一种基于自适应分段线性逼近曲线的集成电路加速方法及系统与流程
本发明属于人工智能技术领域,尤其涉及一种基于自适应分段线性逼近曲线的集成电路加速方法及系统。
背景技术:
在人工神经网络的研究领域内,线性激活函数只是把输入线性组合再输出,无法实现对复杂函数的逼近,多层神经网络和单层无异。曲线激活函数对深层神经网络的函数逼近能力起着至关重要的作用。人工智能算法经常采用曲线激活函数,比如sigmoid函数或者tanh函数,由于集成电路不容易实现指数运算或者三角函数运算等等曲线计算,而且没有统一的公式计算各个不同的曲线激活函数,以串行架构为主的传统处理器无法同时进行大规模的曲线函数计算,因此,研究如何高速地计算曲线激活函数具有十分重要的意义,现有技术存在现有人工智能算法存在曲线激活函数计算速度慢且计算结果精度低的问题。
技术实现要素:
本发明提供一种基于自适应分段线性逼近曲线的集成电路加速方法及系统,以解决上述背景技术中提出现有技术存在现有人工智能算法存在曲线激活函数计算速度慢且计算结果精度低的问题。
本发明所解决的技术问题采用以下技术方案来实现:一种基于自适应分段线性逼近曲线的集成电路加速方法,包括:
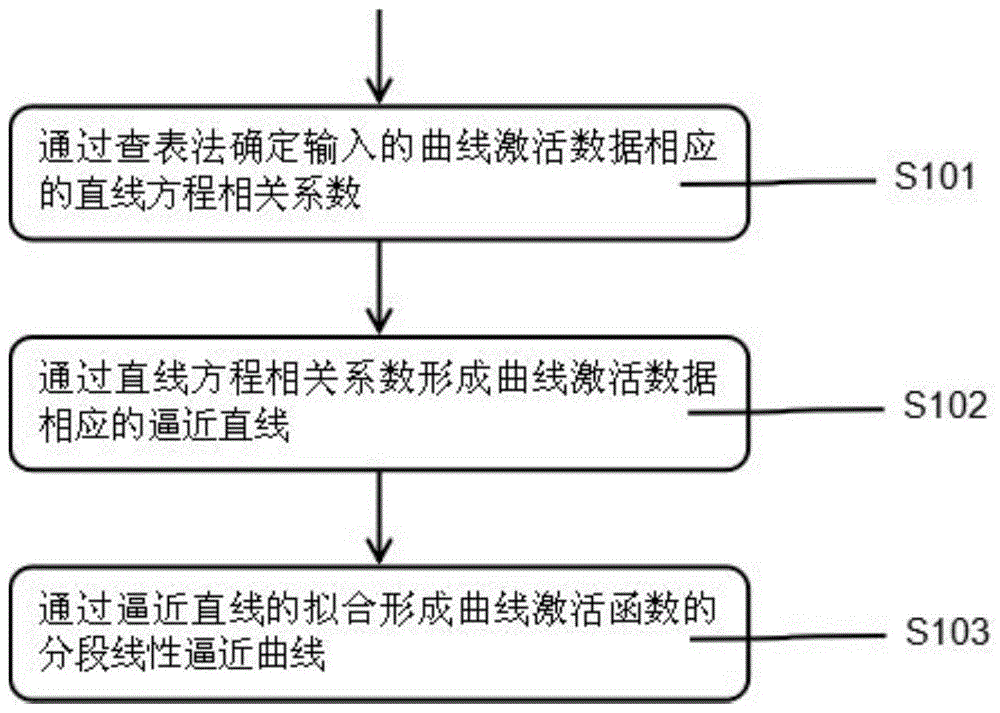
通过查表法确定输入的曲线激活数据相应的直线方程相关系数,通过直线方程相关系数形成曲线激活数据相应的逼近直线,通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线。
进一步,所述查表法包括精确查表法和粗略查表法,所述精确查表法通过查找精准查找表,所述粗略查表法通过查找粗略查找表。
进一步,所述方法还包括:
在正常运行阶段;
通过精粗决定规则确定选择精准查找表或粗略查找表,通过索引建立规则在确定的精准查找表或粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段。
进一步,所述曲线激活函数值计算函数为:
y=kx+b;
其中;
所述x为输入的曲线激活数据;
所述y为曲线激活数据的计算函数值;
所述k为曲线激活数据的斜率系数;
所述b为曲线激活数据的偏置系数。
进一步,所述精粗决定规则包括:
若输入的曲线激活数据的高位地址是精准查找表地址且精准查找表已更新完成,则选择精准查找表,否则选择粗略查找表。
进一步,所述索引建立规则包括:
若选择精准查找表,则将输入的曲线激活数据的低位地址为精准查找表索引值;
若选择粗略查找表,则将输入的曲线激活数据的高位地址为粗略查找表索引值。
进一步,所述曲线激活函数值运算方法包括:
将输入的曲线激活数据输入乘法器,将乘法器运算后的输入的曲线激活数据与曲线激活数据的斜率系数的中间乘积高速串行通过缓冲器并行输入相应的加法器,将相应的加法器运算后的中间乘积与曲线激活数据的偏置系数之和并行输出。
进一步,其中,所述曲线激活函数值运算方法具体方法为:
若输入一个8位曲线激活数据a和另一个8位曲线激活数据b;
其中;
一个8位曲线激活数据a的数据位由高到低顺序排列为:数据位a1、数据位a2、数据位a3、数据位a4、数据位a5、数据位a6、数据位a7、数据位a8;
另一个8位曲线激活数据b的数据位由高到低顺序排列为:数据位b1、数据位b2、数据位b3、数据位b4、数据位b5、数据位b6、数据位b7、数据位b8;
则:
构建第一级流水线,所述第一级流水线包括:
第一左移数据al1:将一个8位曲线激活数据a左移1位;
第二左移数据al2:将一个8位曲线激活数据a左移2位;
第三左移数据al3:将一个8位曲线激活数据a左移3位;
第四左移数据al4:将一个8位曲线激活数据a左移4位;
第五左移数据al5:将一个8位曲线激活数据a左移5位;
第六左移数据al6:将一个8位曲线激活数据a左移6位;
第七左移数据al7:将一个8位曲线激活数据a左移7位;
第八左移数据al8:一个8位曲线激活数据a不左移;
构建8个临时寄存器依次为第一临时寄存器r1、第二临时寄存器r2、第三临时寄存器r3、第四临时寄存器r4、第五临时寄存器r5、第六临时寄存器r6、第七临时寄存器r7、第八临时寄存器r8;
若数据位b1等于0,则第一临时寄存器r1等于0,否则第一临时寄存器r1等于第一左移数据al1;
若数据位b2等于0,则第二临时寄存器r2等于0,否则第二临时寄存器r2等于第二左移数据al2;
若数据位b3等于0,则第三临时寄存器r3等于0,否则第三临时寄存器r3等于第三左移数据al3;
若数据位b4等于0,则第四临时寄存器r4等于0,否则第四临时寄存器r4等于第四左移数据al4;
若数据位b5等于0,则第五临时寄存器r5等于0,否则第五临时寄存器r5等于第五左移数据al5;
若数据位b6等于0,则第六临时寄存器r6等于0,否则第六临时寄存器r6等于第六左移数据al6;
若数据位b7等于0,则第七临时寄存器r7等于0,否则第七临时寄存器r7等于第七左移数据al7;
