一种采摘点定位方法与流程
本发明涉及计算机视觉领域,特别涉及一种基于卷积神经网络与密度聚类的野外荔枝采摘点定位方法。
背景技术:
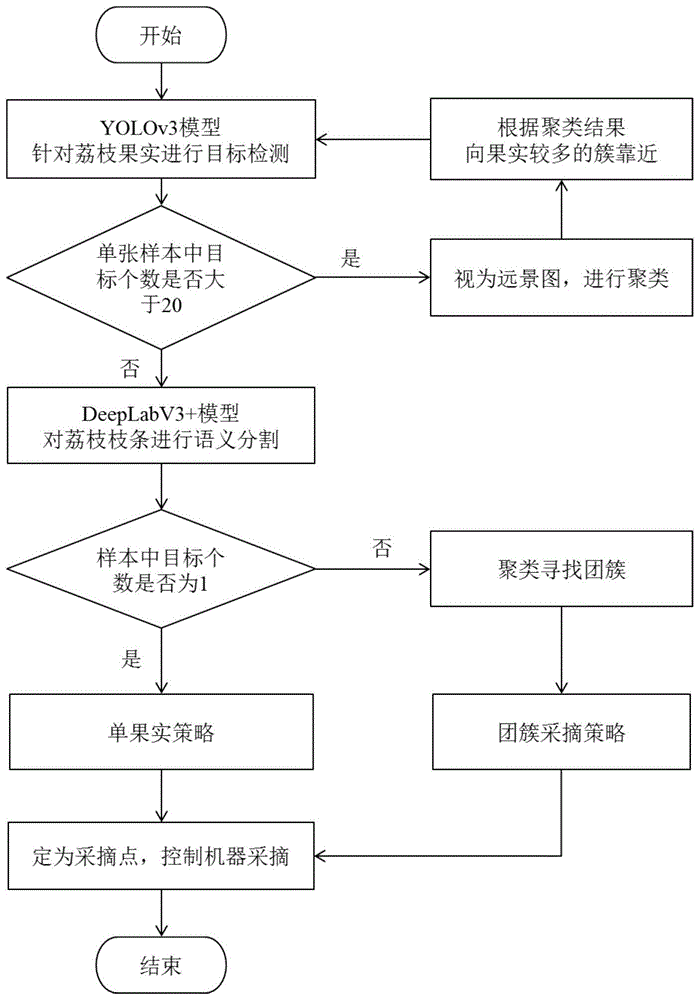
:采摘机器人作为未来蔬果收获工具,能有效解决劳动力不足和劳动成本巨大等问题,通过机械化采摘,能实现全天候采摘、气候干扰下采摘、高效多部同时采摘等人力较难完成的任务,对提高劳动效率,减少劳动成本,加快农业发展具有极其重要的意义。自动化蔬果采摘机器人,通过机械自动化手段来解决蔬果采摘过程中的费时、费力、费钱的问题。其中蔬果果实采摘点的选取和定位,作为蔬果采摘机器人的重要组成部分,在整个机械化环节中占据其重要地位。目前荔枝等串果的采摘大多是采用传统的机器学习算法,进行单目标的采摘。这类装置的缺点是检测精度较低,寻找剪切式采摘点较为困难,且采摘效率不高。因此,需要提供一种检测较为精准,针对串果采摘的较为高效的装置及方法。技术实现要素:本发明的目的在于克服现有技术的缺点与不足,提供一种采摘点定位方法,此方法可实现对成熟串果进行无损伤采摘,通过算法精确寻找定位其剪切点位置,实现果实剪切式采摘,保证了果实的完整与采摘的效率。本发明的目的通过以下的技术方案实现:一种采摘点定位方法,包括以下步骤:获取训练好的yolov3目标检测模型,采集并检测果实生长区域图像,获取检测视野中的果实数量和位置,该模型的特征提取网络采用密集卷积块与残差等结构,实验表明其对荔枝果实具有更强的特征提取能力;判断视野中果实数量,并根据数量判断图像为远景图和近景图;对近景图采用语义分割模型进行枝条分割(即针对图像中的所有像素进行分类,用于区分枝条与背景,也称为语义分割),获得枝条分割图像;对远景图则再进行目标检测;判断枝条分割图像中的果实数量是否为1,若为1则使用单果实采摘策略,若不为1则采用多果实采摘策略;获取最终采摘定位点。优选的,所述yolov3目标检测模型由以下步骤训练得出:对采集的图像进行数据标注,对果实使用labelimg标注;对标注的图像进行分类,按7:3的比例分出训练集与测试集,训练集用来训练神经网络检测模型,测试集用来评估训练出的模型鲁棒性的强弱;使用训练集数据运用yolov3目标检测算法进行神经网络权重训练,并对训练结果使用测试集进行模型评估,调整训练参数,训练获得yolov3目标检测模型。该模型为融合密集连接与残差思想的特征提取网络ournet,解决了果实重叠遮挡情况下的识别率较低、定位较难的问题。更进一步的,对采集到的图像进行压缩处理,减少不必要的存储空间。优选的,所述语义分割模型由以下步骤训练得出:对采集的图像样本进行数据标注,采用labelme标注,标注所需检测枝条;对标注图像进行分类,按7:3的比例分出训练集与测试集,训练集用来训练神经网络分割模型,测试集用来评估训练出的模型鲁棒性的强弱;使用训练集,运用deeplabv3+进行语义分割算法模型训练,对模型进行调参处理,在损失函数中加入正则化项增强模型鲁棒性,运用测试集对模型进行评估,获得枝条语义分割模型。运用deeplabv3+框架,xception_65特征提取网络,对果实枝条实现语义分割,通过编码解码结构大大缩小了运算参数,使用深层语义与浅层语义同权重进行融合,对细节描述有了较大程度的提高。更进一步的,对所述采集的样本图像进行压缩,以减少存储空间。