一种上下文感知的短语表示学习方法与流程
本发明涉及双语短语的表示学习,尤其是涉及用于统计机器翻译的一种上下文感知的短语表示学习方法。
背景技术:
在传统的统计机器翻译中,由于数据表示的的原因,一方面模型受到数据稀疏的影响,另一方面模型很难建模基本翻译单元之间的语义信息。因此对于统计机器翻译来说,学习基本翻译单元的表示是一个很重要的研究课题。随着深度学习的发展,主流的方法都用低维向量来表示基本翻译单元。在基于短语的统计机器翻译系统中,短语是基本的翻译单元。socheretal.(2010)[1]使用递归神经网络(recursiveneuralnetwork)来联合进行句法分析和短语表示学习两个任务。socheretal.(2011)[2]使用递归自编码器(recursiveautoencoders)用半监督学习的方式来学习短语的表示。mikolovetal.(2013)[3]将短语看成一个词,通过skip-gram模型来学习词的表示。
受到这些单语短语表示学习工作的启发,许多工作提出了双语短语表示的学习方法。gaoetal.(2013)[4]使用一个多层网络将双语短语投射到一个共同的低维空间,然后计算两者在共同空间的相似度作为两者之间的翻译概率。zhangetal.(2014)[5]提出了一个双语限制的递归自编码器(bilingually-constrainedrecursiveautoencoders)用于双语短语的表示学习。这个模型在最小化互为翻译的双语短语之间的距离的同时最大化非对应翻译的短语之间的距离。在训练结束后,该模型能够得到短语对的嵌入表示(embedding),同时学习到了源端短语的目标端短语所在向量空间的变换关系。choetal.(2014)[6]提出了一个基于自编码器的双语短语翻译概率的学习模型。不同的是,编码器和解码器都是一个循环神经网络(recurrentneuralnetwork,rnn)。首先使用一个循环神经网络将源端短语编码成一个固定大小的向量表示(取最后一步的隐状态),然后基于这个源端短语的向量表示,解码器(另外一个循环神经网络)解码出目标短语。通过最大化目标短语的似然概率联合训练编码器和解码器。suetal.(2015)[7]将词对齐信息融入双语短语的表示学习中。由于词对齐信息的加入,该模型能够利用双语短语在短语上的对应关系学习到更好的短语表示。wangetal.(2015)[8]使用神经网络为基于短语的层次机器翻译模型学习非终结符的表示。基于得到的短语表示,模型可以衡量对应短语和非终结符的语义相似性。这些模型的基本思想都是基于平行短语对中源端短语和目标端短语的语义一致性。一方面,现有的模型只考虑短语内部的信息,忽略了上下文信息。另外一方面,上下文信息对短语学习表示来说很重要,相同的短语在不同的上下文中可能有不同的含义。以“bank”为例,当其在上下文是金融相关的时候,那么其对应的翻译很可能是“银行”;当其上下文是景物描述的时候,此时最可能被翻译为“河岸”。
参考文献
[1]richardsocher,christopherdmanning,andrewyng.learningcontinuousphraserepresentationsandsyntacticparsingwithrecursiveneuralnetworks[a].proceedingsofthenips-2010deeplearningandunsupervisedfeaturelearningworkshop[c]..,2010,2010:1–9.
[2]richardsocher,jeffreypennington,erichhuang,etal.semi-supervisedrecursiveautoencodersforpredictingsentimentdistributions[a].proceedingsoftheconferenceonempiricalmethodsinnaturallanguageprocessing[c]..,2011:151–161.
[3]tomasmikolov,ilyasutskever,kaichen,etal.distributedrepresentationsofwordsandphrasesandtheircompositionality[a].advancesinneuralinformationprocessingsystems[c]..,2013:3111–3119.
[4]jianfenggao,xiaodonghe,wen-tauyih,etal.learningsemanticrepresentationsforthephrasetranslationmodel[j].arxivpreprintarxiv:1312.0482,2013.
[5]jiajunzhang,shujieliu,muli,etal.bilingually-constrainedphraseembeddingsformachinetranslation[a].proceedingsofthe52ndannualmeetingoftheassociationforcomputationallinguistics(volume1:longpapers)[c]..,2014,1:111–121.
[6]kyunghyuncho,bartvan
[7]jinsongsu,deyixiong,biaozhang,etal.bilingualcorrespondencerecursiveautoencoderforstatisticalmachinetranslation[a].proceedingsofthe2015conferenceonempiricalmethodsinnaturallanguageprocessing[c]..,2015:1248–1258.
[8]xingwang,deyixiong,minzhang.learningsemanticrepresentationsfornonterminalsinhierarchicalphrase-basedtranslation[a].proceedingsofthe2015conferenceonempiricalmethodsinnaturallanguageprocessing[c]..,2015:1391–1400.