若数据位b8等于0,则第八临时寄存器r8等于0,否则第八临时寄存器r8等于第八左移数据al8;
构建第二级流水线,所述第二级流水线包括:
第一临时寄存器t1=第一临时寄存器r1+第二临时寄存器r2;
第二临时寄存器t2=第三临时寄存器r3+第四临时寄存器r4;
第三临时寄存器t3=第五临时寄存器r5+第六临时寄存器r6;
第四临时寄存器t4=第七临时寄存器r7+第八临时寄存器r8;
构建第三级流水线,所述第三级流水线包括:
第一临时寄存器y1=第一临时寄存器t1+第二临时寄存器t2;
第二临时寄存器y2=第三临时寄存器t3+第四临时寄存器t4;
构建第四级流水线,所述第四级流水线包括:
临时寄存器x=第一临时寄存器y1+第二临时寄存器y2;
输出最终结果临时寄存器x。
进一步,所述方法还包括:
在初始化阶段;
建立曲线逼近数据库:遍历并计算曲线激活函数所有的相邻两点对应的直线方程的斜率系数和偏置系数并将其相应写入曲线逼近数据库;
初始化精准查找表:将曲线逼近数据库中部分曲线激活函数的区间确定为精准区间,将精准区间内相应的直线方程参数写入精准查找表;
初始化粗略查找表:遍历并计算曲线激活函数所有的经划分的粗略区间的起始点和结束点对应的直线方程的斜率系数和偏置系数并将其相应写入粗略查找表。
进一步,所述方法还包括:
所述建立曲线逼近数据库还包括:分别通过相应的精确逼近直线穿过曲线激活函数的所有的相邻两个点,将相应的精确逼近直线对应的直线方程的斜率系数和偏置系数分别写入曲线逼近数据库;
所述初始化精准查找表还包括:将曲线逼近数据库中曲线激活函数的任意点确定为精准区间的起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数写入精准查找表;
所述初始化粗略查找表还包括:分别通过相应的粗略逼近直线穿过曲线激活函数的所有的经划分的粗略区间的起始点和结束点,将相应的粗略逼近直线对应的直线方程的斜率系数和偏置系数分别写入粗略查找表。
进一步,所述方法还包括:
在正常运行阶段;
重新确定精准查找表:
地址阈值计数:粗略区间经划分后,通过将输入的曲线激活数据的高位地址计数确定最频繁访问的地址区间;
请求仲裁:若计数达到阈值以后,则通过数据仲裁访问曲线逼近数据库;
更新精准查找表:若数据仲裁通过,则将当前输入的曲线激活数据的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表。
进一步,所述方法还包括:所述数据仲裁采用round-robin轮循调度策略。
同时,本发明还提供一种基于自适应分段线性逼近曲线的集成电路加速系统,所述系统包括:
曲线逼近数据库、仲裁器、若干并行计算单元;
所述仲裁器用于若输入的曲线激活数据的高位地址计数达到阈值以后,则通过round-robin轮循调度策略的数据仲裁访问曲线逼近数据库;
所述计算单元用于实现上述所述的基于自适应分段线性逼近曲线的集成电路加速方法。
进一步,所述系统还包括:
所述计算单元包括动态反馈调整模块,所述动态反馈调整模块包括:
地址阈值计数器:用于粗略区间经划分后,通过将输入的曲线激活数据的高位地址计数确定最频繁访问的地址区间;
查找表选择器:用于若输入的曲线激活数据的高位地址是精准查找表地址且精准查找表已更新完成,则选择精准查找表,否则选择粗略查找表;
更新查找表请求器:用于若数据仲裁通过,则将当前输入的曲线激活数据的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表。
进一步,所述系统还包括:
所述计算单元还包括直线方程运算模块,所述直线方程运算模块包括单周期高速乘法器、加法器;
所述直线方程运算模块用于将输入的曲线激活数据输入单周期高速乘法器,将单周期高速乘法器运算后的输入的曲线激活数据与曲线激活数据的斜率系数的中间乘积高速串行通过缓冲器并行输入相应的加法器,将相应的加法器运算后的中间乘积与曲线激活数据的偏置系数之和并行输出。
进一步,所述系统还包括:
所述直线方程运算模块还包括查找表模块,所述查找表模块包括:
精准查找表模块:用于若选择精准查找表,则将输入的曲线激活数据的低位地址为精准查找表索引值,通过精准查找表索引值在确定的精准查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段;
粗略查找表模块:用于若选择粗略查找表,则将输入的曲线激活数据的高位地址为粗略查找表索引值,通过粗略查找表索引值在确定的粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段。
有益技术效果