优选的,所述单果实采摘策略为:获取到荔枝果实在图像上的坐标;通过图像语义分割获取到枝条处的像素区域;对目标检测框上方90像素进行区域平移,直至与目标枝条相交处像素值数量大于20,即定义为单目标采摘点。优选的,所述多果实采摘策略为:通过optics聚类与语义分割,选取最外围目标的坐标点为标定聚类的包含框,向上平移搜索图像语义分割的像素,最终获取到采摘点。本发明与现有技术相比,具有如下优点和有益效果:1、本发明选择采用融合密集连接与残差思想的深度学习模型进行目标检测,目标检测精度更高。2、本发明结合精度较高的语义分割网络,对枝条语义进行分割,获取到较为精准到枝条的采摘点定位,在缩小运算参数的同时对细节描述有了较大程度的提高。3、本发明结合聚类算法,分别在远景与近景,多果实与单果实方面分别选取不同策略,提出了较为完整的定位流程,应用范围广。附图说明图1是本发明实施例采摘点定位方法。图2是本发明实施例采摘点定位装置工作情况示意图。图3本发明实施例yolov3_ournet结构图。图4为本发明实施例yolov3目标检测模型训练至理想模型时的损失函数下降曲线图。图5为本发明实施例deeplabv3+模型编码解码检测框架及检测流程示意图。图6为本发明实施例xception65特征提取网络结构图。图7为本发明实施例deeplabv3+模型训练至理想模型时的损失曲线图。其中:1—野外荔枝图像;2—计算机;3—工业相机。具体实施方式为了更好的理解本发明的技术方案,下面结合附图详细描述本发明提供的实施例,但本发明的实施方式不限于此。实施例1如图1所示,一种基于采摘点定位方法,包括四个方面:1.野外荔枝图像采集及数据处理;2.yolo目标检测算法的模型训练;3.deeplab语义分割模型训练;4.optics聚类及相关采摘流程。1、野外荔枝图像采集及数据处理本实验的荔枝图像1分别用工业相机3拍摄,荔枝品种包括桂味、妃子笑、淮枝、糯米糍,天气情况包括雨天、阴天及晴天,拍摄时间为8:00至17:00,各采样数据有较大的差异,便于加强检测网络的鲁棒性及测试难度。由于实验数据过于庞大,会给网络及数据拷贝带来不必要的空间及时间成本,所以在原始数据的基础上,对图片降低分辨率,转换格式压缩,数据总量为4748张,使用labelimg对荔枝果实进行标注,使用labelme对荔枝枝条进行标注。处理后的数据集按照pascalvoc数据集格式整理,按照训练集:测试集=7:3的分割原则,保证数据的随机性,各个集合互斥,保证了后期测试的可靠性。数据分布及压缩状况图如表1所示。表12.yolov3目标检测模型训练野外环境下,由于光照及背景条件复杂且荔枝果实本身重叠遮挡的情况,为荔枝的野外准确检测带来了巨大挑战。针对荔枝采摘机器人在野外作业中果实识别率较低定位较难等问题,提出一种基于yolov3模型改进的目标检测算法,用于对荔枝果实的检测。借鉴残差网络和密集连接卷积思想,提出一个融合密集连接与残差思想的特征提取网络ournet,对野外环境下荔枝的识别具有更强的鲁棒性。所述yolov3目标检测模型训练具体步骤为:使用训练集数据运用yolov3目标检测算法进行神经网络权重训练,并对训练结果使用测试集进行模型评估,调整训练参数,获得较为理想的目标检测模型;本实验采用darknet深度学习框架,硬件设备为cpu采用intercorei7-6700@3.40ghzx8,内存为16gb,gpu选用geforcegtxtitanx显存12g,nvidia驱动版本为390.87,cuda版本选用9.0.176,cudnn7.0.5神经网络加速库,操作系统为linuxubuntu18.04lts,由于darknet深度学习框架为c编写,故本实验的g++与gcc的版本均选用7.3.0,使用500g机械硬盘存储。