技术实现要素:
本发明的目的在于提供一种上下文感知的短语表示学习方法。
本发明包括以下步骤:
1)基于递归自编码器的短语表示学习;
在步骤1)中,所述基于递归自编码器的短语表示学习的具体方法可为:对于源端短语和目标端短语分别独立使用一个递归自编码器学习起短语表示。
2)上下文建模;
在步骤2)中,所述上下文建模的具体方法可为:将主题看成一个“伪”词,每个主题也像词一样有对应的主题向量表示;用短语所在的文档的主题分布作为短语的主题分布,短语的上下文表示就是各个主题表示的加权和,每个主题的权重是主题分布中对应的概率。
3)主题上下文感知的短语表示;
在步骤3)中,所述主题上下文感知的短语表示的具体方法可为:通过步骤1)和2)可以得到短语的向量表示以及短语的主题上下文表示,将得到的两个向量表示输入到一个一层的全连接网络中得到上下文感知的短语表示。
4)短语对的语义约束;
在步骤4)中,所述短语对的语义约束的具体方法可为:在相同的主题上下文条件下,源端的短语和目标端的平行短语的语义相同,所以两个短语的表示可以互相监督学习,源端的短语可以看成目标端短语的真实表示;反之,目标端的短语也可以看成是源端的短语的真实表示;不过两个短语的表示学习过程是独立的,虽然语义一致,但是可能处在不同的向量空间中,通过将目标端映射到源端,可以计算两者之间的语义距离;反之,也可以将源端的短语映射到目标端的向量空间中,计算两个短语之间的语义距离,由于两个短语的语义是相同的,因此在训练过程中需要最小化两者之间的距离。
5)主题上下文映射;
在步骤5)中,所述主题上下文映射的具体方法可为:在训练的时候可以通过步骤2)中的上下文建模方式得到源端和目标端的主题上下文表示,但是在测试时,只能得到源端的短语的上下文表示,通过学习一个源端到目标端的上下文映射来解决这个问题;由于源端和目标端的主题上下文是相同的,只是由于主题表示处在不同的向量空间中,因此可以通过将源端的上下文表示投射到目标端的上下文向量空间中,通过最小化投射后的上下文表示和目标端的上下文表示来学习主题上下文的映射关系。
6)词-主题语义约束建模。
在步骤6)中,所述词-主题语义约束建模的具体方法可为:文档的主题上下文是通过主题模型得到的,主题模型首先从一个多项式分布中采样一个主题,然后基于这个主题生成一个词;所以词的主题分布可以反映两个词在主题空间中的语义关系;基于这个条件,可以通过主题模型训练的到的词的主题分布来约束模型的训练,从而进一步提高学习到的短语表示质量。
本发明通过扩展双语递归自编码器(bilingually-constrainedrecursiveautoencoders,brae),将上下文信息融入短语表示的学习中,本发明提出两种方式来使用主题信息进行短语表示学习。首先,很直观地,知道短语的语义是与上下文相关的,所以本发明将文档的主题分布作为短语的上下文表示。将主题分布融入到递归自编码器得到的短语表示中,可以得到带有上下文信息的短语表示(上下文可知的短语表示)。其次,由主题模型得到的词的主题分布可以反映词和主题之间的语义关系。如果两个词的主题分布很相似,说明这两个词的语义很接近,那么这两个词的表示也应该要接近。为此本发明设计了一个词和主题的约束模型,使用这些词和主题关系来约束短语和主题的表示学习。
与现有方法相比,本发明具有以下突出的优点:
第一,本发明将短语所在文档的主题分布作为短语的上下文,将其加入到短语的表示学习中,得到上下文感知的短语表示。
第二,本发明利用主题模型得到的词的主题分布来约束词和主题的嵌入表示的学习,进而影响学习到到的短语表示,进一步提高学习到的短语表示的质量。
附图说明
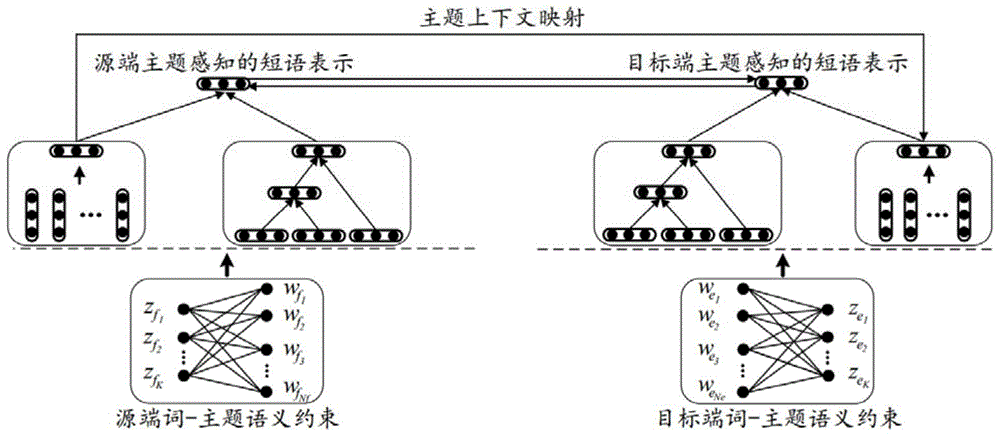
