主动配电网分布式状态估计的分区方法、介质及设备与流程
本公开属于电力系统领域,涉及一种主动配电网分布式状态估计的分区方法、介质及设备。
背景技术:
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
随着清洁能源以分布式电源的形式接入配电网,传统配电网中出现双向潮流的问题;配电管理系统的升级使得分布式电源、可控负荷等可控资源可以实现主动实时的调控,进而有利于优化配电网的运行情况,被动配电网逐步转变为主动配电网。相较于传统配电网,主动配电网的主要特征体现在其可以通过灵活的网络拓扑结构来管理潮流,以便对局部的可控资源进行主动控制和主动管理。进行主动有效的控制与管理对数据的实时性与精确性有较高要求,即需对配电网的运行状态有实时精确的感知能力。配电网状态估计是感知配电网运行状态的有效途径,根据配电网安装的量测设备获取的实时量测信息以及根据负荷预测或非遥测数据得到的伪量测数据,对量测数据采用合适的滤波方法估计出完整精确可靠的状态信息,为配电管理系统中其他高级应用提供精确的数据支撑。
主动配电网有着网络规模较大、三相不对称问题突出、分布式电源与可控负荷渗透率高等特点,使得配电网状态估计计算规模大;而主动配电网对估计数据的实时性和精确性要求更高,传统的集中式状态估计在计算效率上面临较大挑战,分布式状态估计可以将大规模系统划分为多个小规模的子区域,采用并行或串行的计算架构,有效缩小计算规模,从而提高计算效率。进行分布式状态估计首先需要将主动配电网划分为若干子区域,如何实现高内聚低耦合的配电网分区是进行分布式状态估计的重要基础。分区结果将直接影响分布式状态估计的计算性能,因此研究配电网的优化分区有重要意义。
据发明人了解,目前的主动配电网分布式状态估计的分区方法存在以下问题:
(1)没有考虑同步相量量测单元(phasormeasurementunit,pmu)对主动配电网分布式状态估计的影响;
(2)没有给出适用于主动配电网分布式状态估计的分区原则;
(3)没有给出针对主动配电网分布式状态估计的分区方法。
技术实现要素:
本公开为了解决上述问题,提出了一种主动配电网分布式状态估计的分区方法、介质及设备,本公开根据主动配电网及其分布式状态估计的特点,给出分区原则,包括子区域数目、子区域均衡性与子区域连通性、可观性;基于拓扑分析及同步相量量测单元的配置情况提出适用于分布式状态估计的分区方法,依据分区原则实现主动配电网的合理分区。
根据一些实施例,本公开采用如下技术方案:
一种主动配电网分布式状态估计的分区方法,包括以下步骤:
分析主动配电网的拓扑结构,采用分支线分层法实现支路分层并实现节点编号;
采用树的深度优先搜索算法对完成编号的配电网进行后序遍历,根据分区原则以配置同步相量量测单元的节点作为重叠节点实现配电网分区;
在重叠节点处对配电网进行子区域解耦,相应的支路功率量测数据转化为虚拟注入功率量测数据,对解耦后的配电网进行分布式状态估计。
作为可能的实施方式,利用分支线分层法,在配电网选定一条主馈线,该馈线支路层数为1;与主馈线相连的支路其层数为2;以此类推实现所有支路的分层。
作为可能的实施方式,所述支路分层实现节点编号具有至少四个元素,分别代表系统的节点原始编号,该节点所在分支线的层次编号,该节点所在分支线上的节点编号,该节点是否安装同步相量量测单元的表示编号。
作为可能的实施方式,所述分区原则根据分布式状态估计并行计算的特点及分区对分布式状态估计计算性能的影响得到。
作为可能的实施方式,所述分区原则具体包括合理子区域数目、子区域连通性与可观性以及子区域节点数目均衡性及量测冗余度均衡性。
作为可能的实施方式,所述遍历搜索的过程包括:
