一种实现低资源消耗卷积器的方法与流程
本发明涉及深度学习技术领域,更具体的,涉及一种基于fpga(fieldprogrammablegatearray)的实现低资源消耗卷积器的方法。
背景技术:
深度卷积神经网络广泛用于计算机视觉、图像分类、物体识别等领域,但是训练网络所需庞大的数据集和复杂的计算过程,限制了网络部署的平台,特别是在低功耗,计算资源有限等平台,尤其是移动设备和嵌入式设备等。将深度卷积神经网络从服务器集群迁移到移动平台中执行,是目前的研究热点和大趋势。
在卷积神经网络中,卷积层的计算量占据总体计算量90%以上,因此,卷积层运算的加速是卷积神经网络加速的重要组成部分。通用处理器cpu和gpu等在执行通用的处理任务时具有很高的性能表现,但是卷积神经网络的计算包含大量并行的非线性函数运算,向量运算和卷积运算,而通用处理器的硬件结构并不是一种高并行度的结构,缺乏对这类运算的加速能力,因此,通用处理器执行卷积神经网络的性能不尽如人意。所以,卷积神经网络的加速器必须要能够实现以下两个功能:(1)充分利用卷积神经网络中层与层之间,层内各个卷积器的并行度;(2)定制化的计算模块——卷积运算模块。
fpga是一种可编程逻辑器件,随着半导体技术的不断升级和发展,现在主流的fpga包含了丰富的逻辑计算,存储和布线资源,可以让研究人员有足够的设计空间来定制专用卷积神经网络加速硬件结构,并且充分利用卷积神经网络计算的并行特性。
目前大多数研究的主要内容都是设计一个合适计算框架来对卷积神经网络进行加速,常见的框架有dataflow、simd和simt等等。研究的重点在于数据和计算单元——卷积运算核的配合,而非对卷积运算核的优化,大部分的研究都是通过调用fpga内部的dsp单元来实现卷积运算,或者进一步搭建树状的卷积运算核来减少计算延时,这类卷积运算核包含了通用的乘法器,然而,卷积器的权重值在整个卷积过程都是固定的,因此,在卷积运算核中使用通用乘法器会导致不必要的资源开销,消耗较大的计算机资源而且效率低下。
技术实现要素:
为了解决现有的深度卷积神经网络技术在进行网络训练时需要消耗较大计算机资源的不足,本发明提供了一种基于fpga的实现低资源(lut6资源)消耗卷积器的方法。
为实现以上发明目的,采用的技术方案是:
一种实现低资源消耗卷积器的方法,包括以下步骤:
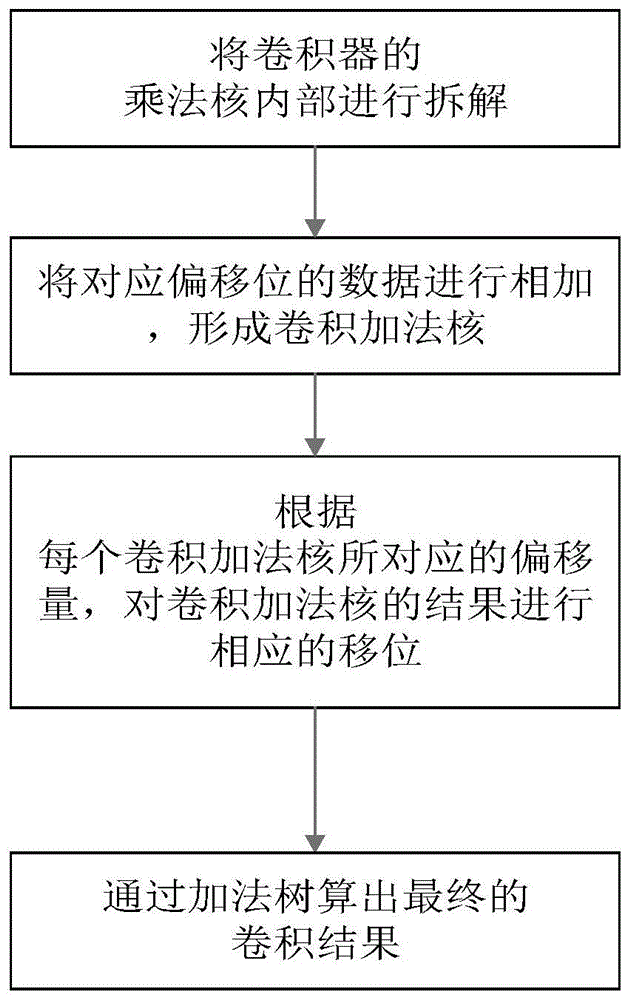
将卷积器的乘法核内部进行拆解,将乘法核内部具有相同偏移量的数据进行相加,形成卷积加法核;根据每个卷积加法核所对应的偏移量,对卷积加法核的结果进行相应的移位,并通过加法树算出最终的卷积结果。
优选的,所述的方法在fpga的基础单元lut6中实现。
优选的,在fpga的基础单元lut6中,对于n个mbit数据与n个mbit数据的卷积器,将卷积器n个乘法核内部进行拆解,将n个乘法核内部具有相同偏移量的n个mbit数据进行相加,形成m个卷积加法核。
优选的,所述的m个卷积加法核的每个加法核输出一个最终的加法结果。
优选的,m个卷积加法核的每个加法核的计算结果,都应进行一个额外的移位操作,移位操作的偏移量由其操作数的原本偏移量决定。
优选的,所述的m个卷积加法核的每个加法核通过一个完全二叉树固定。
与现有技术相比,本发明的有益效果是:
1.在fpga上部署相比传统方法更省lut资源,本发明计算了最大的是m个n操作数的加法核,通过本发明的结构,在最耗lut6资源的加法核中并没有移位操作,用的是原始的m比特数据进行运算。相比传统方法中在计算量最大的乘法核中进行大位数的操作数计算,本发明能节省部分fpga中的lut6的算资源。
