用于正则化神经网络的系统和方法与流程
本申请要求美国临时专利申请号62/660,617的优先权,该临时专利申请通过引用整体并入本文。
技术领域
本公开通常涉及机器学习。更具体地,本公开涉及通过在神经网络的训练期间解相关(decorrelate)神经网络的神经元和/或其他组件或参数来正则化神经网络的系统和方法。
背景技术:
神经网络在大数据预测方面已经提供了巨大突破,以及改善了机器学习的预测准确度和能力。然而,由于神经网络为了实现这样的性能而试图学习的非常大量的参数,因此它们可能显著地过度拟合训练数据,潜在地引起对训练期间未观察到的数据的不良泛化。
神经网络还遭受训练中潜在的不稳定性和不可再现性。对于不可再现性,例如,有可能在相同的数据上两次独立训练相同的网络结构仍然可以得到两个非常不同的神经网络,并且有可能对训练期间未观察到的数据产生不同的预测。这可以发生在不保证以相同的顺序访问训练示例的高度并行化和分布式的训练系统中。然后,如果网络然后控制哪些后续训练示例被看见,那么该网络可以随着协变量移位非常不同地演进。这些偏差可以从训练示例的不同随机初始化、并行化和/或顺序产生。
已经示出了神经网络中存在大量冗余。冗余可能导致上述过度拟合和其他问题。具体地,网络可以被很好地过度参数化,其中一些参数可以由其他参数预测。因为学习(遗憾)惩罚支付给比所需更多的参数,并且收敛速度和泛化能力减慢,所以这特别导致具有有限的训练示例的过度拟合。
因此,当在相同的数据上重新训练但具有训练示例的潜在的不同初始化、并行化和顺序时,神经网络遭受过度拟合、对看不见的数据的潜在的不良泛化、不稳定性和不可再现性。这些问题使得使用神经网络部署大规模系统变得困难,有时甚至是不可能的,由于在提供更准确的预测时无法利用神经网络的显著优势和优点而导致巨大损失。当前的解决方案要求在训练和部署中重复,引起CPU和内存的过度利用,并且由于缺乏资源而阻碍部署更多系统的能力。
技术实现要素:
本公开的实施例的方面和优点将部分地在以下描述中阐述,或者可以从描述中学习,或者可以通过实施例的实践来学习。
本公开的一个示例方面针对一种用于训练神经网络的计算机实施的方法。该方法包括由一个或多个计算设备获得描述神经网络的数据。神经网络包括多层神经元。该方法包括由一个或多个计算设备通过神经网络反向传播损失函数来训练神经网络。损失函数描述神经网络相对于一组训练示例的性能。由一个或多个计算设备通过神经网络反向传播损失函数包括,对于神经网络的多个层中的一个或多个层中的每个层:由一个或多个计算设备确定损失函数相对于层中包括的神经元的梯度。对于至少该层,损失函数包括创新损失项,该创新损失项为层中包括的一个或多个神经元或单元中的每一个提供基于层中的一个或多个其他神经元的能力的损失值,以预测这样的神经元的值。通过一个或多个计算设备通过神经网络反向传播损失函数包括,对于神经网络的多个层中的一个或多个层中的每个层:由一个或多个计算设备至少部分地基于包括创新损失项的损失函数的梯度修改该层中包括的神经元,以解相关该层中包括的神经元。
本公开的另一示例方面针对一种用于训练神经网络的计算机实施的方法。该方法包括由一个或多个计算设备获得描述神经网络的数据。神经网络包括多层神经元。该方法包括由一个或多个计算设备至少部分地基于由相同层中包括的一个或多个其他神经元预测这样的神经元的值的误差来为多个层中的一个或多个层中包括的一个或多个神经元中的每一个神经元确定有益分数(benefit score)。该方法包括由一个或多个计算设备至少部分地基于为至少一个神经元确定的有益分数来修改与一个或多个神经元中的这样的至少一个相关联的权重。
在一些实施方式中,由一个或多个计算设备至少部分地基于有益分数来修改与一个或多个神经元中的至少一个神经元相关联的权重包括,由一个或多个计算设备在误差小于阈值时将权重正则化为零。
在一些实施方式中,该方法还包括在由一个或多个计算设备将权重正则化为零之后,随机地重新初始化与神经元相关联的一个或多个链接(link)。
在一些实施方式中,对于一个或多个神经元中的每一个神经元,由相同层中包括的一个或多个其他神经元预测神经元的值的误差包括,根据相同层中包括的一个或多个其他神经元的一个或多个正则化的激活权重估计这样的神经元的完全激活权重的误差。
在一些实施方式中,由一个或多个计算设备修改与一个或多个神经元中的至少一个神经元相关联的权重包括,由一个或多个计算设备将与一个或多个神经元中的至少一个神经元相关联的权重修改为正则化的值,该正则化的值等于应用于这样的神经元的有益分数的Sigmoid函数或双曲正切函数与这样的神经元的值的点积。
在一些实施方式中,对于一个或多个神经元中的每一个神经元,有益分数包括:所有批次和当前批次的累积平方误差;平均每批次每示例误差;或者一组最近批次的滑动或衰减指数窗口误差。
本公开的另一示例方面针对一种用于训练神经网络的计算机实施的方法。该方法包括由一个或多个计算设备获得描述神经网络的数据。神经网络包括分别通过多个链接连接的多个神经元。该方法包括由一个或多个计算设备通过神经网络反向传播损失函数来训练神经网络。损失函数描述了神经网络相对于一组训练示例的性能。由一个或多个计算设备通过神经网络反向传播损失函数包括,对于神经网络的一个或多个神经元、链接或偏差中的每一个:由一个或多个计算设备确定损失函数相对于神经网络的一个或多个神经元、链接或偏差的梯度。对于神经网络的至少一个或多个神经元、链接或偏差,损失函数包括创新损失项,该创新损失项为一个或多个神经元、链接或偏差中的每一个提供基于一个或多个其他神经元、链接或偏差的能力的损失值,以预测这样的神经元、链接或偏差的值。由一个或多个计算设备通过神经网络反向传播损失函数包括,由一个或多个计算设备至少部分地基于包括创新损失项的损失函数的梯度来修改神经网络的一个或多个神经元、链接或偏差,以解相关神经网络的一个或多个神经元、链接或偏差。
在一些实施方式中,神经网络的一个或多个其他神经元、链接或偏差可以被包括在神经网络的与它们尝试预测的一个或多个神经元、链接或偏差相同的层中。
在一些实施方式中,神经网络的一个或多个神经元、链接或偏差中的至少一个被包括在神经网络的与这样的至少一个神经元、链接或偏差尝试预测的一个或多个神经元、链接或偏差不同的层中。
在一些实施方式中,对于来自该层的每个训练批次,随机选择神经网络的一个或多个神经元、链接或偏差中的至少一个。
在一些实施方式中,示例是小批次训练批次以计算创新解相关损失。
在一些实施方式中,输入层嵌入被随机地或确定地初始化为促进连接到它们的层和塔的解相关的非零值。
本公开的其他方面针对各种系统、装置、非暂时性计算机可读介质、用户接口和电子设备。
参考以下描述和所附权利要求,将更好地理解本公开的各种实施例的这些和其他特征、方面和优点。包含在本说明书中并构成其一部分的附图示出了本公开的示例实施例,并且与说明书一起用于解释相关原理。
附图说明
在说明书中阐述了针对本领域普通技术人员的实施例的详细讨论,其参考了附图,其中:
图1A描绘了根据本公开的示例实施例的训练神经网络的示例计算系统的框图。
图1B描绘了根据本公开的示例实施例的示例计算设备的框图。
图1C描绘了根据本公开的示例实施例的示例计算设备的框图。
