一种污染物排放超标车辆判断方法及系统与流程
本发明涉及排污监控技术领域,特别涉及一种污染物排放超标车辆判断方法及系统。
背景技术:
遥感监测技术于20世纪80年代后期由丹佛大学的feat(fuelefficiencyautomobiletest)项目中发展起来,这种技术可测量通过车辆的尾气烟羽中污染物与co2的浓度比。最初遥感技术仅能测量co与co2的浓度比,其目的是识别co排放高的车辆,随后研究者开发了对于hc,no,pm(用颗粒不透光度表示),no2,so2和nh3的检测功能。其原理都是利用尾气中的不同成分对不同波长的红外线或紫外线的吸收作用,从而计算其浓度。
虽然遥感监测技术主要是为筛查高排放污染源而开发的,但是这方面的研究却非常有限,其中的大多数研究是在美国进行的。早期研究(1997年及更早)主要依靠测量co,评估遥感监测的有效性和准确性。总体来说大多数关于高排放车筛查的研究都使用排放百分比(%或ppm)描述排放限值。
但是,绝对排放百分比是从测量的浓度百分比计算出来的,该计算过程基于一个关键的假设,即没有氧气残留在尾气中。这一假设对于传统的汽油车来说是可满足的,但对于柴油车和现代的直喷式分层充电汽油车来说这一假设是不成立的。此外,虽然有些研究根据年限的不同为车辆设定不同的排放限值,但是未考虑道路环境及驾驶条件(例如坡度、速度、加速度),因此对所有的车辆使用固定的排放限值仍然存在其局限性。
最近一些研究提出了更为复杂的筛选策略,park和rakha提出了一种确定排放限值的模型,该模型考虑车辆速度、加速度以及车辆年份、重量和发动机尺寸。该模型对于识别高hc-co排放和高hc-co-no排放的车辆是有效的,但对于高no排放和高co排放车辆需要进一步改进。rakha等人(2010)开发了一种根据遥测设备获取的浓度比和由vt-micro模型预测的燃料消耗率来计算污染物排放质量的新方法,其中考虑了车辆的类型、速度、加速度、年份和发动机尺寸。这种方法显示了当前高排放车筛选方法的改进。
神经网络模型虽具有强大的学习能力来揭示多变量之间的非线性关系,然而在对于高污染排放源的判定中,在神经网络训练阶段,由于排放超标的样本数量大大少于正常排放的样本数量,也就是说训练数据集是非常不平衡的,这种情况下分类算法倾向于将样本数量少的类别的样本错误地分到样本数量多的类别中,从而导致对高排放污染源的判别错误。
技术实现要素:
本发明的目的在于提供一种污染物排放超标车辆判断方法及系统,以在训练样本数量少的前提下,保证高排放污染源判别的准确性。
为实现以上目的,本发明采用一种污染物排放超标车辆判断方法,包括如下步骤:
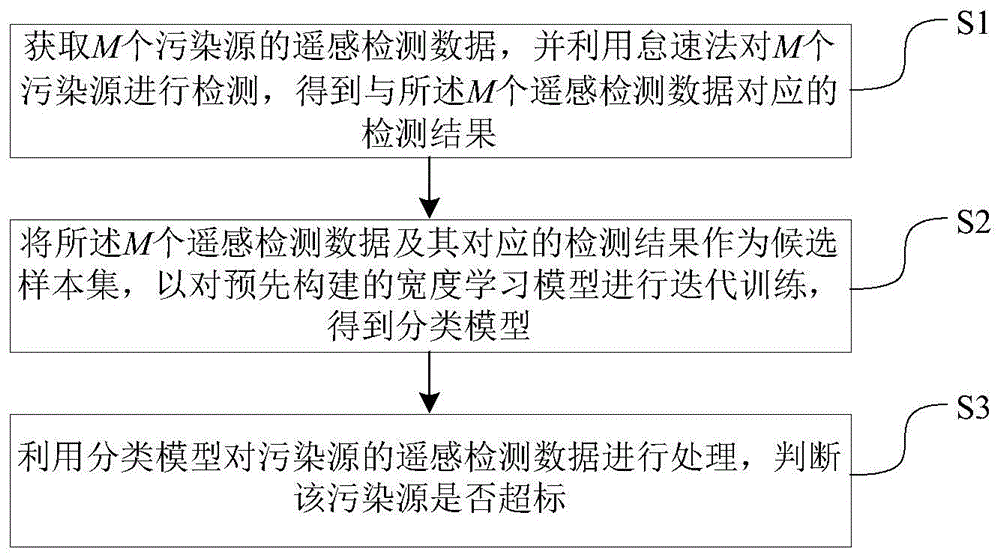
获取m个污染源的遥感检测数据,并利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果;
将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型;
利用分类模型对污染源的遥感检测数据进行处理,判断该污染源是否超标。
进一步地,所述将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型,包括:
从所述候训样本集中随机选取部分数据作为训练集,余下数据作为测试集;
利用训练集中的训练数据对预先构建的宽度学习模型进行迭代训练,得到训练后的模型;
利用测试集中的测试数据对所述训练后的模型进行测试,得到所述分类模型。
进一步地,在所述获取m个污染源的遥感检测数据之后,还包括:
对所述获取的m个污染源的遥感检测数据进行标准化处理;
相应地,利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果。
