一种融合听觉感知特征和视觉特征的中国民歌地域分类方法与流程
本发明属于机器学习与数据挖掘领域,具体涉及一种融合听觉感知特征和视觉特征的中国民歌地域分类方法。
背景技术:
近年来,随着数字音频音乐的增加以及互联网的迅猛发展,具有独特民族风格与浓郁地方色彩的中国民歌开始被更多的人接触、喜欢与研究。然而由于中国民歌一般是即兴编作、口头传唱,不如流派歌曲创作规则明显,民歌的地域风格界限较为模糊,增加了地域识别的难度,因此目前中国民歌的地域识别研究比较少,急需学术界和工业界提出相关新的研究。
听觉感知特征在声学特征的基础上提出,其充分考虑人耳的听觉特性,融入大量的音乐感知信息,能够更贴近人耳与神经系统感知与处理音乐的过程,因此成为音乐分类中重要的特征选择。此外,通过将音乐音频信号转化成语谱图,进而提取视觉特征间接反映音乐节奏、韵律等特点,同样在音乐分类领域具有很大的潜力。听觉感知特征与视觉特征的巨大优势在中国民歌的地域识别的研究中应用的还非常少,尤其是视觉特征几乎没有应用。
技术实现要素:
本发明的目的是解决现有研究中存在的缺乏探究新特征的不足问题,提出了一种融合听觉感知特征和视觉特征的中国民歌地域分类方法,该方法同时提取听觉感知特征与视觉特征对中国民歌进行地域识别,通过前者捕捉民歌中的感知信息,通过后者捕捉民歌中的纹理特征,提高了中国民歌地域分类准确率。
为了达到上述目的,本发明采用如下的技术方案来实现:
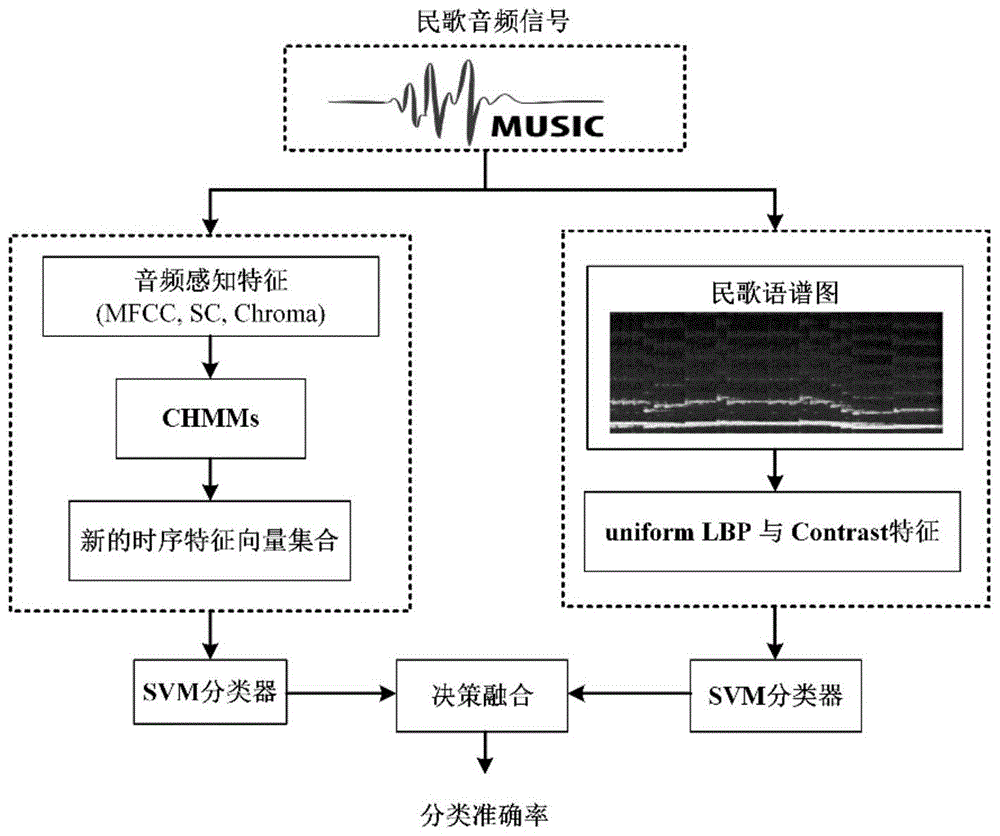
一种融合听觉感知特征和视觉特征的中国民歌地域分类方法,首先,对原始音频信号按帧提取听觉感知特征并进行时序相关性建模;其次,将原始音频信号的整体转化为彩色语谱图提取视觉特征;最后,将提取到的两部分特征进行决策级融合得到最终的分类结果;具体包括以下步骤:
1)听觉感知特征的提取:包括按帧提取音频特征,帧特征时序相关性建模,新的特征向量集合,归一化处理,具体包括以下步骤:
1-1)按帧提取音频特征:针对原始音频信号按帧提取梅尔频率倒谱系数、谱质心及chroma特征作为听觉感知特征;
1-2)帧特征时序相关性建模:采用连续隐马尔科夫模型为每类民歌建立模型,连续隐马尔科夫模型简称chmm模型;
1-3)新的特征向量集合:计算每首民歌对应于所有chmm模型的输出概率,并将这些输出概率组合成新的特征向量集合;
1-4)归一化处理:对得到的新特征向量进行归一化处理,作为最终用于分类的听觉感知特征向量集合;
2)视觉特征的提取:视觉特征的提取过程,包括视觉图像的获取,视觉纹理特征的提取,以及视觉特征的降维处理,具体包括以下步骤:
2-1)视觉图像的获取:将每首民歌的音频信号的整体转化为彩色语谱图,并将每幅彩色语谱图转化为rgb三个颜色通道的灰度图像;
2-2)视觉纹理特征的提取:分别对每个颜色通道的灰度图像提取均匀二值模式和对比度特征,同时考虑对不同颜色通道之间的uniformlbp特征相关性进行计算,考虑contrast特征提取时算子取值离散化问题;
2-3)视觉特征的降维处理:采用概率分析方法来获得不同地域民歌各种颜色通道内lbp特征中差异比较大的模式,然后只保留这些模式,从而达到降维的目的;
3)地域分类器融合:分别将提取到的听觉感知特征、视觉特征输入到各自的支持向量机分类器,对得到的svm分类器分数向量进行融合作为最终的分类结果。
