基于密集卷积和深度可分离卷积的视网膜血管分割方法与流程
本发明涉及医学图像处理领域,特别是涉及基于密集卷积和深度可分离卷积的视网膜血管分割方法。
背景技术:
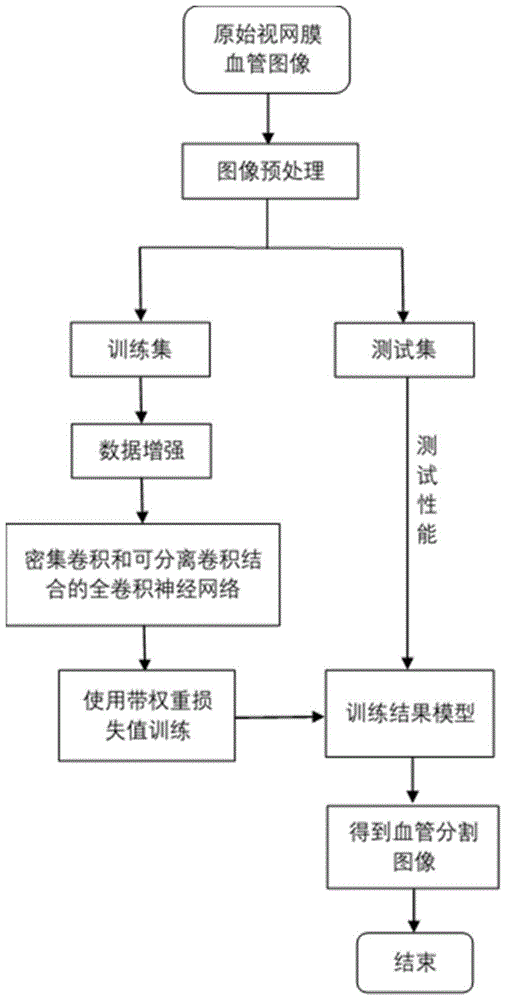
:在视网膜眼底图像中,血管呈树状网络结构布满整个眼底图像,是眼底图像中可观察的最重要的结构。视网膜眼底图像是判断眼部疾病的重要依据,同时也对糖尿病、高血压、动脉硬化等疾病的诊断具有重要作用。手动分割视网膜血管是一项非常繁琐的任务,并需要经验和技巧。基于计算机自动提取分割视网膜血管的辅助诊断系统,在医学诊断中有着重要的应用价值。根据分割时是否使用标准图像特工的特征数据,现有的视网膜血管分割方法主要分为两大类:无监督分割方法和有监督分割方法。无监督分割方法不需要先验标记信息,包括基于模型方法、血管追踪方法、匹配滤波方法等。基于模型的血管分割方法主要依据眼底图像中血管的灰度变化。对于图像中亮的或者暗的病变以及血管分支点和交叉点等其他组织则需要建立更加复杂的模型。基于血管追踪分割方法首先确定初始点,然后通过血管中心线跟踪血管。这种方法计算量大,并且依赖于初始点和方向的选择,并且无法有效分割血管的分支点和低对比度血管。匹配滤波器的方法时将滤波器和图像进行卷积来提取目标,该方法对于病理图片分割效果,假阳性率偏大。有监督分割方法主要是基于提取的特征训练分类器,达到血管与非血管分类的目的。ricci等采用线操作结合支持向量机完成对样本的学习,特征提取简单,所需样本较少。marin等提出基于神经网络的视网膜血管检测方法,首先预处理原始图像,使其灰度均匀且血管增强,并利用多层前馈神经网络进行训练和分类。该神经网络可以只在一个数据库上训练却在多个数据库上得到很好的血管分割结果。wang等提出一种分层次的视网膜血管分割方法,该方法首先对图片的绿色通道进行直方图均衡化和高斯滤波,接着用简单的线性迭代聚类方法进行超像素分割,再从每个超像素中随机选中一个像素点代表整个超像素作为样本特征提取,最后用卷积神经网络完成层次特征提取并用随机森林进行分类。这些有监督分割方法的结果取决于手动特征选取的好坏,并需要大量预先分割好的视网膜血管图像进行训练来保证模型的准确率,对医学图像要求较高。近年来,深度学习的方法取得了重大进展。卷积神经网络可以通过网络层数的增加学习到图片的深层特征。fu等提出将卷积神经网络与条件随机场结合进行视网膜图像分割。其将血管分割作为边界检测问题处理,利用卷积神经网络产生分割概率图,再用条件随机场得到二值分割结果。但目前语义分割效果最好的方法都基于全卷积神经网络。dasgupta等人提出将完全卷积网络(fcn)用于视网膜图像分割血管。但是,fcn只是通过单一的双线性插值来执行反卷积操作,在一定程度上损失了图片精度,使其难以准确重建血管边界的高度非线性结构。现有的视网膜血管分割方法中,深度学习相比于传统方法有一定程度的提高,但血管不明显的区域或血管过于精细的部分分割结果还不是特别准确,不利于辅助医生的准确诊断。技术实现要素:为了解决以上问题,本发明提供基于密集卷积和深度可分离卷积的视网膜血管分割方法,该方法结合了密集卷积和深度可分离卷积,使其可以充分融合浅层特征信息和深层特征信息,提高分割准确率,并且大大减少网络参数,减少训练时间,为达此目的,本发明提供基于密集卷积和深度可分离卷积的视网膜血管分割方法,包含以下步骤:步骤1:对原始视网膜血管图像进行数据预处理:提取对比明显的绿色通道,限制对比度、直方图均衡化,并对其进行锐化操作;步骤2:对上一步处理结果进行进一步的局部自适应伽马矫正;步骤3:对训练集进行数据增强,并分组;步骤4:以编码-解码结构的对称全卷积网络作为主干网络,构建基于密集卷积与深度可分离卷积结合的全卷积网络模型;步骤5:构建自定义权重的损失函数用于训练;步骤6:使用增强过的训练集作为网络的输入,使用步骤5的损失函数对步骤4构建的全卷积网络进行训练;步骤7:采用训练好的网络模型对测试集进行分割,并生成最终视网膜血管分割图像。