进一步地,所述宽度学习模型为基于代价敏感宽度学习模型,该模型的代价敏感的损失函数为:
其中,e表示代价敏感的损失函数,1≤j≤a,a表示所述训练集中训练数据的总数量,
进一步地,还包括:
计算所述训练后的模型在所述训练集上的分类正确率,作为第一分类正确率;
计算所述分类模型在所述测试集上的分类正确率,作为第二分类正确率;
根据第一分类正确率和第二分类正确率,判断所述训练后的模型是否存在过拟合或者欠拟合;
若是,则调整所述预先构建的宽度学习模型中的超参数取值,并重新执行所述利用训练集中的训练数据对构建的宽度学习模型进行迭代训练,得到训练后的模型。
另一方面,提供一种污染物排放超标车辆判断系统,包括数据获取模块、检测模块、训练模块以及判断模块;
数据获取模块用于获取m个污染源的遥感检测数据;
检测模块用于利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果;
训练模块用于将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型;
判断模块用于利用分类模型对污染源的遥感检测数据进行处理,判断该污染源是否超标。
进一步地,所述训练模块包括选取单元、训练单元和测试单元;
选取单元用于从所述候训样本集中随机选取部分数据作为训练集,余下数据作为测试集;
训练单元用于利用训练集中的训练数据对预先构建的宽度学习模型进行迭代训练,得到训练后的模型;
测试单元用于利用测试集中的测试数据对所述训练后的模型进行测试,得到所述分类模型。
进一步地,还包括标准化模块,其用于对所述获取的m个污染源的遥感检测数据进行标准化处理。
进一步地,所述宽度学习模型为基于代价敏感宽度学习模型,该模型的代价敏感的损失函数为:
其中,e表示代价敏感的损失函数,1≤j≤a,a表示所述训练集中训练数据的总数量,
进一步地,还包括第一计算模块、第二计算模块、拟合判断模块和超参数调整模块;
第一计算模块用于计算所述训练后的模型在所述训练集上的分类正确率,作为第一分类正确率;
第二计算模块用于计算所述分类模型在所述测试集上的分类正确率,作为第二分类正确率;
拟合判断模块用于根据第一分类正确率和第二分类正确率,判断所述训练后的模型是否存在过拟合或者欠拟合;
超参数调整模块用于在所述拟合判断模块的判断结果为是时,调整所述预先构建的宽度学习模型中的超参数取值,并重新执行所述利用训练集中的训练数据对构建的宽度学习模型进行迭代训练,得到训练后的模型。
与现有技术相比,本发明存在以下技术效果:本发明通过利用污染源的遥感检测数据及其对应的检测结果,对宽度学习模型进行训练,得到分类模型,用于对当前获取的污染源遥感检测数据进行分类处理,得到污染源是超标或者合格的分类结果。通过采用宽度学习模型,不仅可在样本数量大大减少的情况下保证对污染源判定结果的准确性,还提高了模型的训练速度。
附图说明
下面结合附图,对本发明的具体实施方式进行详细描述:
图1是一种污染物排放超标车辆判断方法的流程示意图;
图2是另一种污染物排放超标车辆判断方法的流程示意图;
图3是一种污染物排放超标车辆判断系统的结构示意图。
具体实施方式
为了更进一步说明本发明的特征,请参阅以下有关本发明的详细说明与附图。所附图仅供参考与说明之用,并非用来对本发明的保护范围加以限制。
如图1所示,本实施例公开了一种污染物排放超标车辆判断方法,包括如下步骤s1至s2:
s1、获取m个污染源的遥感检测数据,并利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果;
需要说明的是,污染源的遥感检测数据包括co浓度、hc浓度和no浓度等,遥感数据的检测条件包括一定的温度、相对湿度、风速和风向等。