本专利采用通过查表法确定输入的曲线激活数据相应的直线方程相关系数,通过直线方程相关系数形成曲线激活数据相应的逼近直线,通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线,由于人工智能算法经常采用曲线激活函数,比如sigmoid函数或者tanh函数,由于集成电路不容易实现指数运算或者三角函数运算等等曲线计算,而且没有统一的公式计算各个不同的曲线激活函数,以串行架构为主的传统处理器无法同时进行大规模的曲线计算,因此,如何快速完成激活函数的曲线计算就是需要解决的重要问题,由于逼近曲线激活函数的原理是用一系列折线来逼近曲线,将曲线激活函数划分成若干段曲线,每一段曲线用一条直线来近似,直线段越密集,越逼近对应的那段曲线,本发明采用多个计算单元同时处理多个输入数据,利用查找表,计算直线方程,输出多个曲线激活函数值,根据输入数据的变化自适应调整精准查找表的内容,以达到提高计算精度的目的,本发明具有曲线计算速度快,计算结果精度高,占用硬件资源少,运算实时性,适合任意一种曲线的特点。
附图说明
图1是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的总流程图;
图2是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的具体流程图;
图3是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的多个计算单元通过仲裁器访问曲线逼近数据库的结构图;
图4是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的实施例二中sigmoid曲线与曲线逼近数据库中对应的逼近直线结合的示意图;
图5是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的实施例二中sigmoid曲线与精准查找表对应的中对应的逼近直线结合的示意图;
图6是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的实施例二中sigmoid曲线与粗略查找表中对应的逼近直线结合的示意图;
图7是本发明一种基于自适应分段线性逼近曲线的集成电路加速方法的实施例二中sigmoid曲线激活函数的示意图;
图8是本发明一种基于自适应分段线性逼近曲线的集成电路加速系统的框架图;
图9是本发明一种基于自适应分段线性逼近曲线的集成电路加速系统的整体架构图;
图10是本发明一种基于自适应分段线性逼近曲线的集成电路加速系统的计算单元的具体结构图;
图11是本发明一种基于自适应分段线性逼近曲线的集成电路加速系统的单周期高速乘法器结构图;
具体实施方式
以下结合附图对本发明做进一步描述:
图中:
s101-通过查表法确定输入的曲线激活数据相应的直线方程相关系数;
s102-通过直线方程相关系数形成曲线激活数据相应的逼近直线;
s103-通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线;
s201-建立曲线逼近数据库;
s202-初始化精准查找表;
s203-初始化粗略查找表;
s204-输入的曲线激活数据;
s205-通过精粗决定规则确定选择精准查找表或粗略查找表;
s206-通过索引建立规则在确定的精准查找表或粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数;
s207-通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段;
s208-粗略区间经划分后,通过将输入的曲线激活数据的高位地址计数确定最频繁访问的地址区间;
s209-若计数达到阈值以后,则通过数据仲裁访问曲线逼近数据库;
s210-若数据仲裁通过,则将当前输入的曲线激活数据的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表;
实施例:
实施例一:如图1所示,一种基于自适应分段线性逼近曲线的集成电路加速方法,包括:
通过查表法确定输入的曲线激活数据s204相应的直线方程相关系数s101,通过直线方程相关系数形成曲线激活数据相应的逼近直线s102,通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线s103。
由于采用通过查表法确定输入的曲线激活数据相应的直线方程相关系数,通过直线方程相关系数形成曲线激活数据相应的逼近直线,通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线,由于人工智能算法经常采用曲线激活函数,比如sigmoid函数或者tanh函数,由于集成电路不容易实现指数运算或者三角函数运算等等曲线计算,而且没有统一的公式计算各个不同的曲线激活函数,以串行架构为主的传统处理器无法同时进行大规模的曲线计算,因此,如何快速完成激活函数的曲线计算就是需要解决的重要问题,由于逼近曲线激活函数的原理是用一系列折线来逼近曲线,将曲线激活函数划分成若干段曲线,每一段曲线用一条直线来近似,直线段越密集,越逼近对应的那段曲线,本发明采用多个计算单元同时处理多个输入数据,利用查找表,计算直线方程,输出多个曲线激活函数值,根据输入数据的变化自适应调整精准查找表的内容,以达到提高计算精度的目的,本发明具有曲线计算速度快,计算结果精度高,占用硬件资源少,运算实时性,适合任意一种曲线的特点。