图1为本发明的模型框架图。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
参见图1,本发明的具体实施步骤如下:
1)基于递归自编码器的短语表示学习
模型中包含两个递归自编码器用于学习源端的和目标端的短语表示,以源端为例,假设源端的短语由三个词组成(x1,x2,x3),其对应的向量表示为
y1=f(w(1)[x1;x2]+b[1])
其中,w(1)和b(1)是模型的参数,f是激活函数,本发明中使用tanh(双曲正切),在这里可以将y1看成是由x1和x2组合而成的一个新词。为了衡量学习到的y1的质量,即多大程度上保留了原来的信息,可以从y1还原出x1和x2:
其中,
2)上下文建模
本发明使用文档的主题分布来表示文档中短语的上下文。其中,将每个主题看成一个“词”,每个主题也用n维向量来表示。与词的向量表示一样,所有主题的向量表示也组成一个主题嵌入表示矩阵l∈rn×|z|。由于文档的主题表示是一个在所有主题上的概率分布,根据主题的概率对主题的向量表示进行加权求和得到文档的主题表示:
其中,dc是上下文表示,z表示主题,
3)主题上下文感知的短语表示
通过步骤1)和2)可以得到短语的向量表示p以及短语的主题上下文表示dc。将得到的两个向量表示输入到一个一层的全连接网络中得到上下文感知的短语表示:
pdc=g(w(4)[p;dc]+b[4])
其中,w(4)和b(4)是模型参数。
4)短语对的语义约束
在相同的主题上下文条件下,源端的短语和目标端的平行短语的语义相同。所以两个短语的表示可以互相监督学习,源端的短语表示fdc可以看成目标端短语的真实表示,反之,目标端的短语表示edc也可以看成是源端的短语的真实表示。不过两个短语的表示学习过程是独立的,虽然语义一致,但是他们可能处在不同的向量空间中。通过将目标端映射到源端,可以计算两者之间的语义距离;反之,也可以将源端的短语映射到目标端的向量空间中,计算两个短语之间的语义距离。因为两个短语的语义是相同的,所以在训练过程中需要最小化两者之间的距离。以源端映射到目标端为例,语义距离定义为:
其中,
类似的,也可以得到
5)主题上下文映射
在训练的时候,能够用用上面提到的方法得到短语对(f,e)的上下文表示,用dcf和dce表示短语f和e的主题上下文。由于上下文的获取依赖的是单语的文档,能够利用额外的语料来更好地训练主题模型。值得注意的是,在测试的时候,只能获取源端文档的主题上下文信息。机器翻译是将一段文本从一种自然语言翻译到另外一种自然语言,在翻译后,虽然语义的表达形式发生了变化,但是本质上语义以及主题是保持不变的。同时,由于源端的文本和目标端的文本的主题建模是独立的,那么两个模型的主题分布可能不在相同的向量空间。基于上面的条件,为了获得目标端的主题分布,可以学习一个从源端到目标端的主题上下文的变换关系。具体地,对于平行短语对(f,e)以及他们的主题上下文(dcf,dce),通过最小化变化损失来学习主题上下文的变换关系:
其中,
6)词-主题语义约束建模
文档的主题上下文是通过主题模型得到的,主题模型首先从一个多项式分布中采样一个主题,然后基于这个主题生成一个词。所以词的主题分布可以反映两个词在主题空间中的语义关系。基于这个条件,可以通过主题模型训练的到的词的主题分布来约束模型的训练,从而进一步提高学习到的短语表示质量。具体的,在主题模型训练结束后可以得到词的主题分布。根据最大似然估计,根据主题模型得到词对应的主题信息,定义如下的经验条件分布:
其中,count(w,z)代表主题z采样得到词w的次数。因此,词w和词w'之间的语义关系可以通过他们的经验条件概率分布
其中,
其中,λw是词w对应的权重,用其在训练集中的出现频率表示。上面的约束同时加在源端和目标端。
- 还没有人留言评论。精彩留言会获得点赞!