一种金融文本主观句自动识别方法与流程
本发明涉及金融技术、数据挖掘、信息检索等领域,尤其涉及一种金融文本主观句自动识别方法。
背景技术:
金融市场信息主要来源于非结构化的文本数据,如企业年报、公告、新闻、政策法规、市场研报等,其中蕴含了大量金融机构与分析师对市场行情的研究与预判,有效挖掘此类信息对金融业务开展与投资决策具有较大的指导意义。该问题主要通过数据挖掘领域的情感分析技术进行解决。现有的情感分析技术主要包括机器学习方法和语义方法。基于机器学习的情感分析方法需要大量标注的样本数据对分类模型进行训练,而训练数据集的建立需要人工对文本逐条阅读,与自动情感分析的目的相矛盾。因此,许多研究者将情感分析的研究重点集中在语义方法上,并已取得一定的成果。
最早提出的语义情感分析方法将点互信息与信息检索方法相结合,借助搜索引擎的后台数据库获得语义倾向信息并做出情感判断,其可靠性已在英文顾客评论分析中得到了初步验证。日本nec公司对产品声誉文本数据进行了语义抽象和分类研究,取得了初步成功。匹兹堡大学的智能系统研究了情感分析中的语义强度识别问题,对该领域做出了基础性的贡献。另外,一些研究者采用普林斯顿大学开发的英文词网开展英文语义情感分析研究,也取得了较好的结果。
实现情感分析的前提是有效识别文本数据中表达主观情感、态度和观点的内容,对文本的主观性成分进行判断,情感倾向主要通过主观句进行表达。因此,主观语句自动识别技术是情感分析的基础性关键技术。现有的主观情感识别方法主要针对英文文本进行研究,例如选择某些词类(代词、形容词、情态动词、副词等)、标点和句子位置作为特征,实现对主观句识别。还有的方法根据先前确定的主观特征,分别建立主观分类器和客观分类器,从未标注的文本数据中自动获取大量的主观句和客观句,并从中抽取主观性词语搭配,以实现对主观语句的识别。
文本主观句识别技术除了可用于金融数据分析外,还可广泛用于搜索引擎、企业客户服务系统等应用系统中,以帮助企业深入挖掘有价值的信息。然而,现有方法大多针对英文文本数据实现,由于语言结构的差异,它们难以直接用于中文文本数据。因此,目前国内的工业界和金融界对中文文本数据的主观句识别技术具有较为迫切的应用需求。
技术实现要素:
本发明要解决的问题是如何自动识别金融文本所包含的主观性语句。为了解决该问题,本发明提出了一种金融文本主观句自动识别方法。
本发明的目的是通过以下技术方案实现的:
本发明的有益效果是:
1、有效解决了非结构化文本数据中的主观性语句自动识别问题,基于语义方法无需标注训练语料,极大的提升了计算效率。