图2A-图2C描绘了根据本公开的示例实施例的示例神经网络。
跨多个附图重复的参考编号意图标识各种实施方式中的相同的特征。
具体实施方式
概述和介绍
本公开的示例方面针对通过在神经网络的训练期间解相关神经网络的神经元或者其他参数或组件来正则化神经网络的系统和方法。具体地,本公开提供了一种用于解相关神经网络中的层(例如,输出层或隐藏层)中的相关的神经元的新方案。在一些实施方式中,本公开的系统和方法可以标识在层中提供较少增加的预测值的层神经元。可以由该层的其他神经元很好地预测的神经元对网络增加较少的预测值。可以迫使这种神经元在增加其增加的值的方向上移动。这可以通过注入神经网络的层的附加损失来进行,使得这些神经元上的损失梯度推动神经元远离彼此预测。
因此,在一些实施方式中,本文描述的方案不仅仅基于解相关层中的神经元对,而且还基于确保神经网络的层中的每个神经元被推向超过该层中的其他神经元的信息的创新。作为一个示例,这可以通过确保由层中的一些或所有其他神经元预测给定神经元的值的最小均方误差被最大化来进行。这些示例方案的变化可以通过施加强制执行这样的约束的附加的每层正则化器损失来实施。作为示例,约束可以以L2正则化的形式以及以拉格朗日对偶变量(dual variable)优化的形式施加。因此,本公开提供了用于测量神经元的创新并应用相关的损失以使其最大化的多个策略。神经元可以但不一定包括非线性激活。例如,神经元可以包括并实施线性或非线性激活函数,以基于作为输入提供给神经元的输入值来提供神经元输出。
此外,本公开还示范了,除了示例正则化类型和拉格朗日对偶变量技术之外,还可以实施类似于最小描述长度(Minimum Description Length,MDL)正则化的附加技术以灌输(instill)神经元创新。具体地,神经元的创新(例如,它带来的超过由其他神经元对其预测的值的附加的维度)可以用于放大或缩小神经元的权重。在一个示例中,如果神经元是创新的,则它的权重不会缩小(或者可以放大),而如果它不是创新的,则它的权重会缩小,允许其他神经元接管,并且在某些情况下,迫使神经元最终被正则化。
因此,本公开提供了可以用于正则化神经网络的系统和方法,从而改善网络再现性、泛化和稳定性。作为一个示例技术效果和益处,可以通过消除对整体(ensemble)训练的需要来实现资源节省,从而节省部署中的RAM和CPU使用,确保更快的训练,并且还潜在地改善预测准确性。作为另一示例技术效果和益处,根据本公开的系统和方法训练的神经网络呈现出降低的预测偏差和过度拟合,得到对看不见的数据的更好泛化。
更具体地,考虑神经网络的层(例如,神经网络的隐藏层)。假定给定层保存由网络学习的所有信息,因为它充当信息从输入到输出的瓶颈。由于过度参数化,一些激活的神经元可以与其他神经元相关。换句话说,可以使用层中的激活的神经元的子集来预测其他子集。如果是这种情况,则在可预测的神经元上花费学习损失可能导致较慢的收敛。反过来,这可能导致过度拟合和不良的泛化,以及不可再现性和不稳定的网络。具体地,这样的冗余可以增加解决方案的多样性,使网络的可再现性降低。该问题可以从两个方向解决:解相关;或强制相关。本公开提供了采用解相关方案的系统和方法。
某些技术增加了应用于神经网络中的层中的所有神经元的激活的层损失,其中层损失惩罚具有高协方差的神经元对的层。因此,层损失在逐对(pair-wise)的基础上操作。该损失的反向传播降低了这样的对之间的协方差。总体层目标被设置为省略对角线上的元素的所有协方差的平方(或协方差矩阵的Frobenius范数的平方)和。在一批训练示例中获得协方差的估计。反向传播在这个附加损失上应用梯度。虽然这种方案有优点,但由于以下两个原因,它没有完全解决问题:
首先,协方差可能不是给定神经元解释另一个神经元的程度的正确度量,因为它省略了两个神经元的均值。由于在层中典型地没有任何其他知识用于预测均值,因此仅通过查看协方差可能会丢失层中的神经元之间的某些关系。例如,两个神经元可以具有(非常大的)相等的预期的值——一个具有大方差而另一个具有小方差——但是在两种情况下,方差都远小于均值。此外,神经元之间的协方差非常小。一个神经元仍然可以预测另一个神经元的大部分能量,但是基于协方差的相关性将意味着情况并非如此。协方差约束对均值不施加任何约束,因此均值可以差异很大。例如,如果两个神经元的均值之和为1,则它们的均值可以是总和为1的任意两个值。当施加仅协方差约束时,不消除这样的不同的多种解决方案的可能性。此外,由于神经网络中的激活是非线性的,因此不能预期激活的神经元在批次中将具有均值0。事实上,对于ReLU,这是不可能的,除非神经元未被激活用于该批次中的任何示例。仅协方差约束隐含地假设0均值。
其次,协方差或相关性仅给出两个元素之间的关系。对协方差的平方和进行惩罚省略了其他神经元之间的关系。例如,如果存在三个线性依赖的神经元,为了预测第三个神经元,第一个和第二个神经元两者将被惩罚而不考虑它们之间的关系,而不是在它们之间分割惩罚。这可以潜在地夸大对一些神经元的惩罚,同时低估对其他神经元的惩罚。
本公开的各方面解决了这两个问题。具体地,在一些实施方式中,代替使用协方差,本公开的系统和方法使用相关性,因为在层中没有对均值的估计器。那么,一个目标是基本上迫使层中每个神经元的创新(例如,每个神经元的激活)相对于来自该层中的其他神经元的信息最大化。例如,考虑具有n个神经元的给定层中的信息由n维欧几里德空间中的点给出,平方误差是有效度量。
为了最大化激活的神经元(例如,其中激活也可以是线性的)相对于其同伴的创新,本公开的系统和方法可以尝试根据其他激活的神经元来预测激活的神经元。在最小化示例训练批次(batch)上的均方误差方面的最佳预测器是条件均值估计器。然而,由于难以计算它,因此在一些实施方式中,本公开可以替代地考虑最佳线性预测器。因为在层中没有用于优化层之外的损失的其他信息,所以在一些实施方式中,可以使用齐次线性估计器。换句话说,由于最终目标仅“看见”层的激活的神经元,因此不应该使用其他任何东西来确定神经元相对于传播到最终目标的所有其他信息单元是否具有创新性。
本公开提供的第一示例策略是使用齐次线性最小均方误差(Minimum Mean Square Error,MMSE)估计器来预测层中的每个神经元。考虑到对统计相关性和均值的估计是准确的,该估计器给出了根据其他激活的针对每个激活的良好估计(给定的计算上易处理的约束)。根据本公开的方面,在一些实施方式中的目标是使该估计器的误差尽可能大;误差越大,神经元的创新越好。该解决方案要求大矩阵的多个求逆(inverse)。然而,如果这是难以处理的,则可以用作为第二示例策略提出的潜在次优的基于回归的解决方案来替换误差最小化。
由本公开提供的第三示例策略将训练批次中的k个示例的n个神经元视为对于k个示例的神经元值的nk维向量。该第j个向量表示在训练批次的k个示例上的第j个神经元的状态。可以从每个神经元向量减去其在其他n-1个向量上的投影,以产生由其他n-1个向量预测该向量的预测误差。换句话说,可以产生与其他向量正交的误差向量。该向量的范数是批次的预测误差。同样,可以尝试通过例如反向传播范数的平方的反转(invert)的值的梯度来最大化该范数的平方。可替代地,可以最小化该向量到其他向量的投影的范数。