如图2所示,所述查表法包括精确查表法和粗略查表法,所述精确查表法通过查找精准查找表,所述粗略查表法通过查找粗略查找表。
由于采用所述查表法包括精确查表法和粗略查表法,所述精确查表法通过查找精准查找表,所述粗略查表法通过查找粗略查找表,精准查找表和粗略查找表步长间距不一样,精准查找表步长间距小,逼近曲线的精准度高,只能覆盖一小部分曲线激活函数,不能完整的覆盖曲线激活函数,粗略查找表步长间距大,逼近曲线的精准度低,能够完整的覆盖曲线激活函数,精准查找表的数据来自曲线逼近数据库,粗略查找表的数据不是来自曲线逼近数据库,在初始化阶段计算出来的,在正常运行阶段,系统根据输入的数据和查找表,计算相应的曲线激活函数值,因此,精准查找表覆盖的地址范围小,粗略查找表覆盖的地址范围大,精准查找表里面的内容会动态改变,粗略查找表里面的内容固定不变,计算单元使用精准查找表可以得到精准的计算结果,计算单元使用粗略查找表可以得到粗略的计算结果,由于使用2种分段方法划分曲线激活函数,即方法一:把全部地址划分成若干个区间。这个方法能够完整的覆盖曲线激活函数,但是逼近曲线的精准度低。使用方法一构造粗略查找表,初始化以后粗略查找表的内容不会改变;方法二:按照精准查找表地址选取选取一段地址区间,把这个区间的数据库的数据写入精准查找表。这个方法只能覆盖一小部分曲线激活函数,不能完整的覆盖曲线激活函数,但是逼近曲线的精准度高。使用方法二构造精准查找表,初始化以后精准查找表的内容会不停的改变。初始化阶段精准查找表地址可以选取任意值。
所述方法还包括:
在正常运行阶段;
通过精粗决定规则确定选择精准查找表或粗略查找表s205,通过索引建立规则在确定的精准查找表或粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数s206,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段s207。
由于采用在正常运行阶段,通过精粗决定规则确定选择精准查找表或粗略查找表,通过索引建立规则在确定的精准查找表或粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段,由于输入的数据分为两部分:高位地址,低位地址,当输入新的数据时,首先通过分割地址,即输入的数据作为曲线函数的地址,分为两部分(即高位地址和低位地址),根据地址读查找表,根据高位地址决定选择精准查找表还是粗略查找表,以输入的数据作为索引,在查找表里读取数据,获取直线方程的斜率系数k和偏置系数b,从而选择最逼近曲线的直线段,计算曲线激活函数值,根据输入的数据x、斜率系数k和偏置系数b,计算相应的曲线激活函数值y,其计算公式是y=k*x+b,输入的数据x,斜率系数k输入乘法器,其结果和偏置系数b输入加法器,产生最终结果,输出最终结果,通过上述处理,能够同时快速计算多个曲线激活函数值,同时输入多个数据,在固定的时钟周期以后,输出对应的多个曲线激活函数值。
所述曲线激活函数值计算函数为:
y=kx+b;
其中;
所述x为输入的曲线激活数据;
所述y为曲线激活数据的计算函数值;
所述k为曲线激活数据的斜率系数;
所述b为曲线激活数据的偏置系数。
由于采用所述曲线激活函数值计算函数为:y=kx+b,其中,所述x为输入的曲线激活数据,所述y为曲线激活数据的计算函数值,所述k为曲线激活数据的斜率系数,所述b为曲线激活数据的偏置系数,由于逼近曲线激活函数的原理是用一系列折线来逼近曲线,将曲线激活函数划分成若干段曲线,每一段曲线用一条直线来近似。直线段越密集,越逼近对应的那段曲线,直线段可以用代数直线方程表示:y=k*x+b,其中,k代表直线方程的斜率系数,b代表直线方程的偏置系数,计算曲线激活函数值:根据输入的数据x,斜率系数k和偏置系数b,计算相应的曲线激活函数值y,计算公式是y=k*x+b,输入的数据x,斜率系数k输入乘法器,其结果和偏置系数b输入加法器,产生最终结果。
所述精粗决定规则包括:
若输入的曲线激活数据s204的高位地址是精准查找表地址且精准查找表已更新完成,则选择精准查找表,否则选择粗略查找表。
由于采用所述精粗决定规则包括若输入的曲线激活数据的高位地址是精准查找表地址且精准查找表已更新完成,则选择精准查找表,否则选择粗略查找表,由于判断高位地址是否同时满足这两个条件,决定选择精准查找表还是粗略查找表,只有同时满足这两个条件,才可以选择精准查找表,条件一:判断是不是精准查找表地址,条件二:判断是否完成更新精准查找表,查找表输出直线方程的斜率系数和直线方程的偏置系数。
所述索引建立规则包括:
若选择精准查找表,则将输入的曲线激活数据s204的低位地址为精准查找表索引值;
若选择粗略查找表,则将输入的曲线激活数据s204的高位地址为粗略查找表索引值。
