一种面向数据库的GPU和CPU异构加速方法与流程
本发明涉及计算机领域中的数据库执行技术领域,具体地,涉及一种面向数据库的gpu和cpu异构加速方法。
背景技术:
现有的数据库执行方法大多是基于cpu的,然而现代化的硬件设备越来越多样化。今天,单个机器可以包含几个不同的并行处理器,如多核cpu或gpu。这种多样性预计在未来几年将进一步增长,使数据库引擎准备好利用这种多样化的并行处理平台的能力将是未来数据库的主要挑战之一。显然单纯使用cpu以无法充分利用已有的计算器资源。
近年特别是对图形处理单元gpu的利用逐渐广泛。然而,目前的方法将gpu本身视为系统,未能为高效的cpu和gpu异构协作加速数据库提供通用方法由于其并行计算能力强大,gpu已被用于加速数据库。现行的主要方法是在gpu上有效实现经典关系运算符,以及在运行时选择gpu或cpu运算符。通常,gpu运算符通过缓慢的pci-e总线传输其输入、处理它们、传输结果并可能缓存数据以供以后重用。虽然供应商简化了cpu和gpu通过"统一虚拟寻址"进行的传输,但对于pci-e瓶颈,几乎无能为力。因此,只有在数据集大小适合gpu显存的情况下,此类方法才能获得良好的性能,但这通常不是常见情况。所以现行的gpu加速数据库的方法所发挥的gpu算力有限。
技术实现要素:
本发明目的在于充分利用gpu对数据库执行器进行加速,并克服由于总线传输带宽和gpu显存有限导而致对gpu性能限制问题,提供一种有效的gpu加速数据库方法。
为实现上述发明目的,本申请提供了一种面向数据库的gpu和cpu异构加速方法,所述方法包括:
当数据库需要对预设数据进行处理时,对预设数据进行位域切割处理,将预设数据切割为第一部分数据和第二部分数据,将第一部分数据传输给数据库中的gpu处理器进行处理,将第二部分数据传输给数据库中的cpu处理器进行处理;
对于数据库中的同一个数据库算子,将该数据库算子分成gpu近似计算算子和cpu精确计算算子两种;将数据库需要处理的预设数据首先通过gpu近似计算算子进行筛选,对于筛选后的数据,使用cpu精确计算算子进行计算得到计算结果。
优选的,对预设数据进行位域切割处理时,首先需要判断预设数据的类型,并根据预设数据的类型分别采用对应的切割方式对数据进行切割处理。
优选的,当预设数据为unsignedchar类型时,去除预设数据中的前面若干符号位为0的数据,获得剩下的nbit数据;对剩下的nbit数据进行均分,gpu处理器处理其中
优选的,当预设数据为int型数据,对预设数据的正负进行判断,当预设数据为正数时,去除预设数据中符号位为0的部分数据,并将剩下位数据均分为两份数据发送给gpu处理器和cpu处理器,在gpu处理器对应份数据bit前加上1bit用作符号位0,0表示正,1表示负;当预设数据为负数时,将预设数据转换成正数,并去除预设数据中符号位为0的部分数据,并将剩下位数据均分为两份数据发送给gpu处理器和cpu处理器,并在gpu处理器对应份数据前增添1bit用作符号位,符号位为1,表示负,符号位为0,表示正。
优选的,当预设数据为浮点型数据,切割位数应该大于等于指数,如果等于指数,意味着gpu处理浮点数的整数部分,cpu处理小数部分。如果大于指数,意味着gpu处理浮点数的整数和部分小数,cpu处理剩下的小数部分。切割的位数即是gpu和cpu处理位数的分界点,指数是指浮点数据中本身的概念,类似于科学计数法中的指数。浮点数的存储方式就是第一位表示符号位,之后8位为指数,余下的为基数。
优选的,对于数据库中的fliter算子,则先使用gpu处理器控制数据中的高位得到gpu近似计算算子筛选的结果,再使用cpu精确计算算子得到计算结果,cpu处理器控制低位。gpu处理器控制高位(为一个存储数据偏左边的数,比如说十进制数12,1为高位,2为低位。对于二进制数一样,1001,左边的10是高位,右边的01是低位),再使用cpu精确计算算子得到计算结果,cpu处理器控制低位。比如要筛选仅有3bit表示的数中大于等于5的数据,5用二进制表示就是101,假设通过要求9的切割策略得到gpu处理两位,cpu处理一位,那么在gpu中就只处理前两位,那么前两位为00和01的数据必然不可能大于5,直接过滤掉,而前两位为11的数据必然大于5,只有前两位为10的数据才需要进一步交由cpu细化比较,若最后一位是0,有cpu过滤掉,是1则通过。