在以下部分中,本公开描述了以上呈现的策略的细节。首先,本公开示范了如何应用神经元对的解相关的示例。接下来,本公开示范了用于计算网络层的基于最大创新的基于均方误差(Mean Square Error,MSE)的目标的三个示例策略。然后,本公开示范了将该目标应用于网络的层的两个示例方案:用于对批次强制执行最大MMSE(创新)约束的类正则化方案、以及使用基于拉格朗日约束的优化的变体。接下来,描述如何利用平方误差创新估计器以在层上应用基于在线益处(类MDL正则化)的方案。最后,解决了些实际的复杂度问题,并呈现了关于如何在实际系统中应用该技术的若干想法。
因此,本文提供了基于由层中的其他神经元预测层神经元的创新或均方误差的方案。一个根本的想法是,如果可以以小幅度的误差从层中的其他神经元预测神经元,则该神经元可能是冗余的。通过推动神经元的梯度来增加其在其他神经元上的创新,提出了解相关神经元的方法。可替代地,提出了如果神经元不是创新的,则使用基于有益分数的方案正则化神经元,其中该分数与神经元的创新紧密相关。
虽然本文讨论的部分集中于隐藏层内的神经元,但是本文描述的创新正则化技术可以在任何层中执行。在顶层和/或底层上执行技术可能就足够了,但是除了增加的计算成本之外,没有限制不包括更多层。例如,执行该技术的计算成本可能使得期望仅在顶层实施它以降低复杂度。但是,将它施加于其他层也可以是有益的。因此,除非另有指明,否则在本公开中对层的任何引用都包括在其范围内的输入层、隐藏层和输出层(例如,包括由单个神经元组成的层,其中每个层朝向完整网络的组件(例如,塔))。
另外,尽管讨论集中于神经网络,但是本文的方案(例如,利用MSE解相关的方案)比仅用于神经网络更通用。它们还可用于查找线性模型中特征之间的相关性。具体地,在一些实施方式中,它们可以仅应用于线性模型的批次更新中存在的特征子集,而不是整个特征集合。
此外,虽然通常在层的激活的神经元上描述该方案,但是可以将其应用于预激活的神经元、链接、偏差或神经网络的其他参数或方面。由于期望在最接近最终输出的点处测量层的创新,并且因为对最终目标的影响是最终关注的,所以在激活后应用约束是合理的。然而,如果许多神经元不激活,则可能不是非常有益,并且应用预激活方案也是可能的。同样地,除了非线性激活之外或替代非线性激活,本文描述的方案可以应用于线性激活。此外,该方案还可以应用于其他组件和链接或者网络中的任何参数。具体地,在一些实施方式中,它可以跨层应用于不同的神经元。然而,本公开主要考虑的方案是在完整层内应用它,因为层应该捕获来自其下面的层和神经元的所有信息,并将该(压缩的)信息中继到目标。
在一些实施方式中,提出的方法可以具体应用于最接近整体模型结构中的输出的层。这样的星座(constellation)的一个示例包括几个独立的网络,网络中的每一个在输出端有一个神经元。附加的创新损失可以应用于组合整体的组件的输出神经元的层,但是迫使每个独立的整体组件彼此不同并且在其他网络上创新。
在一些示例中,其中输入由被编码到嵌入的特征表示,可以通过对输入嵌入强制执行不同的随机初始化来复制网络的整体组件来鼓励神经元或网络组件的创新。
本公开的系统和方法提供了多个技术效果和益处。作为一个示例技术效果,本公开的系统和方法使得能够生成展现出对看不见的数据较少的过度拟合和更好的泛化、稳定性和再现性的神经网络或其他机器学习模型。因此,本公开的系统和方法使得能够生成相对于现有技术展现出优越性能的机器学习模型。此外,本公开的系统和方法可以使得能够更快收敛神经网络,因为在一些实施方式中,在每轮训练中推动神经元在其同伴上创新。
作为另一示例技术效果,本公开的系统和方法使得能够改善处理和存储器资源的利用。更具体地,尝试解决过度拟合、不良泛化、不稳定性和/或不可再现性的某些现有技术依赖于整体方案的性能。这些整体方案要求在训练和部署中复制(可以是大规模的)多个网络。重复或冗余网络的这种训练和部署极大地增加了处理和存储器资源两者的消耗。因此,通过提供解决过度拟合、不良泛化、不稳定性和/或不可再现性而不依赖或较少依赖于整体方案的性能的解决方案,本公开的系统和方法释放了大量的处理和存储器资源,否则该大量的处理和存储器资源将专用于这样的整体方案。可替代地,如果维持类似的整体结构,创新鼓励方法可以依赖整体来促进更好的再现性。
解相关
考虑具有n个神经元的神经网络的层。该网络每次训练k个示例的批次。对于一些示例,令Z代表表示层的末端处的神经元的激活的n维随机列向量。层的相关矩阵由下式给出
C2=E[ZZT]
其中上标T代表转置运算符。我们可以使用当前训练批次中的相关矩阵Cz的元素i,j的经验估计
为了使这些估计有效,我们应该在批次中具有比层中的神经元数量足够多的示例,即κ>>n。贯穿本公开,将使用以下符号约定。下标表示激活的神经元(或层神经元)的索引j,其中1≤j≤n。多个(两个)下标i,j代表两个这样的神经元之间的关系。上标l,其中1≤l≤k,代表训练批次中的示例的索引。
根据本公开的方面,通过增加层损失,诸如以下示例层损失,可以对层中的相关性的平方和施加约束:
其中||Cz||F代表Cz的Frobenius范数,以及diag表示矩阵的对角元素。注意,这种损失可以通过神经元的数量n来标准化(normalize)。增加正则化器权重λ并且将叠加有总体目标的损失的梯度从给定层中的神经元的激活向下传播,可以强制执行正则化,该正则化将减小层中的激活对之间的相关性的幅度。这解决了这样一个事实,即利用协方差的类似方案不能解决激活的均值的相关性。
可以扩展上述方案,使得相关性贯穿训练期间被连续更新,而不是被每批次重新计算。对此的一种实施方式可以对批次使用指数衰减窗口的形式,其将先前计算的值乘以小的正常数(positive constant)(例如,小于1),并将针对当前批次的计算的相关性与小于1的另一常数相加。
可替代的方案
上面呈现的解相关方法对训练批次使用层或组件输出之间的解相关或接协方差(de-covariance)。其他损失可以生成与解相关相似的效果。可以被称为反蒸馏损失(anti-distillation loss)的损失可以用于将输出推离彼此,诸如L2损失,
可以迫使预测不同的其他损失也是可能的。
可以修改相关性和协方差损失以消除因为组件输出在对之外相关而引起的重复损失。降低输出a和b之间和输出a和c之间的相关性可能重复(double)计算a与b和c的相关的分量之间的相关性。为了消除这种重复计数,可以对分量Zi进行Gram-Schmidt标准正交化以生成批向量(batch vector)的基础。不是在向量Zi之间增加解相关损失,而是对于j<i可以在Zi和Bj之间增加解相关损失,其中Bj是在Gram-Schmidt标准正交化步骤j处产生的基础向量。仅对这些相关性施加损失将确保每个附加步骤试图仅消除先前步骤未消除的投影(或相关性)。
在层中灌输创新
MMSE估计器
为了解决(在可行的线性约束下)每个激活的神经元的创新的最大化,我们从由Z-j代表的、其他神经元的n-1维向量推导出第j层神经元Zj的线性MMSE估计器。同样,为了使相关性的估计有效,批次大小应该相对于神经元的数量足够大,即k>>n。令Cz;-j代表从Cz中丢弃第j行和第j列得到的(n-1)×(n-1)维相关矩阵。令