(1)选择搜索起始节点;
(2)从初始搜索节点出发按照后序遍历顺序搜索,至安装同步相量量测单元的节点时,暂停搜索并判断上述已搜索的节点是否可以组成一个子区域,即判断已搜索节点数目是否在给定范围内,若节点数目小于设定值,则继续向前搜索,否则上述节点形成多个子区域;
(3)配置同步相量量测单元的节点保留,再次选择搜索起始节点;
(4)重复步骤(1)至(3),直至所有节点遍历完成。
作为可能的实施例,在配置同步相量量测单元的重叠节点处对配电网进行子区域解耦,该节点也被称为边界节点,用于分布式状态估计中的信息交互;相应的支路功率转化为解耦之后边界节点的虚拟注入功率。
作为可能的实施例,利用并行计算方法进行配电网分布式状态估计。
一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行所述的主动配电网分布式状态估计的分区方法。
一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行所述的主动配电网分布式状态估计的分区方法。
与现有技术相比,本公开的有益效果为:
本公开考虑了分区对主动配电网分布式状态估计的影响,更加符合实际情况;给出了考虑主动配电网分布式状态估计计算性能的分区原则,综合考虑了分区数目、分区均衡性、可观性与连通性的问题;适用于分布式状态估计的分区方法,具有针对性和有效性。
附图说明
构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的不当限定。
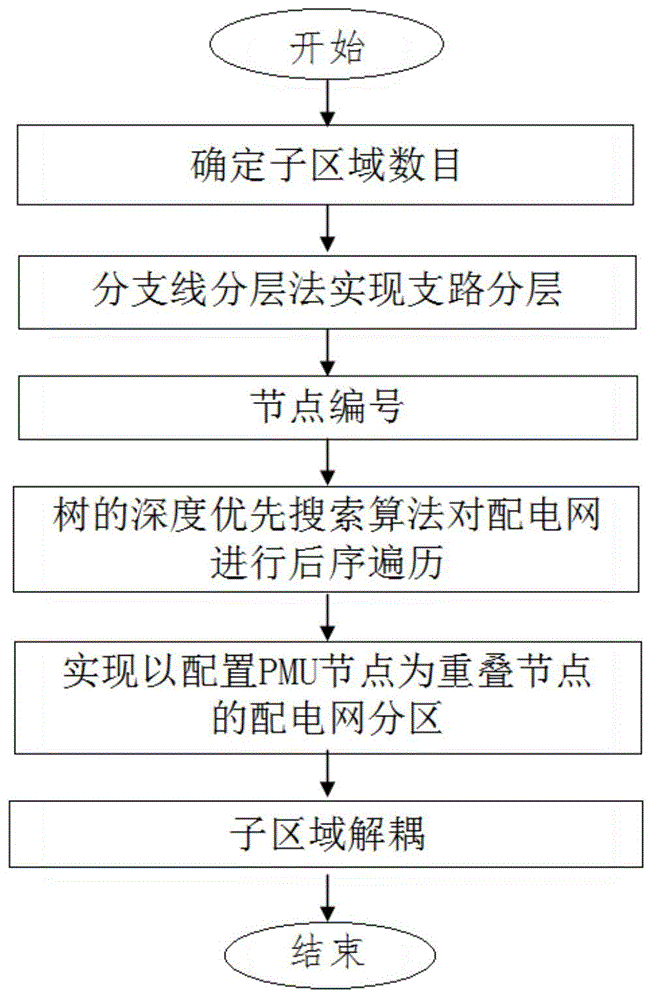
图1本公开提供的主动配电网分区方法流程图;
图2本公开提供的15节点配电网分区过程;
图3本公开提供的15节点配电网子区域解耦过程;
图4本公开提供的分布式状态估计流程图;
图5本公开提供的ieee123节点配电网分区结果;
具体实施方式:
下面结合附图与实施例对本公开作进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本公开提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,适用于主动配电网分布式状态估计的分区方法,包括以下步骤:
(1)首先根据给定的分区原则确定子区域数目;
(2)采用分支线分层法实现配电网各条支路的分层;
(3)根据配电网拓扑结构及分层结果实现节点编号;
(4)采用树的深度优先搜索算法对配电网进行后序遍历;
(5)实现以配置pmu节点为重叠节点的配电网分区;
(6)实现配电网分区后子区域的解耦。
前述步骤(1)中,分区原则包含三方面:
1)合理的子区域数目
随着子区域数目的增加,子区域节点数目减少,子区域进行当地状态估计的计算用时会有缩短;但与此同时,区域数目的增多会加重分布式通信的负担,会对分布式状态估计的整体收敛性造成负面影响,从而影响分布式状态估计的整体计算效率和精度。因此,需要给出一个合理的分区数目。理论分区数目np根据经验公式
2)子区域的连通性与可观性
子区域节点的连通性与可观性是分区后各子区域可以独立且完整的实现当地状态估计的必要前提。配电网拓扑分析方法可以实现配电网网络结构的辨识,可用于判别节点之间是否互联,利用拓扑搜索算法可以保证各子区域节点的连通性。配电网中实时量测数量有限,单纯依靠实时量测无法保证系统的可观性和冗余度,一般进行配电网状态估计时会添加节点注入功率作为伪量测和零注入功率作为虚拟量测,从而保证系统进行状态估计时的可观性和冗余度。配电系统可观性可以采用数值分析或网络拓扑的方法进行判别。数值分析方法是通过判别雅各比矩阵是否满秩,如果满秩则认为该系统是代数可观的;网络拓扑方法是通过拓扑搜索生成量测树,如果量测树能够覆盖全网的所有节点,则认为该系统是拓扑可观的。在本公开中选择利用数值方法对配电网子区域可观性进行判断。除此之外,在保证子区域满足可观性的基础上应尽量使量测冗余均衡。