本实验采用分批次异步随机梯度下降优化处理,使用均方差代价函数,每次送入网络64张图片,分8个批次以减少显存过载导致的模型训练失败;每次传入的图片大小为416x416、3通道的rgb彩色图;动量因子设为0.9;衰减系数设为0.0005;饱和度和曝光度均调整为1.5倍,更容易突出目标物体与背景的特征反差;学习率初始设为0.001;训练最大批次为25000次停止训练,训练策略为在19000批次和23000批次时学习率分别下降0.1,以获得更小损失;选用默认的anchors进行预测,抖动系数设为0.3,用以增大模型的鲁棒性。实验各类网络性能对比如表2所示:表2实验表明:经改进后的算法,获得比经典yolov3算法tiny特征提取网络及darknet53特征提取网络更好的效果,荔枝果实的map为97.07%,高于yolov3_tiny的94.48%的map,且高于经典yolov3的95.18%的map。时间效率上可达到fps为58,同比高于经典yolov3的29fps。当训练集的损失趋于平缓,且测试集的检测精度不再上升,则表明已经达到训练要求。其损失函数下降曲线如图4所示。该模型采用融合密集连接与残差思想的特征提取网ournet,解决了果实重叠遮挡情况下的识别率较低、定位较难的问题。ournet网络结构图如图3所示。3.deeplab语义分割模型训练针对采摘点定位困难的问题,提出采用深度学习图像语义分割算法对荔枝生长枝条进行分割,运用deeplabv3+框架,xception_65特征提取网络对荔枝枝条实现语义分割,通过编码解码结构大大缩小了运算参数,使用深层语义与浅层语义同权重进行融合,对细节描述有了较大程度的提高,提出多孔洞卷积池化;所述deeplab语义分割模型由以下步骤训练得出:使用训练集,运用deeplabv3+进行语义分割算法模型训练,对模型进行调参处理,在损失函数中加入正则化项增强模型鲁棒性,运用测试集对模型进行评估,获得较为理想的枝条分割模型。本实验选用tensorflow深度学习框架,硬件设备为cpu采用intercorei7-6700@3.40ghzx8,内存为16gb,gpu选用geforcegtxtitanx显存12g,nvidia驱动版本为390.87,cuda版本选用9.0.176,cudnn7.0.5神经网络加速库,操作系统为linuxubuntu18.04lts,python版本选用python3.6,tensorflow版本为1.8.0,选用500gb机械硬盘。根据实验机器的硬件配置,采用tensorflow学习框架,先将数据转化为tensorflow独有的二进制tfrecord格式,方便数据读取,整理好的训练集大小为96mb,测试集大小为30mb,使用deeplabv3+语义分割网络,随机梯度下降法进行参数学习,每批次传入网络的样本数量为8张,分别选用了xception_65、xception_41、xception_71等特征提取模型,编码结构使用孔洞为6、12、18的多尺度孔洞金字塔池化,样本裁剪大小为321x321,权重衰退系数为0.00004,训练迭代次数为50000次,控制变量参数基本相同的情况下,进行对比实验。