本发明的进一步改进,所述步骤1中的数据预处理,根据视网膜血管图像特点,选取对比度较明显的绿色通道;对绿色通道限制图像对比度,直方图均衡化。本发明的进一步改进,所述步骤2中的局部自适应伽马矫正,首先对整张图像进行一个相对较大的伽马值进行矫正,提高整幅图像的对比度,再对局部进行小值的伽马矫正,减小非特征部分的噪声。本发明的进一步改进,所述步骤3中对训练集图像进行数据增强,首先将训练集的图片和标签在通道维度相加,使其可以同步实现相同的平移,旋转和翻转等变换,保存并分组,然后对增强过后的图片通道分离,分别保存图片和对应标签,实现对数量较小的数据集扩充。本发明的进一步改进,所述步骤4中以编码-解码的对称全卷积网络作为主干网络,使得到的视网膜血管分割图像和输入图像大小相同,该网络结构一共有九个模块,前四个为编码模块,第五个是过渡模块,第六到第九为译码模块,第一个编码块为深度可分离卷积块,对输入图片进行两次深度可分离卷积,将结果保留,之后进行一次最大池化。本发明的进一步改进,所述步骤4中第二个编码块到第四个编码块为密集卷积块,在每个密集卷积块内进行密集卷积层数次瓶颈层运算并把每次结果直接在通道相连,在每一个密集卷积块后,对通道数进行一半的降维,将结果保留,之后进行一次最大池化,假设在瓶颈层中,每次输出的通道数目为k,k为密集卷积块的增长率,那么第i层网络的输入通道数目为k0+(i-1)×k。本方法的增长率设为k=32,第二到第四个卷积块的密集卷积层数分别为6,12,24。其中的瓶颈层包含一次1*1,深度为4倍增长率的卷积、一次3*3,深度为1倍增长率的卷积、每个卷积前一次批量标准化以防止训练过拟合,和进行一个relu激活函数,用于实现数据的非线性变换。本发明的进一步改进,所述步骤4中,过渡模块进行了两次深度可分离卷积,一次反卷积上采样,将结果保留。本发明的进一步改进,每个译码块通过反卷积对图像进行上采样,并进行两次卷积对通道数进行降维、提取特征,4次译码后使图像变回原图像大小,第四个编码块保留的结果连接到过渡模块保留的结果作为第一个译码块的输入,第一个译码块结果保留,连接到第三个编码块保留的结果作为第二个译码块的输入,第二个译码块结果保留,连接到第二个编码块保留的结果作为第三个译码块的输入,第三个译码块的结果保留,连接到第一个编码块保留的结果作为第四个译码块的输入。本发明的进一步改进,步骤5中对损失函数自定义权重进行训练;α—γ损失函数其中,n为像素个数,为标签,yi为预测值,α为权重系数,γ为指数系数,权重系数α用来解决类别不平衡问题,指数系数γ用来解决难区分样本问题;对于每个像素点i:由于目标点(的点)的数量远小于背景点(的点)的数量,引入权重系数α,在这里,本方法取α=0.8,使目标点相比背景点,对损失函数有更大的贡献,这弥补了目标点过少的不足,有利于更好地训练目标点;指数系数γ的引入是为了更好的训练难以区分的像素点,本方法取γ=2,对于目标点,y=0.9时(1-y)γ的值,要比y=0.6时(1-y)γ值要小得多;对于背景点,1-y=0.9时yγ的值,要比1-y=0.6时yγ的值要小得多,因此α—γ损失函数对于预测值在0.5左右的像素点更敏感;视网膜血管图片中的待分割区域只有血管,其目标点的数量远小于背景点的数量,引入权重系数可以使目标点对损失函数有更大的贡献,弥补了目标点过少的不足,有利于更好地训练目标点。本发明针对视网膜血管分割提出了一种新型深度神经网络结构,具有以下的优点和效果:1、本发明进行的图像预处理操作,大大提升了原视网膜图像中血管的清晰度和对比度,减少了网络在提取特征时一些不必要的难度,同时提高了网络学习模型的精确度。2、本发明提出的密集卷积和深度卷积结合的神经网络结构,复用了每层的特征信息,缩短了前后层之间的距离,加强了特征传播的能力,有效减少过拟合的问题。同时减少了网络参数,提高网络的训练效率。在drive数据集上可达到:准确率96.83%,精确率87.02%,灵敏度73.71%,特异度98.95%。