本发明进一步的改进在于,所述步骤1-2)具体操作为:将每首民歌提取的听觉感知特征作为观测向量,采用改进的baum-welch算法训练每个地域民歌的chmm模型;具体步骤如下:
1)chmm的初值选择
chmm的参数训练过程,需要输入初始的模型参数;其中hmm初始状态概率向量初值π0与初始状态转移矩阵a0对模型的建立影响不大,随机给出;而hmm状态数w与gmm模型个数p,则尝试采用不同组合来确定,以寻找最优的chmm模型;gmm的初始参数选择则采取k均值分段算法来设置;
2)chmm参数训练过程
chmm参数训练过程分为以下两步:
e-step:给定观察向量序列
m-step:根据γt(sj)重新估计chmm的参数:计算gmm各模型平均值向量μjm、协方差矩阵∑jm,权重cjm;状态转移概率aij,初始状态概率向量π;各参数表达式如下:
本发明进一步的改进在于,所述步骤1-3)具体操作为:将每首民歌的感知特征作为观察向量采用viterbi算法求出其对应于每个chmm模型的输出概率,然后将其串接成一维向量
本发明进一步的改进在于,所述步骤1-4)将所有歌曲的特征向量作归一化处理,作为听觉感知特征最终的训练向量集合。
本发明进一步的改进在于,所述步骤2-2)具体操作为:首先分别对每个颜色通道的灰度图像进行
本发明进一步的改进在于,所述步骤2-3)采用变异系数cv对相同颜色通道内的相同模式做差异度衡量,cv越大表示在该模式上差异越大,只保留这些差异大的模式,从而达到降维的目的。
本发明具有如下有益的技术效果:
本发明提供的一种融合听觉感知特征和视觉特征的中国民歌地域分类方法,融合听觉感知特征与视觉特征对中国民歌的地域识别。在提取两种特征的时候不仅充分考虑民歌音乐自身的特点,而且还进行了相应的改进。提取感知特征时,充分考虑各帧特征之间的时序关系,首先采用chmm模型对每类民歌建模,然后计算每首民歌对应于各个chmm的输出概率,进而将每首歌曲的听觉感知特征转化为新的特征向量。提取视觉特征时,采用彩色语谱图替代灰度图,以捕捉更多的纹理信息,并且为了更好的表征图像的纹理,不仅考虑纹理的模式,而且还考虑了纹理模式的强度。首先将每首歌曲的音频文件整体转化为彩色语谱图,进而将彩色语谱图转化成rgb三个颜色通道的灰度图像,然后提取视觉特征,并对提取的视觉特征采用变异系数降维。实验表明,本发明不仅可以有效识别不同地域的民歌,而且优于现有的民歌地域识别方法。
附图说明
图1为本发明提出的融合听觉感知特征和视觉特征的中国民歌地域分类整体处理流程图;
图2为本发明中听觉感知特征提取及处理过程示意图;
图3为本发明中视觉特征提取及处理过程示意图。
具体实施方式
下面结合附图对本发明做进一步详细描述:。
参照图1,本发明提供的一种融合听觉感知特征和视觉特征的中国民歌地域分类方法,首先,对原始音频信号按帧提取听觉感知特征,采用改进的baum-welch算法训练每个地域民歌的chmm模型;其次,将原始音频信号的整体转化为彩色语谱图,进而转化成rgb三个颜色通道的灰度图像提取视觉特征,同时采用变异系数降维;最后,分别将提取到的两部分特征输入到各自的svm分类器进行决策级融合,具体包括以下步骤:
1)听觉感知特征的提取:听觉感知特征的提取过程,包括按帧提取音频特征,帧特征时序相关性建模,新的特征向量集合,归一化处理,参照图2,具体包括以下步骤,
step1按帧提取音频特征:针对原始音频信号按帧提取梅尔频率倒谱系数、谱质心及chroma特征作为听觉感知特征;