bj=E[ZjZ-j]
是层的第j个神经元和所有其他神经元之间的n-1维互相关向量。注意,bj等于具有省略的第j个元素的Cz的第j列,。然后,根据Z-j的Zj的(齐次)线性MMSE估计器由下式给出
其中
aj=(Cz;-j)-1·bj。
例如,在对批次中的示例l估计Zj时的误差由下式给出
其中小写字母用于代表随机变量的实例化值。可以每示例进行估计,其中上标l代表批次中的示例的索引。平均批次误差由下式给出
平均批次平方误差由下式给出
平方的平均批次平方误差
预期的MSE也可以直接从相关性中计算。它由下式给出
使用此表达式,我们不需要计算批次中的每个示例的误差。相反,我们从批次估计相关性、反转矩阵Cz;-j,以及用该等式针对批次计算MSE。
为了避免可能的奇点,如果我们的神经元在批次期间未被激活或者针对该批次中的非常小的部分被激活,则我们可以将它们排除在预测和附加传播的损失之外。
求逆创新损失:
训练批次中的层损失是神经元和批次的示例上的损失的叠加
可以每示例和每层神经元标准化损失。但是,有可能,这可以不是必要的。无论如何,标准化或缺乏标准化都可以专注于正则化缩放(scale)因子λ,当与网络的目标损失相结合时,该缩放因子λ可以被添加到该损失中。损失可以每神经元每示例被分解,以及可以仅每个神经元被分解。
创新损失旨在推动网络最大化层中每个神经元的创新。这意味着(最小)均方预测误差应该被最大化。为了将该约束与被最小化的网络损失相叠加,可以将误差的概念转换为可以被最小化的损失。施加负的批次均方误差损失将满足该要求。然而,这样的损失不是凸的(它是凹的)。因此,在MSE为0的情况下,损失的梯度为0。大约0,其具有很小的幅度。MSE接近0的区域是我们需要大梯度来推动神经元在其他神经元上更快地进行创新的区域。
在一些实施方式中,我们可以具有反转MSE的损失,而不否定MSE。这种损失确实在0区域处提供了大的梯度。我们可以通过在分母上增加一个正项β来抑制该损失,将梯度上限设为0MSE,即没有此项该梯度是无限的。针对第l个示例上的第j个神经元,这引起以下损失
为了数字方便,增加系数1/2以抵消梯度中的2项。(它最终被一个将被增加的正则化因子λ抵消。)层损失由下式给出
每神经元每示例的损失相对于(相对于)示例l中的第i个神经元的梯度由下式给出
注意,该梯度具有示例l中的每神经元j相对于层中的任何神经元(包括第j个神经元)的损失。我们使用aj;v来代表n-1维向量aj的第V个分量。最后两个区域之间的区别仅仅是因为通过去除z-j中的第j个分量而使分量上移。
我们注意到梯度推动非创新的神经元的权重远离基于其他神经元的相关的估计器。然而,它还将估计器中的神经元推向远离估计的神经元的相反方向。这可能潜在地削弱其他神经元。在一些实施方式中,可能更期望仅允许移动预测的神经元(predicted neuron)而不移动预测神经元(predicting neuron)。这可以通过停止第i神经元上的梯度的传播来施加,其中i≠j。但是,可能没有必要。下面呈现的替代的基于有益分数(MDL正则化)的方法可以解决这一问题。
如果我们有非常相关的神经元(在极端情况下,相等的神经元)i和j,并且这两者上的一个神经元i的创新损失的梯度将否定这两者上的另一个神经元j的创新损失的梯度,并且它们可能永远不会移出这种相关状态。为了解决这样的问题,在一些实施方式中,我们可以在神经元当中区分优先级。对此的一种方案是通过为每个神经元的损失分配不同的正则化系数来避免这样的问题。但是,我们可以随机分配神经元之间的相关性的比率的倒数,这可能会产生同样的问题。这可以通过随机扰乱批次之间的正则化系数来解决。当我们描述如何利用正则化在网络上施加层损失时,将更详细地讨论该主题。同样,最后描述的基于有益分数(MDL正则化)的方案对于像这样的问题可以更加稳健。
可替代的创新损失:
作为求逆MSE损失的可替代的方案,也可以使用具有正目标值的MSE的递减函数,只要它们满足凸性要求,并且在0MSE的区域处实现最大梯度。不幸的是,相对于平方误差的指数衰减遭受与否定MSE(相对于0平方误差处的非平方误差的0梯度)相同的问题。然而,相对于MSE的平方根衰减的函数满足这些要求,并且可以使用。两个这样的损失是相对于由下式给出的误差的L1范数的逆损失
其中,同样,β用于抑制函数以避免0处的无限梯度。可替代地拉普拉斯损失
其中可以使用参数α。
批次平方误差:
用于从其他神经元预测神经元j的损失Lj在批次中的示例上被分解。但是,该方案的统计相关性由批次中的所有示例估计。考虑示例上的聚合的损失也是合理的。与线性回归不同,梯度在误差项中不再是线性的。计算批次的误差或平方误差的预期,并且在更新中使用预期的值将引起不同的批次梯度。
使用具有阻尼的逆平方损失(dampened inverse square loss)的预期的误差(而不是如前所述应用对批次的损失的预期),所有神经元的聚合的损失由下式给出:
每神经元损失是
相对于示例的神经元j的微分
求和批次中的所有示例
批次中所有示例的得到的梯度等于批次中预期的误差的梯度。当我们在示例上分解时,批次的梯度之和是相同的函数的预期
对于正且足够大的x以及对于足够小的β,该函数的幅度是凸的。因此,通过Jensen的不等式,每示例计算的梯度可以会引起更大的梯度步长(如果它们都在相同的方向上)。类似地,对于足够大的负值,同样会发生相反的方向上。
对于一些i≠j,通过相对于j的梯度在i<j和i<j的情况下分别乘以因子-aj;i或-aj;i-1,Lj相对于的梯度被表示得类似于每示例梯度。
使用具有阻尼的逆平方损失的预期的平方误差,所有神经元的聚合的损失由下式给出
每神经元损失是
相对于示例的神经元j的微分为,
求和批次中的所有示例
由于EX2≥(EX)2,因此批次MSE的梯度的幅度小于批次的平均误差的幅度,(在提到的条件下)其小于批次上的示例的梯度的那种聚合。
同样,对于一些i≠j,通过相对于j的梯度在i<j和i>j的情况下分别乘以因子-aj;i或-aj;i-1,Lj相对于的梯度被表示的类似于每个示例的梯度。
如果我们直接计算MSE或通过后面呈现的投影进行创新,则使用预期的均方误差的梯度可以是自然拟合的。
梯度下降回归估计器
n个神经元的层中的n个MMSE估计器的集合需要反转n个(n-1)×(n-1)维相关矩阵Cz;-j。在一些情况下,这可能是计算密集型的。作为可替代的方案,最小二乘线性回归问题可以利用训练批次期间相对于向量aj的平方损失
来解决。这可以通过在批次上执行批次梯度下降的多次迭代来进行。它可以为所有n个神经元进行。虽然我们可以迭代足够次数以保证对解决方案的收敛,但是我们也可以针对一些可能次优的解决方案执行少量固定数量的迭代。然后,该解决方案可以用于计算从该层向下传播的损失和梯度,而不是MMSE。在最小化相对于aj的误差之后,剩余步骤现在将最小化如针对MMSE呈现的反转的误差损失。不完全回归可能引起一些次优的最小值,现在在这些次优的最小值上执行误差的最大化。第一步中的不完全最小化可能会夸大神经元的创新。尽管是次优的,它仍然可以执行足够的正则化水平,但是具有更可行、更少计算密集的方案。