2、在主观模式抽取步骤中,使用chi检验筛选双词性组合,可有效区分不同词性的语义功能,保证了本发明对主观语句识别的准确率。
3、在主观模式抽取步骤中,使用查准率对主观模式赋权,可有效区分主观模式在不同语句中的主观程度,同样保证了本发明对主观语句识别的准确率。
附图说明
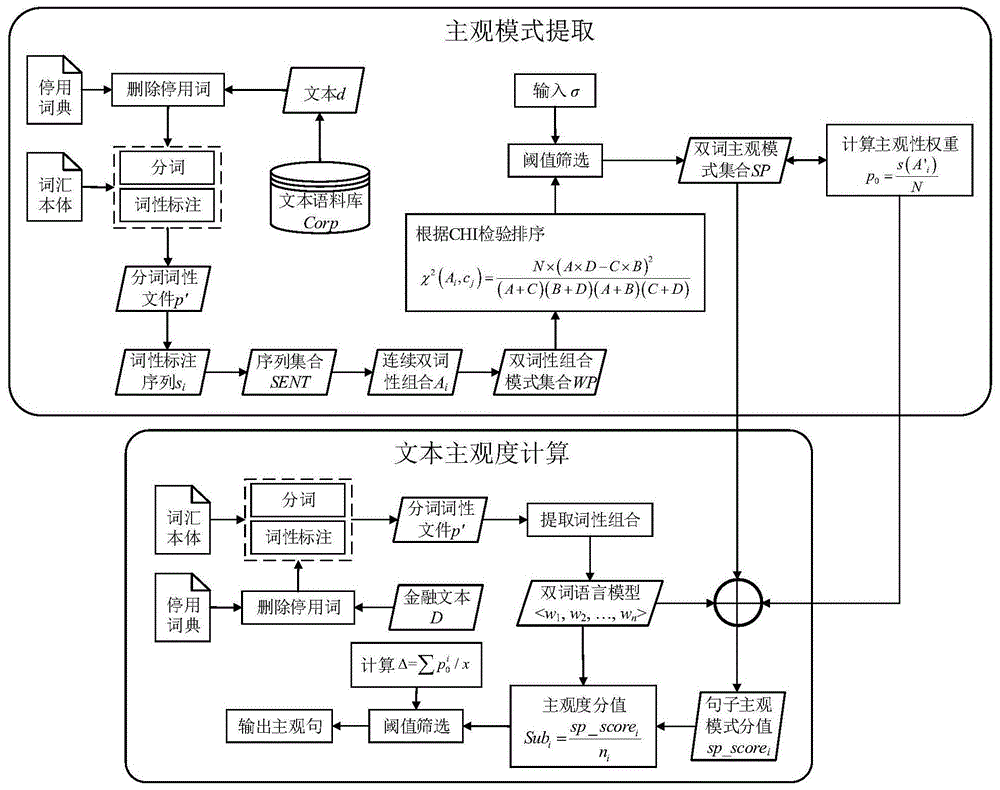
图1为金融文本主观句自动识别方法流程图。
具体实施方式
下面结合附图对本发明作进一步详细说明。
如图1所示,本发明提供一种金融文本主观句自动识别方法,包括以下步骤:
(1)主观模式提取,具体包括以下子步骤:
(1.1)依次读取金融文本语料库corp的每个文本di;
(1.2)读取停用词典,删除文本di中所有停用词;
(1.3)读取金融词汇本体,对文本di进行分词,生成分词文件pi=<w1,w2,…,wn>;
(1.4)对分词文件pi标注词性,得到词性标注文件p'i=<a1,a2,…,an>;
(1.5)初始化序列集合
(1.6)初始化双词性组合模式集合
(1.7)初始化双词主观模式集合
其中,n表示语料库的句子总数,cj为主客观类别,a表示属于cj类包含ai的句子频数,b表示不属于cj类包含ai的句子频数,c表示属于cj类不包含ai的句子频数,d表示不属于cj类不包含ai的句子频数;
阈值σ根据应用场景来调节,σ取值越大a'i的主观性越强;
(1.8)根据公式(2)依次计算每个双词主观模式a'i在语料库corp中的查准率
其中,s(a′i)为与a'i主客观性一致的句子总数;
(1.9)计算主观模式集合sp中所有模式的主观性权重平均值
(2)文本主观度计算,具体包括以下子步骤:
(2.1)对于新的金融文本d,根据步骤(1.2)~(1.4)对d分词并标注词性;
(2.2)对于文本d的每个句子si,提取其全部相邻词的词性组合<w1,w2,…,wn>,建立句子si的双词语言模型;
(2.3)初始化句子si的主观模式分值sp_scorei=0,对于si的每个双词性组合项wj,若属于双词主观模式集合sp,则将该模式的主观性权重加到整个句子的主观模式分值sp_scorei;
(2.4)统计句子si的双词性组合数目ni,根据公式(3)计算其主观度分值subi;
(2.5)若subi大于主观度阈值δ,则判定si为主观句并输出。
本发明针对金融文本主观性语句自动识别任务,提出了一种金融文本主观句自动识别方法,可在自动化决策系统中发挥重要作用,例如对大类资产配置等应用提供重要的参考依据,对智能投顾等金融科技领域具有重要的价值。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!