step2帧特征时序相关性建模:采用连续隐马尔科夫模型(continuoushiddenmarkovmodel,chmm)为每类民歌建立模型,采用改进的baum-welch算法训练每个地域民歌的chmm模型;具体步骤如下:
1)chmm的初值选择
chmm的参数训练过程,需要输入初始的模型参数;其中hmm初始状态概率向量初值π0与初始状态转移矩阵a0对模型的建立影响不大,随机给出;而hmm状态数w与gmm模型个数p,则尝试采用不同组合来确定,以寻找最优的chmm模型;gmm的初始参数选择则采取k均值分段算法来设置;
2)chmm参数训练过程
chmm参数训练过程分为以下两步:
e-step:给定观察向量序列
m-step:根据γt(sj)重新估计chmm的参数:计算gmm各模型平均值向量μjm、协方差矩阵∑jm,权重cjm;状态转移概率aij,初始状态概率向量π;各参数表达式如下:
step3新的特征向量集合:将每首民歌的感知特征作为观察向量采用viterbi算法求出其对应于每个chmm模型的输出概率,然后将其串接成一维向量
step4归一化处理:对得到的新特征向量进行归一化处理,作为最终用于分类的听觉感知特征向量集合;
2)视觉特征的提取:视觉特征的提取过程,包括视觉图像的获取,视觉纹理特征的提取,视觉特征的降维处理,参照图3,具体包括以下步骤,
step1视觉图像的获取:将每首民歌的音频信号的整体转化为彩色语谱图,并将每幅彩色语谱图转化为rgb三个颜色通道的灰度图像;
step2视觉纹理特征的提取:分别对每个颜色通道的灰度图像提取均匀二值模式(uniformlocalbinarypattern,uniformlbp)和对比度(contrast)特征,同时考虑对不同颜色通道之间的uniformlbp特征相关性进行计算,考虑contrast特征提取时算子取值离散化问题;具体分别对每个颜色通道的灰度图像进行
1)针对每一首歌,从g通道灰度图像中取一个像素点a,其像素值为
2)针对a点的像素值
3)计算邻域值
4)重复上述步骤,直至得到g通道图像中每个像素点对应的3个
step3视觉特征的降维处理:采用概率分析方法来获得不同地域民歌各种颜色通道内lbp特征中差异比较大的模式,然后只保留这些模式,从而达到降维的目的;具体采用变异系数cv(coefficientofvariance)对三个地域民歌相同颜色通道内的相同模式做差异度衡量,cv越大则三个地域的民歌在该模式上差异越大,反之越小。本发明认为内部通道模式cv小于α的为差异较小的模式,交互通道内模式cv小于β的为差异较小的模式,进而将这些模式删除以达到降维的目的。
3)地域分类器融合:分别将提取到的听觉感知特征、视觉特征输入到各自的(supportvectormachine,svm)分类器,对得到的分类器分数向量进行融合作为最终的分类结果。
为了证明融合听觉感知特征与音频视觉特征的中国民歌地域分类算法在民歌地域分类上的优越性,本发明将其与其它基于音频的民歌地域分类算法做了比较,参照表1所示,融合听觉感知特征与音频视觉特征的中国民歌地域分类算法在现有的基于音频的中国民歌地域分类算法中分类准确率是最高的,这也说明将这两类特征结合研究中国民歌的地域分类比直接采用声学特征的研究方式更符合中国民歌的音乐特点。
表1:本发明中民歌地域分类方法与其它民歌地域分类方法的分类准确率对比结果。
- 还没有人留言评论。精彩留言会获得点赞!