如果我们可以每层利用O(n2)的附加存储,则我们可以在给定批次中执行几次梯度下降迭代,以改善估计器αj的系数。然后,我们存储系数aj的状态,并在下一批次中使用存储的值热启动下一次迭代。这可以改善结果并使向量αj接近其实现MMSE的值,但代价是附加的存储空间。
通过投影的批次创新
对于基于投影的方案,我们应该使k≥n,即,我们应该在批次中至少有与层中神经元一样多的示例。否则,层的神经元所跨越的空间的维度由小于层中的神经元的数量k限制。
为了呈现基于投影的方案,我们需要在表示层的维度的n个神经元和k个示例的之间转置之前定义的符号。令
是列向量,其表示批次中k个训练示例的神经元j的k个值。定义k×n维矩阵
X=[x1,x2,...,xn]
作为所有层神经元上的层神经元值的列向量的级接。令
B-j=[b-j;1,b-j;2,...,b-j;n-1]
是k×(n-1)维矩阵,其列是跨越由省略第j列的X列所跨越的空间的基础向量。可以通过对排除第j列的X列执行Gram-Schmidt标准正交化来获得B-j的列。B-j的实际的列将取决于Gram-Schmidt过程在X列上执行的顺序,但是这不会影响我们感兴趣的实际投影误差。此过程的复杂度将在本部分的末尾讨论。
现在,对于所有j,1≤j≤n,我们需要计算将向量xj投影在由B-j所跨越的空间的误差。此误差由下式给出
其中<xj,b-j;i>是两个向量之间的内积。ej的第l分量是示例l的误差分量。该误差ej给出了不能由其他n-1个向量xi,i≠j解释(或预测)的xj的部分。换句话说,误差是在第j个层神经元的值与由该层的其他n-1个神经元对它们的预测之间的、批次中k个训练示例上的差值的向量。
批次上的神经元j的MSE由ej的标准化(例如,每示例的)的平方范数给出
由于示例的完整批次上的投影过程,表达关于批次均方误差的损失目标似乎是这里的自然方案。因此,我们将层损失定义为
可以通过遵循损失的推导的线性步骤(包括为每个j生成基础矩阵B-j)来推导出相对于的梯度。
我们还可以使用用于MSE策略中类似损失的等式来定义每示例的损失。与ej中的各个元素相对应的误差可以被插入等式中。同样,梯度可以从执行以获得的线性步骤中推导出。
矩阵B-j的生成要求将来自X的n-1个向量中的每一个递增地投影到B-j的已经形成的列上,从向量中减去投影,以及将残差标准化到B-j的新的列中。将xj投影到基础上要求另一n-1个投影(乘法)。每次投影都是O(k)的乘法。对于完整过程,有O(1+2+3+...+n-1)=O(n2)个投影/标准化步骤。因此,将一个向量j投影到由其他向量创建的基础中的复杂度是O(kn2)个乘法。如果我们为每一个j执行此操作,则我们将需要O(kn3)个乘法。
通过共享创建的一些基础向量可以降低这种复杂度。我们可以存储O(nklogn)个元素,并且只执行O(kn2logn)个操作,而不是在任何给定时间存储O(nk)个元素(O(n)个基础,k个元素中的每一个)。我们将向量xj分成两个相等(或几乎相等大小)的集合。对于每个集合,生成基础。存储为两个集合形成的n个基础向量的级联。然后,每个集合再次分成两半。令A是原来的上半部分,B是原来的下半部分。A的原始向量现在被对半分成两个集合Λ1和A2,并且B的那些被分成集合B1和B2。对于集合Λv中的每一个,我们在为集合B形成的基础向量上(在集合之间单独地)继续Gram-Schmidt过程。类似地,这也使用为A形成的基础来对Bv进行。递归地重复该过程,直到每个剩余的集合具有单个向量。对于这些单个向量中的每一个,现在将来自前一步骤的其同胞(sibling)投影到由该单个向量的路径上的集合中的向量组成的基础上以产生误差。这个过程有O(log n)个步骤,每个步骤都有O(n2)个投影,每个都采取O(k)个操作。
可替代的投影损失
我们可以直接最小化任何向量在其他向量所跨越的空间上的投影能量,而不是使用投影误差并最小化与误差成反比的损失。我们可以对分量xj执行Gram-Schmidt标准正交化,以生成批向量的基础。除了在向量xj之间增加解相关损失之外,我们还将在xj和B-j的列之间增加解相关损失,其中B-j是如上定义的基础矩阵。xj的损失将被施加到从xj投影到B-j的所有列的能量上。仅对这些相关性施加损失将确保每个附加步骤试图仅消除先前步骤未消除的投影(或相关性)。如果对xj和B-j的列两者施加损失,并且允许梯度反向传播到这两个向量,则对于每个j,我们可以降低过程的复杂度并且仅在列i上执行它,使得i<j。这允许构建单个矩阵B以考虑所有相关性,但是对于相同的相关性可能遭受多次补偿。
在网络上施加层创新
现在将示出如何在反向传播期间将层创新解相关约束施加于神经网络更新。这些方法适用于上面呈现的任何创新损失计算策略。
创新灌输作为正则化
在训练网络时施加层创新损失约束的一种方案是L2类正则化的形式。在反向传播期间,当从上面的层进入层时,该层看见的损失是来自上面的损失(全目标加上来自其他层的潜在正则化损失)和创新损失的缩放的版本的总和
其中,应用于上述任何(在示例和层神经元两者上聚合的)全损失。系数λ是正则化系数。
如上所述,如果两个层神经元i和j对于所有示例是相等的(或是高度相关的),则神经元i上的损失将推动它们在一个方向上彼此远离。j上的损失会将他们每个推向相反的方向。这可能引起不会推动任何神经元的聚合梯度。为了打破这样的对称性,可以使用不同的缩放因子λj对每个神经元的约束进行正则化。因此施加的正则化层损失是
如果神经元是彼此相关的缩放的版本,则我们将选择抵消梯度之间的比率的λi和λj是仍然可能的(尽管非常不可能),仍然引起如上所述的类似问题。为了解决这个问题,我们可以对每个λj值应用小的随机扰动。批次的正则化缩放因子λj可以包括具有附加的低方差(相对于均值)0-均值正态随机变量的固定均值,为每个批和每个神经元j绘制一次。
利用约束优化的创新灌输
作为正则化方案的替代,可以通过拉格朗日约束优化来施加创新解相关损失。对于约束的每个元素(例如,对于层的n个神经元的每个神经元),我们附加对偶变量λj,并且与在网络中向下传播的损失叠加的损失
相对于最小化,但是相对于对偶变量λj最大化。我们还可以在训练批次上增加对偶变量的L2正则化。
利用类最小描述长度(MDL)正则化方案的创新灌输
线性模型的MDL正则化使用测量特征在损失上的改善的有益分数。该特征在没有正则化的情况下进行训练,但是看见正则化的所有其他特征。有益分数用于通过缩小其权重来正则化该特征。具有大的有益时,几乎不会发生缩放,具有较低的有益时,该特征可以缩小。有益分数的阈值μ可以用于完全拒绝其有益分数低于该阈值的特征。
针对层中的神经元计算的均方误差可以充当用于层的类MDL正则化方案的有益分数。使用这种方案,在反向传播算法中训练神经元而不进行正则化。然而,为了执行创新正则化,估计的神经元使用所有其他神经元的正则化的版本。然后,前向传播将神经元的正则化的版本传播到网络上。反向传播接收正则化的版本的梯度,将它们缩放回完整版本,以便反向传播到下面的层。
βj代表该层的第j个神经元的有益分数。来代表正则化的版本。对于前两个创新计算策略,通过下式来根据所有其他神经元的正则化的激活权重来估计该第j个神经元的完整激活权重
并且(例如,示例l的)误差由下式给出
神经元的正则化的权重由下式给出
其中ρ和ξ是参数,并σ代表Sigmoid函数
