一种基于主题信息的类别预测方法及装置与流程
本发明属于文本分类技术领域,特别涉及一种基于主题信息的类别预测方法及装置。
背景技术:
近年来,法院的信息化建设不断完善,截止2018年12月,中国裁判文书网已收录并公布超过5900万篇裁判文书,使用人工智能技术对这些司法大数据进行分析、总结、利用成为热点研究话题。
罪名预测是根据裁判文书中的案情描述,预测合理的罪名,可用于审判前的量刑定罪,也可用于审判后的审判公正性评价,有利于实现“同案同判”,确保公平正义。
罪名预测实质上是司法领域的文本类别预测问题:案情描述文本作为待分类文本,案件对应的罪名是文本对应的分类标签。现有方法是使用tf-idf、卷积神经网络、循环神经网络等方法提取文本的语义特征,再使用分类器对文本语义特征进行分类。但现有方法在进行文本语义特征提取时,仅使用单一的tf-idf统计特征方法或仅使用单一的神经网络方法,造成了严重的语义流失,由此带来的后果是现有分类方法严重依赖于充足的训练数据,且训练数据中每个类别的训练样本数量需平衡。然而,在司法领域,不同类别案件的发生概率存在天然的不平衡现象,导致收录的不同类别案件对应的裁判文书数量存在巨大的差异,例如,“盗窃”、“诈骗”等罪名对应的案例存在数十万个,而“非法收购、运输、出售珍贵、濒危野生动物制品”罪名仅存在几十例。实际上,高频罪名包含的罪名种类仅占所有罪名的少部分,大部分罪名对应的案例数量较少,直接使用现有文本分类方法在司法数据上进行训练,会使得模型倾向于预测高频罪名,实用性有限。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于主题信息的类别预测方法及装置,用于刻画案情描述中各个语义单元与案情整体的语义关联性,识别重要词汇和句子,解决现阶段文本分类方法中语义缺失、无法预测低频罪名等问题,提高司法智能化程度。
为了实现上述目的,本发明采用的技术方案是:
一种基于主题信息的类别预测方法,包括:
获取案情描述文本及对应的罪名,构建训练数据集;
构建神经网络模型,使用主题信息识别重点词语与句子,计算案情描述文本语义向量表示;
使用分类器对案情描述文本语义向量进行罪名类别预测。
所述构建训练数据集,具体包括:
对案情描述文本进行预处理,文本进行分句分词;
去除停用词,去除文档频率过高的词,去除文档频率过低的词;
将分词后案情描述文本按序排列,构建案情描述文本集合,训练词向量模型,将案情描述文本的词汇进行映射,得到词向量序列。
本发明还包括:为每个案情描述文本计算其主题概率分布,作为主题信息指导案情描述文本语义提取过程。
所述构建神经网络,包括:
使用深度神经网络进行词语间语义计算,得到每个词语的隐含表示;
将词语隐含表示和案情描述文本的主题信息作为词语级别注意力机制的输入,计算每个词语与案情描述文本整体语义的关联程度,将词语语义向量融合得到句子的语义向量表示;
使用深度神经网络进行句子间语义计算,得到每个句子的隐含表示;
将句子隐含表示和案情描述文本的主题信息作为句子级别注意力机制的输入,计算每个句子与案情描述文本整体语义的关联程度,将句子语义向量融合得到案情描述文本语义向量。
本发明还包括:使用主题信息作为词语级别注意力机制的输入,由词语语义向量表示计算句子的语义向量表示;使用主题信息作为句子级别注意力机制的输入,由句子语义表征计算案情描述文本语义表示。
本发明还包括:
对于案情描述文本的语义向量,使用分类器计算案情描述文本在所有类别集合上的概率分布;
将案情描述文本预测的类别概率分布与真实的类别概率分布对比,计算单一案情描述文本的神经网络损失函数值;
计算同一个训练批次中所有案情描述文本的损失值的平均值,得到模型的整体损失;
使用神经网络优化算法优化层级神经网络模型参数。
使用优化后模型预测案情描述文本类别。
所述案情描述文本类别预测,具体包括:
选择案情描述文本类别概率分布中概率最大的类别作为最终预测类别。
本发明还提供了一种基于主题信息的类别预测装置,包括:
预处理模块:对给定的案情描述文本进行分句分词,得到词语序列,将词语转化成词向量表示,得到案情描述文本对应的词向量序列,同时使用预训练的主题模型计算案情描述文本的主题概率分布;