优选的,对于数据库中的group算子,若需要对预设数据进行处理时,先使用gpu近似计算group算子对高位(为一个存储数据偏左边的数,比如说十进制数12,1为高位,2为低位。对于二进制数一样,1001,左边的10是高位,右边的01是低位)进行分组,获得预设数据的分组结果;使用cpu精确计算group算子按照低位(为一个存储数据偏右边的数)对分组后的数据继续进行细化分组。
优选的,对于数据库中的对于join算子,若需要对预设数据进行处理时,hash表使用一种双层机制,第一次hash时使用gpu近似计算join算子处理部分bit,将其散列到第一层的hash桶中;在每个第一层hash桶中,进行第二次细化hash,第二次hash时使用cpu精确计算join算子处理剩余部分bit,映射到第二层hash桶中;当两次hash均命中数据库中的缓存数据时,则认为hash均命中数据库中的缓存数据。
优选的,当数据库需要对预设数据进行处理时,对预设数据进行位域切割处理,根据预设数据的类型、数据所表示的值域范围值域、算子类型、cpu处理器数量、gpu处理器数量、显卡的显存大小,使用最小二乘法、决策树、启发算法、强化学习来确定位域的切割点。具体的切割策略本质上是一种优化方法,可以使用强化学习算法进行优化。现将前面的各种变量量化、归一化、再使用无监督的强化学习算法得到较好的切割策略。根据切割策略最后得到运行时间,运行时间短是一个正向激励,运行时间长是一个负向激励,运行时间作为一个reward来反馈到算法模型中,根据强化学习算法理论,reward会自动对算法模型进行调优,得到一个稳定的优化结果,也就是我们的切割策略。
本申请提供的一个或多个技术方案,至少具有如下技术效果或优点:
本发明克服了前述的现有技术仅仅使用cpu来执行数据库算子的局限性,引入gpu来大大加速数据库执行的效率。
并提出了基于位域切割的办法来缓解gpu显存有限以及总线带宽有限的问题,提出了位域切割的指导思想,并提供了几种具体得出位域切割点的思路,提出了配套的逻辑计划优化策略的指导思想,进一步提高了数据库执行效率。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定;
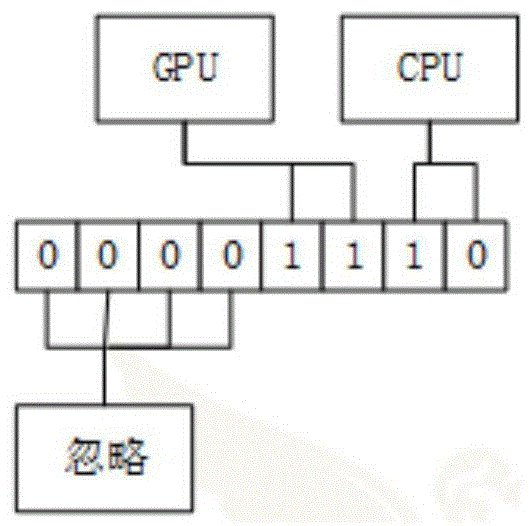
图1是本申请中unsignedchar类型数据的位域切割示意图;
图2是本申请中使用gpu近似计算算子和cpu精确计算算子进行筛选和精确计的示意图;
图3是本申请中sql执行计划示意图;
图4是本申请中使用gpu近似算子和cpu精确算子后的执行计划示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
本方法使用位域切割解决总线和显存瓶颈,提高gpu利用率。gpu近似计算不使用所有的数据位,仅仅使用局部位,如图1所示。以一个unsignedchar类型为例,其他数值类型使用类似的方法。忽略前面无用的4个0,在剩下的4bit数据中,如果采用cpu、gpu均分的方法,gpu处理其中较高的2bit,cpu处理较低的2bit。这意味着原本需要通过总线传递给gpu8bit,现在只需要传递给gpu2bit,极大地减轻了总线压力,也意味着每次gpu并行计算可以装载更多的数据,过滤更多数据。
a)如果是一个int型数据,我们需要区分其正负,对于正数,要消除前面无用的0,对于负数,消除前面无用的1。具体做法如下:a、对于正数,先去除无效的0,剩下位均分给gpu和cpu,最后在gpu的那一份bit前加上1bit用作符号位0,0表示正,1表示负。b、对于负数,先转换成正数,再去除无效的0,剩下位均分给gpu和cpu,再在gpu的那部分数据前增添1bit用作符号位,符号位为1,表示负。