由于采用所述索引建立规则包括:若选择精准查找表,则将输入的曲线激活数据的低位地址为精准查找表索引值;若选择粗略查找表,则将输入的曲线激活数据的高位地址为粗略查找表索引值,由于如果选择精准查找表,低位地址提供精准查找表索引值,如果选择粗略查找表,高位地址提供粗略查找表索引值,查找表输出直线方程的斜率系数和直线方程的偏置系数,计算曲线激活函数值的方法是:输入的数据乘以直线方程的斜率系数,然后加上直线方程的偏置系数,输出最后的结果。
所述曲线激活函数值运算方法包括:
将输入的曲线激活数据s204输入乘法器,将乘法器运算后的输入的曲线激活数据s204与曲线激活数据的斜率系数的中间乘积高速串行通过缓冲器并行输入相应的加法器,将相应的加法器运算后的中间乘积与曲线激活数据的偏置系数之和并行输出。
其中,所述曲线激活函数值运算方法具体方法为:
若输入一个8位曲线激活数据a和另一个8位曲线激活数据b;
其中;
一个8位曲线激活数据a的数据位由高到低顺序排列为:数据位a1、数据位a2、数据位a3、数据位a4、数据位a5、数据位a6、数据位a7、数据位a8;
另一个8位曲线激活数据b的数据位由高到低顺序排列为:数据位b1、数据位b2、数据位b3、数据位b4、数据位b5、数据位b6、数据位b7、数据位b8;
则:
构建第一级流水线,所述第一级流水线包括:
第一左移数据al1:将一个8位曲线激活数据a左移1位;
第二左移数据al2:将一个8位曲线激活数据a左移2位;
第三左移数据al3:将一个8位曲线激活数据a左移3位;
第四左移数据al4:将一个8位曲线激活数据a左移4位;
第五左移数据al5:将一个8位曲线激活数据a左移5位;
第六左移数据al6:将一个8位曲线激活数据a左移6位;
第七左移数据al7:将一个8位曲线激活数据a左移7位;
第八左移数据al8:一个8位曲线激活数据a不左移;
构建8个临时寄存器依次为第一临时寄存器r1、第二临时寄存器r2、第三临时寄存器r3、第四临时寄存器r4、第五临时寄存器r5、第六临时寄存器r6、第七临时寄存器r7、第八临时寄存器r8;
若数据位b1等于0,则第一临时寄存器r1等于0,否则第一临时寄存器r1等于第一左移数据al1;
若数据位b2等于0,则第二临时寄存器r2等于0,否则第二临时寄存器r2等于第二左移数据al2;
若数据位b3等于0,则第三临时寄存器r3等于0,否则第三临时寄存器r3等于第三左移数据al3;
若数据位b4等于0,则第四临时寄存器r4等于0,否则第四临时寄存器r4等于第四左移数据al4;
若数据位b5等于0,则第五临时寄存器r5等于0,否则第五临时寄存器r5等于第五左移数据al5;
若数据位b6等于0,则第六临时寄存器r6等于0,否则第六临时寄存器r6等于第六左移数据al6;
若数据位b7等于0,则第七临时寄存器r7等于0,否则第七临时寄存器r7等于第七左移数据al7;
若数据位b8等于0,则第八临时寄存器r8等于0,否则第八临时寄存器r8等于第八左移数据al8;
构建第二级流水线,所述第二级流水线包括:
第一临时寄存器t1=第一临时寄存器r1+第二临时寄存器r2;
第二临时寄存器t2=第三临时寄存器r3+第四临时寄存器r4;
第三临时寄存器t3=第五临时寄存器r5+第六临时寄存器r6;
第四临时寄存器t4=第七临时寄存器r7+第八临时寄存器r8;
构建第三级流水线,所述第三级流水线包括:
第一临时寄存器y1=第一临时寄存器t1+第二临时寄存器t2;
第二临时寄存器y2=第三临时寄存器t3+第四临时寄存器t4;
构建第四级流水线,所述第四级流水线包括:
临时寄存器x=第一临时寄存器y1+第二临时寄存器y2;
输出最终结果临时寄存器x。
由于采用将输入的曲线激活数据输入乘法器,将乘法器运算后的输入的曲线激活数据与曲线激活数据的斜率系数的中间乘积高速串行通过缓冲器并行输入相应的加法器,将相应的加法器运算后的中间乘积与曲线激活数据的偏置系数之和并行输出,由于高速乘法器采用了树式架构,按照2的指数展开为多级流水线,多个加法器并行运算,一个周期以后就可以输出结果,因为运算的中间结果锁存在流水线触发器里,所以即使还没有输出上一个乘法计算结果,还是可以立刻开始下一个乘法计算,因此,具有结构简单、运算速度快的优点且适合大量的使用在计算单元里,具体的运算过程如下图所示:
(1)2个输入的数据,标记为a,b。
(2)2个输入的数据宽度都是8位,由高位到低位,按顺序标记为:
a1,a2,a3,a4,a5,a6,a7,a8;
b1,b2,b3,b4,b5,b6,b7,b8;
(3)总共构建4级流水线;
(4)构建第1级流水线;
数据a左移1位,标记为al1,数据a左移2位,标记为al2,数据a左移3位,标记为al3,数据a左移4位,标记为al4,数据a左移5位,标记为al5,数据a左移6位,标记为al6,数据a左移7位,标记为al7.数据a不左移,标记为al8;
(5)构建8个临时寄存器,标记为r1,r2,r3,r4,r5,r6,r7,r8.