3)子区域均衡性
分布式状态估计采用并行计算的架构,为了保证各个子区域进行当地状态估计时计算用时以及计算精度的均衡,子区域节点数目与量测冗余度应具有较高均衡性。各子区域独立且同时进行当地状态估计,不同子区域的计算规模不同则计算用时也不同;每一轮的当地状态估计所用时间取决于时间最长的子区域,分布式状态估计的整体计算时间包括当地状态估计用时和子区域间信息交互用时,当地状态估计用时长会为分布式状态估计计算效率带来较大负面影响;为了提高分布式状态估计的计算效率,各个子区域当地状态估计的计算规模应尽量相近,即保证子区域节点数目的均衡性。各个子区域进行当地状态估计的计算精度与其量测冗余度密切相关,子区域间具有较均衡的量测冗余度有利于整体估计的快速满足收敛精度要求,因此应尽量保证子区域量测冗余度的均衡性。
配电网的拓扑为辐射型拓扑,分区时应在保证各个子区域节点的连通性的前提下,尽可能的保证各子区域节点数目与量测冗余度的均衡。本公开中,根据理论分区数np,给出子区域节点数的范围约束nsr,min≤nsr≤nsr,max,其中,nsr,min和nsr,max根据系统节点总数n和分区数的比值给定。
前述步骤(2)中,配电网中各个节点均设有特定编号,编号用于表征该节点的详细信息,包括其在配电网络中所处的具体位置以及是否安装有pmu量测。首先根据分支线分层法按照分支线距离根节点的远近实现配电网的拓扑分层。主馈线为第一层,从主馈线上引出的分支线层次为2,从第二层分支线引出的分支线的层次为3,以此类推直到所有馈线分层完毕。
前述步骤(3)中,各个节点根据其所在位置给出编号(a1,a2,a3,a4),分别代表系统的节点原始编号,该节点所在分支线的层次编号,该节点所在分支线上的节点编号,该节点是否安装pmu量测编号,a4=0代表该节点未安装pmu,a4=1代表该节点安装有pmu。
前述步骤(4)中,利用树的深度优先搜索算法中的后序遍历方法对已编号的配电网进行区域划分,实现以配置pmu的节点作为重叠节点的配电网分区。本公开中采用后序遍历顺序对配电网进行遍历搜索,目的是保证分区后子区域节点的连通性。遍历搜索的初始起点选择分为两种情况:1)对于规模较小,分支线较少的配电系统,主馈线的末端节点为初始搜索起点;2)对于规模大,分支线数量庞大的配电系统,初始搜索起点选择层级最高的分支线末端节点。从初始搜索节点出发按照后序遍历顺序搜索,至安装pmu的节点时,暂停搜索并判断上述已搜索的节点是否可以组成一个子区域,即判断已搜索节点数目是否在给定范围内nsr,min≤nsr≤nsr,max;若小于nsr,min,继续向前搜索,否则上述节点形成
前述步骤(5)中,配电网实现分区后,还需要各个子区域之间解耦才能进行分布式状态估计的计算。在配置pmu的重叠节点处对配电网进行子区域解耦,该节点也被称为边界节点;相应的支路功率转化为解耦之后边界节点的虚拟注入功率。