我们可以设置阈值μ,是的如果βj≤μ,则我们将正则化为0。请注意,与具有线性模型的MDL不同,均方误差的下限为0,即,我们不能具有负的有益分数。因此,我们可以通过选择(高)负值来使用参数ξ降低缩放因子。可替代地,Sigmoid函数可以由另一个函数替换。可能的替代方案是双曲正切,即
其中ξ≥0。
对于通过投影的创新,我们使用其他神经元的正则化的权重来预测未经正则化的权重。这意味着矩阵X使用神经元权重的未经正则化的版本,而基础矩阵B-j使用正则化的版本构建。较低的复杂度版本应用引起正则化的向量上的B-j的所有步骤,但是最后的投影步骤应用于X的列。请注意,只要我们没有将阈值向量设置为0,这就没有区别,因为xj的所有示例都会出现相同的缩放。如果我们将具有βj<μ的神经元j的阈值设为0,则这会将xj的所有分量设置为0。这将从Gram-Schmidt过程中排除xj,以用于寻找所有i≤j的B-i。因此,它潜在增加可以由第j个神经元预测的其他神经元的误差。这生成了期望的效果,其中我们丢弃对其他神经元增加很少值的神经元,从而增加了其他神经元的益处。
令代表传播到的梯度。然后,从传播到然后连接到下面的层的梯度由以下链式法则给出
其中σ′(ρβj+ξ,μ)代表Sigmoid的剪辑版本,(假设我们使用Sigmoid)对于βj≤μ剪辑到0。
有益分数可以是所有批次和当前批次的累积平方误差,或者我们可以将其标准化为每批次每示例的平均。我们还可以在一组最近的批次上使用滑动(或衰减指数)窗口。因为在任何情况下我们都求和了示例上的平方误差,并且我们不对得到的均方误差应用非线性运算,所以在聚合每示例平方误差或使用平均批次平方误差之间没有区别。
训练开始前的初始有益分数可以设置为对于所有神经元是一些足够大的值,以确保它们有机会来训练。然而,有可能,其中一些神经元优先于其他神经元的随机初始化可以打破对称性,并且让一些神经元首先演进为有益的,保持冗余神经元正则化。将对于所有j的初始有益分数设置为0将停止训练,因为它会通过将所有神经元设置为0来阻止任何反向传播。
可以通过有益分数的设计来调整参数ρ。将具有低平均或累积MSE的神经元(取决于效益得分的设计选择)将使得被层上方的网络的其他组件看见的其权重被正则化为非常小的值或者如果低于阈值μ则被正则化为0。这将停止更新向下传播到连接到该神经元的神经元。然而,如果这些神经元开始偏离它们的当前值,它们可能会影响当前层中的其他神经元发生改变,使得估计正则化的神经元的MSE可以再次生长,引起该神经元在更新中再次有效。
如果神经元在许多批次中被正则化为0,则该神经元呈现的参数可能不会再次变得有用。随机初始化引起神经元的链接及其偏差可以是有益的,因此网络可能能够为该神经元找到不同的、可能有用的参数。现在可以通过以下方式使神经元与当前批次上的其他神经元正交来进行初始化:随机生成神经元的批次值;利用前两个策略从其他神经元生成神经元的线性MMSE估计器(或者从投影策略中推导出估计器);从随机生成的值中减去批次中的每个示例的MMSE估计值,或者利用投影策略,仅将其应用于神经元以找到残差;以及将得到的梯度传播到连接的链接和偏差。这可以在几个批次中进行,因此下面的链接适应于新值。
在一些实施方式中,最后两个步骤可以通过基于它们看见的他们的下面的激活求解满足偏差的变量的神经元的值和直接连接到下面的神经元的链接的等式来替换,并分配这些解决方案以再次热启动这些链接。
对于某些层,可以由层中的其他神经元预测的相关的神经元表示不向网络增加预测值的冗余参数。这还可以包括表示对预测没有帮助的特征的参数。这在概念上意味着神经元的创新可以具有益分数的含义。虽然在一些情况下,这样的有益分数类似于MDL正则化有益分数的作用,但是相关性维度比常规MDL分数捕获更多。它还捕获特征之间的相关性。对于连接到输出损失的顶隐藏层,利用驱动有益分数的损失(如在利用MDL的线性模型中使用的有损失)有可能可以向神经网络增加另一维度的降噪改善。
MDL方案可以比基于梯度的正则化方案更快地消除坏神经元,该基于梯度的正则化方案要求迭代梯度的传播,直到神经元在没有用的情况下被正则化。如果发生这种情况,它可以更好地泛化并更好地消除过度拟合。
如已经提到的,用于将神经元权重缩放为创新有益分数的函数的Sigmoid函数仅是一种选择。虽然对于使用线性模型的MDL正则化来说它是合理的,因为它将有益分数作为对数优势来表示该特征对模型是有益的,但是在这里,概率的概念稍微有些脱离计算的度量。除了已经提到的双曲正切之外,[0,1]中具有目标的其他单调尺度函数可能更好。
类MDL方案的有益分数与我们尝试最大化的目标直接相关。目标越大(神经元越具创新性),其益处越大。通过不反转创新,我们也没有不同的行为,无论我们平均批次的平方误差还是目标。
MDL正则化驱动策略的附加的优点在于我们不会直接在网络上施加损失。除了对正则化的神经元本身的正则化效应之外,网络可以在没有附加损失的情况下进行训练。创新仅用于正则化所讨论的神经元,而不影响其他神经元。这可以防止可以由非自然正则化形成的偏差(正如我们已经在MDL正则化比L1方案中看见的那样)。它还可以避免像针对两个相同的神经元描述的问题,该两个相同的神经元的创新目标可以相互否定,因为对一个神经元的约束影响其他神经元。
实际约束和迷你批次处理(Mini-Batching)
使用针对给定批次提出的任何策略来计算层的神经元的创新可能都过于计算密集。计算复杂度是O(kn2)或更大。如果一个层由数千个神经元组成,并且示例的批次由数千个示例组成,则这样的复杂度是不可行的。为了解决这个问题,我们可以在任一维度或两个维度中使用迷你批次。示例可以被迷你分批为更小的批次(尽管为了满足维度要求,这些批次应该大于批次中的神经元的数量)。我们还可以将层中的神经元划分为多个批次,并计算层神经元的较小的迷你批次的相关损失。这两种方法也可以结合起来。
迷你批次处理神经元将该层划分为被迫不相关的集合,而来自不同集合的神经元之间的相关性可能仍然存在。这不是理想的,但是可以(至少部分地)通过定期或随机地在不同批次之间混洗(shuffle)迷你批次分区来避免。随机混洗将确保平均地将创新约束均匀地应用于层神经元的子集上。对相对层神经元的较小子集进行迷你批次处理并在完整批次之间进行混洗分区将大大降低复杂度,并使这种方案即使在较大的层的情况下时也是可行的。
在包括塔的集合(ensemble)的神经网络上的示例使用
本文描述的技术的一个示例应用是神经网络,该神经网络包括独立的塔的集合(例如,从输入到输出缩小的独立网络)。具体地,作为一个示例,图2A示出了包括塔的集合的神经网络200,该塔的集合包括塔202、204和206。出于解释的目的示出了三个塔,但是网络可以包括任意数量的独立的塔。
在一些实施方式中,每个塔202、204、206可以接收塔特定输入,该塔特定输入可以来自网络200的较早塔特定部分。例如,塔202从网络200的部分252接收塔特定输入;塔204从网络200的部分254接收塔特定输入;塔206从网络200的部分256接收塔特定输入。可替代地或另外地,每个塔202、204、206可以接收可以来自网络200的较早部分的共享输入。例如,每个塔202、204和206从网络200的部分258接收共享输入。