(6)如果b1等于0,r1=0,否则r1=al1。如果b2等于0,r2=0,否则r2=al2,如果b3等于0,r3=0,否则r3=al3,如果b4等于0,r4=0,否则r4=al4,如果b5等于0,r5=0,否则r5=al5,如果b6等于0,r6=0,否则r6=al6,如果b7等于0,r7=0,否则r7=al7,如果b8等于0,r8=0,否则r8=al8;
(7)构建第2级流水线;
(8)构建4个临时寄存器,标记为t1,t2,t3,t4;
(9)第1级流水线8个临时寄存器编成4组加法:
t1=r1+r2,t2=r3+r4,t3=r5+r6,t4=r7+r8;
(10)构建第3级流水线;
(11)构建2个临时寄存器,标记为y1,y2;
(12)第2级流水线4个临时寄存器编成2组加法:y1=t1+t2,y2=t3+t4;
(13)构建第4级流水线;
(14)构建最后结果寄存器,标记为x;
(15)第3级流水线2个临时寄存器编成1组加法:x=y1+y2;
输出最后结果x。
所述方法还包括:
在初始化阶段;
建立曲线逼近数据库s201:遍历并计算曲线激活函数所有的相邻两点对应的直线方程的斜率系数和偏置系数并将其相应写入曲线逼近数据库;
初始化精准查找表s202:将曲线逼近数据库中部分曲线激活函数的区间确定为精准区间,将精准区间内相应的直线方程参数写入精准查找表;
初始化粗略查找表s203:遍历并计算曲线激活函数所有的经划分的粗略区间的起始点和结束点对应的直线方程的斜率系数和偏置系数并将其相应写入粗略查找表。
所述方法还包括:
所述建立曲线逼近数据库s201还包括:分别通过相应的精确逼近直线穿过曲线激活函数的所有的相邻两个点,将相应的精确逼近直线对应的直线方程的斜率系数和偏置系数分别写入曲线逼近数据库;
所述初始化精准查找表s202还包括:将曲线逼近数据库中曲线激活函数的任意点确定为精准区间的起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数写入精准查找表;
所述初始化粗略查找表s203还包括:分别通过相应的粗略逼近直线穿过曲线激活函数的所有的经划分的粗略区间的起始点和结束点,将相应的粗略逼近直线对应的直线方程的斜率系数和偏置系数分别写入粗略查找表。
由于采用在初始化阶段,建立曲线逼近数据库:遍历并计算曲线激活函数所有的相邻两点对应的直线方程的斜率系数和偏置系数并将其相应写入曲线逼近数据库;初始化精准查找表:将曲线逼近数据库中部分曲线激活函数的区间确定为精准区间,将精准区间内相应的直线方程参数写入精准查找表;初始化粗略查找表:遍历并计算曲线激活函数所有的经划分的粗略区间的起始点和结束点对应的直线方程的斜率系数和偏置系数并将其相应写入粗略查找表,由于建立曲线逼近数据库:首先,在初始化阶段,系统选择曲线激活函数的相邻两个点,构造一条直线穿过两个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库,以此类推,遍历曲线激活函数所有的相邻两个点,完成建立曲线逼近数据库,其次,初始化精准查找表:选取任意值作为精准查找表地址,作为地址区间的起始地址,把这个区间的数据库的数据写入精准查找表。这个方法只能覆盖一小部分曲线激活函数,不能完整的覆盖曲线激活函数,但是逼近曲线的精准度高,最后,初始化粗略查找表:把全部地址划分成若干个区间,选取每一个区间的起始点,结束点,构造一条直线穿过两个点,计算出对应的直线方程的斜率系数和偏置系数,写入粗略查找表。
如图2所示,所述方法还包括:
在正常运行阶段;
重新确定精准查找表:
地址阈值计数:粗略区间经划分后,通过将输入的曲线激活数据s204的高位地址计数确定最频繁访问的地址区间s208;
请求仲裁:若计数达到阈值以后,则通过数据仲裁访问曲线逼近数据库s209;
更新精准查找表:若数据仲裁通过,则将当前输入的曲线激活数据s204的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表s210。
由于采用在正常运行阶段,重新确定精准查找表:地址阈值计数:粗略区间经划分后,通过将输入的曲线激活数据的高位地址计数确定最频繁访问的地址区间;请求仲裁:若计数达到阈值以后,则通过数据仲裁访问曲线逼近数据库;更新精准查找表:若数据仲裁通过,则将当前输入的曲线激活数据的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表,由于地址阈值计数器,发现最频繁访问的地址区间:分割地址以后,高位地址送入地址阈值计数器,对当前的高位地址进行计数。它的目的是发现最频繁访问的地址区间,给出反馈,及时更新精准查找表,请求仲裁器,访问曲线逼近数据库:计数器达到阈值以后,请求仲裁器,要求访问曲线逼近数据库,根据动态反馈,更新精准查找表:仲裁器授权以后,把当前的高位地址设置为精准查找表地址,更新精准查找表,选取曲线逼近数据库的高位地址的数据写入精准查找表,更新精准查找表需要一段时间,期间计算单元只能使用粗略查找表,曲线逼近数据库有完整的曲线函数值,但是数据量太大,计算单元有许多个,如果每一个计算单元都配备一个曲线逼近数据库会占用庞大的存储空间,所以只能选取一部分数据写入精准查找表。