2.本发明在卷积神经网络的fpga实现中,具有更易部署,易重用的优点。
本发明的提出是源于神经网络的fpga实现,本发明的卷积结构是固定的,加法核通过一个完全二叉树固定,因此在后续的矩阵变换都不需要进行调整,只需要更换成对应的卷积加法核即可,相比大框架重新部署,大大的提高了效率。
附图说明
图1为本发明的流程图。
图2为实施例2的卷积器结构示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
如图1所示,一种实现低资源消耗卷积器的方法,包括以下步骤:
将卷积器的乘法核内部进行拆解,将乘法核内部具有相同偏移量的数据进行相加,形成卷积加法核;根据每个卷积加法核所对应的偏移量,对卷积加法核的结果进行相应的移位,并通过加法树算出最终的卷积结果。
作为一个优选的实施例,所述的方法在fpga的基础单元lut6中实现。
作为一个优选的实施例,在fpga的基础单元lut6中,对于n个mbit数据与n个mbit数据的卷积器,将卷积器n个乘法核内部进行拆解,将n个乘法核内部具有相同偏移量的n个mbit数据进行相加,形成m个卷积加法核。
作为一个优选的实施例,所述的m个卷积加法核的每个加法核输出一个最终的加法结果,位数会比操作数的m比特大。
作为一个优选的实施例,m个卷积加法核的每个加法核的计算结果,都应进行一个额外的移位操作,移位操作的偏移量由其操作数的原本偏移量决定。
作为一个优选的实施例,所述的m个卷积加法核的每个加法核通过一个完全二叉树固定。
实施例2
本实施例选取5个8bit数据与5个8bit数据的卷积器。
具体的实现步骤如图2所示。标识e所标注的部分为特殊的卷积加法核,其操作数都为c所标注的数据。即这个特殊的加法核,其操作数是取自传统的乘法核里面具有相同偏移位置的5个数据,并且输入这个加法核的数据是不进行移位操作的,只取了最原始的8比特数据。
上述的特殊的卷积加法核中,进行了5个8比特数据的全加操作。每个加法核输出一个最终的加法结果,位数为11bit。每个加法核都是将拥有相同偏移量的8比特数据进行相加,可以得出,对于每个加法核的计算结果,都应进行一个额外的移位操作,偏移量由其操作数的原本的偏移量决定(0~8-1),如图2标注d所示的数据,即为加法核对应的偏移量。最后,将这8个数据进行相加,得到最终的结果。
传统乘法器结构的卷积器在fpga中进行硬件实现的rtl示意图及资源消耗如表格1所示。
表格1传统乘法器结构卷积器资源消耗统计。
在传统乘法器结构的卷积器中,5对数据(10个8bit数据)分别输入乘法器模块中,乘法结果输出传进加法器组成的加法树中,经过3层加法树计算最终得到卷积结果。表格1列出了单个乘法器核消耗的资源数及总消耗资源数(相应的加法树消耗的资源可以从表中算出),本发明的卷积器在fpga中进行硬件实现的rtl示意图及资源消耗如表格2所示。
表格2本发明卷积器资源消耗统计
而在基于本发明的卷积器中,5对数据(10个8bit数据),每队数据中,第一个数被第二个数的每一比特选通一次,将5对数据中相应比特位选通的数据汇总成组(一共8组)一起传入本发明声明的特殊加法核中,产生8个输出,并最终通过加法树累加到一起得出卷积结果。表格2列出了单个特殊加法核消耗的资源数及总消耗资源数(相应加法树消耗的资源可以从表中算出)
可见,实际应用中,本发明能比传统方法节省约16%的硬件资源。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!