神经网络200包括组织成多个层的神经元。作为示例,这些层包括输出层218和诸如隐藏层214和216的多个隐藏层。隐藏层216被示出为位于一组softmax或Sigmoid操作之前,并且因此在一些情况下可以被称为logits层。如层214和216所示,在一些情况下,神经元可以在相同的层中但是在不同的塔内(例如,神经元241和244都在层214中,但是分别在独立的塔202和204中)。
在本文描述的技术的一些示例应用中,一个塔中包括的神经元或其他参数可以相对于其他塔中包括的神经元解相关。可以在隐藏层(例如,214或216)或输出层218处应用解相关。
在一些实施方式中,可以通过在损失函数中包括创新损失项来执行解相关技术,该创新损失项为塔中的一个塔中包括的每个神经元提供基于其他塔中的神经元,而不是自己塔中的其他神经元的能力的损失值,来预测这样的神经元的值。随后的描述将解相关作为迫使神经元在其他神经元上进行创新的任何损失,诸如但不限于解相关或前面描述的任何创新损失。
作为一个示例,神经元241可以与神经元244-248解相关。此外,在一些实施方式中,解相关技术不应用于从神经元242或243解相关神经元241。因此,创新损失可以应用于神经元241,该创新损失为神经元241提供基于其他塔204、206中的神经元244-248,而不是其自身塔202中的其他神经元242、243的能力的损失值,以预测神经元241的值。创新损失可以分别应用于所有神经元241-248中的一些。
类似地,层216和218中的神经元可以与相同层中的其他塔中的其他神经元解相关。作为示例,神经元262可以与神经元261和263解相关。作为又一个示例,输出283可以与输出281和282解相关。因此,可以在softmax或Sigmoid操作之前(例如,在层214和214处)应用解相关和/或可以在softmax或Sigmoid操作之后(例如,在层218处)应用解相关。如果标签是二进制的,则softmax可以用Sigmoid函数替换。否则,在一些实施方式中,softmax上的解相关可以应用于softmax的每个标签值(例如,如果存在4个不同的标签值,则可以为4个中的每个进行神经元之间的解相关。它也可以为4个中的3个进行,其中第4个标签softmax值来自其他3个)。
因此,可以在网络200的一个或多个不同层上应用解相关,该网络200包括诸如214的隐藏层、诸如216的logits层、和/或诸如218的输出层。
图2B显示了另一示例神经网络300。神经网络300与图2A的网络200非常相似,除了在图2B的网络300中,塔202、204和206的神经元261、262和263在生成输出304的softmax或Sigmoid层306之前被组合成单个共享神经元302。根据本文描述的解相关技术,层214和/或216的神经元可以解相关。因此,在一些示例中,可以在将塔组合成一个或多个共享神经元(例如,共享神经元302)之前执行解相关。如图2B所示,塔202、204、206到共享神经元302的组合可以在softmax层306之前发生。在一些示例中,神经元的组合可以被应用为总和、平均、门控混合专家(gated mixture of experts)或其他形式。
图2C显示了另一示例神经网络400。神经网络400与图2B的网络300非常相似,除了在图2C的网络400中,塔202、204和206的神经元261、262和263在softmax层404之后被组合成单个共享输出402。因此,如图2C所示,塔202、204、206到共享神经元402的组合可以在softmax层404之后发生。
再次参考图2A,根据另一方面,在训练期间,可以将嵌入到网络200的输入值初始化为除零之外的值。例如,可以将到部分252、254、256和/或258的输入值初始化为非零值。具体地,在一些实施方式中,输入值可以初始化为随机值。将输入值初始化为非零可以有助于本文描述的解相关技术,因为它们可以提供可以在训练期间增加的解相关的初始量。在一些实施方式中,嵌入值可以非随机地初始化为非零值、或者作为从先前训练的模型传送的值。
示例设备和系统
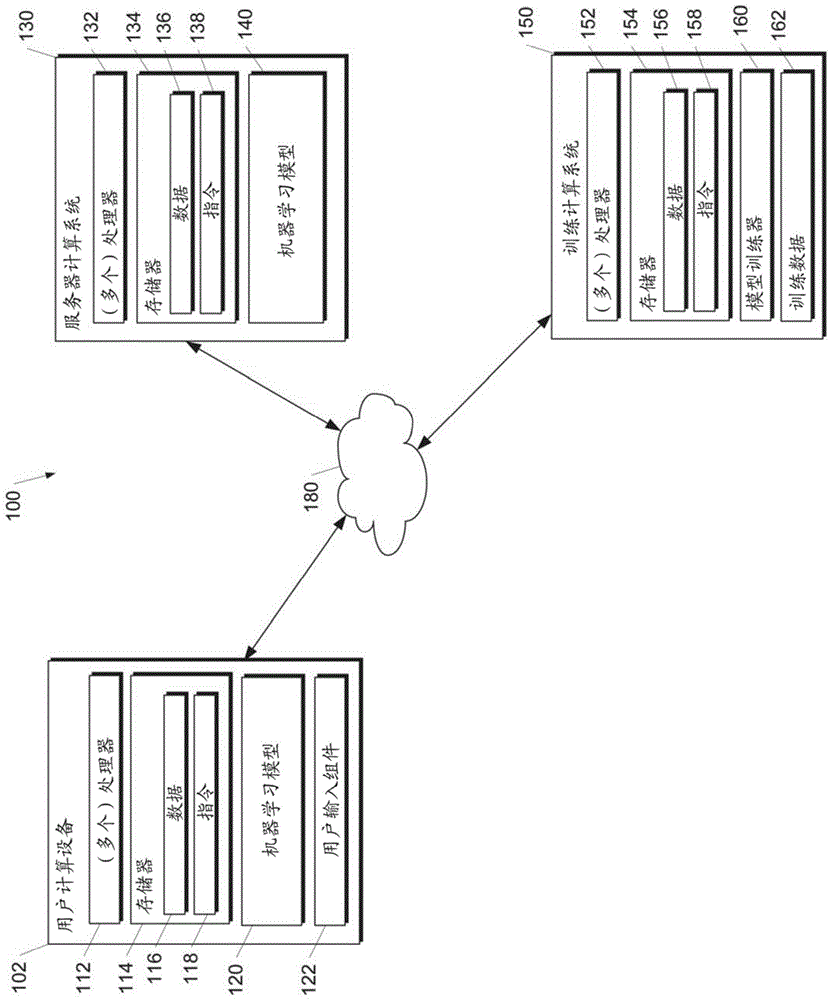
图1A描绘了根据本公开的示例实施例的示例计算系统100的框图。系统100包括通过网络180通信地耦合的用户计算设备102、服务器计算系统130和训练计算系统150。
用户计算设备102可以是任何类型的计算设备,诸如例如,个人计算设备(例如,膝上型电脑或桌上型电脑)、移动计算设备(例如,智能电话或平板电脑)、游戏控制台或控制器、可穿戴计算设备、嵌入式计算设备或任何其他类型的计算设备。
用户计算设备102包括一个或多个处理器112和存储器114。一个或多个处理器112可以是任何合适的处理设备(例如,处理器核、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或可操作地连接的多个处理器。存储器114可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存存储器设备、磁盘等、以及它们的组合。存储器114可以存储数据116和由处理器112运行以使用户计算设备102执行操作的指令118。
在一些实施方式中,用户计算设备102可以存储或包括一个或多个机器学习模型120。例如,机器学习模型120可以是或可以以其他方式包括各种机器学习模型,诸如神经网络(例如,深度神经网络)或其他类型的机器学习模型,包括非线性模型和/或线性模型。神经网络可以包括前馈神经网络、递归神经网络(例如,长期短期记忆递归神经网络)、卷积神经网络或其他形式的神经网络。
在一些实施方式中,一个或多个机器学习模型120可以通过网络180从服务器计算系统130接收,存储在用户计算设备存储器114中,然后由一个或多个处理器112使用或以其他方式实施。在一些实施方式中,用户计算设备102可以实施单个机器学习模型120的多个并行实例。
附加地或可替代地,一个或多个机器学习模型140可以被包括在服务器计算系统130中或由服务器计算系统130以其他方式存储和实施,服务器计算系统130根据客户端-服务器关系与用户计算设备102通信。例如,机器学习模型140可以由服务器计算系统140实施为web服务的一部分。因此,可以在用户计算设备102处存储和实施一个或多个模型120和/或可以在服务器计算系统130处存储和实施一个或多个模型140。
用户计算设备102还可以包括接收用户输入的一个或多个用户输入组件122。例如,用户输入组件122可以是对用户输入对象(例如,手指或触笔)的触摸敏感的触敏组件(例如,触敏显示屏或触摸板)。触敏组件可以用于实施虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘或用户可以通过其提供用户输入的其他装置。
服务器计算系统130包括一个或多个处理器132和存储器134。一个或多个处理器132可以是任何合适的处理设备(例如,处理器核、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或可操作地连接的多个处理器。存储器134可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存存储器设备、磁盘等、以及它们的组合。存储器134可以存储数据136和由处理器132运行以使服务器计算系统130执行操作的指令138。