句子语义计算模块:使用深度神经网络在句子的词向量矩阵中计算每个词语的隐含表示,使用主题信息作为词语级别注意力机制的输入,计算句子的语义向量表示;
案情文本语义计算模块:使用深度神经网络对案情文本中所有句子的语义向量进行语义计算,得到每个句子的隐含表示,使用主题信息作为句子级别注意力机制的输入,得到案情描述文本的语义向量表示;
类别预测模块:将案情描述文本的语义向量输入到分类器中,预测案件对应的罪名。
所述句子语义计算模块,由词语语义表征经计算得到句子的初步表示,使用主题信息作为词语级别注意力机制的输入。
所述案情文本语义计算模块,由句子的语义表征经计算得到案情描述文本的语义表示,使用主题信息作为句子级别注意力机制的输入。
与现有方法相比,本发明方法的显著优点是:使用案件描述文本的主题信息识别文本中的重点词语与重点句子,避免了文本语义特征提取过程中的语义流失问题,同时避免了文本中冗余、无关信息的干扰,能得到更有效的案件文本语义向量表示,从而能解决罪名预测中低频罪名难预测的问题。
附图说明
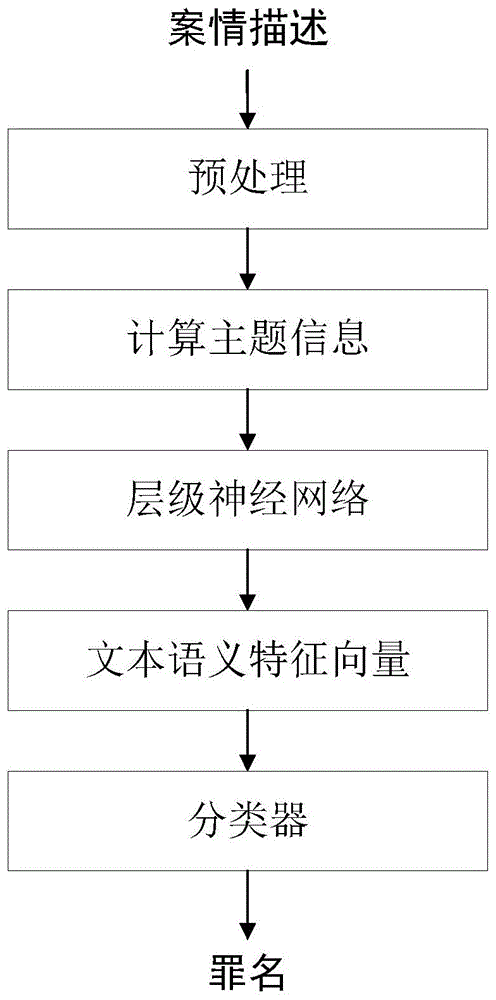
图1为本发明方法流程图。
图2为层级神经网络结构图。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
主题信息是对文本隐式主题语义的表征。主题是对文本语义的总结,使用一个或多个概念词概括文本所表达的内容,主题信息即为文本语义在给定的概念词集合上的概率分布,反映了文本的整体语义。主题信息能有效的缓解文本语义特征提取过程中的语义流失问题,适用于罪名预测过程中重点语义的获取,提高低频罪名的预测准确率。
因此,本发明提出一种基于主题信息的罪名预测分类方法及装置,在层级神经网络的基础上,根据案情描述文本的主题信息刻画每个句子中每个词汇与案情文本整体的关联,同时在进行句子级别的表示时,考虑当前句子与前面句子的语义联系,得到更有效的句子表示,通过案情主题信息确定各个句子的重要性,加权求和得到案情描述的语义向量表示,输入到分类器中预测案件对应的罪名。本方法使用主题信息挖掘案情描述文本中的重点词语与句子,能得到更有效的案情描述文本的语义向量表示,从而在低频罪名预测上达到更好的效果,解决以往方法和装置不能准确的预测低频罪名的问题。
具体参考图1,本发明基于主题信息的罪名预测方法,包括以下步骤:
步骤1:首先获取裁判文书,从裁判文书中提取案情描述文本及其对应的罪名,对案情描述文本进行分句分词,其次去除停用词,去除在5%案情描述文本中都出现的词,即文档频率过高词,去除只在一两个文档中出现的词,即文档频率过低的词,统计剩下的所有词汇及其词频,构建对应的词典。训练词向量模型,得到每个词对应的词向量,并按照句子、词语的顺序排列,构成案情文本的原始词向量表示,最终得到训练数据集。
步骤2:使用步骤1中得到的字典,将案情文本转化成字典表示,输入到主题模型中进行训练,并使用训练后主题模型计算每个案情描述文本的主题分布htopic。
步骤3:构建层级神经网络,参见图2,具体步骤包括:
步骤3.1:句子向量表示
记案情描述文本中第i个句子为li,包含t个词{wi,1,wi,2,...,wi,t,...,wi,t},对应的词向量矩阵为{xi,1,xi,2,...,xi,t,...,xi,t},其中xi,t∈rd,是第i个句子第t个词wi,t对应的词向量。使用双向循环神经网络计算每个词对应的隐藏状态
式中:*——代表矩阵对应元素相乘,即element-wisemultiplication;
xi,t——第i个句子第t个词对应的词向量;
hi,t-1——第i个句子在t-1时刻的模型单元状态;
zi,t、ri,t——分别是第i个句子在t时刻更新门和重置门的输出;
wz、wr——分别是词语级别网络更新门和重置门的权重矩阵;
σ、tanh——分别是sigmoid激活函数和tanh激活函数;
[hi,t-1,xi,t]——拼接操作,将hi,t-1和xi,t按照最后一个维度拼接;
w——词语级别语义变换矩阵;