图2是一个15节点的配电网络,首先进行阶段1:根据分支线分层法可以被划分为3层。完成分层后,各个节点根据其所在位置给出编号(a1,a2,a3,a4)。如图2所示,节点编号为(13,2,1,0),代表原始系统节点编号为13,处于第2层分支线上的第一个节点,该节点上未安装pmu。然后进行阶段2:假设该配电网需要被划分为三个子区域,则每个子区域节点数目范围为;选择主馈线末端节点(7,1,7,0)作为初始搜索节点,搜索路径为(7,1,7,0)-(6,1,6,1)此时判断上述已搜索节点数目共2个,不满足节点数目约束,继续向前搜索,(14,2,2,0)-(15,3,1,0)-(13,2,1,0)-(5,1,5,1),此时判断上述已搜索节点数目共6个,在给定范围内,因此上述节点组成一个子区域;然后,以节点(5,1,5,1)作为起始点按照相同规则继续搜索并实现分区。如图2所示,该配电网以节点(4,1,4,1)、(5,1,5,1)作为重叠节点被划分为三个子区域。
图3给出解耦过程,在配置pmu的重叠节点处对配电网进行子区域解耦,相应的支路功率转化为解耦后边界节点的虚拟注入功率。图中s3-4、s4-5、s4-10分别代表支路3-4、4-5、4-10的复功率;s4代表节点4的注入复功率。需要注意的是,图3中的箭头不代表实际的功率流向。
如图4所示,主动配电网分布式状态估计包括以下步骤:
(1)主动配电网分区解耦;
(2)各子区域采用并行计算架构,利用加权最小二乘法进行当地状态估计;
(3)相邻子区域间进行信息交互,用于判别分布式状态估计是否整体收敛,如果已经收敛,则进行步骤(5),否则进行步骤(4);
(4)交互后的数据作为相邻子区域新增的量测量,转到步骤(2);
(5)记录估计结果。
前述步骤(1)中,主动配电网分区解耦方法采用本公开给出的方法。图4中给出的主动配电网分布式状态估计方法目的是验证本公开提出分区方法的有效性。
图5表明本公开将ieee123节点划分为4个子区域,其对应的各子区域节点数及量测冗余度如表1所示。根据表1可以看出,节点数目及量测冗余度都有较高的均衡性,本公开在给定配电网及其pmu配置的情况下,尽可能均衡的将该配电网划分为合理的子区域。
表1
表2为配电网分布式状态估计结果,将其计算精度与计算时间与集中式状态估计进行对照。其中,rmse为状态估计均方根误差,用于表征状态估计的精度,其计算公式可以表示为
表2
本公开可以为主动配电网分布式状态估计提供合理的分区,分区以配置pmu的节点作为重叠节点,提高了pmu量测在状态估计中的利用率,有利于分布式状态估计计算性能的提升。
综上,首先根据dse算法的特点,给出分区准则,包括节点数目均衡性、量测冗余度均衡性以及分区后的子区域可观性、连通性等;然后利用拓扑分析方法中的分支线分层法实现各节点的分层编号,再利用树的深度优先搜索算法遍历所有节点,依据所提出的分区准则、以配置pmu的节点作为重叠节点实现adn分区和解耦,用于主动配电网的分布式状态估计。
根据分布式状态估计并行计算的特点,分析了分区对分布式状态估计计算精度及效率的影响。随着子区域数目的增加,子区域节点数目减少,子区域进行当地状态估计的计算用时会有缩短;但与此同时,区域数目的增多会加重分布式通信的负担,会对分布式状态估计的整体收敛性造成负面影响,从而影响分布式状态估计的整体计算性能。此外,子区域连通性、均衡性都对分布式状态估计计算性能有较大影响。分区原则包含合理子区域数目、子区域连通性与可观性、子区域节点数目均衡性及量测冗余度均衡性。采用分支线分层法实现配电网分层并对节点进行编号;根据节点编号情况,采用树的深度优先搜索算法对配电网进行后序遍历,依据分区原则实现以配置pmu节点为重叠节点的配电网分区;在配置pmu的重叠节点处对配电网进行子区域解耦,用于分布式状态估计。本公开在分析分区对分布式状态估计影响的基础上,给出分区原则,提出适用于分布式状态估计的分区方法,有利于分布式状态估计计算性能的提升。
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!