附图说明图1是本发明的实现流程框图;图2密集卷积中瓶颈层结构示意图;图3是密集卷积块结构示意图;图4是本发明算法网络框图;图5是数据集原图、预处理结果对比图;图6是本发明实现视网膜血管分割的结果图:图(a)是视网膜眼底原图像,图(b)是手动分割标签,图(c)是本发明分割结果。具体实施方式下面结合附图与具体实施方式对本发明作进一步详细描述:本发明提供基于密集卷积和深度可分离卷积的视网膜血管分割方法,该方法结合了密集卷积和深度可分离卷积,使其可以充分融合浅层特征信息和深层特征信息,提高分割准确率,并且大大减少网络参数,减少训练时间。本发明的实现流程图如图1所示。本发明使用的原始视网膜血管图像是drive(digitalretinalimageforvesselextraction)公开数据集,该数据集中共有40张视网膜眼底图像,分为训练集和测试集,各有20张图片。在训练集中,每张视网膜图像都有一张对应的专家手动分割图。将专家分割结果作为训练数据的标签用于网络模型的训练。测试集中的每张视网膜原始图像有两个专家对应的手动分割图,在测试过程中,将第一个专家的分割结果作为真值来评估本发明所提出模型的分割性能,将得到的各种指标值和第二个专家的分割结果进行对比,以此来验证本发明中模型的性能和人类手动分割效果的优劣。具体实施步骤分别如下:1.对图片进行预处理由于训练集和测试集中的原始视网膜图片都是彩色图像,并且背景与血管目标的分辨度不高,所以需要对原始图像进行一些预处理,使其适合后续网络模型的输入。首先,提取分辨率较高的图片的绿色通道。然后将绿色通道的单通道灰度图进行限制对比度直方图均衡化(clahe)。再对处理过的图片进行锐化操作,抑制clahe增强后图像的伪影与黄斑等噪声信息,凸显血管信息。利用局部自适应伽马矫正,首先对全局进行一个稍大的伽马值调节图片对比度,再根据血管和背景的不同像素特征进行伽马值匹配,将视网膜图像分区域进行矫正。2.对经过预处理的训练集图片进行数据增强因为drive数据集中只有20张用来训练的图片,对于神经网络来说数量较少。进行数据增强时,首先,将图片与对应标签在通道数相加得到一张混合图片,使图片和对应标签可以同时进行数据增强的平移、旋转、翻转等变换,使得每张图片扩展70张,得到1400张图片。然后将1200张图片用于训练,200张用于验证。最后把每张混合图片按照对应的通道,分解成一一对应的输入图片和输入标签。3.构建密集卷积和可分离卷积结合的全卷积神经网络本发明的网络框架如附图4所示,由4个编码块,1个过渡块和4个译码块组成。其特征、作用、内部运算以及每层输出图片的尺寸在表格1中呈现。表格1:本发明网络结构各层信息第一个编码块由两层深度可分离卷积和一个最大池化层构成。深度可分离卷积将标准卷积分解为深度卷积和逐点卷积。标准卷积的卷积核尺寸为:df×df×m,共又n个,输出尺寸为df×df×n:其计算量为:cost1=dk×dk×m×df×df×n。深度可分离卷积的深度卷积的卷积核尺寸为:dk×dk×1,共有m个。深度可分离卷积的逐点卷积的卷积核尺寸,为:1×1×m,共有n个。深度可分离卷积的计算量为:cost2=dk×dk×m×df×df+m×df×df×n。同样效果的深度卷积与标准卷积的计算量相比:使用深度可分离卷积可以大大减少网络的参数量。减少训练和预测时间。两次深度可分离卷积运算之后将结果保留,进行最大池化运算,使图片尺寸减半。第二个到第四个编码块由密集卷积块组成。密集卷积块结构如附图3。密集卷积:xl=hl([x0,x1,...,xl-1]),其中,xl是第l个卷积层的输出,hi(·)是第l个卷积层的非线性运算,[x0,x1,...,xl-1]是第0,1,…,l-1个卷积层输出的拼接。hi(·)包含3中操作:批标准化,修正先行单元,3*3卷积。假设在denseblock中,每一个非线性变换hi(·)的输出为k个featuremap。设k为denseblock的growthrate。