hi,t——是第i个句子在t时刻的输出,即t时刻的单元状态。
得到句子中所有词语的隐藏状态
式中:hi,t——文档第i个句子第t个词对应的隐藏状态,同时作为词级别注意力机制键值对中的值;
ui,t——词级别注意力机制键值对中的键;
wu、bu——词级别注意力机制键值对中由值到键映射过程中的参数矩阵和偏差项;
htopic——案情描述文本的主题概率分布;
wtopic——主题概率分布的语义映射矩阵,将其映射为词级别注意力机制的查询向量;
ei,t、αi,t——分别是词级别注意力机制计算的语义相关度、归一化权重;
yi——词级别注意力机制的输出,即第i个句子的语义向量表示。
步骤3.2:文档向量表示
得到所有的向量表示
式中:*——代表矩阵对应元素相乘,即element-wisemultiplication;
yi——第i个句子对应的语义向量;
si-1——第i-1个句子对应的隐藏状态;
zi、ri——分别是第i个句子的更新门和重置门的输出;
wzs、wrs——分别是句子级别网络更新门和重置门的权重矩阵;
ws——句子级别语义变换矩阵;
si——第i个句子隐藏状态。
在所有句子的隐藏状态
式中:si——文档第i个句子对应的隐藏状态;
ui——句子级别注意力机制键值对中的键;
wus、bus——句子级别注意力机制键值对中由值到键映射过程中的参数矩阵和偏差项;
htopic——案情描述文本的主题概率分布;
wtopic'——主题概率分布的语义映射矩阵,将其映射为句子级别注意力机制的查询向量;
αi——句子级别注意力机制计算的归一化权重;
c——句子级别注意力机制的输出,即案情描述文本的语义向量表示。
步骤4:将案情描述文本的语义向量表示c输入到分类器中,计算案情描述文本在罪名集合上的概率分布,并与真实罪名概率分布比较,计算交叉熵,将所有案情描述文本的交叉熵求平均得到模型整体的损失,计算方式如下:
式中:probi——第i个案情描述文本预测的罪名概率分布;
labeli——第i个案情描述文本真实的罪名概率分布;
i——文档的索引值;
j——罪名类别的索引值;
n——一个训练批次中案情描述文本的数量;
m——罪名类别的个数;
loss——当前训练批次的模型整体损失。
使用梯度下降算法进行误差反向传播,进行层级神经网络模型参数优化。
本发明提供了一种基于主题信息的罪名预测装置,以案情描述“河南省驻马店市人民检察院指控:被告人柏6某与其妻子枚某因感情不和经常发生争吵。2014年11月8日6时许,二人在家×××住×××,对其侮辱打骂,一直持续至当晚22时许。柏6某被激怒后用拳头击打枚某头面部,又随手从床上拿一手电筒击其头部,后又持铁锤朝枚某头部连夯数下,致枚某倒地昏迷,后经抢救无效死亡。经鉴定,枚某系被他人用钝器作用于头部,致其重型颅脑损伤死亡。”为例,包括以下模块:
预处理模块:将案情描述文本分句分词,得到案情文本的词语集合,转化成tf-idf表示,使用预训练的主题模型计算案情文本的主题分布概率htopic,一个简化的数字化表示为:
htopic=(0.00153841,0.00153841,0.08249629,0.08467486,0.68360263,0.00153841),
使用预训练的skip-gram词向量模型,得到每个词对应的词向量,并按照句子、词语的顺序排列,构成文档的原始词向量表示。对于不在词表和词向量中的词语,使用全零的词向量替代;
句子语义计算模块:按照步骤3.1中公式(1)计算每个句子中每个词语的隐藏状态,再按照步骤3.1中公式(2)计算句子中每个词语的权重,按照权重加权得到每个句子的向量表示;
案情描述文本语义计算模块,按照步骤3.2中公式(3)和(4)依次计算每个句子的隐藏状态和权重大小,按照权重加权得到案情描述文本的语义向量表示;
罪名预测模块:将案情描述文本语义向量表示输入到分类器中,预测案件对应的罪名,可以预测该案件描述中被告人犯“故意杀人罪”。
本说明书中方法与装置实施例基本相似,相关之处可相互参照。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!