此由源领域的图像训练得到的类别预测网络也可以应用到目标领域上,从而实现领域适应。由于引入了中心损失函数,源领域内同一类别的图像的特征会更加聚集和紧凑,从而提升了特征的判别力。此外,通过对齐两个域的条件概率分布,目标领域的特征也保持了较好的判别能力,从而提升了目标领域上的类别预测准确率。此外,通过共享同一个特征提取网络,两个域的图像特征是联合学习的,并且在测试的时候,不需要知道图像来自源领域还是目标领域。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!