s2、将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型;
其中,预先构建的宽度学习模型包括7个输入神经元,分别表示遥感检测结果的co浓度、hc浓度、no浓度、温度、相对湿度、风速和风向,特征节点有10组,每组包括5个神经元,增强节点数量为20。
s3、利用分类模型对当前获取的污染源的遥感检测数据进行处理,判断该污染源是否超标。
进一步地,在上述步骤获取m个污染源的遥感检测数据之后,还包括:
对所述获取的m个污染源的遥感检测数据进行标准化处理,标准化处理的方法如下:
v=(1-(-1))×(u-umin)/(umax-umin)+(-1),
其中,u表示数据原始值,v表示标准化处理后的数据值,umin和umax分别表示该数据维度中的最小值和最大值。
相应地,利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果。
需要说明的是,通过标准化将各数据维度的范围统一,从而可以提升模型训练速度和模型效果。
相应地,在上述步骤s3中,将污染源的遥感检测数据进行标准化处理后,利用分类模型对标准化处理后的数据进行处理,得到车辆的排污状态。
具体地,数据标准化处理之后,用x={x1,x2,…,xm}表示,其中xi,i=1,2,…,m表示第i个污染源的遥感检测数据,m表示收集到的污染源遥感检测数据总量。利用怠速法对标准化处理后的遥感检测数据进行处理,得到各污染源的排放状态用y={y1,y2,…,ym}表示,其中yi为第i个污染源的遥感检测数据xi对应的检测结果,检测结果为超标或合格,将检测结果为“超标”用1表示,将检测结果为“合格”用-1表示。然后将{(x1,y1),(x2,y2),…,(xm,ym)}作为所述候选样本集。
进一步地,上述步骤s2:将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型,包括如下细分步骤s21至s23:
s21、从所述候训样本集中随机选取部分数据作为训练集,余下数据作为测试集;
具体地,在候选样本集{(x1,y1),(x2,y2),…,(xm,ym)}中随机选择部分数据作为训练集tr,tr中训练数据的下标用r1,r2,…,ra表示,a表示训练集中训练数据的总数,余下的数据构成测试集te,te中的测试数据的下标用e1,e2,…,eb表示,b表示测试集中测试数据的总数,b=m-a。
s22、利用训练集中的训练数据对预先构建的宽度学习模型进行迭代训练,得到训练后的模型;
s23、利用测试集中的测试数据对所述训练后的模型进行测试,得到所述分类模型。
进一步地,宽度学习模型为基于代价敏感宽度学习模型,该模型的代价敏感的损失函数为:
其中,e表示代价敏感的损失函数,1≤j≤a,a表示所述训练集中训练数据的总数量,
将训练集中的遥感检测数据
需要说明的是,本实施例通过设计代价敏感的损失函数,利用基于代价敏感的宽度学习模型,使用污染源的遥感检测数据及其检测结果对其进行训练,由于在损失函数中检测结果为“超标”的数据其权重是检测结果为“合格”的数据的10倍,即模型对于将“超标”误分类为“合格”这样的分类错误施以更大的惩罚力度,因此在训练过程完成后得到的模型就更少地出现将超标车辆误判为合格车辆的错误,则利用训练得到的分类模型对当前获取的污染源的遥感检测数据进行处理,可以大大降低污染排放超标车辆的漏检率,以增强相关部门对污染排放超标车辆的检查能力。
进一步地,如图2所示,本实施例在上述实施例公开的内容的基础上,还包括如下步骤:
计算所述训练后的模型在所述训练集上的分类正确率,作为第一分类正确率;即当训练迭代次数达到预设的最大迭代次数时,通过以下公式计算模型在训练集上的第一分类正确率:
计算所述分类模型在所述测试集上的分类正确率,作为第二分类正确率;即将测试集数据输入训练出来的模型,得到该模型在测试集上的第二分类正确率:
根据第一分类正确率和第二分类正确率,判断所述训练后的模型是否存在过拟合或者欠拟合,如果第一分类正确率过低,如低于80%,则判断存在欠拟合现象,若第一分类正确率和第二分类正确率的差值较大,如大于10%,则判断存在过拟合现象;
若是,则调整所述预先构建的宽度学习模型中的超参数取值,具体如下:若存在欠拟合现象,则增加模型中特征节点或增强节点数量,若存在过拟合现象,则适当减少模型中特征节点或增强节点数量,然后重新执行所述利用训练集中的训练数据对宽度学习模型进行迭代训练,得到训练后的模型;
若否,则将该训练后的模型作为最终的分类模型。
如图3所示,本实施例公开了一种污染物排放超标车辆判断系统,包括数据获取模块10、检测模块20、训练模块30以及判断模块40;
数据获取模块10用于获取m个污染源的遥感检测数据;
检测模块20用于利用怠速法对m个污染源进行检测,得到与所述m个遥感检测数据对应的检测结果;
训练模块30用于将所述m个遥感检测数据及其对应的检测结果作为候选样本集,以对预先构建的宽度学习模型进行迭代训练,得到分类模型;
判断模块40用于利用分类模型对污染源的遥感检测数据进行处理,判断该污染源是否超标。
进一步地,还包括标准化模块,其用于对所述获取的m个污染源的遥感检测数据进行标准化处理,数据标准化处理之后,用x={x1,x2,…,xm}表示,其中xi,i=1,2,…,m表示第i个污染源的遥感检测数据,m表示收集到的污染源遥感检测数据总量。利用怠速法对m个污染源进行检测,得到各污染源的排放状态用y={y1,y2,…,ym}表示,其中yi为第i个污染源的遥感检测数据xi对应的检测结果,检测结果为超标或合格,将检测结果为“超标”用1表示,将检测结果为“合格”用-1表示。然后将{(x1,y1),(x2,y2),…,(xm,ym)}作为所述候选样本集。
进一步地,所述训练模块30包括选取单元、训练单元和测试单元;
选取单元用于从所述候训样本集中随机选取部分数据作为训练集,余下数据作为测试集;
训练单元用于利用训练集中的训练数据对预先构建的宽度学习模型进行迭代训练,得到训练后的模型;
测试单元用于利用测试集中的测试数据对所述训练后的模型进行测试,得到所述分类模型。
具体地,在候选样本集{(x1,y1),(x2,y2),…,(xm,ym)}中随机选择部分数据作为训练集tr,tr中训练数据的下标用r1,r2,…,ra表示,a表示训练集中训练数据的总数,余下的数据构成测试集te,te中的测试数据的下标用e1,e2,…,eb表示,b表示测试集中测试数据的总数,b=m-a。
进一步地,宽度学习模型为基于代价敏感宽度学习模型,该模型的代价敏感的损失函数为:
其中,e表示代价敏感的损失函数,1≤j≤a,a表示所述训练集中训练数据的总数量,
将训练集中的遥感检测数据
进一步地,还包括第一计算模块、第二计算模块、拟合判断模块40和超参数调整模块;
第一计算模块用于计算所述训练后的模型在所述训练集上的分类正确率,作为第一分类正确率;即当训练迭代次数达到预设的最大迭代次数时,通过以下公式计算模型在训练集上的第一分类正确率:
第二计算模块用于计算所述分类模型在所述测试集上的分类正确率,作为第二分类正确率;即将测试集数据输入训练出来的模型,得到该模型在测试集上的第二分类正确率:
拟合判断模块40用于根据第一分类正确率和第二分类正确率,判断所述训练后的模型是否存在过拟合或者欠拟合;
超参数调整模块用于在所述拟合判断模块40的判断结果为是时,调整所述预先构建的宽度学习模型中的超参数取值,并重新执行所述利用训练集中的训练数据对构建的宽度学习模型进行迭代训练,得到训练后的模型。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!