b)如果是一个浮点型数据,切割位数应该大于等于指数,如果等于指数,意味着gpu处理浮点数的整数部分,cpu处理小数部分。如果大于指数,意味着gpu处理浮点数的整数和部分小数,cpu处理剩下的小数部分。
本方法对于同一个数据库算子,分成gpu近似计算算子和cpu精确计算算子两种。先将海量数据通过gpu进行快速筛选,之后再将结果通过cpu进行精确计算,得到正确的结果。如图2所示。
a)对于一个fliter算子,要选出小于2的所有数据,先使用gpu选出所有小于4的数据,gpu控制1位再使用cpu得到精确结果,cpu控制最后两位。
b)对于一个group算子,先使用gpu近似group算子对高位进行分组,此时同一组里面可能还能继续分组,但不同组之间必然不会有相同的组,再使用cpu精确group算子按照低位对gpu分好的组继续进行分组细化。
c)对于join算子。主要考虑hashjoin的情况,hash表使用一种双层机制,第一次hash使用gpu部分bit,在每个hash桶中,进行第二次hash,第二次hash使用cpu部分的bit。只有两级hash都命中才命中。使用gpu近似join算子进行第一级hash,命中的数据反馈给cpu精确join算子进行精确匹配。
本方法使用位域切割策略。通常情况下的切割方案是先去除前面无效的0,在剩下的bit中平分给gpu和cpu。但是这通常不是最优的切割方案,gpu算子处理的位数越多,结果越精确,但是对总线压力更大,效率更低。gpu算子处理的位数越少,结果越模糊,但是速度越快。最优的位域切割点取决于:要处理的数据类型、值域、算子类型、cpu数量、gpu数量、显存大小、总线速率……可以使用最小二乘法、决策树、启发算法、强化学习等更好地来确定位域的切割点。
本方法采用基于异构算子逻辑计划优化策略。算子改变势必会导致逻辑计划的改变,gpu近似算子会往下沉,而cpu精确算子往上提。通过这种逻辑计划优化方案在gpu中过快速滤掉绝大部分数据。
如:sql语句:
selectt1,t2,sum(t2.c3)
fromt1,t2
wheret1.c2=t2.c2
groupbyt1.c2
havingsun(t2.c3)>=10;
步骤一:对sql语句进行词法分析、语法分析……生成执行计划,如图3所示。
步骤二:扫描执行计划,对可以优化的算子修改成先使用gpu近似算子,再使用cpu精确算子。得到新的执行计划如图4所示。可以看到gpu近似算子总是在cpu精确算子下面,因为我们期望通过gpu过滤掉绝大部分数据。需要说明的是cpu和gpu并不是串行工作的,图4只是未分裂执行计划,通过执行计划分裂,cpu和gpu都是并行工作的。
步骤三:按照新的执行计划分配算子,进行执行。具体执行步骤如下:
a、两个scan算子分别对t1和t2两张表进行扫表。得到的数据进行位切割,将gpu处理的位数发送给gpu,完整数据发送给cpu;
b、gpujoin按照本发明方法进行一级hash,筛去不符合条件的数据,将符合条件的数据发送给下一级的cpujoin算子;
c、cpujoin进行精确hash,得到正确的结果后传给下一个算子。将数据进行位切割,将gpu处理的数据发送给gpugroup算子,完整数据发送给cpugroup;
d、gpugroup算子按照本发明的方法进行初步分组,结果发送给cpugroup算子;
e、cpugroup算子进行精确的分组,结果发送给下一个fliter算子;数据进行位切割,gpu处理的数据发送给gpu算子,完整数据发送给cpu算子;
f、gpufliter按照本发明的方法进行初步过滤,符合条件的数据发送给cpufliter进行精确筛选;
g、cpufliter进行精确筛选后得到正确结果;
h、project算子将结果显示出来。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!