本发明跟随输入数据的变化,动态修改精准查找表地址,自适应调整精准查找表的内容,尽量使用精准查找表计算,以达到提高计算精度的目的。
如图3所示,所述方法还包括:所述数据仲裁采用round-robin轮循调度策略。
由于采用所述数据仲裁采用round-robin轮循调度策略,由于多个计算单元可以同时处理多个输入数据。多个计算单元同时请求访问一个曲线逼近数据库,通过仲裁器给其中一个计算单元授权。仲裁器采用了轮循round-robin的调度策略。
如图8所示,同时,本发明还提供一种基于自适应分段线性逼近曲线的集成电路加速系统,所述系统包括:
曲线逼近数据库、仲裁器、若干并行计算单元;
所述仲裁器用于若输入的曲线激活数据s204的高位地址计数达到阈值以后,则通过round-robin轮循调度策略的数据仲裁访问曲线逼近数据库;
所述计算单元用于实现上述所述的基于自适应分段线性逼近曲线的集成电路加速方法。
如图9所示,所述系统还包括:
所述计算单元包括动态反馈调整模块,所述动态反馈调整模块包括:
地址阈值计数器:用于粗略区间经划分后,通过将输入的曲线激活数据s204的高位地址计数确定最频繁访问的地址区间s208;
查找表选择器:用于若输入的曲线激活数据s204的高位地址是精准查找表地址且精准查找表已更新完成,则选择精准查找表,否则选择粗略查找表;
更新查找表请求器:用于若数据仲裁通过,则将当前输入的曲线激活数据s204的高位地址确定为曲线激活函数的精准区间起始地址,从精准区间的起始地址开始依次将精准区间的所有直线方程参数更新精准查找表s210。
如图10所示,所述系统还包括:
所述计算单元还包括直线方程运算模块,所述直线方程运算模块包括单周期高速乘法器、加法器;
所述直线方程运算模块用于将输入的曲线激活数据s204输入单周期高速乘法器,将单周期高速乘法器运算后的输入的曲线激活数据s204与曲线激活数据的斜率系数的中间乘积高速串行通过缓冲器并行输入相应的加法器,将相应的加法器运算后的中间乘积与曲线激活数据的偏置系数之和并行输出。
所述系统还包括:
所述直线方程运算模块还包括查找表模块,所述查找表模块包括:
精准查找表模块:用于若选择精准查找表,则将输入的曲线激活数据s204的低位地址为精准查找表索引值,通过精准查找表索引值在确定的精准查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段s207;
粗略查找表模块:用于若选择粗略查找表,则将输入的曲线激活数据s204的高位地址为粗略查找表索引值,通过粗略查找表索引值在确定的粗略查找表内确定曲线激活数据相应的直线方程的斜率系数和偏置系数,通过曲线激活函数值计算函数和曲线激活函数值运算方法确定最逼近曲线的直线段s207。
由于采用所述系统包括:曲线逼近数据库、仲裁器、若干并行计算单元;所述仲裁器用于若输入的曲线激活数据的高位地址计数达到阈值以后,则通过round-robin轮循调度策略的数据仲裁访问曲线逼近数据库;所述计算单元用于实现上述所述的基于自适应分段线性逼近曲线的集成电路加速方法,系统包括曲线逼近数据库,仲裁器,多个计算单元,每一个计算单元包括动态反馈调整模块,直线方程运算模块,动态反馈调整模块包括地址阈值计数器,查找表选择器,更新查找表请求器,直线方程运算模块包括单周期高速乘法器,加法器,查找表,查找表包括精准查找表,粗略查找表。根据一定规则不断更新精准查找表,每一个计算单元包括动态反馈调整模块,直线方程运算模块,输入1个数据,在固定的时钟周期以后,输出对应的1个曲线激活函数值,达到阈值的多个计算单元同时请求访问一个曲线逼近数据库,通过仲裁器给其中一个计算单元授权,仲裁器采用了轮循round-robin的调度策略,每一个计算单元以输入的数据x作为索引,在查找表里读取出直线方程的斜率系数k和偏置系数b,计算相应的曲线激活函数值y,计算公式是y=k*x+b,输入的数据x,斜率系数k输入乘法器,其结果和偏置系数b输入加法器,产生最终结果,高速乘法器利用多级流水线,多个加法器并行运算,一个周期以后就可以输出结果,因为运算的中间结果锁存在流水线触发器里,所以即使还没有输出上一个乘法计算结果,还是可以立刻开始下一个乘法计算,查找表包括两个,即精准查找表和粗略查找表,步长间距不一样,系统跟随输入数据的变化,动态修改精准查找表地址,自适应调整精准查找表的内容,尽量使用精准查找表计算。
实施例二:
如图8、9、10、11以下是以计算sigmoid曲线激活函数为例来说明一种基于自适应分段线性逼近曲线的集成电路加速算法及系统,如下:
步骤1:建立曲线逼近数据库:在初始化阶段,把全部地址划分成8个区间。系统选择曲线激活函数的相邻2个点a0,a1,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。系统选择曲线激活函数的相邻2个点a1,a2,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a2,a3,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a3,a4,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a4,a5,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a5,a6,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a6,a7,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。选择2个点a7,a8,构造一条直线穿过2个点,计算出对应的直线方程的斜率系数和偏置系数,写入曲线逼近数据库。点a0的x轴地址是000。点a1的x轴地址是001。点a2的x轴地址是010。点a3的x轴地址是011。点a4的x轴地址是100。点a5的x轴地址是101。点a6的x轴地址是110。点a7的x轴地址是111。请参考附图6。完成建立曲线逼近数据库。
步骤2:初始化精准查找表:选取任意值0作为精准查找表地址,作为地址区间的起始地址,区间长度设置为4,这个区间有5个点a0,a1,a2,a3,a4,有4条直线穿过这5个点,把数据库里对应的直线方程的数据写入精准查找表。请参考附图7。
步骤3:初始化粗略查找表:把全部地址划分成2个区间。选取第1个区间的起始点b0,结束点b1,构造一条直线穿过这2个点,计算出对应的直线方程的斜率系数和偏置系数,写入粗略查找表。选取第2个区间的起始点b1,结束点b2,构造一条直线穿过这2个点,计算出对应的直线方程的斜率系数和偏置系数,写入粗略查找表。点b0的x轴地址是000。点b1的x轴地址是100。点b2的x轴地址是111。穿过点b0点b1的直线方程对应的索引是0。穿过点b1点b2的直线方程对应的索引是1。请参考附图8,
步骤4:输入新的数据101。
步骤5:分割地址:输入的数据101作为曲线函数的地址,高位地址选择1位,低位地址选择2位,分为2部分:高位地址是1,低位地址是01。
步骤6:根据地址读查找表:根据高位地址1决定选择粗略查找表。因为精准查找表地址是011,高位地址是0。以高位地址1作为索引,在粗略查找表里读取数据,选择穿过点b1点b2的直线方程的斜率系数和偏置系数。
步骤7:获取直线方程的斜率系数k和偏置系数b:选择最逼近曲线的直线段:穿过点b1点b2的直线。
步骤8:计算曲线激活函数值:根据输入的数据x,斜率系数k和偏置系数b,计算相应的曲线激活函数值y。计算公式是y=k*x+b。
步骤9:输出最终结果。
步骤10:分割地址以后,高位地址送入地址阈值计数器,对当前的高位地址进行计数。发现最频繁访问的地址是1,不是0:
步骤11:计数器达到阈值,请求仲裁器,要求访问曲线逼近数据库。
步骤12:仲裁器授权以后,把当前的高位地址1设置为精准查找表地址,更新精准查找表。选取曲线逼近数据库的高位地址对应的数据写入精准查找表。因为点a0的x轴地址是000。点a1的x轴地址是001。点a2的x轴地址是010。点a3的x轴地址是011。点a4的x轴地址是100。点a5的x轴地址是101。点a6的x轴地址是110。点a7的x轴地址是111。所以选择点a4,点a5,点a6,点a7,把穿过这些点的直线方程的斜率系数k和偏置系数b写入精准查找表。
举个例子,图7是sigmoid曲线激活函数,其中包括一条sigmoid曲线;
图6中sigmoid曲线可以分成两段曲线,用两条直线来近似;
参考图6,该图中包括sigmoid曲线和两条直线,该两条直线对应的直线方程的斜率系数和偏置系数保存在粗略查找表。
参考图5,该图中包括sigmoid曲线的一部分曲线和用四条直线来近似;
参考图4,该图中包括sigmoid曲线和八条直线,该八条直线更加的逼近曲线,该八条直线对应的直线方程的斜率系数和偏置系数因为数据量庞大,只能保存一部分在精准查找表。
工作原理:
本专利通过通过查表法确定输入的曲线激活数据相应的直线方程相关系数,通过直线方程相关系数形成曲线激活数据相应的逼近直线,通过逼近直线的拟合形成曲线激活函数的分段线性逼近曲线,由于人工智能算法经常采用曲线激活函数,比如sigmoid函数或者tanh函数,由于集成电路不容易实现指数运算或者三角函数运算等等曲线计算,而且没有统一的公式计算各个不同的曲线激活函数,以串行架构为主的传统处理器无法同时进行大规模的曲线计算,因此,如何快速完成激活函数的曲线计算就是需要解决的重要问题,由于逼近曲线激活函数的原理是用一系列折线来逼近曲线,将曲线激活函数划分成若干段曲线,每一段曲线用一条直线来近似,直线段越密集,越逼近对应的那段曲线,本发明采用多个计算单元同时处理多个输入数据,利用查找表,计算直线方程,输出多个曲线激活函数值,根据输入数据的变化自适应调整精准查找表的内容,以达到提高计算精度的目的,本发明解决了现有技术存在现有人工智能算法存在曲线激活函数计算速度慢且计算结果精度低的问题,具有曲线计算速度快,计算结果精度高,占用硬件资源少,运算实时性,适合任意一种曲线的特点的有益技术效果。
利用本发明的技术方案,或本领域的技术人员在本发明技术方案的启发下,设计出类似的技术方案,而达到上述技术效果的,均是落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!