在一些实施方式中,服务器计算系统130包括一个或多个服务器计算设备或由一个或多个服务器计算设备以其他方式实施。在服务器计算系统130包括多个服务器计算设备的情况下,这样的服务器计算设备可以根据顺序计算架构、并行计算架构或他们的某种组合来操作。
如上所述,服务器计算系统130可以存储或以其他方式包括一个或多个机器学习模型140。例如,模型140可以是或可以以其他方式包括各种机器学习模型。示例机器学习模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、递归神经网络和卷积神经网络。
用户计算设备102和/或服务器计算系统130可以经由与通过网络180通信地耦合的训练计算系统150的交互来训练模型120和/或140。训练计算系统150可以与服务器计算系统130分离,或者可以是服务器计算系统130的一部分。
训练计算系统150包括一个或多个处理器152和存储器154。一个或多个处理器152可以是任何合适的处理设备(例如,处理器核、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是一个处理器或可操作地连接的多个处理器。存储器154可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存存储器设备、磁盘等、以及它们的组合。存储器154可以存储数据156和由处理器152运行以使训练计算系统150执行操作的指令158。在一些实施方式中,训练计算系统150包括一个或多个服务器计算设备或由一个或多个服务器计算设备以其他方式实施。
训练计算系统150可以包括模型训练器160,模型训练器160使用各种训练或学习技术(诸如例如误差的反向传播)训练存储在用户计算设备102和/或服务器计算系统130中的机器学习模型120和/或140。在一些实施方式中,执行误差的反向传播可以包括执行随时间截断的反向传播。模型训练器160可以执行多种泛化技术(例如,权重衰减、丢失等)以改善正在训练的模型的泛化能力。
具体地,模型训练器160可以基于一组训练数据162训练机器学习模型120和/或140。模型训练器160可以执行本文描述的任何解相关技术。
在一些实施方式中,如果用户已经提供了同意,则训练示例可以由用户计算设备102提供。因此,在这样的实施方式中,提供给用户计算设备102的模型120可以由训练计算系统150在从用户计算设备102接收的用户特定数据上训练。在某些情况下,该过程可以被称为个性化模型。
模型训练器160包括用于提供所期望的功能的计算机逻辑。模型训练器160可以在控制通用处理器的硬件、固件和/或软件中实施。例如,在一些实施方式中,模型训练器160包括存储在存储设备上、加载到存储器中并由一个或多个处理器运行的程序文件。在其他实施方式中,模型训练器160包括一组或多组计算机可运行指令,其存储在有形计算机可读存储介质中,诸如RAM硬盘或者光学或磁性介质。
网络180可以是任何类型的通信网络,诸如局域网(例如,内联网)、广域网(例如,互联网)或其一些组合,并且可以包括任何数量的有线或无线链接。通常,网络180上的通信可以使用各种的通信协议(例如,TCP/IP、HTTP、SMTP、FTP)、编码或格式(例如,HTML、XML)和/或保护方案(例如,VPN、安全HTTP、SSL)经由任何类型的有线和/或无线连接来实现。
图1A示出了可以用于实施本公开的一个示例计算系统。也可以使用其他计算系统。例如,在一些实施方式中,用户计算设备102可以包括模型训练器160和训练数据集162。在这样的实施方式中,模型120可以被训练并且在用户计算设备102处被本地使用两者。在一些这样的实施方式中,用户计算设备102可以实施模型训练器160以基于用户特定数据来个性化模型120。
图1B描绘了根据本公开的示例实施例执行的示例计算设备10的框图。计算设备10可以是用户计算设备或服务器计算设备。
计算设备10包括多个应用(例如,应用1到N)。每个应用都包含自己的机器学习库和(多个)机器学习模型。例如,每个应用可以包括机器学习模型。示例应用包括文本消息传递应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。
如图1B中所示,每个应用可以与计算设备的多个其他组件(诸如例如,一个或多个传感器、上下文管理器、设备状态组件和/或附加组件)通信。在一些实施方式中,每个应用可以使用API(例如,公共API)与每个设备组件通信。在一些实施方式中,每个应用使用的API特定于该应用。
图1C描绘了根据本公开的示例实施例执行的示例计算设备50的框图。计算设备50可以是用户计算设备或服务器计算设备。
计算设备50包括多个应用(例如,应用1到N)。每个应用都与中央智能层通信。示例应用包括文本消息传递应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实施方式中,每个应用可以使用API(例如,跨所有应用的公共API)与中央智能层(以及存储在其中的(多个)模型)通信。
中央智能层包括多个机器学习模型。例如,如图1C所示,可以为每个应用提供相应的机器学习模型(例如,模型)并由中央智能层管理。在其他实施方式中,两个或多个应用可以共享单个机器学习模型。例如,在一些实施方式中,中央智能层可以为所有应用提供单个模型(例如,单个模型)。在一些实施方式中,中央智能层被包括在计算设备50的操作系统内或由计算设备50的操作系统以其他方式实施。
中央智能层可以与中央设备数据层通信。中央设备数据层可以是计算设备50的集中数据存储库。如图1C所示,中央设备数据层可以与计算设备的多个其他组件(诸如例如一个或多个传感器、上下文管理器、设备状态组件和/或附加组件)通信。在一些实施方式中,中央设备数据层可以使用API(例如,私有API)与每个设备组件通信。
附加公开
本文讨论的技术参考服务器、数据库、软件应用和其他基于计算机的系统,以及这些系统所采取的动作和发送到这些系统和从这些系统发送的信息。基于计算机的系统固有的灵活性允许组件之间各种可能的配置、组合以及任务和功能的划分。例如,本文讨论的过程可以使用单个设备或组件或组合工作的多个设备或组件来实施。数据库和应用可以在单个系统上实施或者可以跨多个系统分布。分布式组件可以顺序或并行操作。
虽然已经关于本主题的各种具体示例实施例详细描述了本主题,但是每个示例是通过解释而非限制本公开来提供的。在获得对前述内容的理解之后,本领域技术人员可以容易地产生对这些实施例的改变、变化和等同物。因此,本主题公开内容并不排除对本主题的这些修改、变化和/或增加的包括,这对于本领域普通技术人员来说是显而易见的。例如,作为一个实施例的一部分示出或描述的特征可以与另一个实施例一起使用,以产生又一个实施例。因此,本公开旨在覆盖这些改变、变化和等同物。
- 还没有人留言评论。精彩留言会获得点赞!