实验表明deeplabv3+使用xception_65特征提取网络获得的效果最佳,达到miou为0.765。同类型模型实验评估如表3所示:表3deeplabv3+模型编码解码检测框架如图5所示。xception65特征提取网络结构采用了深度可分离卷积来降低模型参数,其结构如图6所示。deeplabv3+模型采用负类交叉熵代价函数,当训练集的损失趋于平缓时,表明训练训练达到要求,其损失曲线如图7所示。实验表明,训练后的语义分割模型在不增加参数的情况下减少了由于池化带来的精度损耗,分割获得miou为0.765,远大于其他网络及同架构下其他特征提取网络的分割精度,在同架构下与深度残差网络特征提取网络的模型以及小型网络模型进行对比实验,通过多组对比实验及展示实验,获得较为理想的分割效果。4.optics聚类及相关采摘流程采摘流程为:获取训练好的yolov3目标检测模型,采集并检测果实生长区域图像,获取检测视野中的果实数量和位置;判断视野中果实数量,并根据数量判断图像为远景图和近景图;对近景图采用语义分割模型进行枝条分割,获得枝条分割图像;对远景图则再进行目标检测;判断枝条分割图像中的果实数量是否为1,若为1则使用单果实采摘策略,若不为1则采用多果实采摘策略;获取最终采摘定位点。运用基于密度对初始化参数不敏感的optics聚类算法,结合目标检测网络进行聚类实验,针对远景图果实数量较多采摘机械手距离不够及枝条不明显的情况,采用聚类分区域,拉近距离再检测的方法获得近景图;针对已存在中近景图,分单果与团簇多果两类情况分别进行讨论,并提出相应的采摘点定位算法。梳理总结了采摘思路流程,并对聚类算法针对现有数据样本进行了抽样实验。实验采用含有目标果实2到20个的样本图像100张,经聚类获取到最大外接矩形平移进行寻找采摘点。实验表明,在选取的100张样本中能准确寻找到正确采摘位置的有73张,实验效果较为理想,表4罗列统计部分数据。表4对于单张图像中存在20个果实以上的远景图,由于目标较远,荔枝果梗不易通过视觉方式发现,同时机械手长度有限,影响实际采摘。实验选择通过聚类寻找各个簇,针对单一簇,进行位移,拉近距离再进行分割实验。实验选定存在20到40个果实的样本图像进行聚类,原因是在此区间内拍摄的图像基本拍摄距离相同,便于选取聚类折线图的可达距离阈值。选取样本100张,先经人工标注各个果实团簇的分类,标定完成后设定可达距离阈值为94,对聚类算法获取到的折线图进行划分,最后统计聚类结果。以图像中参与聚类的单个点为单位,采用实际类别与算法预测类别进行对比,若相同则计为准确,反之则视为错误。统计测试集中所有聚类点的对比结果,经统计采用optics聚类算法对100张实验样本中所有果实点的聚类结果可达到93.3%的准确率,表5.5为聚类精度统计相关部分信息。远景聚类准确度统计表如表5所示。表5图像编号果实数实际类别数聚类数准确聚类个数012433240233553303324430043665350534443406265526073776320831333009264426103966391128452512203320133144301422332215294325通过上述步骤获取采摘定位点后,将采摘点位置信息传输给剪切式机械手,进行采摘。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1