那么第i层网络的输入为k0+(i-1)×k个featuremap。其中k0为输入denseblock的featuremap的个数。密集卷积块通过瓶颈层进行一系列的卷积操作。附图2是其结构示意图。本发明中选择增长率为32。则该过程首先将其输入进行一次批标准化,relu激活,然后经过一次1×1×128(增长率×4)尺寸的卷积层,再经过一次批标准化,relu激活,经过一次3×3×32(增长率)尺寸的卷积层,最后将卷积结果和输入进行通道拼接。每个密集卷积块进行l次的瓶颈层操作之后,再进行1次通道降维,将其数量减半。运算结果保留,进行最大池化运算,使图片尺寸减半。第二个到第四个编码块的l分别为6,12,24。每一个密集卷积块中将每一个瓶颈层的卷积结果在通道拼接,作为下一次卷积的输入,使得网络特征被重复利用,不仅缩短了前后层之间的距离,还加强了特征传播的能力。在不增加网络深度的情况下,得到了更深层的特征信息。表格2显示了本发明与同框架普通卷积网络编码块参数量对比。同框架普通卷积网络是指每个编码块使用两个3×3尺寸的普通卷积核,和本发明在过渡块输出同样尺寸的特征图。表格2中的结果显示了本发明在编码块的参数量比普通卷积网络编码块参数量减少了近一半。但分割精度依然有所提升。表格2:本发明与同框架普通卷积网络编码块参数量对比同框架普通卷积网络编码块参数量本发明编码块参数量编码块19.8×1091.2×109编码块214.5×10919.0×109编码块314.5×10911.2×109编码块414.5×1097.2×109过渡块14.5×1091.6×109总计67.8×10940.2×109在过渡块中,经过两次深度可分离卷积,图片尺寸缩小到了输入时的1/16,通道数达到了1024。之后,经过一次反卷积运算,使图片增大一倍,为输入图片大小的1/8。将其与第四编码块结果拼接,作为第一个译码块的输入,进行两次卷积提取特征,一次反卷积,增加一倍图片尺寸。将其与第三编码块结果拼接,作为第二个译码块的输入,进行两次卷积提取特征,一次反卷积,增加一倍图片尺寸。将其与第二编码块结果拼接,作为第三个译码块的输入,进行两次卷积提取特征,一次反卷积,增加一倍图片尺寸。将其与第一编码块结果拼接,作为第四个译码块的输入,进行两次卷积提取特征,达到输入图像尺寸。4.构建带有权重的损失函数α—γ损失函数其中,n为像素个数,为标签,yi为预测值,α为权重系数,γ为指数系数,权重系数α用来解决类别不平衡问题,指数系数γ用来解决难区分样本问题;对于每个像素点i:由于目标点(的点)的数量远小于背景点(的点)的数量,引入权重系数α,在这里,本方法取α=0.8,使目标点相比背景点,对损失函数有更大的贡献,这弥补了目标点过少的不足,有利于更好地训练目标点;指数系数γ的引入是为了更好的训练难以区分的像素点,本方法取γ=2,对于目标点,y=0.9时(1-y)γ的值,要比y=0.6时(1-y)γ值要小得多;对于背景点,1-y=0.9时yγ的值,要比1-y=0.6时yγ的值要小得多,因此α—γ损失函数对于预测值在0.5左右的像素点更敏感;视网膜血管图片中的待分割区域只有血管,其目标点的数量远小于背景点的数量。引入权重系数可以使目标点对损失函数有更大的贡献,弥补了目标点过少的不足,有利于更好地训练目标点。5.训练结果模型本发明将准确率、精确率、灵敏度和特异度作为方法的判别标准。表格1是混淆矩阵。表格1:混淆矩阵准确率是分类模型所有判断正确的结果站总观测值的比重,灵敏度(召回率)是在真实值是目标的所有结果中,模型预测对的比重,特异度是在真实值不是目标的所有结果中,模型预测对的比重,本发明使用adam优化器,学习率为1e-4,在训练集上训练了4次。达到了准确率96.83%,灵敏度73.71%,特异度98.95%。6.测试网络模型将预处理过的测试图片和标签输入网络模型,直接得到每张图片的预测图以及准确率等判别结果。以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1